1.下载Qwen3大模型:
python
git clone https://www.modelscope.cn/Qwen/Qwen3-1.7B.git放在服务器的/mnt/workspace/Qwen3-1.7B目录下。
2.创建python虚拟环境:
python
python3 -m venv venv1
source venv1/bin/activate3.安装vllm推理框架
python
pip install vllm 
4.启动vllm服务
python
CUDA_VISIBLE_DEVICES=0 \
python3 -m vllm.entrypoints.openai.api_server \
--model /mnt/workspace/Qwen3-1.7B \
--served-model-name qwen3 \
--gpu-memory-utilization=0.85 \
--tensor-parallel-size 1 \
--trust-remote-code注意以下几点:
(1)如果不指定端口,则vllm默认端口是8000;
(2)参数gpu-memory-utilization必须加上,不然可能会报oom显存不足的错误;
(3)tensor-parallel-size的个数,取决于使用的GPU数量。
启动需加载1-2分钟左右,启动结果如下:
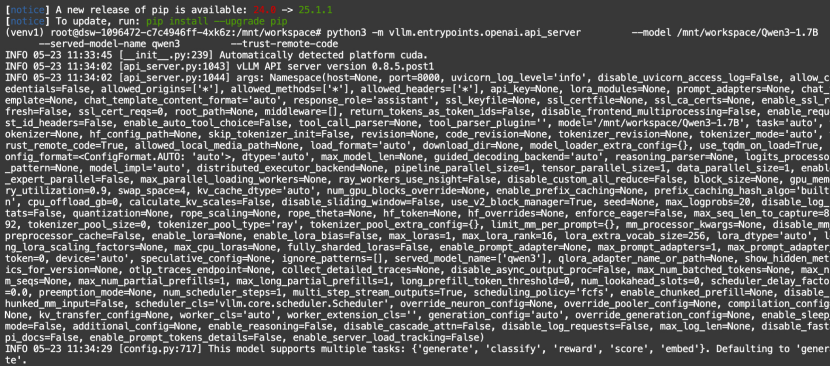
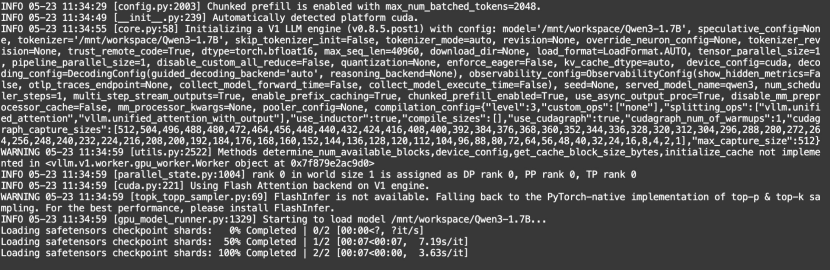
5.查询大模型
python
curl http://localhost:8000/v1/models查询到名字为qwen3的模型:

6.调用大模型服务
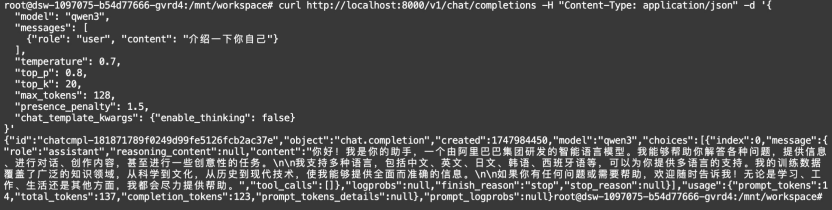
python
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "qwen3",
"messages": [
{"role": "user", "content": "介绍一下你自己"}
],
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20,
"max_tokens": 128,
"presence_penalty": 1.5,
"chat_template_kwargs": {"enable_thinking": false}
}'返回结果:
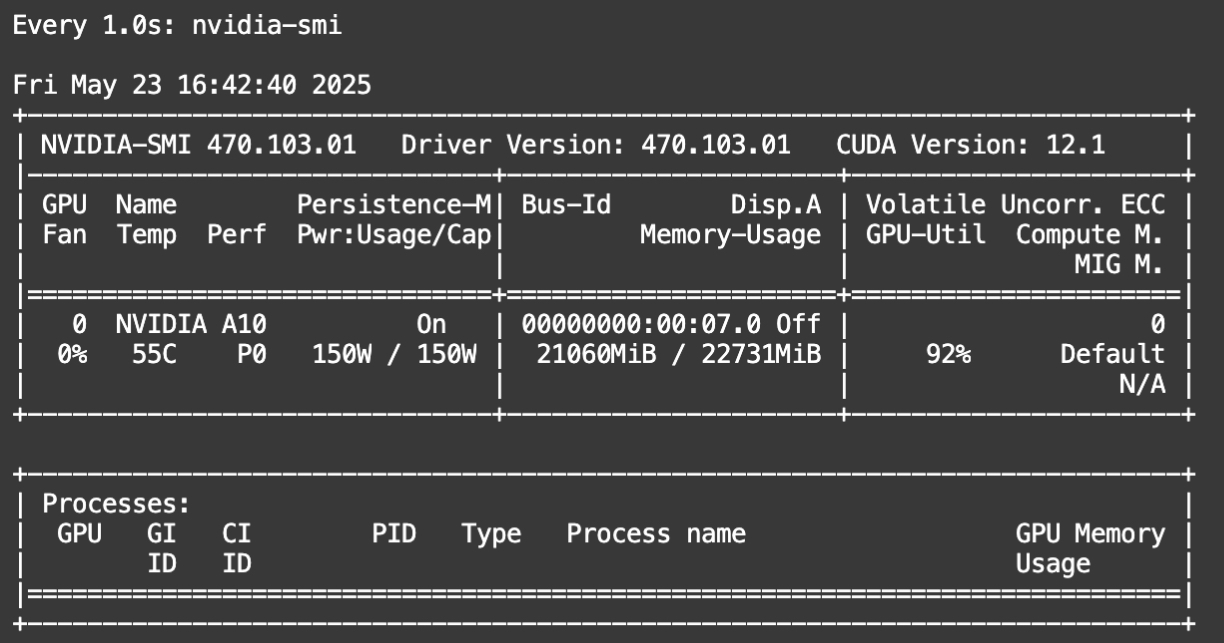
7.显卡使用情况