上篇文章简单介绍了SpringCloud系列熔断器:Sentinel的搭建及基本用法,今天继续讲解下SpringCloud的微服务链路追踪:Zipkin的使用!在分享之前继续回顾下本次SpringCloud的专题要讲的内容:

前置知识说明
在开始本教程前,请确保您已具备:
- Spring Boot基础开发能力
- 熟悉微服务架构基本概念
本教程基于Spring Cloud Hoxton版本构建,建议先完成系列前几篇内容的学习,可直接下载资源绑定的源码进行一起学习!
为什么需要链路追踪?
在微服务架构中,随着业务复杂度提升,一个请求往往需要经过多个服务节点的协作处理。当出现性能瓶颈或异常时,传统的单体应用排查方式已无法满足需求。分布式链路追踪技术应运而生,它能够:
- 清晰展示请求在系统中的完整流转路径
- 快速定位故障节点
- 分析各环节耗时情况
- 优化系统整体性能
目前主流的解决方案包括Sleuth+Zipkin组合和Skywalking等。本文将重点讲解Spring Cloud生态中的Sleuth与Zipkin整合方案。
实战:集成Spring Cloud Sleuth
环境准备
在consumer、provider、gateway和auth四个服务模块中,首先添加以下依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>🌈
注意 :如果同时使用了Hystrix和Sentinel,建议移除
feign.hystrix.enable: true配置,避免组件冲突。
效果验证
启动所有服务后,访问测试接口:http://127.0.0.1:15010/consumer/nacos/echo/hello
观察控制台日志,会发现新增了类似以下格式的内容:
[winter-gateway,88a4de6d2424cedf,88a4de6d2424cedf,false]这些新增信息正是Sleuth实现分布式追踪的关键元素:
- 服务标识 :对应
spring.application.name配置 - Trace ID:整条请求链路的唯一标识
- Span ID:单个服务调用的工作单元标识
- 采样标志:决定是否上报到收集系统
特别值得注意的是,同一请求链路上的不同服务会共享相同的Trace ID,这正是实现跨服务追踪的基础。
核心原理剖析
分布式追踪系统主要解决两大核心问题:
- 请求关联
通过生成全局唯一的Trace ID,在请求穿越各个服务节点时保持传递,最终将所有相关日志串联起来。 - 耗时统计
利用Span ID标记每个处理单元的开始和结束,通过记录时间戳计算各环节耗时,同时可记录附加元数据。
进阶:整合Zipkin可视化
Zipkin服务部署
提供多种安装方式:
快速启动(内存模式):
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jarDocker-Compose方式(MySQL存储):
version: '2'
services:
zipkin:
image: openzipkin/zipkin
environment:
- STORAGE_TYPE=mysql
- MYSQL_HOST=数据库地址
- MYSQL_USER=用户名
- MYSQL_PASS=密码
ports:
- 9411:9411🌈
完整支持多种存储后端,详见官方文档
数据上报配置
在各服务模块中添加Zipkin上报依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>配置上报地址(以consumer为例):
spring:
zipkin:
base-url: http://localhost:9411/
service:
name: consumer效果验证
访问测试接口后,打开Zipkin控制台(http://localhost:9411),可以看到完整的调用链路可视化展示:
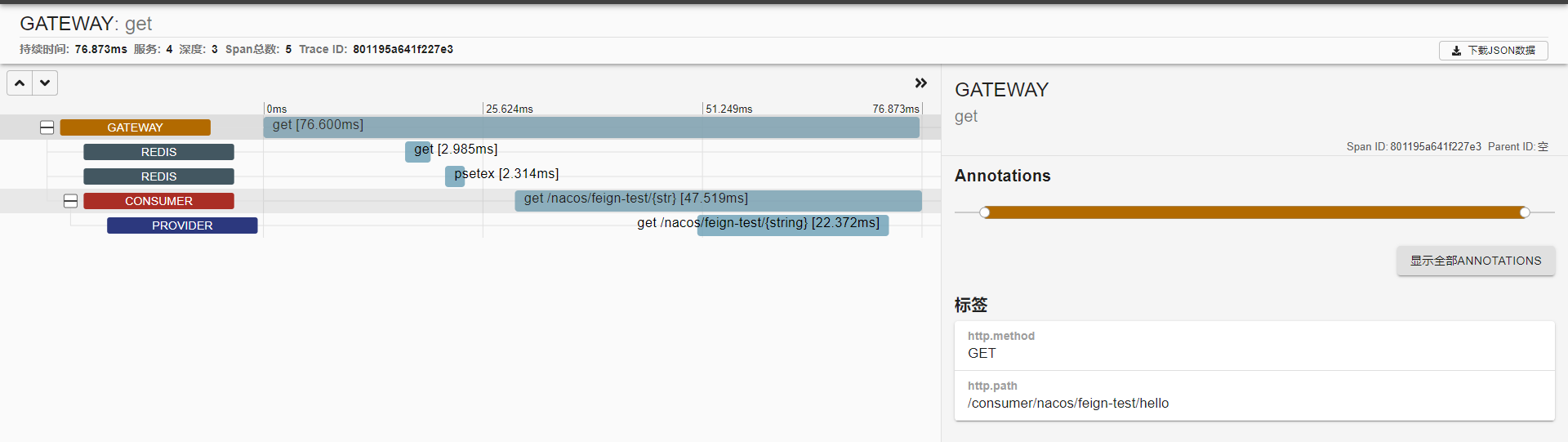
通过分析界面,您可以:
- 查看完整调用拓扑
- 分析各环节耗时
- 定位异常节点
- 发现性能瓶颈
总结与展望
在微服务架构中,完善的监控体系不可或缺。Sleuth+Zipkin组合提供了开箱即用的解决方案,能够有效提升分布式系统的可观测性。随着业务发展,您还可以考虑:
- 结合日志系统实现更全面的监控
- 对接告警系统实现主动监控
- 探索其他APM工具如Skywalking的深度功能
希望本教程能帮助您构建更健壮的微服务系统!如有任何问题,欢迎在评论区交流讨论。