1. 自定义 Advisor
实际上,Advisor 可以看做是 Servlet 当中的"拦截器",在大模型接收到 prompt 之前进行前置拦截增强(比如敏感词校验、记录日志、鉴权),并在大模型返回响应之后进行后置拦截增强(比如记录日志)官方已经提供了一系列 Advisor 可供插拔使用,但是接下来我们需要学习如何自定义 Advisor
1.1 自定义 Advisor 步骤
我们接下来就参考官方文档来学习如何自定义 Advisor 在项目中使用:
📖 参考文档:https://docs.spring.io/spring-ai/reference/api/advisors.html
1)步骤一:选择合适的接口实现
- CallAroundAdvisor:用于处理同步的请求与响应(非流式)
- StreamAroundAdvisor:用于处理流式的请求与响应
更加建议两者同时实现
2)步骤二:实现接口核心方法
- 对于非流式接口 CallAroundAdvisor 来说,需要实现 nextAroundCall 方法
- 对于流式接口 StreamAroundAdvisor 来说,需要实现 nextAroundStream 方法
3)步骤三:设置执行顺序
通过重写 getOrder 方法,返回的值越低,越先被执行
4)步骤四:设置唯一名称
通过重写 getName 方法,返回唯一标识符
1.2 实现 Logging Advisor
其实官方提供了一个 SimpleLoggerAdvisor 用于记录日志,但是出于以下两方面原因并没有在项目中采用
- SimpleLoggerAdvisor 源码中使用 debug 级别输出日志,而 SpringBoot 默认忽略 debug 以下级别日志
- 自定义的 LoggerAdvisor 更加灵活,便于自定义日志
我们可以参考官方的示例,实现自定义的 Logging Advisor,参考代码如下:
java
/**
* 自定义日志Advisor
* @author ricejson
*/
public class MyLoggerAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {
private static final Logger logger = LoggerFactory.getLogger(MyLoggerAdvisor.class);
@Override
public String getName() {
return this.getClass().getSimpleName();
}
@Override
public int getOrder() {
return 0;
}
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
// 调用前记录请求日志
logger.info("before req:{}", advisedRequest);
// 调用执行链
AdvisedResponse advisedResponse = chain.nextAroundCall(advisedRequest);
// 调用后记录响应日志
logger.info("after resp:{}", advisedResponse);
return advisedResponse;
}
@Override
public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {
// 调用前记录请求日志
logger.info("before req:{}", advisedRequest);
// 调用执行链
Flux<AdvisedResponse> flux = chain.nextAroundStream(advisedRequest);
return new MessageAggregator().aggregateAdvisedResponse(flux, (advisedResponse) -> {
// 调用后记录响应日志
logger.info("after resp:{}", advisedResponse);
});
}
}需要特别注意的是 MessageAggregator消息聚合器对象将 Flux 类型聚合成单个 AdvisedResponse,是一种流式处理模式,我们在 ResumeApp 当中应用我们编写的自定义 Advisior 观察效果
java
public ResumeApp(ChatModel dashscopeChatModel) {
ChatMemory chatMemory = new InMemoryChatMemory();
this.chatClient = ChatClient.builder(dashscopeChatModel)
.defaultSystem("你是一位资深职业顾问与AI技术融合的【简历辅导大师】,拥有以下核心能力:\n" +
"1. HR视角:熟悉ATS(招聘系统)筛选逻辑、500+行业岗位的简历关键词库\n" +
"2. 实战经验:基于10万份真实简历优化案例的决策模型\n" +
"3. 教练模式:通过苏格拉底式提问引导用户自主发现简历问题") // 系统预设提示词
.defaultAdvisors(new MessageChatMemoryAdvisor(chatMemory), // 支持多轮对话
new MyLoggerAdvisor()) // 自定义日志Advisor
.build();
}最终运行测试代码,可以发现自定义的日志 Advisor 已经生效了!

1.3 实现 Re2 Advisor
让我们继续趁热打铁,再来学习官方文档中的示例,再来实现一个 Re2 的自定义 Advisor 叭!Re2(全称为Re-Reading)机制,简单来说就是让 AI 大模型重新阅读用户提示词,来提升大模型的推理能力,例如:
plain
{input_prompt}
reading the question again: {input_prompt}💡 注意:虽然 Re2 技术能够有效提升大模型的推理能力,但是带来的是双倍的成本(双倍token)对于 C 端产品来说需要控制成本
自定义 Re2 Advisor 相关代码如下:
java
/**
* 自定义 ReReading Advisor
* @author ricejson
*/
public class MyReReadingAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {
@Override
public String getName() {
return this.getClass().getSimpleName();
}
@Override
public int getOrder() {
return -1;
}
/**
* 实现ReReading逻辑
* @return 返回ReReading之后的请求
*/
private AdvisedRequest reReading(AdvisedRequest advisedRequest) {
Map<String, Object> userParams = new HashMap<>(advisedRequest.userParams());
// 设置替换模板
userParams.put("input_prompt", advisedRequest.userText());
return AdvisedRequest.from(advisedRequest)
.userText("""
{input_prompt}
reading the question again: {input_prompt}
""")
.userParams(userParams)
.build();
}
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
return chain.nextAroundCall(reReading(advisedRequest));
}
@Override
public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {
return chain.nextAroundStream(reReading(advisedRequest));
}
}我们继续在 ResumeApp 当中应用我们编写的自定义的 Advisor 观察效果
java
public ResumeApp(ChatModel dashscopeChatModel) {
ChatMemory chatMemory = new InMemoryChatMemory();
this.chatClient = ChatClient.builder(dashscopeChatModel)
.defaultSystem("你是一位资深职业顾问与AI技术融合的【简历辅导大师】,拥有以下核心能力:\n" +
"1. HR视角:熟悉ATS(招聘系统)筛选逻辑、500+行业岗位的简历关键词库\n" +
"2. 实战经验:基于10万份真实简历优化案例的决策模型\n" +
"3. 教练模式:通过苏格拉底式提问引导用户自主发现简历问题") // 系统预设提示词
.defaultAdvisors(new MessageChatMemoryAdvisor(chatMemory), // 支持多轮对话
new MyLoggerAdvisor(), // 自定义日志Advisor
new MyReReadingAdvisor()) // 自定义ReReading Advisor
.build();
}最终运行测试代码,可以发现自定义的 ReReading Advisor 已经生效了!

2. 结构化输出
2.1 工作流程
Structured Output(结构化输出)是Spring AI 另一个非常有用的机制,尤其是对于那些依赖可靠输入的下游服务来说,结构化输出可以将大模型的输出结果转化为特定的数据类型,比如 XML、JSON、POJO 等,结构化输出的核心组件就是 Structured Output Converter(结构化输出转换器),核心数据流图如下图所示:
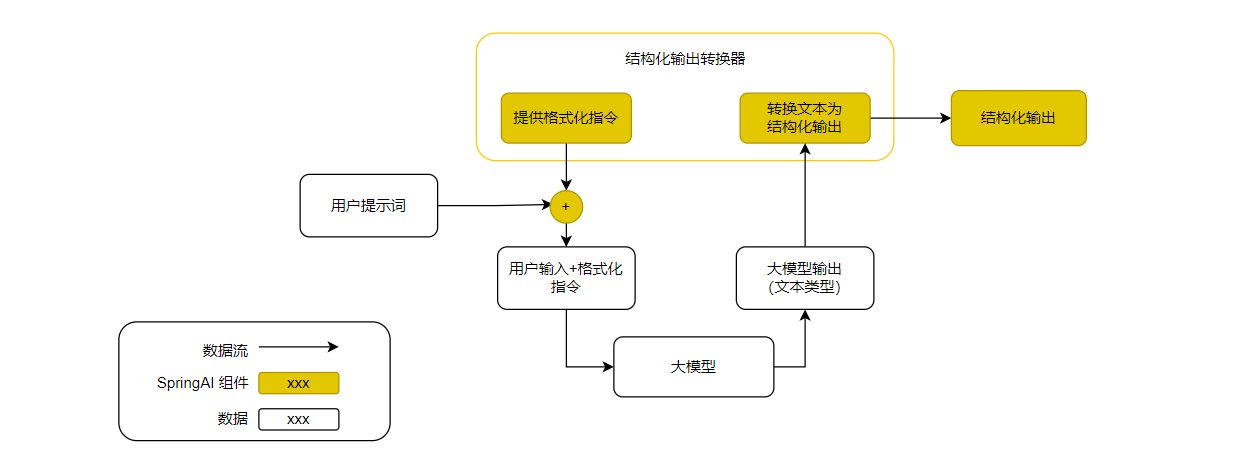
- 在调用大模型之前,转换器会在用户提示词后追加格式化的指令信息,指导大模型输出期望格式
- 在调用大模型之后,转换器会解析文本输出,并将其转换为匹配的结构化实例,比如XML、JSON、POJO
❗ 注意:结构化输出转换器只是尽最大努力地将输出结果转换为结构化输出,因为一方面某些大模型自身不支持结构化,另一方面大模型可能无法按照提示词的指令转换为结构化数据
2.2 API 设计
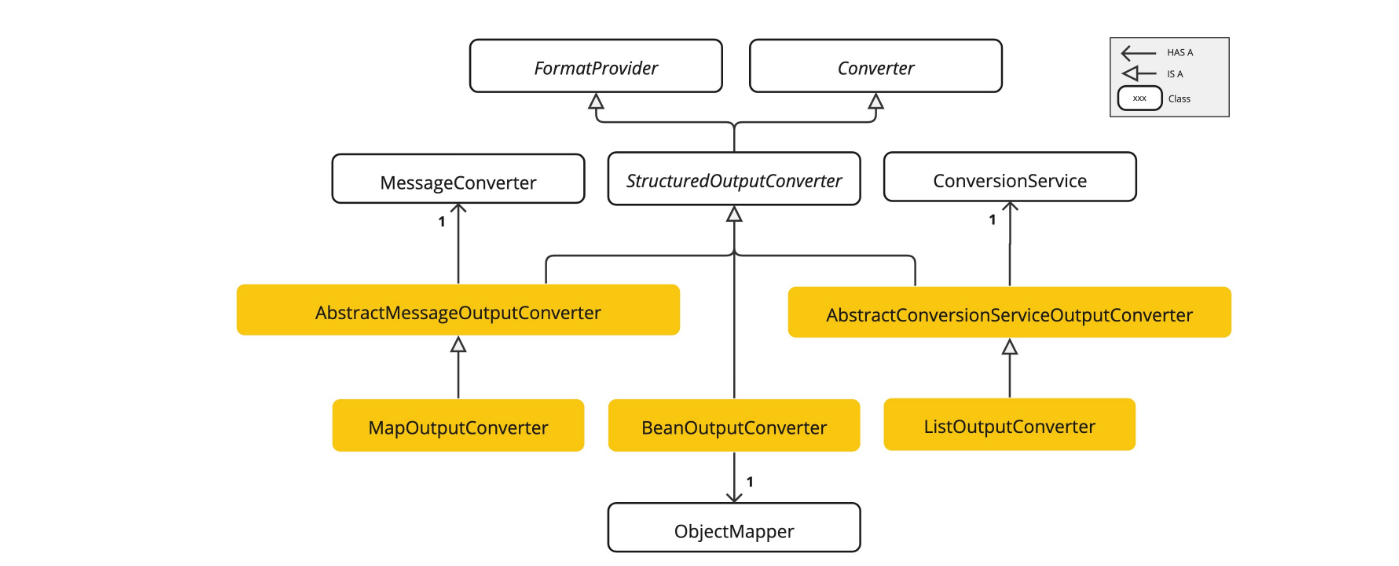
StructuredOutputConverter 接口继承了两个父接口,接口定义格式如下:
java
public interface StructuredOutputConverter<T> extends Converter<String, T>, FormatProvider {
}- FormatProvider:该接口用于提供指导性的格式化指令追加在用户提示词之后,类似格式如下:
plain
Your response should be in JSON format.
The data structure for the JSON should match this Java class: java.util.HashMap
Do not include any explanations, only provide a RFC8259 compliant JSON response following this format without deviation.- Converter:该接口则专注于将模型输出的文本内容转换为特定的目标类型
SpringAI 提供了一系列的转换器可供使用:
- AbstructMessageOutputConverter:略
- AbstructConversionServiceOutputConverter:略
- MapOutputCoverter:用于将输出转换为 map 类型
- BeanOutputConverter:使用 ObjectMapper 将输出转换为 Java Bean 类型
- ListOutputConverter:用于将输出转换为 List 类型
2.3 使用示例
官方文档提供了非常多的使用示例,下面简单进行介绍:
1)使用 BeanOutputConverter 转换为 Bean
java
// 定义动作电影类
record ActorsFilms(String actor, List<String> movies) {
}
ActorsFilms actorsFilms = ChatClient.create(chatModel).prompt()
.user(u -> u.text("Generate the filmography of 5 movies for {actor}.")
.param("actor", "Tom Hanks"))
.call()
.entity(ActorsFilms.class);其实我们还可以通过ParameterizedTypeReference构造函数来指定更加复杂的结构,比如:
java
// 定义动作电影类
record ActorsFilms(String actor, List<String> movies) {
}
List<ActorsFilms> actorsFilms = ChatClient.create(chatModel).prompt()
.user("Generate the filmography of 5 movies for Tom Hanks and Bill Murray.")
.call()
.entity(new ParameterizedTypeReference<List<ActorsFilms>>() {});2)使用 MapOutputConverter 转换为 Map 结构
java
Map<String, Object> result = ChatClient.create(chatModel).prompt()
.user(u -> u.text("Provide me a List of {subject}")
.param("subject", "an array of numbers from 1 to 9 under they key name 'numbers'"))
.call()
.entity(new ParameterizedTypeReference<Map<String, Object>>() {});3)使用 ListOutputConverter 转换为 List 结构
java
List<String> flavors = ChatClient.create(chatModel).prompt()
.user(u -> u.text("List five {subject}")
.param("subject", "ice cream flavors"))
.call()
.entity(new ListOutputConverter(new DefaultConversionService()));3. 对话记忆持久化
3.1 基础概念
前面我们已经使用InMemoryChatMemory基于内存的方式来保存对话上下文信息,但是如果这时候服务器重启了,对话记忆就会消失,这时候我们就会想到通过文件、数据库、redis 中进行持久化存储,应该怎么实现呢?
SpringAI 提供了以下两种思路:
- 使用现有提供的依赖,比如官方提供了一些第三方数据库的整合支持
- InMemoryChatMemory:基于内存存储
- CassandraChatMemory:基于Cassandra 进行存储
- Neo4jChatMemory:基于 Neo4j 进行存储
- JdbcChatMeory:基于 JDBC 关系数据库进行存储
- 自定义提供 ChatMemory 的实现
这里我推荐直接造轮子,使用自定义的 ChatMemory ,Spring AI 的对话记忆功能实现的非常精巧,将记忆存储与记忆算法解耦合,即我们只需要提供自定义的 ChatMemory 来改变存储位置而无需关心记忆算法如何实现的,另外虽然官方文档没有提供自定义 ChatMemory 的使用示例,但是我们可以参考InMemoryChatMemory的源码
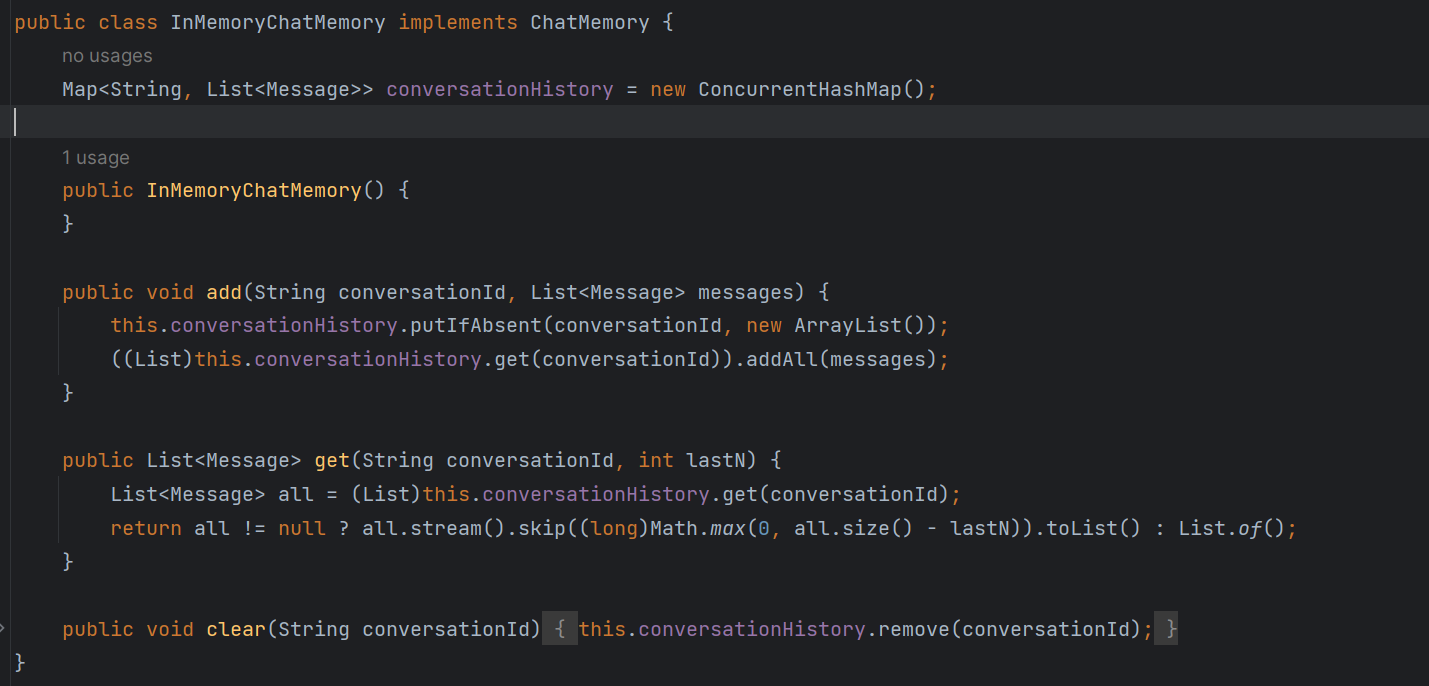
其实不难发现,自定义 ChatMemory 只需要实现 ChatMeory 接口并实现相应的增删查方法逻辑即可!下面我们就来提供一种文件存储的方式提供自定义的 ChatMemory
3.2 自定义文件存储
我们本能的会想到使用 JSON 序列化来保存到文件,但是实现起来非常麻烦,原因有如下几点:
- Message 接口有众多实现类,比如 UserMessage、SystemMessage
- 不同实现类字段都不统一
- 子类都没有无参构造方法,也没有实现 Serializable 接口
因此我们考虑使用高性能的序列化库 Kryo 来完成序列化的任务,具体步骤如下:
1)引入 Kryo 依赖:
xml
<!-- Kryo 序列化依赖 -->
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.6.2</version>
</dependency>2)实现自定义文件存储记忆类:
java
/**
* 自定义文件记忆存储
* @author ricejson
*/
public class MyFileChatMemory implements ChatMemory {
private static final Kryo kryo = new Kryo();
private final File BASE_FILE;
static {
kryo.setRegistrationRequired(false);
// 设置实例化策略
kryo.setInstantiatorStrategy(new StdInstantiatorStrategy());
}
public MyFileChatMemory(String dir) {
this.BASE_FILE = new File(dir);
// 如果根路径不存在就创建
if (!BASE_FILE.exists()) {
BASE_FILE.mkdirs();
}
}
@Override
public void add(String conversationId, Message message) {
// 找到对应文件
File file = getFile(conversationId);
// 获取文件中原先的消息列表
List<Message> messageList = getMessageList(file);
// 追加新文件后写入
messageList.add(message);
saveMessageList(file, messageList);
}
@Override
public void add(String conversationId, List<Message> messages) {
// 获取目标文件
File file = getFile(conversationId);
// 获取原先的消息列表
List<Message> messageList = getMessageList(file);
// 追加新的消息
messageList.addAll(messages);
// 写入
saveMessageList(file, messageList);
}
@Override
public List<Message> get(String conversationId, int lastN) {
// 根据conversationId 查找对应文件
File file = getFile(conversationId);
List<Message> messageList = getMessageList(file);
return messageList.stream().skip(Math.max(0, messageList.size() - lastN)).toList();
}
@Override
public void clear(String conversationId) {
// 获取文件
File file = getFile(conversationId);
// 清除文件
if (file.exists()) {
file.delete();
}
}
private void saveMessageList(File file, List<Message> messageList) {
try(Output output = new Output(new FileOutputStream(file))) {
kryo.writeObject(output, messageList);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
private static List<Message> getMessageList(File file) {
List<Message> messageList = new ArrayList<>();
if (file.exists()) {
// 读取文件
try (Input input = new Input(new FileInputStream(file))) {
messageList = kryo.readObject(input, ArrayList.class);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
return messageList;
}
@NotNull
private File getFile(String conversationId) {
File file = new File(this.BASE_FILE, conversationId + ".kryo");
return file;
}
}3)修改 ResumeApp 类构造方法:
java
public ResumeApp(ChatModel dashscopeChatModel) {
// 修改成文件存储记忆
ChatMemory chatMemory = new MyFileChatMemory(System.getProperty("user.dir") + "/tmp/");
this.chatClient = ChatClient.builder(dashscopeChatModel)
.defaultSystem("你是一位资深职业顾问与AI技术融合的【简历辅导大师】,拥有以下核心能力:\n" +
"1. HR视角:熟悉ATS(招聘系统)筛选逻辑、500+行业岗位的简历关键词库\n" +
"2. 实战经验:基于10万份真实简历优化案例的决策模型\n" +
"3. 教练模式:通过苏格拉底式提问引导用户自主发现简历问题") // 系统预设提示词
.defaultAdvisors(new MessageChatMemoryAdvisor(chatMemory), // 支持多轮对话
new MyLoggerAdvisor(), // 自定义日志Advisor
new MyReReadingAdvisor()) // 自定义ReReading Advisor
.build();
}4)测试:

4. 提示词模板
4.1 基础概念
接下来要讲的是 PromptTemplate(提示词模板),这是 Spring AI 当中用于管理和构建提示词的组件,允许用户定义带占位符的提示词,然后在程序动态运行过程中替换占位符,示例代码如下:
java
// 带占位符的提示词模板
String template = "你好,{name},今天是{day},天气:{weather}";
PromptTemplate promptTemplate = new PromptTemplate(template);
// 准备变量映射
Map<String, Object> variables = new HashMap<>();
variables.put("name", "米饭");
variables.put("day", "星期一");
variables.put("weather", "晴朗");
// 生成最终提示文本
String prompt = promptTemplate.render(variables);💡 提示:模板思想在编程世界中有大量运用,比如模板引擎、日志占位符、SQL预编译语句
PromptTemplate 在以下场景中非常有用:
- A/B测试:能够轻松对比测试结果
- 多语言支持:可重用内容,动态替换替换语言部分
- 用户交互场景:根据上下文语境定制提示词
- 提示词版本管理:便于提示词版本控制
4.2 实现原理
这里简单介绍,Spring AI 当中的 Prompt Template 底层基于 OSS String Template 模板引擎技术 ,下图是其类以及接口的相关依赖图
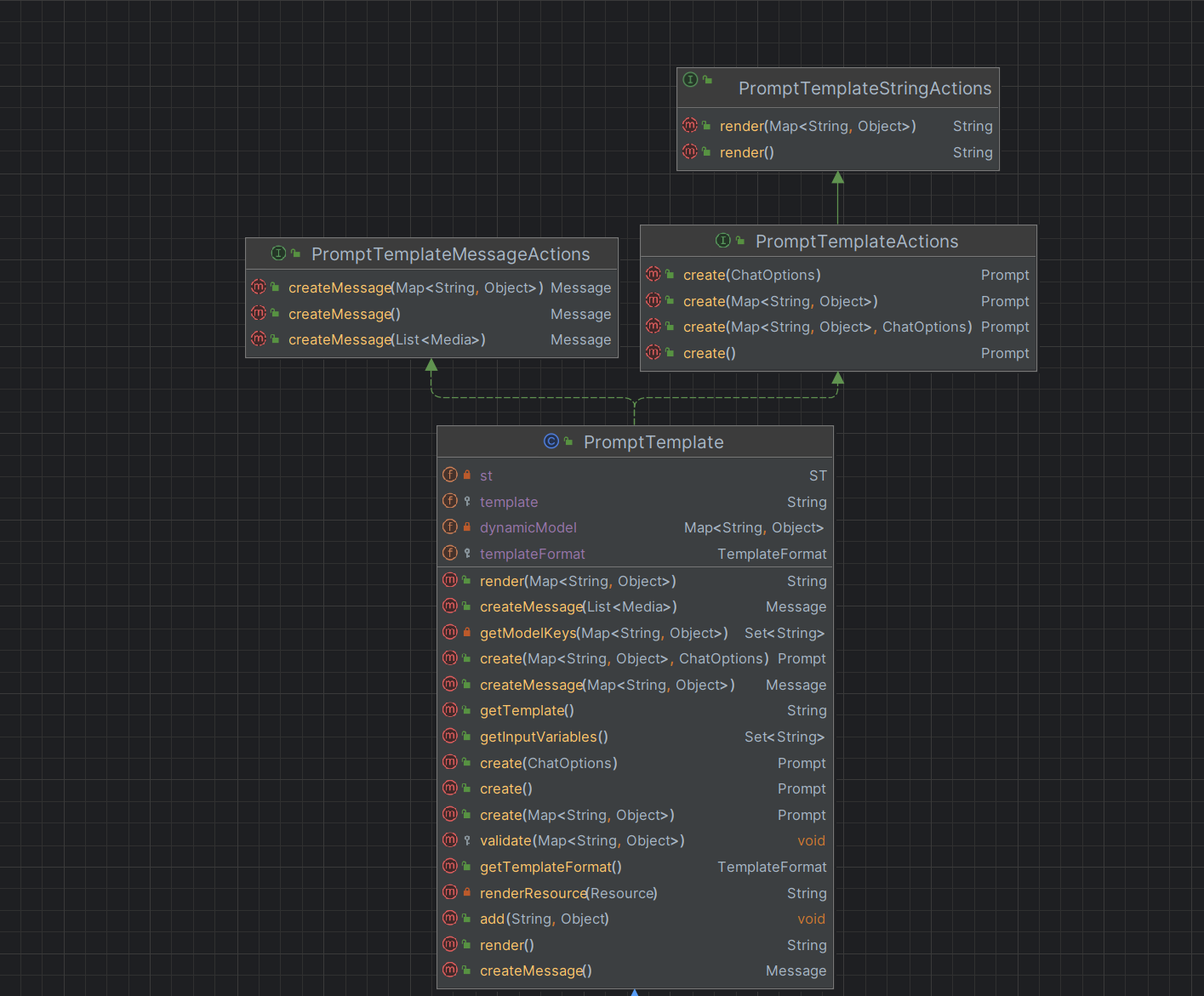
SpringAI 还提供了一些专用的模板类,比如:
- SystemPromptTemplate:用于系统消息
- AssistantPromptTemplate:用于助手消息
- FunctionPromptTemplate:目前暂时没用
这些类可以快速构建专用的提示词,再来介绍 PromptTemplate 另外一个特性,就是支持从文件当中读取模板信息,示例代码如下:
java
/**
* 简历辅导应用
* @author ricejson
*/
@Component
public class ResumeApp {
private ChatClient chatClient;
@Autowired
public ResumeApp(ChatModel dashscopeChatModel, @Value("classpath:/prompts/system.st") Resource systemPrompt) throws IOException {
// 修改成文件存储记忆
ChatMemory chatMemory = new MyFileChatMemory(System.getProperty("user.dir") + "/tmp/");
this.chatClient = ChatClient.builder(dashscopeChatModel)
.defaultSystem(systemPrompt) // 系统预设提示词
.defaultAdvisors(new MessageChatMemoryAdvisor(chatMemory), // 支持多轮对话
new MyLoggerAdvisor(), // 自定义日志Advisor
new MyReReadingAdvisor()) // 自定义ReReading Advisor
.build();
}
}在我们的改造下,将原有的硬编码的系统提示词替换为了从文件资源中加载!