目录
单例模式
单例模式是一种设计模式,用于解决分工协作的问题
单例,一个程序(进程中)唯一实例
设计模式相当于大佬给了一个模版(套路),按照这个模板写,代码效率能比较高
它能解决一些固定场景的固定套路
设计模式还有很多种,单例模式只是其中之一
单例模式指单个实例(对象)
正常情况下,一个类能创建多个实例,但在有些场景中,我们只希望这个类只有一个实例
饿汉模式
饿汉模式是线程安全的
饿汉模式实现:
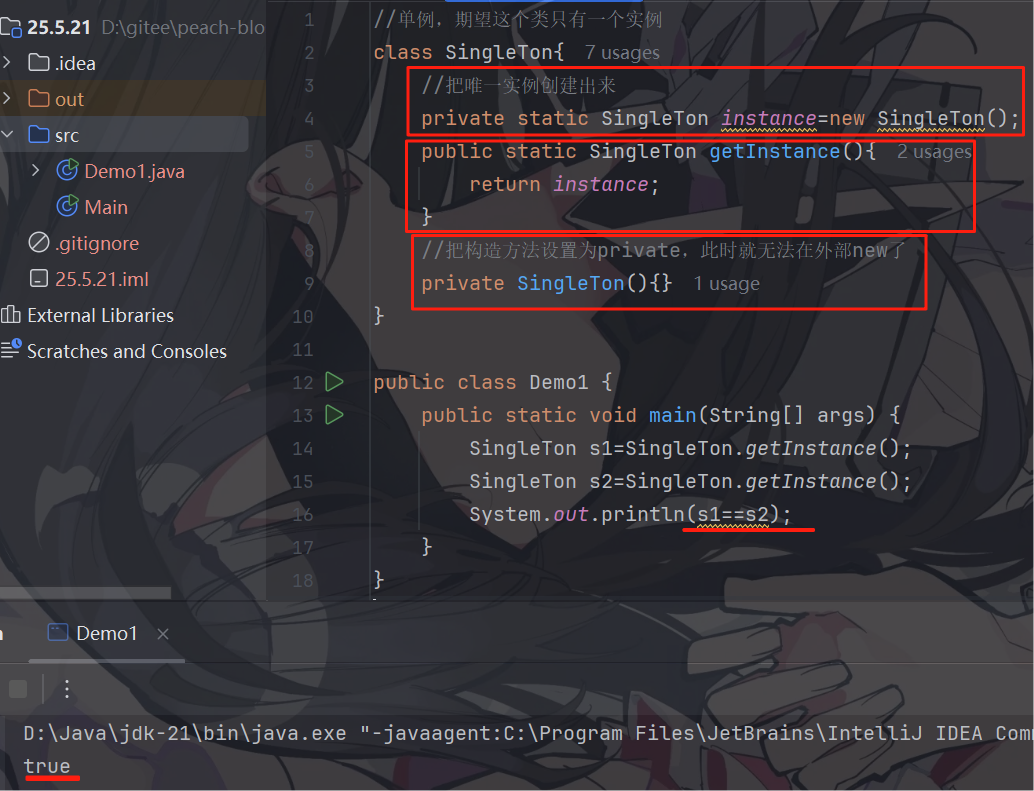
由于此处instance 是一个 static 成员,创建时机就是在类加载的时候(近似理解为程序一启动),常见紧迫
懒汉模式---单线程版
它是线程不安全的,如果有多个线程调用getInstance ,多个判定==null,可能会创建多个实例
getInstance 可能会出现多个线程对同一个变量进行修改,而如果只是读取,就是线程安全的(饿汉模式)
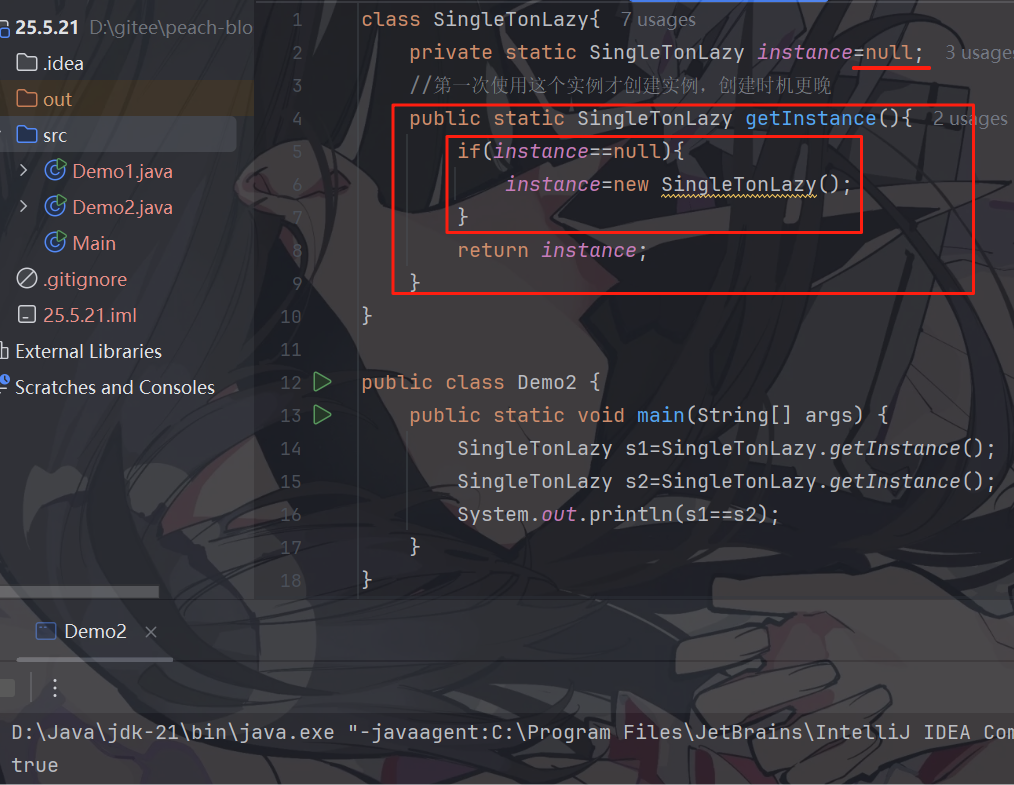

实际开发中,单例类的构造方法可能是一个非常重量的方法,如果多次触发这个bug,就会浪费好几分钟的时间(加载时间翻倍)
懒汉模式就好比非必要不洗碗
假设有一个非常大的文件(几个GB)
要打开这个文件查看内容,两个方案
1.把整个文件都加载到内存里,然后再给用户显示(饿汉模式)
2.值加载文件的一小部分,就立即给用户显示,随着用户的翻页操作,在加载对应部分数据(懒汉模式)
饿汉模式会让用户使用前等待一段时间(明显卡顿),懒汉模式则不需要,因此懒汉模式泛用更广
懒汉模式---多线程版(经典面试题)
对上述代码改动
显然不可以
上面单线程的问题是判定null 的时候就出现问题了,所以应该把判定null 和加锁操作打包成一个原子
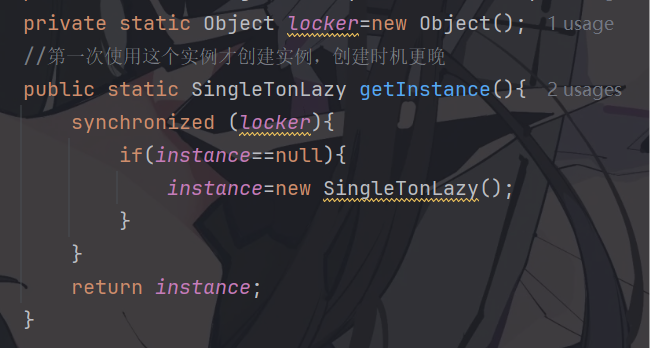
上述创建实例只在线程第一次调用的时候才涉及到线程安全问题 ,但是上面代码在每次调用 getInstance 都加了一次锁,显然很耗费资源,所以还要进行一次变动
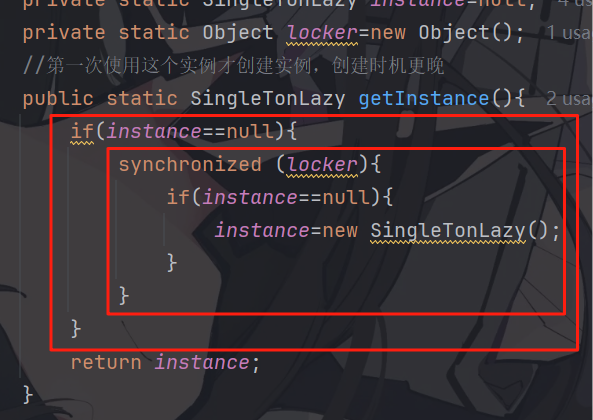
为什么会出现一模一样的线程,连续写两遍?
在之前,都是按照单线程来编写代码,这个代码执行下来,第一次判定和第二次判定的结论是一定相同的,但是现在是多线程模式了,第一次判定和第二次判定,结论可以不同
因为在第一次和第二次判定之间,可能有另一个线程修改了 instance
4.指令重排序引起的线程安全问题
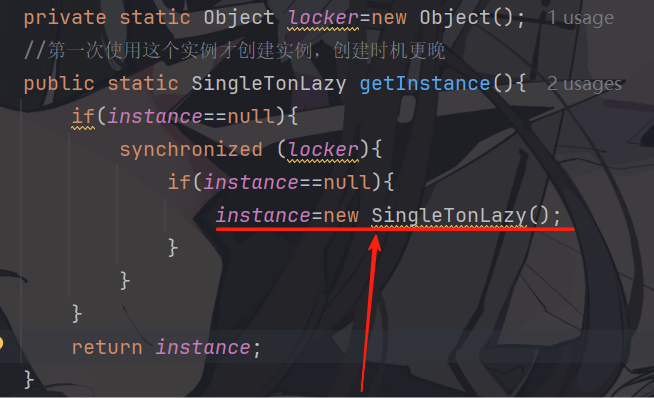
还是之前的代码,上述new 操作设计到的指令是非常多的,为了简化这个模型,我们分成三步:
1. 申请内存空间
2. 在内存空间上进行初始化(构造方法)
3. 内存地址,保存到引用变量中(instance)
在内部操作中,步骤可能是按照1 2 3 执行,也可能是按照1 3 2 执行
就像
1.买一个房子
2.装修
3.交钥匙
2和3可以随意交换

虽然 t1 此时持有锁,但是由于 t2 没有进行加锁操作,t2 不会有任何阻塞,直接返回了
解决方法:volatile
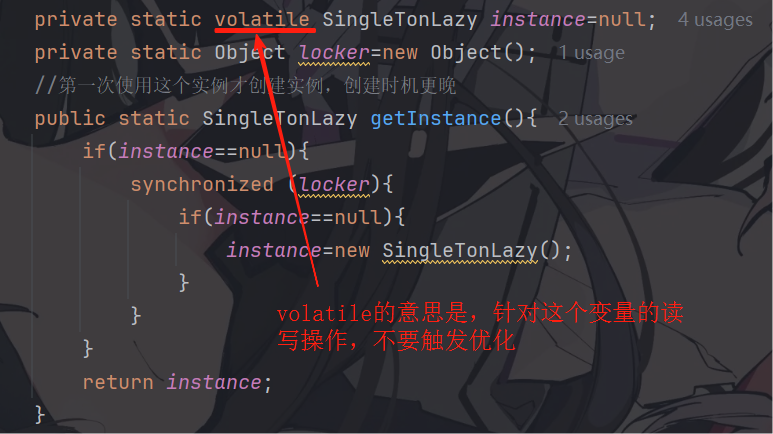
经典面试题:
- 加锁的原因
- 第二次判断非空的原因
- 加volatile 的原因
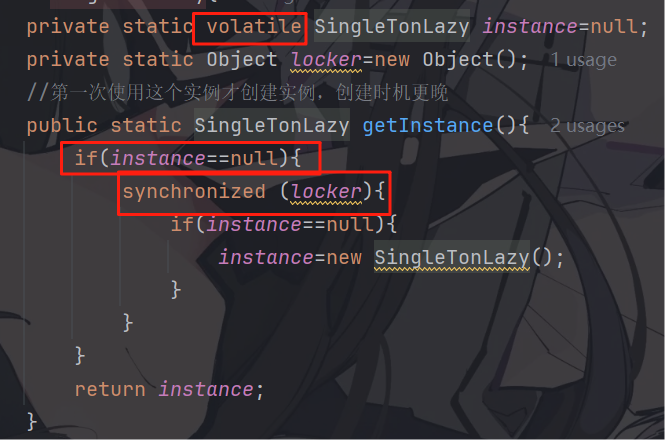
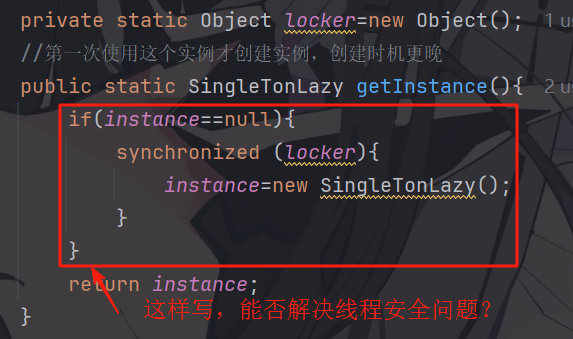
懒汉模式---多线程版(改进)
java
class SingleTonLazy{
private static volatile SingleTonLazy instance=null;
private static Object locker=new Object();
//第一次使用这个实例才创建实例,创建时机更晚
public static SingleTonLazy getInstance(){
if(instance==null){
synchronized (locker){
if(instance==null){
instance=new SingleTonLazy();
}
}
}
return instance;
}
}阻塞队列
阻塞队列是什么
阻塞队列是一种特殊的队列,它也是先进先出的
与其他队列相比,它的特点:
1 线程安全
2. 带有阻塞功能
1.如果队列为空,尝试出队列,会触发阻塞,直到队列不空
2.如果队列满了,尝试入队列,也会触发阻塞,直到队列不满
阻塞队列的⼀个典型应⽤场景就是"⽣产者消费者模型".这是⼀种⾮常典型的开发模型
生产者消费者模型
⽣产者消费者模式就是通过⼀个容器来解决⽣产者和消费者的强耦合问题
⽣产者和消费者彼此之间不直接通讯,⽽通过阻塞队列来进⾏通讯,所以⽣产者⽣产完数据之后不⽤
等待消费者处理,直接扔给阻塞队列,消费者不找⽣产者要数据,⽽是直接从阻塞队列⾥取.
比如加工出一个食物,加工者就是生产者,吃(消耗)这个食物的人就是消费者
像"食物" 就要有存放的地方,用于存储和消耗,阻塞队列就起到了这个作用
引入生产者消费者模型目的是为了减少"锁竞争"
因为生产者和消费者的步调不一定完全一致,通过阻塞队列就能协调好两者关系
生产者消费者模型优点:
- 减少资源竞争,提高效率
- 可以更好做到模块之间的解耦合
例如 A服务器要传给 B服务器 某个信息,可以通过阻塞队列存储信息,然后让B服务器自己去拿,这样耦合度就降低了,B变动,A就不需要修改- 削峰填谷
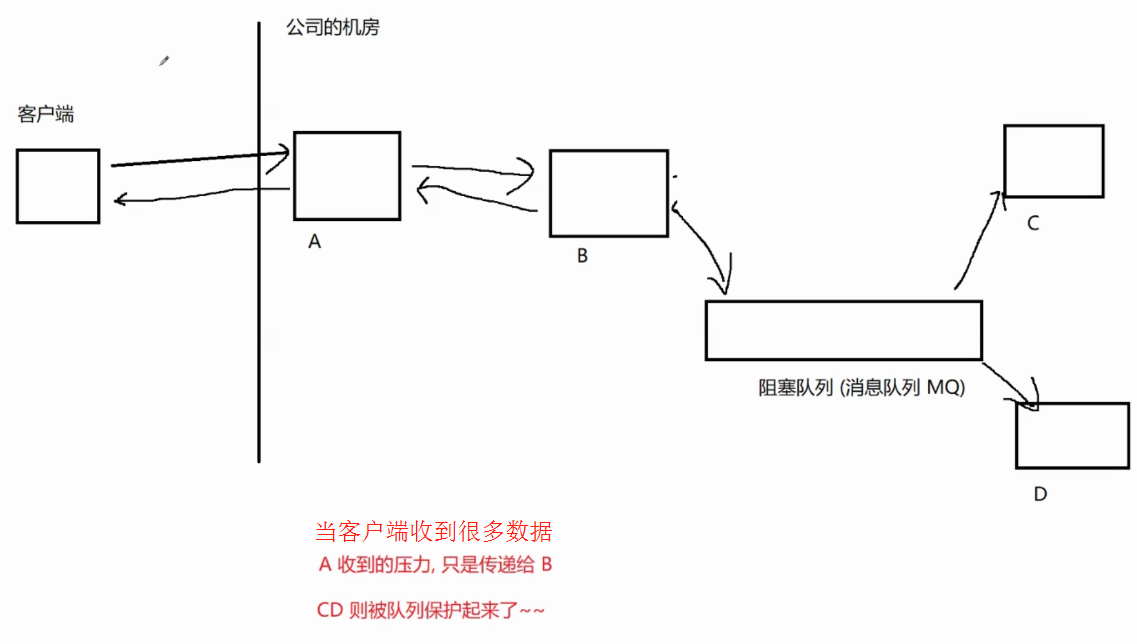
但是这个模型还有一些缺点
1.系统结构更复杂
2.引入队列的层数太多,效率会受到影响
标准库中的阻塞队列-BlockingQueue
因为BlockingQueue 是一个接口interface ,因此不能实例new这个队列,而是实例化继承了这个队列的类
java
BlockingQueue<String> queue=new LinkedBlockingQueue<>();
//基于链表实现的阻塞队列
BlockingQueue<String> queue1=new ArrayBlockingQueue<>(100);
//基于数组实现的阻塞队列,它必须指定容量入队列和出队列:
注意 :虽然BlockingQueue 有offer,add等方法,但是这些方法不带有"阻塞功能"
java
queue.put("123");//入队列
String s=queue.take();//出队列观察阻塞队列:
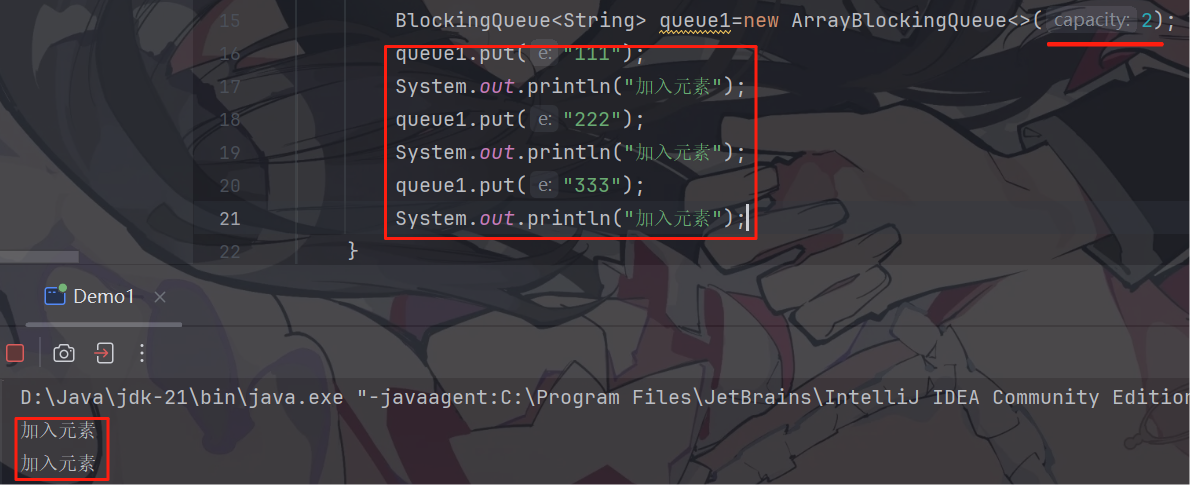
因为队列最大容量只有2,如果再入队列,就会触发阻塞了,take() 同理
阻塞队列使用:
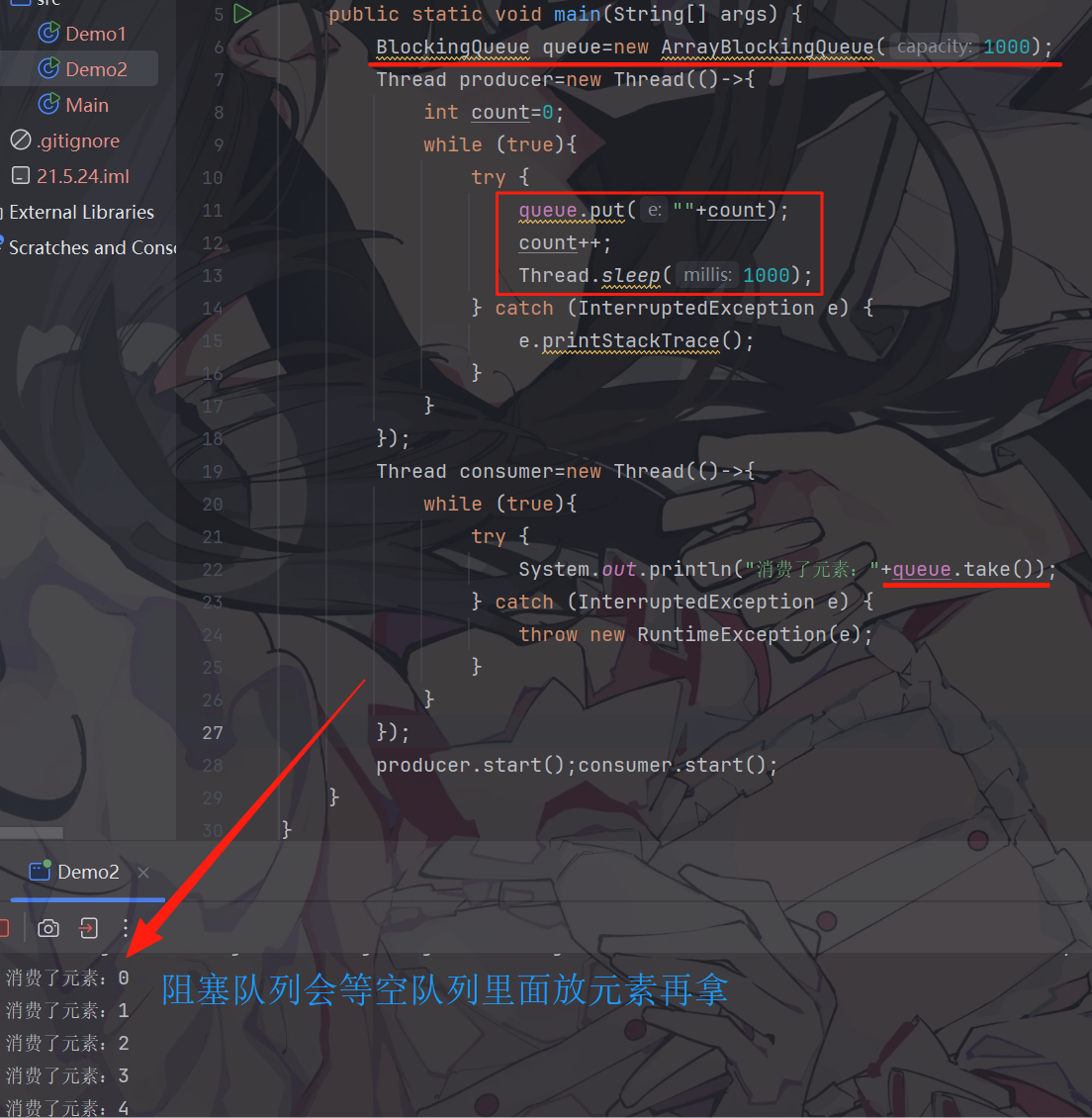
阻塞队列实现
java
/假设元素类型是String
//基于数组实现队列
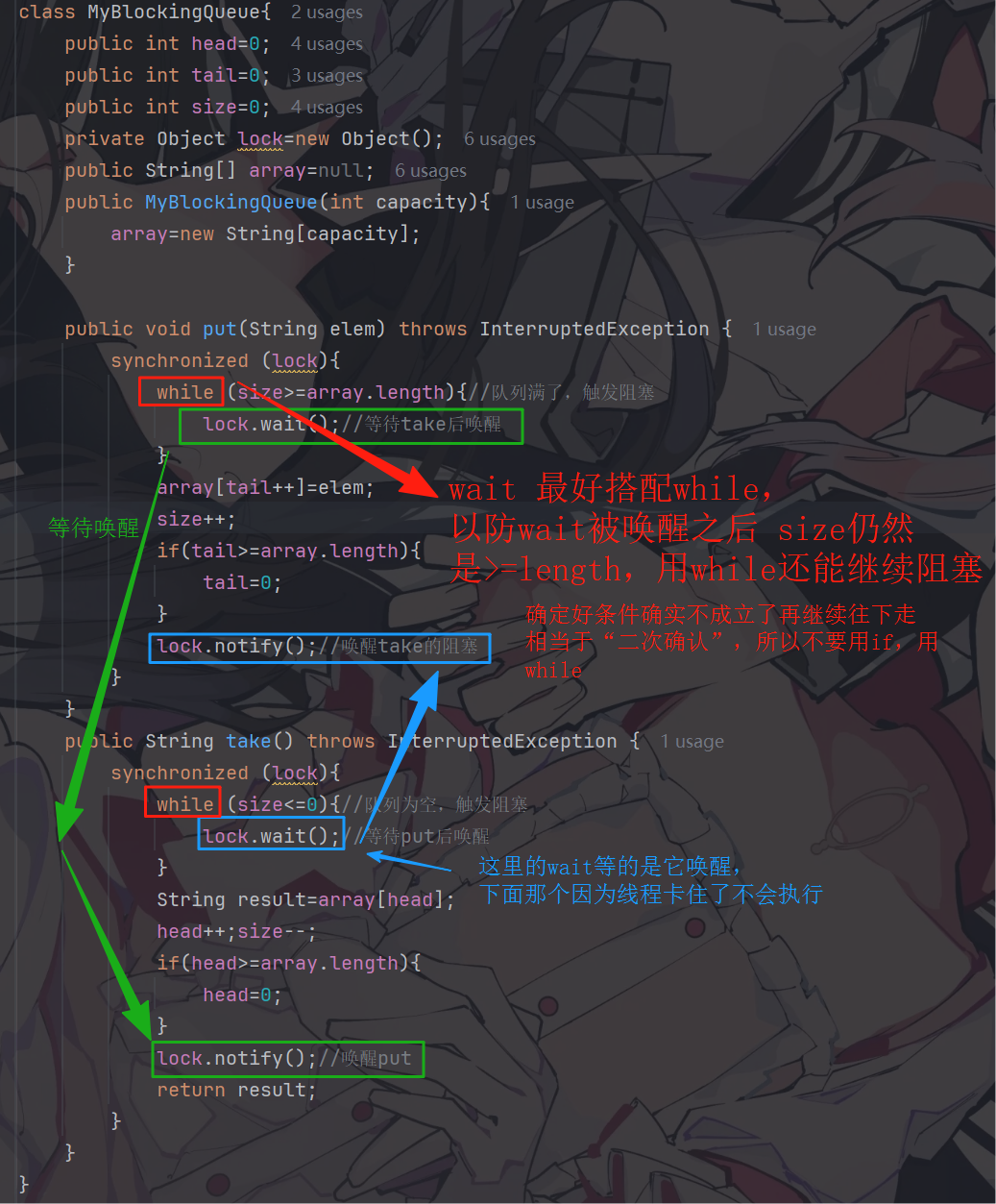
class MyBlockingQueue{
public int head=0;
public int tail=0;
public int size=0;
private Object lock=new Object();
public String[] array=null;
public MyBlockingQueue(int capacity){
array=new String[capacity];
}
public void put(String elem) throws InterruptedException {
synchronized (lock){
while (size>=array.length){//队列满了,触发阻塞
lock.wait();//等待take后唤醒
}
array[tail++]=elem;
size++;
if(tail>=array.length){
tail=0;
}
lock.notify();//唤醒take的阻塞
}
}
public String take() throws InterruptedException {
synchronized (lock){
while (size<=0){//队列为空,触发阻塞
lock.wait();//等待put后唤醒
}
String result=array[head];
head++;size--;
if(head>=array.length){
head=0;
}
lock.notify();//唤醒put
return result;
}
}
}此处有几个注意事项: