文章目录
- 🌇前言
- 1、磁盘文件
- 2、磁盘概念
- 2.2、数据存储
- 3、磁盘信息
- 4、文件相关操作
-
- 4.1、文件创建
- 4.2、文件访问
- 4.3、对文件进行增删查改
- [4.4 dentry树结构](#4.4 dentry树结构)
- [4.5 挂载分区](#4.5 挂载分区)
- [4.6 大文件存储](#4.6 大文件存储)

🌇前言
文件分为 内存文件 和 磁盘文件,内存文件 相关知识前面已经介绍过了,接下来谈谈 磁盘文件,这是一个特殊的存在,因为它不属于冯诺依曼体系,而是位于专门的存储设备中,因此 磁盘文件 存在的意义是将文件更好的存储起来,以便后续对文件进行访问。在高效存储 磁盘文件 这件事上,前辈们研究出了十分巧妙的管理手段及操作方法,而这些手段和方法共同构成了我们今天所谈的 文件系统

注: 本文主要介绍对象为机械硬盘存储模式及 EXT 文件系统
🏙️正文
1、磁盘文件
在计算机中,没有被打开的文件都是静静的躺在外存(磁盘)中,当需要对文件进行操作时,会通过inode对文件进行访问
通过以下指令查看当前目录中文件的详细信息及 inode 值
bash
ll -i
这个就是inode的值
如同 pid 与进程的唯一对应性一样,inode 与文件也是唯一对应的(未被硬链接的情况下),可以通过inode访问文件在磁盘中的详细信息
磁盘文件是如何进行管理的?
- 磁盘文件的管理类似于菜鸟驿站,其中的包裹就像待访问的文件,而
inode就是取件码 - 得益于这种规范化的存储模式,我们可以做到对文件的快速定位、快速读取和快速写入
2、磁盘概念
现在市面上的磁盘主要分为 机械硬盘 和 固态硬盘,前者读取速度慢,但便宜、稳定;后者读取速度快,但价格高昂且数据易损,两者各有其应用场景,本文主要介绍的是 机械硬盘
2.1、基本结构
机械硬盘是我们电脑中的唯一一个机械设备,并且它还是一个外设 ,根据 冯诺依曼体系结构,机械硬盘 在速度上远远慢于 CPU 和 内存
举例机械硬盘有多慢
- 假设 CPU 运行速度是纳秒级,那么内存就是微秒级,而机械硬盘只不是是毫秒级
为何 机械硬盘 如此慢?这与它的结构有很大关系
机械硬盘 的结构主要包括以下几种:
- 盘片:一片两面,每一面都可以存储数据,有一摞盘片
- 磁头:一面配备一个磁头,专门用于读取盘面中的数据
- 主轴:用于控制整块盘的转动
- 音圈马达:控制磁头的进退
- 磁头臂:链接磁头与音圈马达
- 伺服电路板:控制读取数据的流向及各种结构的运行
...... - 注意: 多个盘片、多个磁头都是共进退的
机械设备 控制是需要时间的,因此导致机械硬盘读写数据速度相对于 CPU 和内存来说比较慢

2.2、数据存储
总所周知,数据是以 0 和 1 的方式进行存储的,常见的存储介质有:强信号与弱信号、高电平与低电平、波峰与波谷、南极与北极 等,而盘面上比较适合的是 南极与北极
当磁头移动到指定位置时
- 向磁盘写入数据:N->S
- 删除磁盘中的数据:S->N
磁盘中读写的本质:更改基本元素的南北极、读取南北极
注意: 磁头并非与盘面进行直接接触,而是以 15 纳米的超低距离进行磁场更改
这个距离相当于一架波音747距离地面1米进行超低空飞行,所以如果磁头制作工艺不够精湛,可能会导致磁头在写入/读取数据时,与盘面发生摩擦(高速旋转)发热,从而导致磁场消失,该扇区失效,数据丢失
机械硬盘 不能在其运行时随意移动,因为角度的偏转也有可能导致发生摩擦,造成数据丢失,更不能用力拍打 机械硬盘
在盘面设计上,一个盘面被切割若干个扇区,单个扇区大小为 512 字节(或者 4 kb),这些扇区用来存储数据,同一半径中的所有扇区组成扇面;而半径相同的扇区组成磁道(柱面)
我们可以先根据磁头(head)确定盘面,再根据半径定位磁道(柱面 cylinder),最后根据块号确定扇区(sector)
这种寻址方法称为 CHS 定位法,是机械设备查找具体扇区时的方法
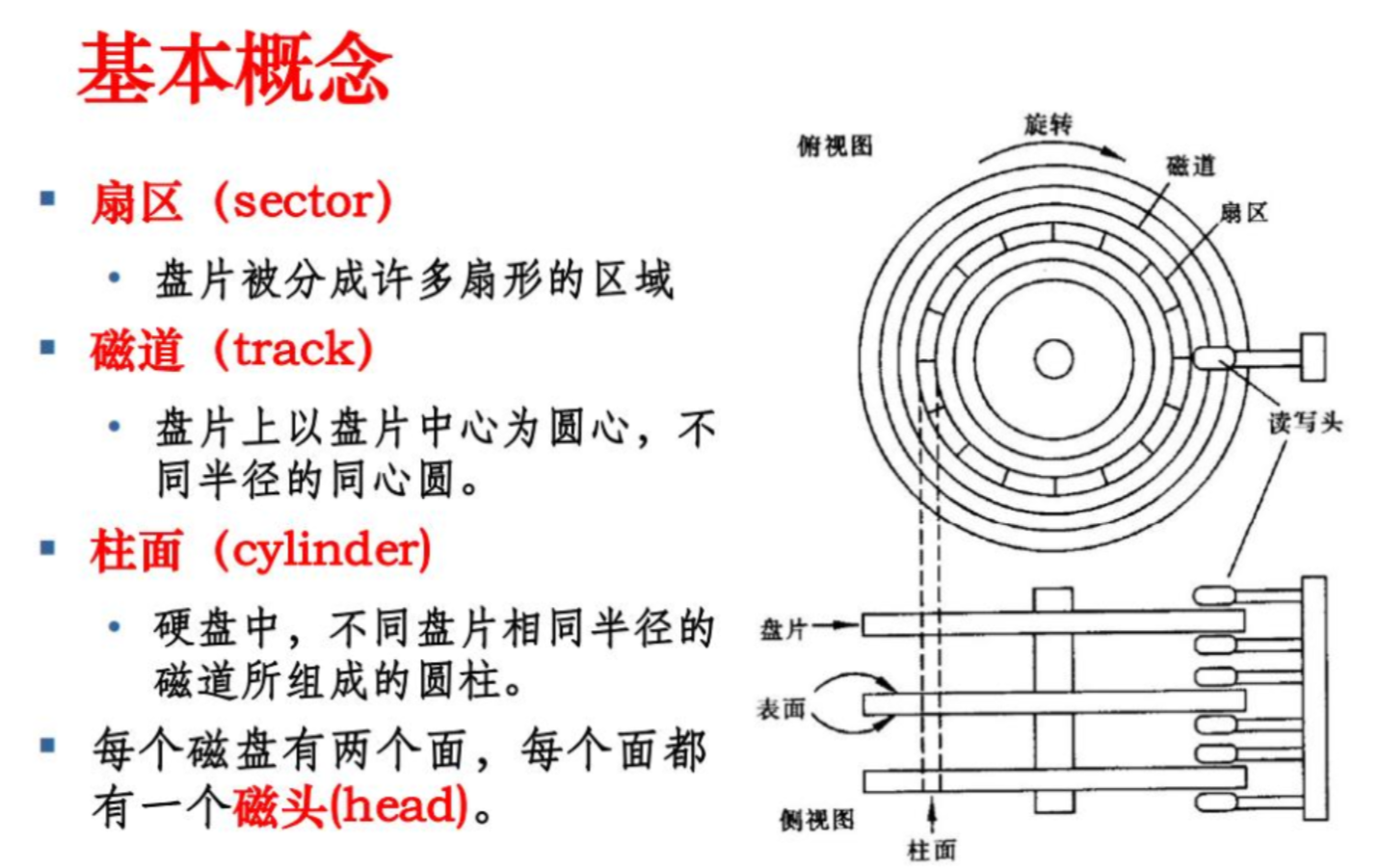
文件(数据+属性)在存储时,占用一个或多个扇区进行数据存储
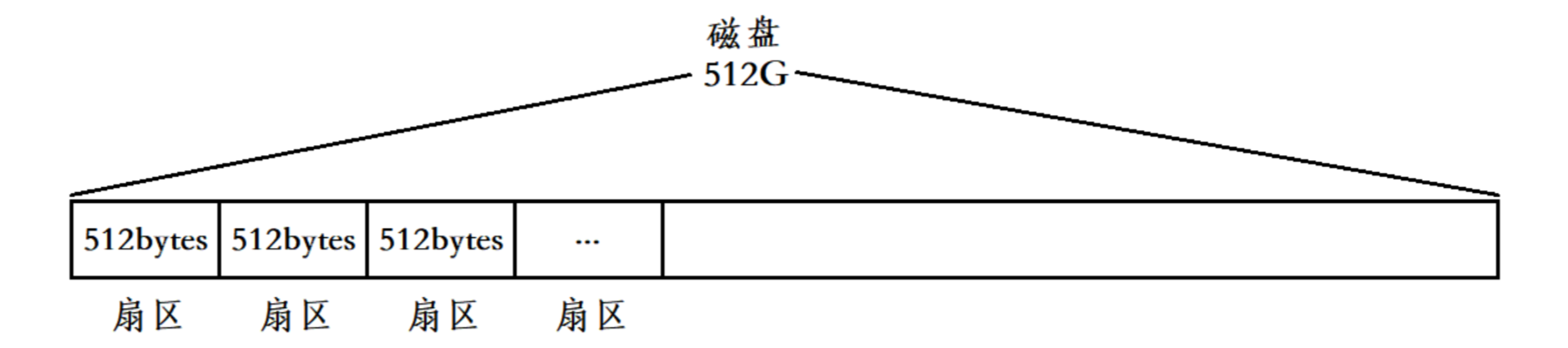
虽然CHS定位法很妙,但它太依赖于具体硬件信息了,假设其中的硬件参数有所不同,那么 OS 就得使用另一套 CHS 定位法,于是为了做到 解耦,OS 使用的并非 CHS 定位法进行文件定位,而是采用 LBA 逻辑地址块进行寻址
- 将盘面分割为多个线性分区,通过下标 N 计算出 CHS 地址,然后进行文件访问
- 将磁道拉长,会得到一串线性空间(数组),其中的每个单位(扇区)为 512 字节(或者 4 kb)
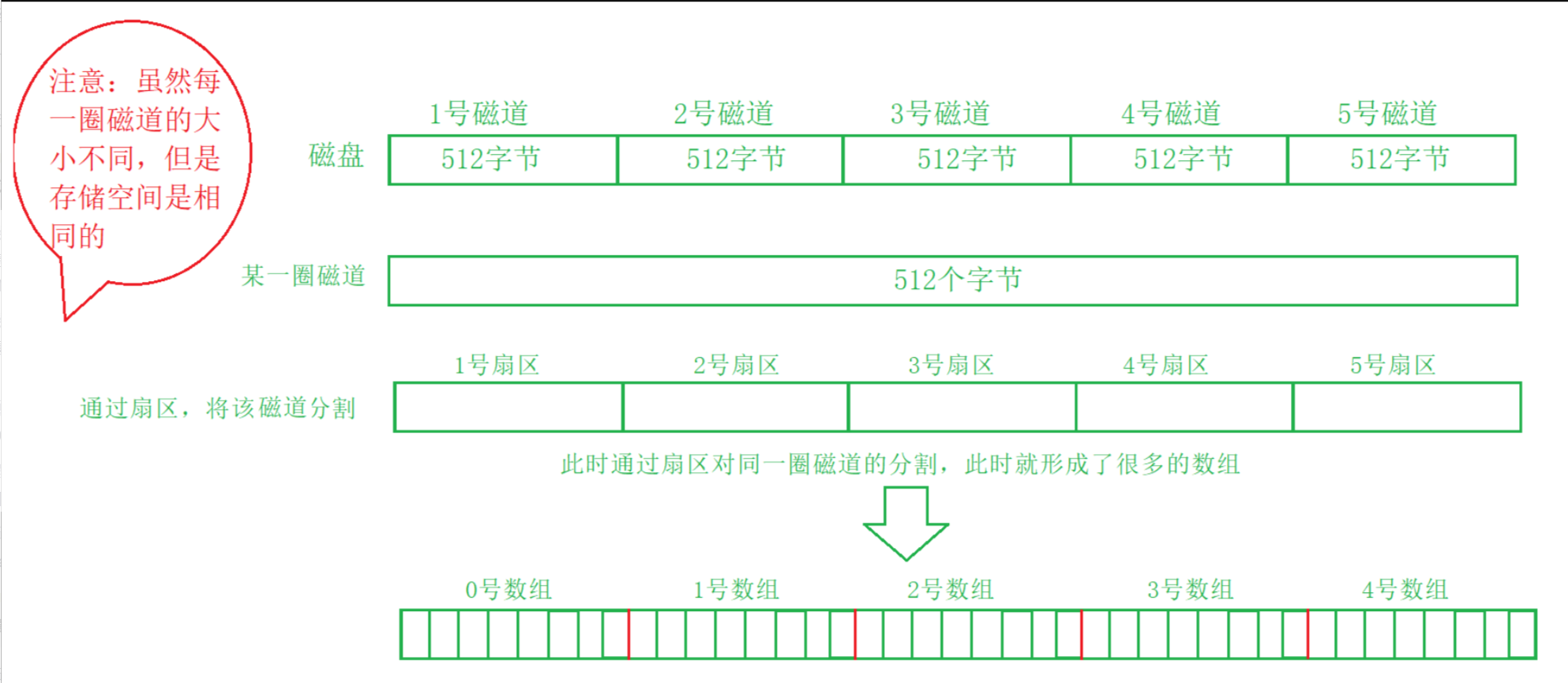
硬盘的每个分区是被划分为⼀个个的"块"。⼀个"块"的⼤⼩是由格式化的时候确定的,并且不可
以更改,最常⻅的是4KB,即连续⼋个扇区组成⼀个 "块"。"块"是⽂件存取的最⼩单位。
现在 OS 想访问具体的扇区时,只需通过 起始扇区的地址 + 偏移量 就可以获取 LBA 地址,然后通过特定手段转为 CHS 地址,交给外设进行访问即可 LBA和CHS转换
-
因此对于外设中文件的管理,经过
先描述,再组织后,变成了对数组的管理,这个数据就是task_struct 中的struct block -
最后我们就能理解为什么 IO 的基本单位是 4 kb 了,因为直接读取一个数据块(4 kb),这样可以提高 IO 效率(内存对齐)
3、磁盘信息
一般电脑中会存在多个分区,比如 C盘、D盘,那么为何需要存在这些分区呢?
3.1、分区意义
磁盘空间是巨大的,如果不加以划分,会导致OS的管理成本提高,对应到现实生活中,学校需要将不同专业的学生及老师分为不同学院,比如管理学院、信息工程学院等,分院后的好处不言而喻,最重要的是上层管理者更好的调用管理资源 ,这种思想称为 分治思想
在文件系统中,OS 先将整个大文件系统分为不同的区,存入struct disk数组中进行管理
bash
struct disk
{
struct part[2];
//......
};可以通过 ll /dev/vda* -i 查看当前系统中的 分区数 及 详细信息

系统在分区后,需要对区块进行格式化
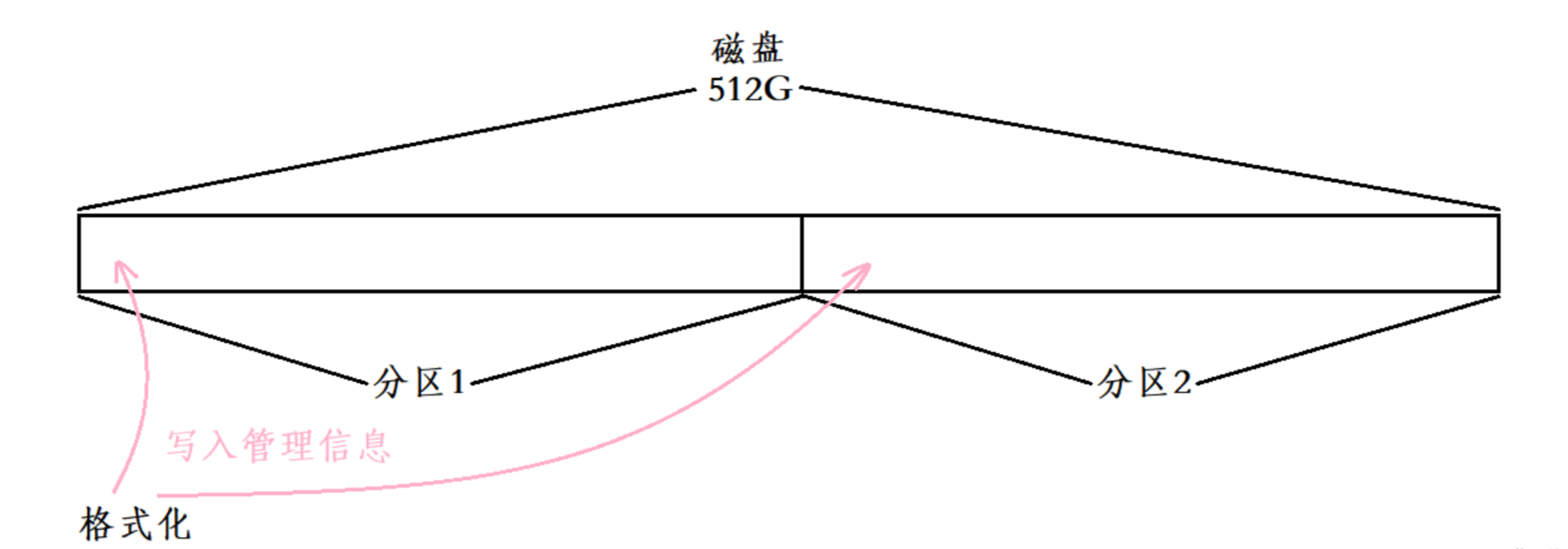
不同的文件系统在格式化时写入的数据是不同的,这里讨论的是 EXT 文件系统
-
磁盘分区后,分组、填写系统属性是
OS做的事 -
为了使分区能被正常使用,需要对分区进行格式化
-
分区格式化:
OS向分区写入文件系统的管理属性信息
在具体分区内,还可以细分为 块组
由 块组 构成的线性空间亦可称为 组线 (代表一个 分区)
bash
struct part
{
struct part group[100]; //分为100个块组
int lba_start; //起始与结束位置
int lba_end;
//......
}将现有资源再分配后,可以 最大化利用资源,避免造成浪费及拖慢效率
块组(Block Group)是本文的重点内容
3.2、块组信息
块组 是由 分区 细分出的产物,它与分区的关系如图所示:
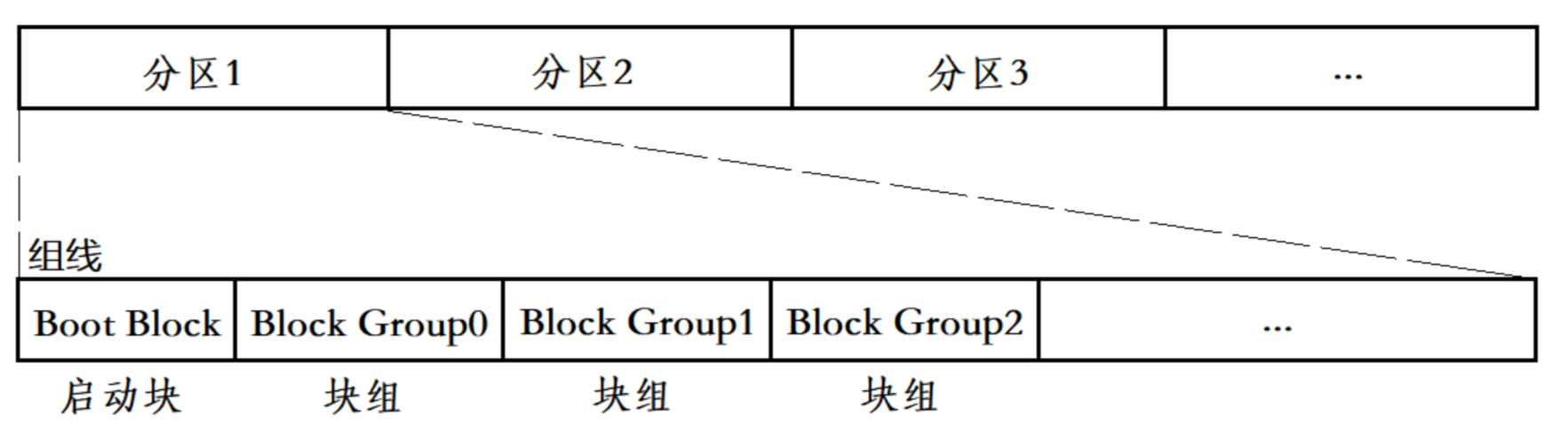
其中, Boot Block 是 启动块,大小固定为 1 kb,在每一条组线前都有此 块组,它用来 存储分区信息和系统启动,属于被保护的内容,不允许用户私自修改
至于其他 块组,它们有着统一的格式,具体内容如图所示:
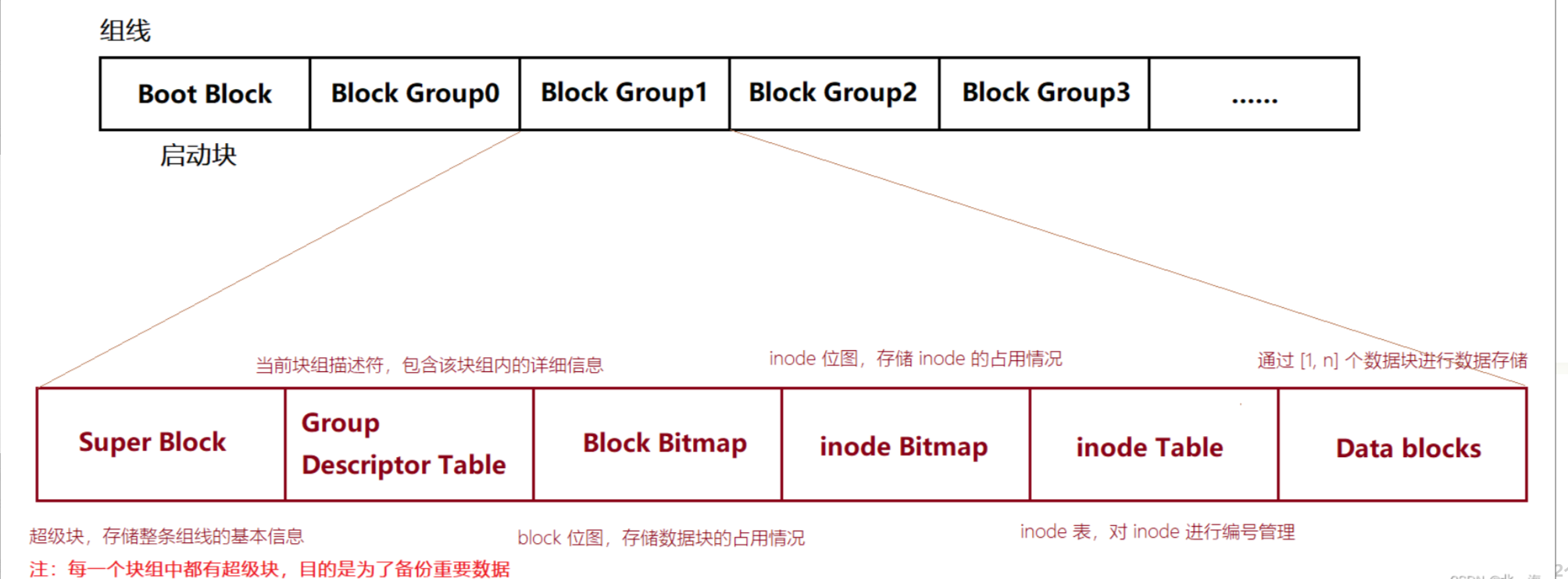
其中一个文件对应一个 inode,而inode中存储了该文件的所有属性,包括所使用的数组块信息,因为文件很多,所以需要 先描述,再组织,即通过 inode Table 对 inode 进行管理
注意:
- inode 属性中并不包含文件名,文件名只是给用户用的
- 目录文件也有 inode,目录中的数据块保存的是该目录下的 文件名 和 inode 编号对应的映射关系,而且在此目录内,文件名和 inode 互为 key 值
- inode 确定分组,
inode值只在一个分区内有效,不能跨分区
4、文件相关操作
接下来看看文件是如何创建在磁盘中的
4.1、文件创建
创建一个文件的步骤如下:
- 申请一个空闲的 inode,将文件信息记录至 inode 属性中
- 寻找空闲的数据块(Data block),将数据块信息填入 inode 中的磁盘分布区
- 添加文件名至当前目录文件的
Data block中,同时将文件名和inode之中的属性链接起来
注意: 每使用一个 inode 和一个 Data block,需要把它们对应位图中的信息改为已占用

创建文件后,生成inode系统标识。
4.2、文件访问
文件创建后,如何根据 inode 访问文件呢?
- 找到文件的
inode编号,在目录分组中查找 - 通过
inode和Data block的映射关系,找到文件的数据块,并加载至内存中 - 这也就解释了为什么在
file对象中会存在inode信息,因为它与fd一样重要
4.3、对文件进行增删查改
文件创建后,如何删除?
-
删除并不是真删除,而是将
inode Bitmap和Block Bitmap中位图信息进行修改即可(只要访问不到,就是删除) -
根据文件名找到 inode 编号
-
再根据
inode属性中的映射关系,设置Block Bitmap对应的比特位,设置为 0 (删内容) -
最后根据 inode 编号设置
inode Bitmap中对应的比特位为 0 (删属性) -
将位图信息置为 0 后,创建新文件时,系统可以直接使用
-
至于文件的查找与修改,通过 inode 修改其内部属性即可
注意: inode 和Data blcok可能存在失衡的情况
- 一直创建空文件,导致
inode满载,而Data block空余很多 - 不断往同一个文件中写入数据,导致
Data block被占用,后续创建文件时,inode无法再分配到Data block
4.4 dentry树结构
上面分析可知,linux中并没有文件名的概念,而是通过属性加内容形成映射进行查找。
也就是说,访问文件,必须要知道当前文件目录,根据文件名,获得对应的inode,然后进行文件访问。
那么就会产生如下问题:
当前文件目录同样也是文件,如果想访问当前文件目录,就需要知道存储当前文件目录的上级目录,由此产生递归问题,递归出口为根目录。
因此每一次文件访问,都要从根⽬录开始,依次打开每⼀个⽬录,根据⽬录名,依次访问每个⽬录下指定的⽬录,直到访问到test.c。
这个过程叫做Linux路径解析。
路径缓存
- 由于每次打开都要层层访问,较为缓慢低效,因此OS会进行
历史路径缓存。
在内核中维护树状路径结构的内核结构体叫做: struct dentry
c
struct dentry {
atomic_t d_count;
unsigned int d_flags; /* protected by d_lock */
spinlock_t d_lock; /* per dentry lock */
struct inode *d_inode; /* Where the name belongs to - NULL is
* negative */
/*
* The next three fields are touched by __d_lookup. Place them here
* so they all fit in a cache line.
*/
struct hlist_node d_hash; /* lookup hash list */
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
struct list_head d_lru; /* LRU list */
/*
* d_child and d_rcu can share memory
*/
union {
struct list_head d_child; /* child of parent list */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* our children */
struct list_head d_alias; /* inode alias list */
unsigned long d_time; /* used by d_revalidate */
struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
void *d_fsdata; /* fs-specific data */
#ifdef CONFIG_PROFILING
struct dcookie_struct *d_cookie; /* cookie, if any */
#endif
int d_mounted;
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
};注意:
• 每个⽂件其实都要有对应的dentry结构,包括普通⽂件。这样所有被打开的⽂件,就可以在内存中
形成整个树形结构
• 整个树形节点也同时会⾪属于LRU(Least Recently Used,最近最少使⽤)结构中,进⾏节点淘汰
• 整个树形节点也同时会⾪属于Hash,⽅便快速查找
• 更重要的是,这个树形结构,整体构成了Linux的路径缓存结构,打开访问任何⽂件,都在先在这
棵树下根据路径进⾏查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry
结构,缓存新路径
4.5 挂载分区
上文我们提到,inode存在分区属性,不可以跨区使用,那么问题是:我们如何知道自己是在哪一个分区呢?
- 分区写⼊⽂件系统,⽆法直接使⽤,需要和指定的⽬录关联,进⾏
挂载才能使⽤。 - 所以,可以根据访问⽬标⽂件的
"路径前缀"准确判断我在哪⼀个分区
4.6 大文件存储
单个数据块大小有限(4 kb),如何做到一个数据块存储大量数据?
答案是 套娃,Data block 中存储其他Data block信息,此时称为多级索引,可以做到一个数据块中存储大量数据
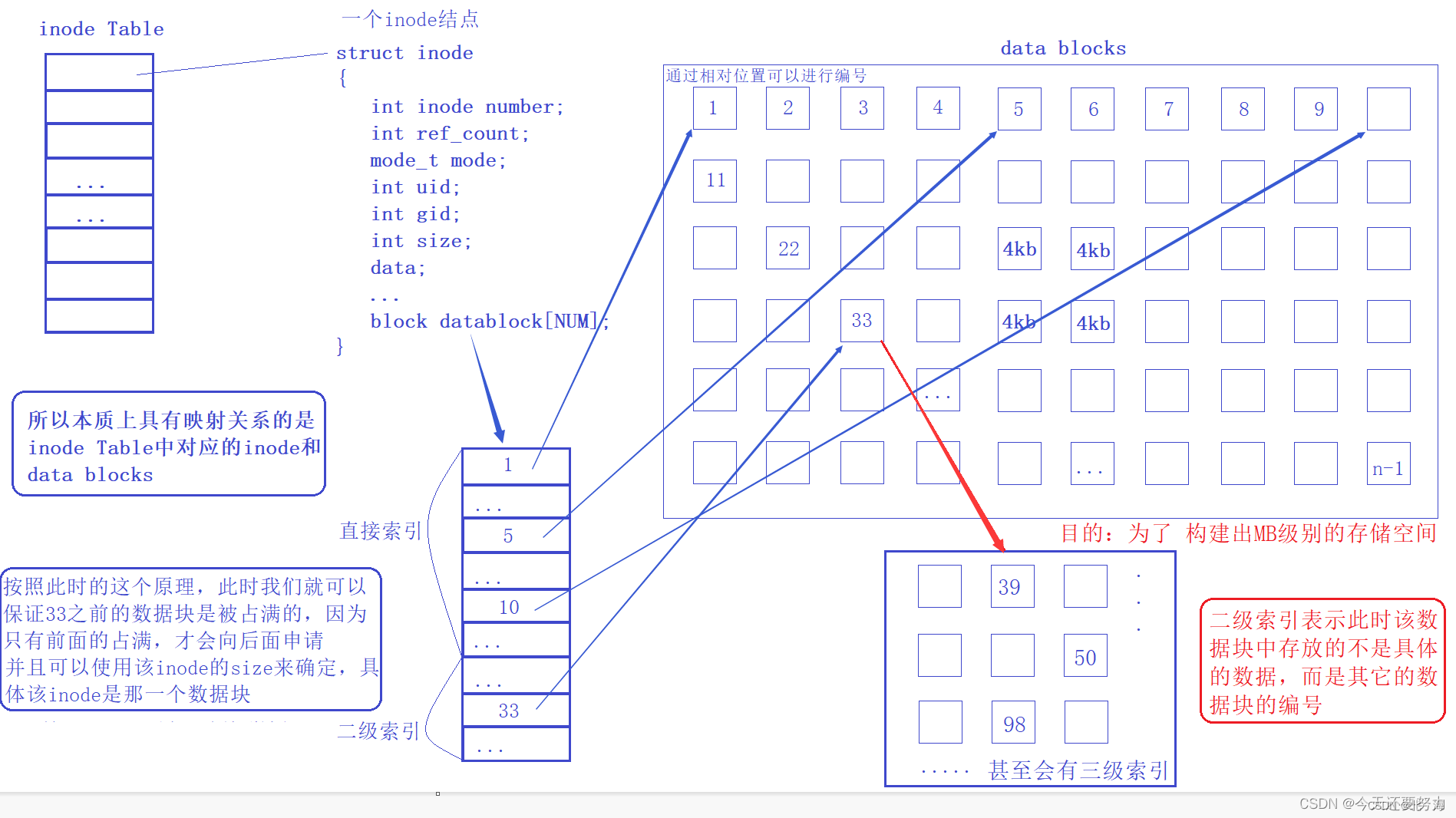
多级索引的基本原理
Linux文件系统中的inode包含15个指针:
-
12个直接指针(0-11):直接指向数据块
-
1个一级间接指针(12):指向一个索引块,该索引块包含数据块指针
-
1个二级间接指针(13):指向一个索引块,该索引块包含一级索引块的指针
-
1个三级间接指针(14):指向一个索引块,该索引块包含二级索引块的指针
多级索引的容量计算
假设每个指针占用4字节,块大小为4KB(4096字节):
-
直接寻址: 12个直接指针 × 4KB = 48KB
-
一级间接: 1个索引块可以存储1024个指针(4096/4) → 1024个数据块 × 4KB = 4MB
-
二级间接: 1024个一级索引块 × 1024个指针 × 4KB = 4GB
-
三级间接: 1024个二级索引块 × 1024个一级索引块 × 1024个指针 × 4KB = 4TB
这种"套娃"结构使Linux文件系统能够高效地支持从几KB到数TB的文件,同时保持较小文件的访问效率。
多级索引的优缺点
优点:
-
支持非常大的文件
-
小文件访问效率高(只需要直接指针)
-
灵活适应不同大小的文件
缺点:
-
大文件随机访问较慢(可能需要多次磁盘IO来解析索引)
-
索引块占用额外空间
这种设计非常类似于数据库中的B树或B+树结构,通过分层索引解决了容量和效率的平衡问题。
本篇关于Linux文件系统的介绍就暂告段落啦,希望能对大家的学习产生帮助,欢迎各位佬前来支持斧正!!!
