目录
[1. {} 初始化](#1. {} 初始化)
[2. std::initializer_list](#2. std::initializer_list)
[1. auto](#1. auto)
[2. decltype](#2. decltype)
[3. nullptr](#3. nullptr)
[1. 左值引用和右值引用](#1. 左值引用和右值引用)
[2. 左值引用与右值引用比较](#2. 左值引用与右值引用比较)
[3. 右值引用使用场景和意义](#3. 右值引用使用场景和意义)
[1. 移动赋值](#1. 移动赋值)
[2. 右值引用引用左值及其深入使用场景](#2. 右值引用引用左值及其深入使用场景)
[1. 基本概念与展开方式](#1. 基本概念与展开方式)
[2. STL容器中的 emplace 相关接口函数](#2. STL容器中的 emplace 相关接口函数)
[1. C++98中的排序示例对比](#1. C++98中的排序示例对比)
[2. lambda表达式的语法与示例](#2. lambda表达式的语法与示例)
[3. 函数对象与lambda表达式对比](#3. 函数对象与lambda表达式对比)
[1. 默认成员函数](#1. 默认成员函数)
[2. 类成员变量初始化](#2. 类成员变量初始化)
[3. 强制生成默认函数的关键字 default 和禁止生成默认函数的关键字 delete](#3. 强制生成默认函数的关键字 default 和禁止生成默认函数的关键字 delete)
[4. 继承和多态中的 final 与 override 关键字](#4. 继承和多态中的 final 与 override 关键字)
[1. 模板中的 && 万能引用](#1. 模板中的 && 万能引用)
[2. std::forward 完美转发在传参过程中保留对象原生类型属性](#2. std::forward 完美转发在传参过程中保留对象原生类型属性)
[1. 为什么需要function包装器](#1. 为什么需要function包装器)
[2. function包装器的使用](#2. function包装器的使用)
[1. 解决模板效率问题](#1. 解决模板效率问题)
[2. std::function 包装不同类型可调用对象的示例](#2. std::function 包装不同类型可调用对象的示例)
[std::bind 函数适配器](#std::bind 函数适配器)
[1. std::bind 的基本概念](#1. std::bind 的基本概念)
[2. std::bind 的使用示例](#2. std::bind 的使用示例)
[1. 传统解法](#1. 传统解法)
[2. 使用包装器的解法](#2. 使用包装器的解法)
引言
C++作为一门强大的编程语言,在不断地进化与发展。C++11标准的推出,为C++带来了诸多令人瞩目的新特性,极大地提升了语言的表达能力与开发效率。今天,就让我们一起深入探索C++11那些实用且有趣的特性。
C++11简介
C++11可谓是历经"十年磨一剑"。早在2003年,C++标准委员会提交了技术勘误表(TC1),C++03逐渐取代C++98成为新的标准,但它主要是对C++98的漏洞进行修复,核心部分改动不大 ,人们常将C++98/03合称为旧标准。而从C++0x(当时不确定最终版本号,所以用x代替)到C++11,才是真正意义上的重大革新,包含了约140个新特性以及对C++03中约600个缺陷的修正。
C++11在系统开发和库开发等领域表现出色,语法更加灵活、简化,稳定性和安全性也得到增强,成为了众多公司实际项目开发中的得力工具。例如,在一些高性能的游戏引擎开发中,C++11的新特性就被广泛应用,优化了代码结构与运行效率。
统一的列表初始化
1. {} 初始化
在C++98中,花括号{}就已被用于数组和结构体元素的初始化。比如:
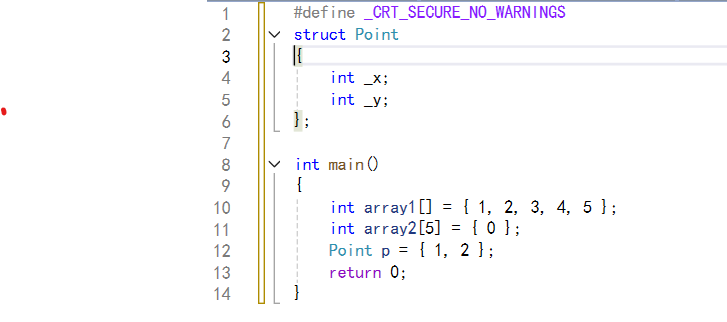
C++11进一步扩大了大括号初始化列表的应用范围,使其适用于所有内置类型和用户自定义类型。而且使用时等号"="可加可不加。示例如下:
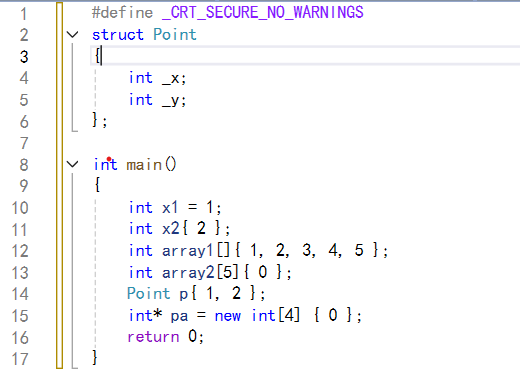
甚至在创建对象时,也能利用列表初始化来调用构造函数:
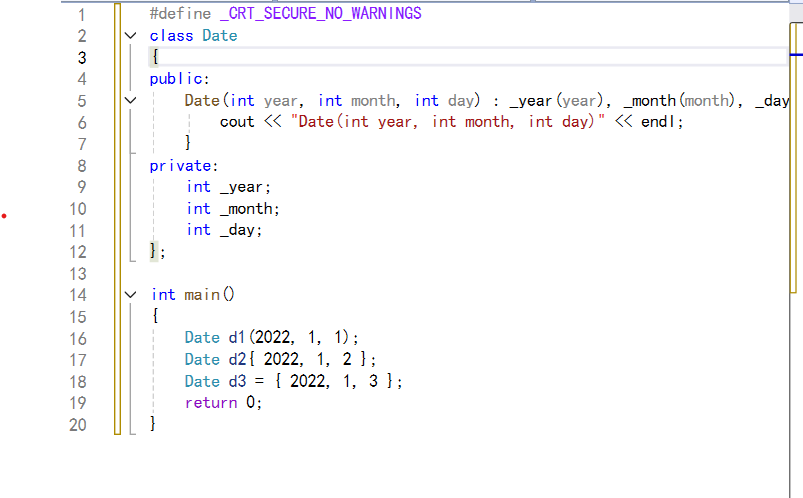
2. std::initializer_list
std::initializer_list 是C++11引入的一个很实用的类型。它一般作为构造函数的参数,让STL容器的初始化更加便捷。
我们可以通过以下代码查看它的类型: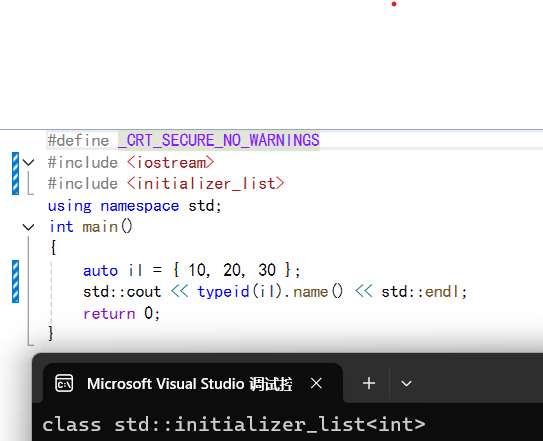
在实际使用中,许多STL容器都增加了以 std::initializer_list 为参数的构造函数。比如:
cpp
#include <vector>
#include <list>
#include <map>
#include <string>
int main() {
std::vector<int> v = { 1, 2, 3, 4 };
std::list<int> lt = { 1, 2 };
std::map<std::string, std::string> dict = { { "sort", "排序" }, { "insert", "插入" } };
v = { 10, 20, 30 };
return 0;
}如果想要让自定义的 vector 也支持这种初始化方式,可以参考以下代码:
cpp
namespace bit {
template<class T>
class vector {
public:
typedef T* iterator;
vector(std::initializer_list<T> l) {
_start = new T[l.size()];
_finish = _start + l.size();
_endofstorage = _start + l.size();
iterator vit = _start;
typename std::initializer_list<T>::iterator lit = l.begin();
while (lit != l.end()) {
*vit++ = *lit++;
}
}
vector<T>& operator=(std::initializer_list<T> l) {
vector<T> tmp(l);
std::swap(_start, tmp._start);
std::swap(_finish, tmp._finish);
std::swap(_endofstorage, tmp._endofstorage);
return *this;
}
private:
iterator _start;
iterator _finish;
iterator _endofstorage;
};
}变量类型推导
1. auto
在C++98中, auto 主要用于表示变量是局部自动存储类型,但在局部域中定义变量默认就是自动存储类型,所以 auto 意义不大。C++11对其进行了革新,使其用于自动类型推断。不过使用 auto 时必须进行显式初始化,编译器会根据初始化值来确定变量的类型。
示例代码如下:
cpp
#include <iostream>
#include <map>
#include <string>
int main() {
int i = 10;
auto p = &i;
auto pf = strcpy;
std::cout << typeid(p).name() << std::endl;
std::cout << typeid(pf).name() << std::endl;
std::map<std::string, std::string> dict = { { "sort", "排序" }, { "insert", "插入" } };
auto it = dict.begin();
return 0;
}2. decltype
decltype 关键字用于将变量的类型声明为表达式指定的类型。以下是一些使用场景:
cpp
#include <iostream>
template<class T1, class T2>
void F(T1 t1, T2 t2) {
decltype(t1 * t2) ret;
std::cout << typeid(ret).name() << std::endl;
}
int main() {
const int x = 1;
double y = 2.2;
decltype(x * y) ret;
decltype(&x) p;
std::cout << typeid(ret).name() << std::endl;
std::cout << typeid(p).name() << std::endl;
F(1, 'a');
return 0;
}3. nullptr
在C++中,之前用 NULL 表示空指针,但 NULL 本质是被定义为字面量0,这可能会导致一些混淆,因为0既可以表示指针常量,又能表示整形常量。C++11引入了 nullptr 来专门表示空指针,让代码更加清晰和安全。
比如在一些条件判断中:
cpp
#include <iostream>
int main() {
int* ptr = nullptr;
if (ptr == nullptr) {
std::cout << "ptr is nullptr" << std::endl;
}
return 0;
}右值引用和移动语义
1. 左值引用和右值引用
在C++11之前,我们所学的引用其实是左值引用。左值是可以获取地址且能被赋值的表达式,比如变量、解引用的指针等;左值引用就是给左值取别名。
cpp
int main() {
int* p = new int(0);
int b = 1;
const int c = 2;
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pvalue = *p;
return 0;
}C++11新增的右值引用,是给右值取别名。右值是不能取地址的表达式,像字面常量、表达式返回值、函数返回值(非左值引用返回 )等。
cpp
int main() {
double x = 1.1, y = 2.2;
int&& r1 = 10;
double&& r2 = x + y;
// 编译报错,右值不能出现在赋值符号左边
// 10 = 1;
// x + y = 1;
return 0;
}2. 左值引用与右值引用比较
- 左值引用只能绑定左值,不过 const 左值引用既可以绑定左值,也能绑定右值。
cpp
int main() {
int a = 10;
int& ra1 = a;
// int& ra2 = 10; 编译失败,10是右值
const int& ra3 = 10;
const int& ra4 = a;
return 0;
}- 右值引用只能绑定右值,但可以绑定 move 以后的左值。
cpp
int main() {
int&& r1 = 10;
int a = 10;
// int&& r2 = a; 编译失败,a是左值
int&& r3 = std::move(a);
return 0;
}3. 右值引用使用场景和意义
左值引用在作为函数参数和返回值时能提高效率,避免不必要的拷贝。但当函数返回一个局部变量时,由于局部变量出了函数作用域就会销毁,不能用左值引用返回,只能传值返回,这会导致拷贝构造开销。
例如:
cpp
#include <iostream>
#include <string>
std::string to_string(int value) {
std::string str;
// 处理逻辑
return str;
}
int main() {
std::string ret = to_string(1234);
return 0;
}
这里原本可能会有两次拷贝构造,但新的编译器一般会优化为一次。而右值引用和移动语义可以进一步优化这种情况。以自定义的 string 类为例:
cpp
namespace bit {
class string {
public:
typedef char* iterator;
string(const char* str = "") : _size(strlen(str)), _capacity(_size) {
_str = new char[_capacity + 1];
strcpy(_str, str);
}
string(const string& s) : _str(nullptr) {
std::cout << "string(const string& s) -- 深拷贝" << std::endl;
string tmp(s._str);
std::swap(tmp);
}
string(string&& s) : _str(nullptr), _size(0), _capacity(0) {
std::cout << "string(string&& s) -- 移动语义" << std::endl;
std::swap(s);
}
~string() {
delete[] _str;
_str = nullptr;
}
private:
char* _str;
size_t _size;
size_t _capacity;
};
}当有移动构造函数时,在函数返回右值时,编译器会优先调用移动构造,避免深拷贝,提高效率。
移动赋值与右值引用的深入应用
1. 移动赋值
在 bit::string 类中,我们不仅有移动构造,还可以添加移动赋值函数。当我们将 bit::to_string(1234) 返回的右值对象赋值给 ret1 对象时,就会调用移动赋值。示例代码如下:
cpp
// 移动赋值
string& operator=(string&& s) {
cout << "string& operator=(string&& s) -- 移动语义" << endl;
swap(s);
return *this;
}
int main() {
bit::string ret1;
ret1 = bit::to_string(1234);
return 0;
}
运行后,我们会看到调用了一次移动构造和一次移动赋值。编译器会把 str 识别成右值,先调用移动构造生成临时对象,再把临时对象赋值给 ret1 ,这里调用移动赋值。
2. 右值引用引用左值及其深入使用场景
虽然右值引用语法上只能引用右值,但在某些场景下,我们可以通过 std::move 函数将左值强制转化为右值引用,从而实现移动语义。 std::move 函数位于 <utility> 头文件中,它并不实际移动任何东西,只是进行类型转换。
例如:
cpp
int main() {
bit::string s1("hello world");
bit::string s2(s1);// 这里s1是左值,调用的是拷贝构造
bit::string s3(std::move(s1)); // 这里把s1 move处理后,会被当成右值,调用移动构造
// 但要注意,s1的资源会被转移给s3,s1被置空
return 0;
}在STL容器插入接口函数中,也增加了右值引用版本,如 std::list 和 std::vector 的 push_back 函数。以 std::list 为例:
cpp
void push_back (value_type&& val);
int main() {
list<bit::string> lt;
bit::string s1("1111");
// 这里调用的是拷贝构造
lt.push_back(s1);
// 下面调用都是移动构造
lt.push_back("2222");
lt.push_back(std::move(s1));
return 0;
}
可变参数模板
1. 基本概念与展开方式
C++11的可变参数模板允许创建可以接受可变参数的函数模板和类模板,这是对C++98/03中固定数量模板参数的重大改进。
- 递归函数方式展开参数包:定义一个基本的可变参数函数模板 ShowList ,通过递归终止函数和展开函数来处理参数包。
cpp
// Args是一个模板参数包,args是一个函数形参数包
// 声明一个参数包Args...args,这个参数包中可以包含0到任意个模板参数
template <class...Args>
void ShowList(Args... args) {}
// 递归终止函数
template <class T>
void ShowList(const T& t) {
cout << t << endl;
}
// 展开函数
template <class T, class...Args>
void ShowList(T value, Args... args) {
cout << value << " ";
ShowList(args...);
}
int main() {
ShowList(1);
ShowList(1, 'A');
ShowList(1, 'A', std::string("sort"));
return 0;
}- 逗号表达式展开参数包:这种方式不需要递归终止函数,直接在 expand 函数体中利用逗号表达式展开参数包。
cpp
template <class T>
void PrintArg(T t) {
cout << t << " ";
}
// 展开函数
template <class...Args>
void ShowList(Args... args) {
int arr[] = { (PrintArg(args), 0)... };
cout << endl;
}
int main() {
ShowList(1);
ShowList(1, 'A');
ShowList(1, 'A', std::string("sort"));
return 0;
}2. STL容器中的 emplace 相关接口函数
emplace 系列接口支持模板的可变参数,并且是万能引用。以 std::vector 和 std::list 的 emplace_back 为例:
cpp
template <class... Args>
void emplace_back (Args&&... args);它的优势在于可以在容器内部直接构造对象,避免了临时对象的拷贝或移动。比如在 std::list 中插入 std::pair<int, char> 对象:
cpp
int main() {
std::list<std::pair<int, char>> mylist;
// emplace_back支持可变参数,拿到构建pair对象的参数后自己去创建对象
mylist.emplace_back(10, 'a');
mylist.emplace_back(20, 'b');
mylist.emplace_back(std::make_pair(30, 'c'));
mylist.emplace_back(std::make_pair(40, 'd'));
mylist.push_back({ 50, 'e' });
for (auto e : mylist) {
cout << e.first << ":" << e.second << endl;
}
return 0;
}lambda表达式
1. C++98中的排序示例对比
在C++98中,使用 std::sort 对数组排序,如果是内置类型,默认按小于比较升序排列,如需降序,需改变比较规则,引入 greater<int>() 。对于自定义类型 Goods ,还需用户定义比较规则类,如 ComparePriceLess 和 ComparePriceGreater 。
cpp
#include <algorithm>
#include <functional>
int main() {
int array[] = { 4,1,8,5,3,7,0,9,2,6 };
// 默认按小于比较,排出来结果是升序
std::sort(array, array + sizeof(array) / sizeof(array[0]));
// 如果需要降序,需要改变元素的比较规则
std::sort(array, array + sizeof(array) / sizeof(array[0]), std::greater<int>());
return 0;
}
struct Goods {
std::string _name;
double _price;
int _evaluate;
Goods(const char* str, double price, int evaluate) : _name(str), _price(price), _evaluate(evaluate) {}
};
struct ComparePriceLess {
bool operator()(const Goods& g1, const Goods& g2) {
return g1._price < g2._price;
}
};
struct ComparePriceGreater {
bool operator()(const Goods& g1, const Goods& g2) {
return g1._price > g2._price;
}
};而在C++11中,lambda表达式让这一过程更加简洁。
2. lambda表达式的语法与示例
lambda表达式书写格式为: capture-list (parameters) mutable -> return-type { statement }
-
各部分说明:
-
capture-list :捕捉列表,用于捕捉上下文中的变量供lambda函数使用,捕捉方式有值传递和引用传递等。例如 = 表示值传递捕捉所有变量, \& 表示引用传递捕捉所有变量 。
-
(parameters) :参数列表,与普通函数参数列表一致,可省略。
-
mutable :默认lambda函数是常量函数,使用 mutable 可取消其常量性,此时参数列表不可省略。
-
->return-type :返回值类型,可省略,由编译器推导。
-
{statement} :函数体,可使用参数和捕获的变量。
-
示例:
cpp
int main() {
// 最简单的lambda表达式,无实际意义
[]{};
int a = 3, b = 4;
// 省略参数列表和返回值类型,返回值类型由编译器推导为int
[=]{return a + 3; };
// 省略了返回值类型,无返回值类型
auto fun1 = [&](int c){b = a + c; };
fun1(10);
cout << a << " " << b << endl;
// 各部分都很完善的lambda函数
auto fun2 = [=, &b](int c)->int{return b += a+ c; };
cout << fun2(10) << endl;
// 复制捕捉x
int x = 10;
auto add_x = [x](int a) mutable { x *= 2; return a + x; };
cout << add_x(10) << endl;
return 0;
}
3. 函数对象与lambda表达式对比
函数对象(仿函数)是在类中重载了 operator() 运算符的类对象。对比函数对象和lambda表达式:
cpp
class Rate {
public:
Rate(double rate) : _rate(rate) {}
double operator()(double money, int year) { return money * _rate * year; }
private:
double _rate;
};
int main() {
// 函数对象
double rate = 0.49;
Rate r1(rate);
r1(10000, 2);
// lambda
auto r2 = [=](double monty, int year)->double{return monty*rate*year; };
r2(10000, 2);
return 0;
}
从使用方式看,二者类似。函数对象将 rate 作为成员变量,在定义对象时初始化;lambda表达式通过捕获列表直接捕获该变量。底层编译器对lambda表达式的处理方式是按照函数对象的方式,定义lambda表达式会自动生成一个类,重载 operator() 。
新的类功能
1. 默认成员函数
在C++中,类有6个默认成员函数:构造函数、析构函数、拷贝构造函数、拷贝赋值重载、取地址重载、 const 取地址重载。C++11新增移动构造函数和移动赋值运算符重载。
关于移动构造函数和移动赋值运算符重载,有以下规则:
-
若未实现移动构造函数,且未实现析构函数、拷贝构造、拷贝赋值重载中的任何一个,编译器会自动生成默认移动构造函数。对于内置类型成员执行逐成员字节拷贝,自定义类型成员看其是否实现移动构造,实现则调用移动构造,未实现则调用拷贝构造。
-
若未实现移动赋值重载函数,且未实现析构函数、拷贝构造、拷贝赋值重载中的任何一个,编译器会自动生成默认移动赋值函数。内置类型成员逐成员字节拷贝,自定义类型成员看其是否实现移动赋值,实现则调用移动赋值,未实现则调用拷贝赋值。
-
若提供了移动构造或移动赋值,编译器不会自动提供拷贝构造和拷贝赋值。
示例代码如下:
cpp
class Person {
public:
Person(const char* name = "", int age = 0) : _name(name), _age(age) {}
// 未实现移动构造和移动赋值相关函数
/*Person(const Person& p)
:_name(p._name)
,_age(p._age)
{}*/
/*Person& operator=(const Person& p) {
if (this != &p) {
_name = p._name;
_age = p._age;
}
return *this;
}*/
/*~Person() {}*/
private:
bit::string _name;
int _age;
};
int main() {
Person s1;
Person s2 = s1;
Person s3 = std::move(s1);
Person s4;
s4 = std::move(s2);
return 0;
}2. 类成员变量初始化
C++11允许在类定义时给成员变量初始缺省值,默认生成构造函数会使用这些缺省值初始化。
3. 强制生成默认函数的关键字 default 和禁止生成默认函数的关键字 delete
- default :当我们希望使用某个默认函数,但由于自定义了其他函数导致编译器不自动生成时,可使用 default 关键字显式指定生成。比如提供了拷贝构造,想让编译器生成移动构造,可如下定义:
cpp
class Person {
public:
Person(const char* name = "", int age = 0)
: _name(name)
, _age(age)
{}
Person(const Person& p)
:_name(p._name)
,_age(p._age) {}
Person(Person&& p) = default;
private:
bit::string _name;
int _age;
};- delete :在C++11中,若想限制某些默认函数生成,只需在函数声明后加上 =delete ,该函数称为删除函数。例如,禁止拷贝构造函数:
cpp
class Person {
public:
Person(const char* name = "", int age = 0) : _name(name), _age(age) {}
Person(const Person& p) = delete;
private:
bit::string _name;
int _age;
};4. 继承和多态中的 final 与 override 关键字
final 用于修饰虚函数,表示该虚函数不能被派生类重写;修饰类,表示该类不能被继承。 override 用于显式表明派生类中的函数是重写基类的虚函数,若基类不存在对应的虚函数,编译器会报错,从而避免一些隐藏的错误。这部分在继承和多态章节有详细讲解。
完美转发
1. 模板中的 && 万能引用
在模板中, && 不代表右值引用,而是万能引用,它既能接收左值又能接收右值。但引用类型唯一作用是限制接收的类型,后续使用中都退化成左值。如果希望在传递过程中保持对象原生类型属性(左值或右值),就需要完美转发。
示例代码如下:
cpp
void Fun(int &x){ cout << "左值引用" << endl; }
void Fun(const int &x){ cout << "const 左值引用" << endl; }
void Fun(int &&x){ cout << "右值引用" << endl; }
void Fun(const int &&x){ cout << "const 右值引用" << endl; }
template<typename T>
void PerfectForward(T&& t) {
Fun(t);
}
int main() {
PerfectForward(10);
int a;
PerfectForward(a);
PerfectForward(std::move(a));
const int b = 8;
PerfectForward(b);
PerfectForward(std::move(b));
return 0;
}2. std::forward 完美转发在传参过程中保留对象原生类型属性
std::forward<T>(t) 在传参过程中能保持 t 的原生类型属性。示例如下:
cpp
void Fun(int &x){ cout << "左值引用" << endl; }
void Fun(const int &x){ cout << "const 左值引用" << endl; }
void Fun(int &&x){ cout << "右值引用" << endl; }
void Fun(const int &&x){ cout << "const 右值引用" << endl; }
template<typename T>
void PerfectForward(T&& t) {
Fun(std::forward<T>(t));
}
int main() {
PerfectForward(10);
int a;
PerfectForward(a);
PerfectForward(std::move(a));
const int b = 8;
PerfectForward(b);
PerfectForward(std::move(b));
return 0;
}完美转发在实际中的使用场景,如自定义的 List 类中:
cpp
template<class T>
struct ListNode {
ListNode* _next = nullptr;
ListNode* _prev = nullptr;
T _data;
};
template<class T>
class List {
typedef ListNode<T> Node;
public:
List() {
_head = new Node;
_head->_next = _head;
_head->_prev = _head;
}
void PushBack(T&& x) {
Insert(_head, std::forward<T>(x));
}
void PushFront(T&& x) {
Insert(_head->_next, std::forward<T>(x));
}
void Insert(Node* pos, T&& x) {
Node* prev = pos->_prev;
Node* newnode = new Node;
newnode->_data = std::forward<T>(x);
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = pos;
pos->_prev = newnode;
}
void Insert(Node* pos, const T& x) {
Node* prev = pos->_prev;
Node* newnode = new Node;
newnode->_data = x;
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = pos;
pos->_prev = newnode;
}
~List() {
Node* cur = _head->_next;
while (cur != _head) {
Node* next = cur->_next;
delete cur;
cur = next;
}
delete _head;
}
// 提供迭代器相关接口,方便遍历
class iterator {
public:
iterator(Node* node) : _node(node) {}
T& operator*() {
return _node->_data;
}
iterator& operator++() {
_node = _node->_next;
return *this;
}
iterator operator++(int) {
iterator tmp = *this;
_node = _node->_next;
return tmp;
}
iterator& operator--() {
_node = _node->_prev;
return *this;
}
iterator operator--(int) {
iterator tmp = *this;
_node = _node->_prev;
return tmp;
}
bool operator!=(const iterator& it) const {
return _node != it._node;
}
bool operator==(const iterator& it) const {
return _node == it._node;
}
private:
Node* _node;
};
iterator begin() {
return iterator(_head->_next);
}
iterator end() {
return iterator(_head);
}
private:
Node* _head;
};代码说明
析构函数( ~List ):用于释放链表中所有节点占用的内存。先从第一个有效节点开始,逐个删除节点,最后删除头节点。
迭代器相关部分
iterator 类:定义了链表的迭代器。通过重载各种运算符,使得迭代器可以像指针一样方便地遍历链表。例如,重载 * 运算符用于获取节点数据,重载 ++ 和 -- 运算符用于移动迭代器到下一个或前一个节点,重载 != 和 == 用于比较迭代器是否相等。
begin 和 end 函数: begin 函数返回指向链表第一个有效节点的迭代器, end 函数返回指向头节点的迭代器,用于界定链表遍历的范围。
这样,外部代码就可以使用 for 循环等方式方便地遍历链表,例如:
cpp
List<int> lst;
lst.PushBack(1);
lst.PushBack(2);
lst.PushBack(3);
for (auto it = lst.begin(); it != lst.end(); ++it) {
std::cout << *it << " ";
}包装器(function包装器)
1. 为什么需要function包装器
在C++中,我们常常会遇到需要处理多种可调用类型的情况,比如函数名、函数指针、函数对象(仿函数对象)以及lambda表达式对象等。例如在下面的函数模板 useF 中: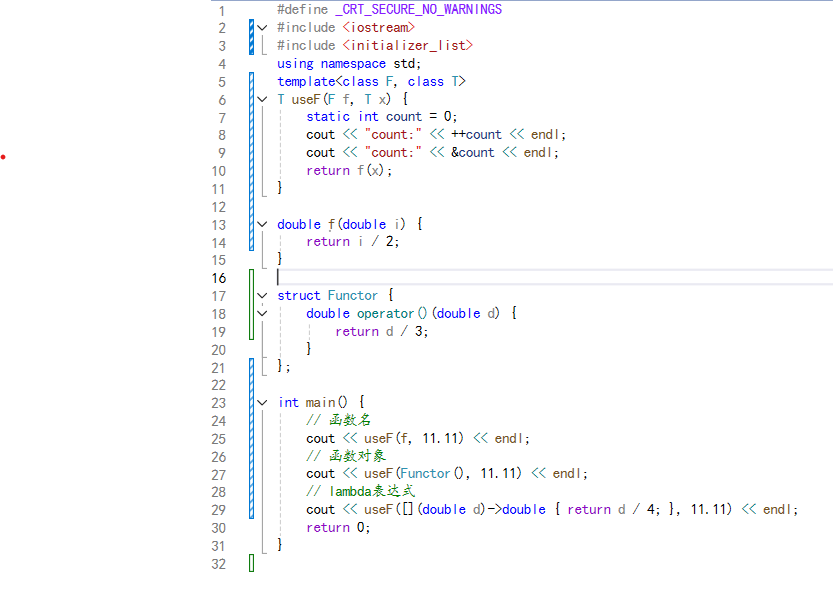
在这个例子中, useF 函数模板实例化了三份,因为编译器需要为不同类型的可调用对象分别生成代码。当可调用类型非常丰富时,这可能会导致模板的效率低下。而 function 包装器可以很好地解决这个问题。
2. function包装器的使用
std::function 是定义在 <functional> 头文件中的一个类模板,它本质是一个包装器,也叫适配器。其类模板原型如下:
cpp
template <class T> function; // undefined
template <class Ret, class... Args>
class function<Ret(Args...)>;其中 Ret 是被调用函数的返回类型, Args... 是被调用函数的形参。
使用示例如下: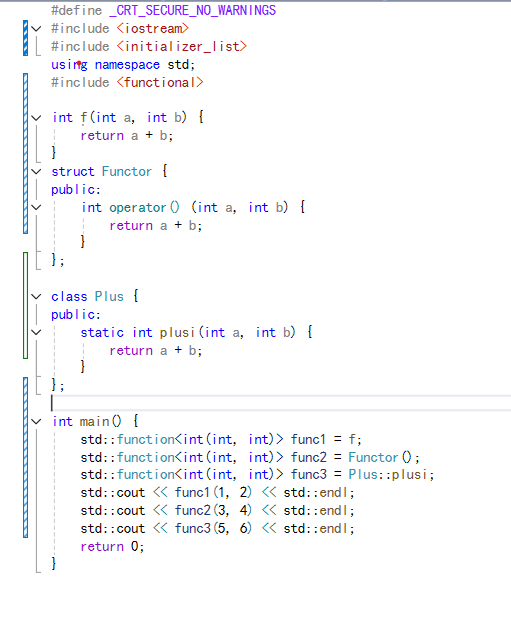
std::function 可以统一包装不同类型的可调用对象,使得代码更加简洁和灵活,提高了代码的可维护性和复用性。
包装器(function包装器)的进一步探讨
1. 解决模板效率问题
在之前提到的 useF 函数模板示例中,当面对多种可调用类型时,会导致模板实例化多份,影响效率。而 std::function 包装器可以统一处理这些可调用类型。
以如下代码为例:
cpp
#include <functional>
template<class F, class T>
T useF(F f, T x) {
static int count = 0;
cout << "count:" << ++count << endl;
cout << "count:" << &count << endl;
return f(x);
}
double f(double i) {
return i / 2;
}
struct Functor {
double operator()(double d) {
return d / 3;
}
};
int main() {
// 函数名
std::function<double(double)> func1 = f;
cout << useF(func1, 11.11) << endl;
// 函数对象
std::function<double(double)> func2 = Functor();
cout << useF(func2, 11.11) << endl;
// lambda表达式
std::function<double(double)> func3 = [](double d)->double{ return d / 4; };
cout << useF(func3, 11.11) << endl;
return 0;
}通过 std::function 将不同类型的可调用对象统一包装, useF 函数模板在处理这些对象时,不再需要为每种类型单独实例化,提高了代码的效率和简洁性。
2. std::function 包装不同类型可调用对象的示例
cpp
class Plus {
public:
static int plusi(int a, int b) {
return a + b;
}
double plusd(double a, double b) {
return a + b;
}
};
int main() {
// 函数名(函数指针)
std::function<int(int, int)> func1 = f;
cout << func1(1, 2) << endl;
// 函数对象
std::function<int(int, int)> func2 = Functor();
cout << func2(1, 2) << endl;
// lambda表达式
std::function<int(int, int)> func3 = [](const int a, const int b) { return a + b; };
cout << func3(1, 2) << endl;
// 类的静态成员函数
std::function<int(int, int)> func4 = &Plus::plusi;
cout << func4(1, 2) << endl;
// 类的非静态成员函数
std::function<double(Plus, double, double)> func5 = &Plus::plusd;
cout << func5(Plus(), 1.1, 2.2) << endl;
return 0;
}这里展示了 std::function 包装函数名、函数对象、lambda表达式、类的静态成员函数以及类的非静态成员函数的方式,体现了其强大的通用性和灵活性。
std::bind 函数适配器
1. std::bind 的基本概念
std::bind 定义在 <functional> 头文件中,是一个函数模板,它如同一个函数包装器(适配器)。它接受一个可调用对象(如函数、函数对象、lambda表达式等),生成一个新的可调用对象来"适应"原对象的参数列表。
一般调用形式为: auto newCallable = bind(callable, arg_list) 。其中, newCallable 本身是一个可调用对象, arg_list 是一个逗号分隔的参数列表,对应给定的 callable 的参数。 arg_list 中的参数可能包含形如 _n 的名字( n 是一个整数),这些参数是"占位符",表示 newCallable 的参数,它们占据了传递给 newCallable 的参数的"位置"。数值 n 表示生成的可调用对象中参数的位置, _1 为 newCallable 的第一个参数, _2 为第二个参数,以此类推。
2. std::bind 的使用示例
cpp
#include <functional>
int Plus(int a, int b) {
return a + b;
}
class Sub {
public:
int sub(int a, int b) {
return a - b;
}
};
int main() {
// 表示绑定函数Plus,参数分别由调用func1的第一、二个参数指定
std::function<int(int, int)> func1 = std::bind(Plus, std::placeholders::_1, std::placeholders::_2);
// auto func1 = std::bind(Plus, placeholders::_1, placeholders::_2);
// func2的类型为function<void(int, int, int)> 与func1类型一样
// 表示绑定函数Plus的第一、二为:1、2
auto func2 = std::bind(Plus, 1, 2);
cout << func1(1, 2) << endl;
cout << func2() << endl;
Sub s;
// 绑定成员函数
std::function<int(int, int)> func3 = std::bind(&Sub::sub, s, std::placeholders::_1, std::placeholders::_2);
// 参数调换顺序
std::function<int(int, int)> func4 = std::bind(&Sub::sub, s, std::placeholders::_2, std::placeholders::_1);
cout << func3(1, 2) << endl;
cout << func4(1, 2) << endl;
return 0;
}
在这个示例中,通过 std::bind 对函数 Plus 和类 Sub 的成员函数 sub 进行了不同方式的绑定。可以指定固定参数,也可以使用占位符灵活地调整参数顺序,展示了 std::bind 在参数绑定和调整方面的强大功能。
在实际问题中的应用------以逆波兰表达式求值为例
1. 传统解法
对于逆波兰表达式求值问题(LeetCode相关题目),传统解法通常使用栈来处理。代码如下:
cpp
class Solution {
public:
int evalRPN(std::vector<std::string>& tokens) {
std::stack<int> st;
for (auto& str : tokens) {
if (str == "+" || str == "-" || str == "*" || str == "/") {
int right = st.top();
st.pop();
int left = st.top();
st.pop();
switch (str[0]) {
case '+':
st.push(left + right);
break;
case '-':
st.push(left - right);
break;
case '*':
st.push(left * right);
break;
case '/':
st.push(left / right);
break;
}
}
else {
st.push(std::stoi(str));
}
}
return st.top();
}
};
这种解法通过遍历逆波兰表达式的字符串数组,利用栈来存储操作数,遇到运算符时进行相应的运算。
2. 使用包装器的解法
利用 std::function 和 std::bind 等包装器机制,可以让代码更加简洁和灵活。
cpp
class Solution {
public:
int evalRPN(std::vector<std::string>& tokens) {
std::stack<int> st;
std::map<std::string, std::function<int(int, int)>> opFuncMap = {
{ "+", [](int i, int j){return i + j; } },
{ "-", [](int i, int j){return i - j; } },
{ "*", [](int i, int j){return i * j; } },
{ "/", [](int i, int j){return i / j; } }
};
for (auto& str : tokens) {
if (opFuncMap.find(str) != opFuncMap.end()) {
int right = st.top();
st.pop();
int left = st.top();
st.pop();
st.push(opFuncMap[str](left, right));
}
else {
st.push(std::stoi(str));
}
}
return st.top();
}
};在这个解法中,使用 std::map 结合 std::function 将运算符与对应的运算逻辑(以lambda表达式表示)进行映射。在遍历过程中,当遇到运算符时,直接从 map 中获取对应的可调用对象进行运算,使得代码逻辑更加清晰,同时也体现了C++11包装器特性在实际问题中的应用优势。
通过对 std::function 和 std::bind 等包装器相关内容的深入探讨以及在实际问题中的应用展示,我们能更全面地掌握C++11在处理可调用对象方面的强大功能,这些特性为我们编写高效、简洁、灵活的代码提供了有力支持。