结合归一化和正则化来优化网络模型结构,观察对比loss结果
搭建的神经网络,使用olivettiface数据集进行训练,结合归一化和正则化来优化网络模型结构,观察对比loss结果
python
from sklearn.datasets import fetch_olivetti_faces #倒入数据集
python
olivetti_faces = fetch_olivetti_faces(data_home='./face_data', shuffle=True)
print(olivetti_faces.data.shape) #打印数据集的形状
print(olivetti_faces.target.shape) #打印目标的形状
print(olivetti_faces.images.shape) #打印图像的形状(400, 4096)
(400,)
(400, 64, 64)
python
import matplotlib.pyplot as plt
face = olivetti_faces.images[1] #选择第二张人脸图像
plt.imshow(face, cmap='gray') #显示图像 cmap='gray'表示灰度图
plt.show()
python
olivetti_faces.data[1] #选择第二张人脸图像的扁平化数据array([0.76859504, 0.75619835, 0.74380165, ..., 0.48347107, 0.6280992 ,
0.6528926 ], shape=(4096,), dtype=float32)
python
import torch
import torch.nn as nn
python
images = torch.tensor(olivetti_faces.data) #将数据转换为tensor
targets = torch.tensor(olivetti_faces.target) #将目标转换为tensor
python
images.shape #打印图像的形状torch.Size([400, 4096])
python
targets.shape #打印目标的形状torch.Size([400])
python
dataset = [(img,lbl) for img,lbl in zip(images, targets)] #将图像和标签组合成一个数据集
dataset[0] #打印数据集的第一个元素(tensor([0.6694, 0.6364, 0.6488, ..., 0.0868, 0.0826, 0.0744]), tensor(13))
python
dataloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True) #创建数据加载器,批量大小为10,打乱数据
python
# device = torch.device('mps' if torch.backends.mps.is_available() else 'cpu')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
devicedevice(type='cpu')使用Dropout正则化优化
python
# 多层神经网络模型
model = nn.Sequential(
nn.Linear(4096, 8192), # 输入层,输入特征数为4096
nn.ReLU(), # ReLU激活函数
nn.Dropout(), # Dropout正则化
nn.Linear(8192, 16384), # 隐藏层,输出特征数为16384
nn.ReLU(),
nn.Dropout(),
nn.Linear(16384, 1024), # 隐藏层,输出特征数为1024
nn.ReLU(),
nn.Dropout(),
nn.Linear(1024, 40) # 输出层,输出特征数为40(对应40个类别)
).to(device) # 模型结构搬到GPU内存中
python
print(model) # 打印模型结构Sequential(
(0): Linear(in_features=4096, out_features=8192, bias=True)
(1): ReLU()
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=8192, out_features=16384, bias=True)
(4): ReLU()
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=16384, out_features=1024, bias=True)
(7): ReLU()
(8): Dropout(p=0.5, inplace=False)
(9): Linear(in_features=1024, out_features=40, bias=True)
)
python
criterion = nn.CrossEntropyLoss() # 损失函数为交叉熵损失
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3) # 优化器为Adam,学习率为1e-3
python
# 训练模型
loss_hist = [] # 用于记录损失值
# 将模型设置为训练模式
model.train()
for i in range(20): # 训练20个epoch
for img,lbl in dataloader:
img,lbl = img.to(device), lbl.to(device) # 数据和模型在同一个设备端
result = model(img)
loss = criterion(result, lbl)
loss.backward()
optimizer.step()
optimizer.zero_grad()
loss_hist.append(loss.item()) # 记录损失值
print(f'epoch:{i+1} loss:{loss.item():.4f}') # 打印当前epoch和损失值epoch:1 loss:3.7076
epoch:1 loss:12.3654
epoch:1 loss:13.7588
epoch:1 loss:6.2780
epoch:1 loss:4.3650
epoch:1 loss:3.9659
epoch:1 loss:3.9149
epoch:1 loss:3.8406
epoch:1 loss:3.8485
epoch:1 loss:3.8279
epoch:1 loss:3.8980
epoch:1 loss:3.8377
epoch:1 loss:3.7295
epoch:1 loss:3.7737
epoch:1 loss:3.7615
epoch:1 loss:3.7997
epoch:1 loss:3.7737
epoch:1 loss:3.7385
epoch:1 loss:3.7080
epoch:1 loss:3.6875
epoch:1 loss:3.7611
epoch:1 loss:3.6810
epoch:1 loss:3.5438
epoch:1 loss:3.7640
epoch:1 loss:3.9102
epoch:1 loss:4.2676
epoch:1 loss:3.8784
epoch:1 loss:3.8589
epoch:1 loss:3.6792
。。。。。。
epoch:20 loss:3.6929
epoch:20 loss:3.6839
epoch:20 loss:3.6866
epoch:20 loss:3.6917
epoch:20 loss:3.6881
epoch:20 loss:3.6903
epoch:20 loss:3.6893
epoch:20 loss:3.6838
epoch:20 loss:3.6909
epoch:20 loss:3.6903
epoch:20 loss:3.6869
epoch:20 loss:3.6871
epoch:20 loss:3.6939
epoch:20 loss:3.6909
epoch:20 loss:3.6971
epoch:20 loss:3.6935
epoch:20 loss:3.6875
epoch:20 loss:3.6901
epoch:20 loss:3.6864
epoch:20 loss:3.6891
epoch:20 loss:3.6912
epoch:20 loss:3.6913
epoch:20 loss:3.6845
epoch:20 loss:3.6889
epoch:20 loss:3.6898
epoch:20 loss:3.6811
epoch:20 loss:3.6926
epoch:20 loss:3.6888
epoch:20 loss:3.6993
epoch:20 loss:3.6898
epoch:20 loss:3.6947
epoch:20 loss:3.6931
epoch:20 loss:3.6951
epoch:20 loss:3.6901
epoch:20 loss:3.6877
epoch:20 loss:3.6880
epoch:20 loss:3.6926
epoch:20 loss:3.6864
epoch:20 loss:3.6910
epoch:20 loss:3.6951
python
plt.plot(range(len(loss_hist)), loss_hist) # 绘制损失值曲线
plt.show()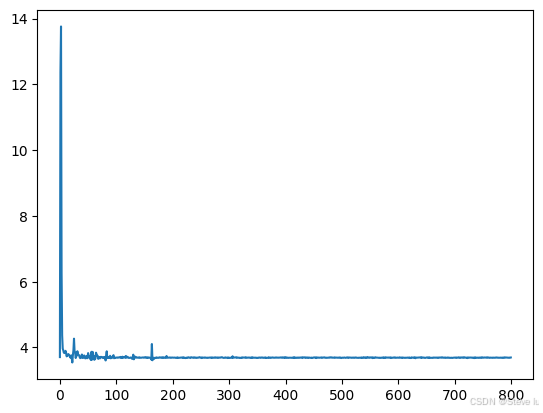
使用BatchNorm1d归一化优化
python
# 多层神经网络模型
model2 = nn.Sequential(
nn.Linear(4096, 8192),
nn.BatchNorm1d(8192),
nn.ReLU(),
nn.Dropout(),
nn.Linear(8192, 16384),
nn.BatchNorm1d(16384), # 批归一化
nn.ReLU(),
nn.Dropout(),
nn.Linear(16384, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Dropout(),
nn.Linear(1024, 40)
).to(device) # 模型结构搬到GPU内存中
python
print(model2)Sequential(
(0): Linear(in_features=4096, out_features=8192, bias=True)
(1): BatchNorm1d(8192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=8192, out_features=16384, bias=True)
(5): BatchNorm1d(16384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU()
(7): Dropout(p=0.5, inplace=False)
(8): Linear(in_features=16384, out_features=1024, bias=True)
(9): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): ReLU()
(11): Dropout(p=0.5, inplace=False)
(12): Linear(in_features=1024, out_features=40, bias=True)
)
python
criterion2 = nn.CrossEntropyLoss() # 损失函数为交叉熵损失
optimizer2 = torch.optim.Adam(model2.parameters(), lr=1e-3) # 优化器为Adam,学习率为1e-3
python
loss_hist2 = []
model2.train()
for i in range(20):
for img,lbl in dataloader:
img,lbl = img.to(device), lbl.to(device) # 数据和模型在同一个设备端
result = model2(img)
loss = criterion2(result, lbl)
loss.backward()
optimizer2.step()
optimizer2.zero_grad()
loss_hist2.append(loss.item())
print(f'epoch:{i+1} loss:{loss.item():.4f}')epoch:1 loss:3.5798
epoch:1 loss:3.2452
epoch:1 loss:3.5353
epoch:1 loss:4.1675
epoch:1 loss:4.0728
epoch:1 loss:3.4937
epoch:1 loss:3.9814
epoch:1 loss:3.6151
epoch:1 loss:3.5217
epoch:1 loss:3.1017
epoch:1 loss:3.4522
epoch:1 loss:4.8181
epoch:1 loss:4.0231
epoch:1 loss:4.3008
epoch:1 loss:3.3741
epoch:1 loss:3.9258
epoch:1 loss:3.6895
epoch:1 loss:4.0020
epoch:1 loss:3.1241
epoch:1 loss:2.9453
epoch:1 loss:3.3162
epoch:1 loss:4.3189
epoch:1 loss:3.4162
epoch:1 loss:4.3958
epoch:1 loss:3.1572
epoch:1 loss:3.2535
epoch:1 loss:3.4887
epoch:1 loss:3.4771
epoch:1 loss:3.5689
epoch:1 loss:2.5994
epoch:1 loss:2.7629
epoch:1 loss:2.9798
epoch:1 loss:2.7517
epoch:1 loss:2.7871
epoch:1 loss:2.6800
epoch:1 loss:2.9784
epoch:1 loss:3.4050
epoch:1 loss:2.6510
epoch:1 loss:3.5258
epoch:1 loss:4.0064
epoch:2 loss:2.8011
epoch:2 loss:2.5357
epoch:2 loss:2.6513
epoch:2 loss:2.5815
epoch:2 loss:2.0862
epoch:2 loss:2.9170
epoch:2 loss:2.5202
。。。。。。
epoch:20 loss:0.0768
epoch:20 loss:0.0592
epoch:20 loss:0.4393
epoch:20 loss:0.2460
epoch:20 loss:0.1196
epoch:20 loss:0.0596
epoch:20 loss:0.0088
epoch:20 loss:0.1478
epoch:20 loss:0.0671
epoch:20 loss:0.1121
epoch:20 loss:0.1161
epoch:20 loss:0.0191
epoch:20 loss:0.1365
epoch:20 loss:0.0635
epoch:20 loss:0.0404
epoch:20 loss:0.0673
epoch:20 loss:0.0122
epoch:20 loss:0.6775
epoch:20 loss:0.0122
epoch:20 loss:0.0137
epoch:20 loss:0.0415
epoch:20 loss:0.1397
epoch:20 loss:0.0244
epoch:20 loss:0.2535
epoch:20 loss:0.3182
epoch:20 loss:0.2677
epoch:20 loss:0.0028
epoch:20 loss:0.0185
epoch:20 loss:0.1291
epoch:20 loss:0.0514
epoch:20 loss:0.0539
epoch:20 loss:0.0254
epoch:20 loss:0.0723
epoch:20 loss:0.4357
epoch:20 loss:0.1185
epoch:20 loss:0.0806
epoch:20 loss:0.7051
epoch:20 loss:0.0060
epoch:20 loss:0.0527
epoch:20 loss:0.0121
python
plt.plot(range(len(loss_hist2)), loss_hist2)
plt.show()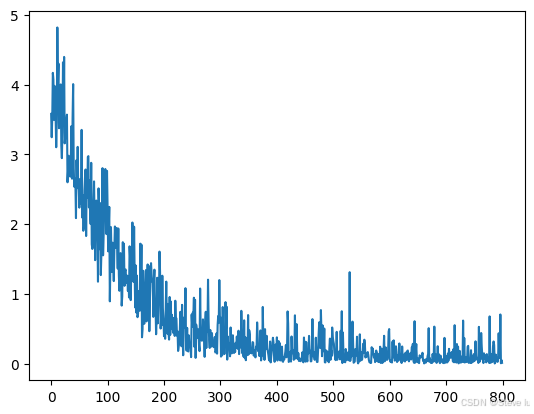
本实验主要内容和结论总结如下:
-
数据集
使用了
sklearn.datasets中的Olivetti人脸数据集,包含400张人脸图片,每张图片为64x64像素,分为40类。 -
数据处理
- 图像数据被扁平化为4096维向量。
- 使用PyTorch的
DataLoader进行批量加载。
-
模型设计与优化
- 基础模型:多层全连接神经网络,使用ReLU激活和Dropout正则化。
- 优化模型 :在基础模型的每一层后增加了
BatchNorm1d批归一化层,进一步提升训练稳定性和收敛速度。
-
训练过程
- 均采用交叉熵损失函数和Adam优化器,训练20个epoch。
- 记录并可视化loss变化曲线。
结果对比与观察
- Dropout正则化:有效缓解过拟合,loss曲线整体下降,但可能波动较大。
- BatchNorm归一化+Dropout:loss下降更快更平滑,模型收敛速度提升,训练更稳定。
结论
- 结合归一化(BatchNorm)和正则化(Dropout)可以显著提升神经网络的训练效果和泛化能力。
- 归一化有助于加速收敛,正则化有助于防止过拟合,两者结合效果更佳。