除了以上常见数据源,还有 NoSQL、MQ 等数据源,其中以 MongoDB 最为常用。我们用 SPL 连接 MongoDB 做计算。
导入 MongoDB 数据。
外部库
SPL 支持的多种数据源大概分两类,一类是像 RDB 有 JDBC 直接使用,或者文件等直接读取;另一类是像 MongoDB 等非关系数据源是在官方驱动上进行了简单封装,具体以"外部库"的形式提供。
外部库列表包括以下数十种非常规数据源及函数:
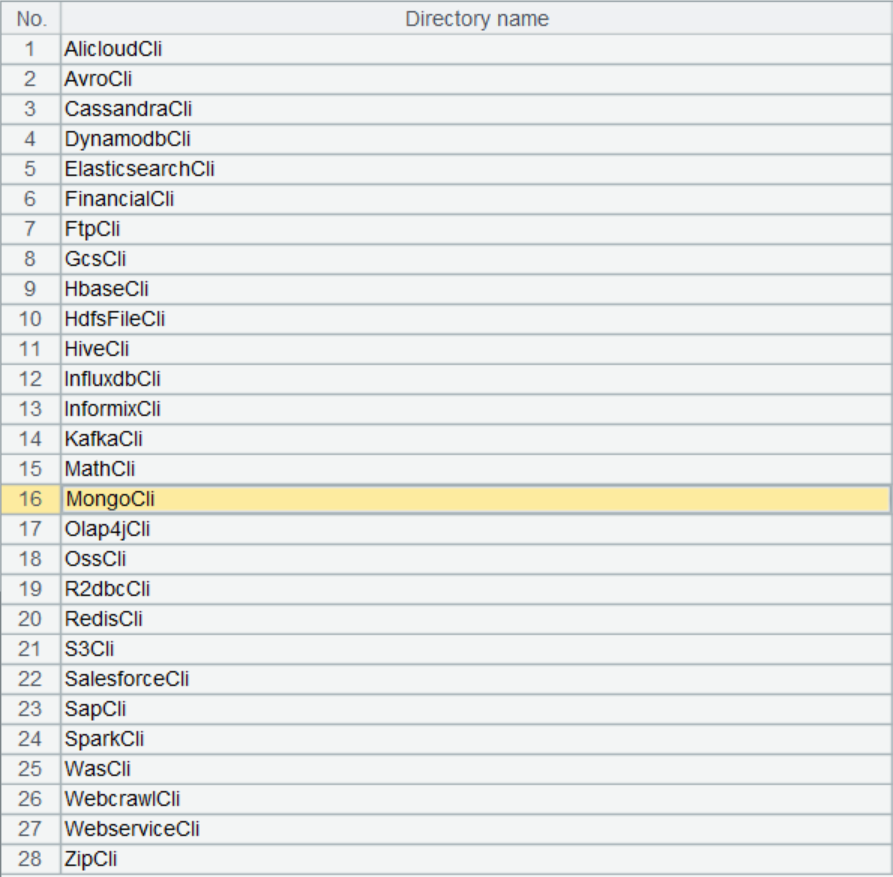
外部连接器放在外部库中,外部库是 SPL 提供的外部函数扩展库,将一些在普遍场景使用频率不高的专门用途函数以外部库形式提交,这样可以根据需要临时加载。
外部数据源种类繁多,也不是每种数据源都很常用,所以将这些连接器以外部库的形式提供会更为灵活,以后发现有新的数据源也可以及时补充而不影响现有的数据源。
具体使用时,需要先下载外部库驱动:https://download.raqsoft.com.cn/esproc/ext/extlib/extlib-20250508.zip
然后放置到任意目录,比如 安装目录 \esProc\extlib。接着在 IDE 中加载外部库目录,并勾选要用到的外部库。
计算用例
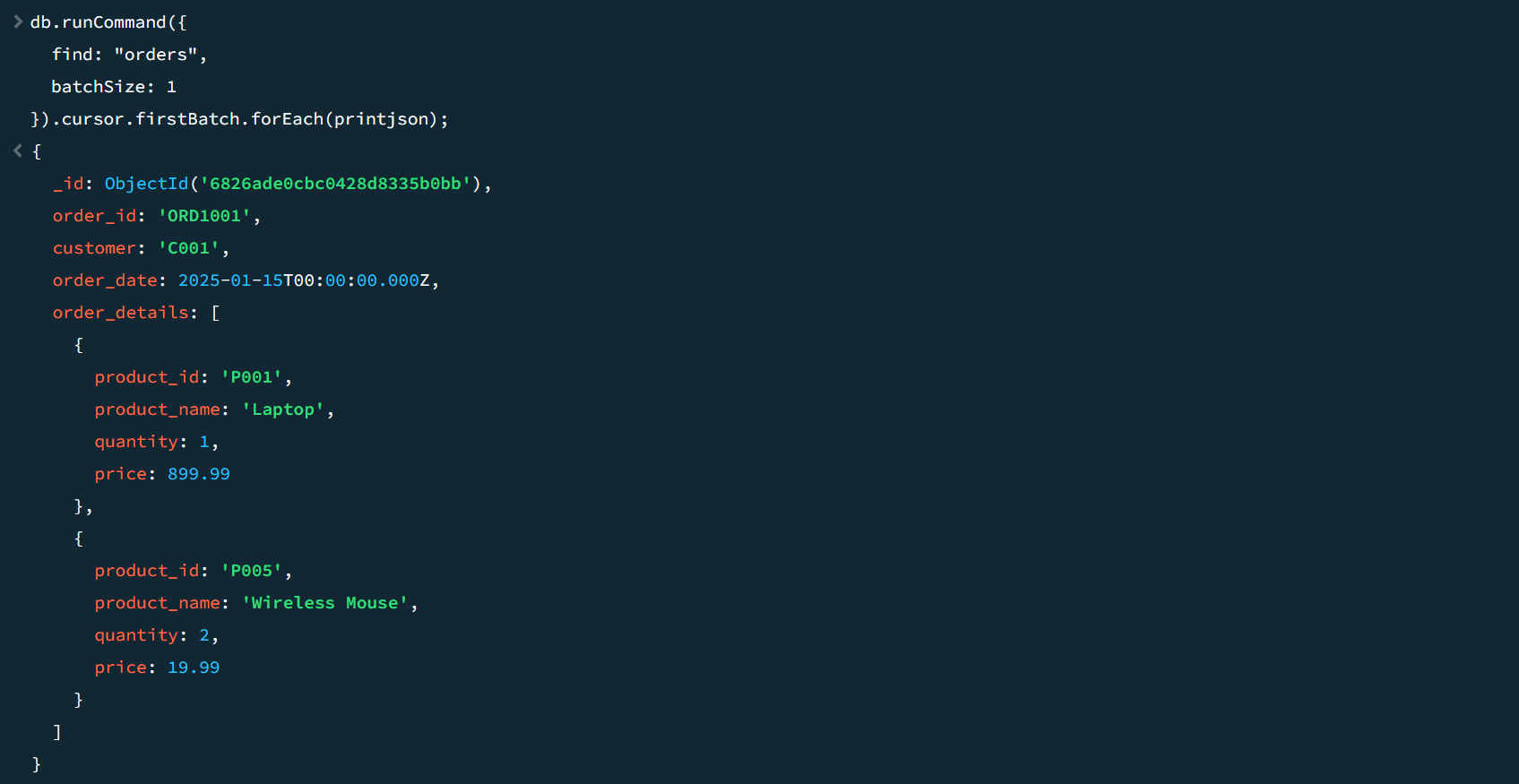
Orders 集合存储了订单相关信息,其结构和内容如下:
{
"_id": {
"$oid": "6826ade0cbc0428d8335b0bb"
},
"order_id": "ORD1001",
"customer": "C001",
"order_date": {
"$date": "2025-01-15T00:00:00.000Z"
},
"order_details": [
{
"product_id": "P001",
"product_name": "Laptop",
"quantity": 1,
"price": 899.99
},
{
"product_id": "P005",
"product_name": "Wireless Mouse",
"quantity": 2,
"price": 19.99
}
]
}现在要查询:orders 集合中订单金额前 3 的客户
SPL 脚本:
|---|-----------------------------------------------------------------|
| | A |
| 1 | =mongo_open("mongodb://127.0.0.1:27017/raqdb") |
| 2 | =mongo_shell@d(A1,"{'find':'orders'}") |
| 3 | =A2.groups(customer; order_details.sum(quantity*price):amount) |
| 4 | =A3.top(3,-amount) |
A1:连接 MongoDB
A2:查询 orders 数据,@d 表示返回成序表。
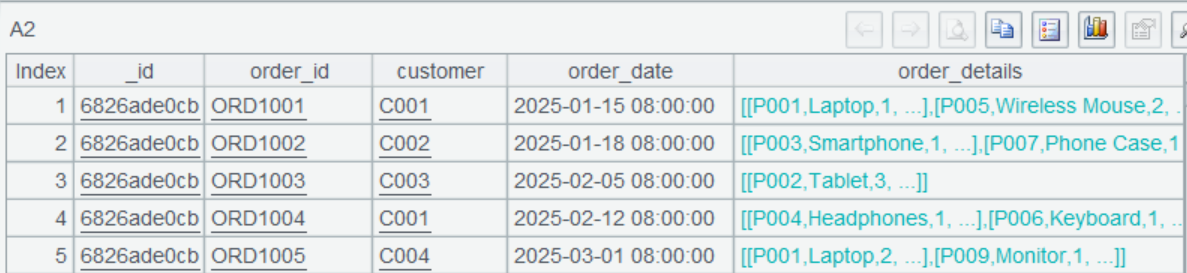
这是一个多层结构,其中一个 order_details 展开,与之前处理的 JSON 结构是类似的。

A2 执行的命令完全是 MongoDB 的原生语法,我们在 MongoShell 中执行看:
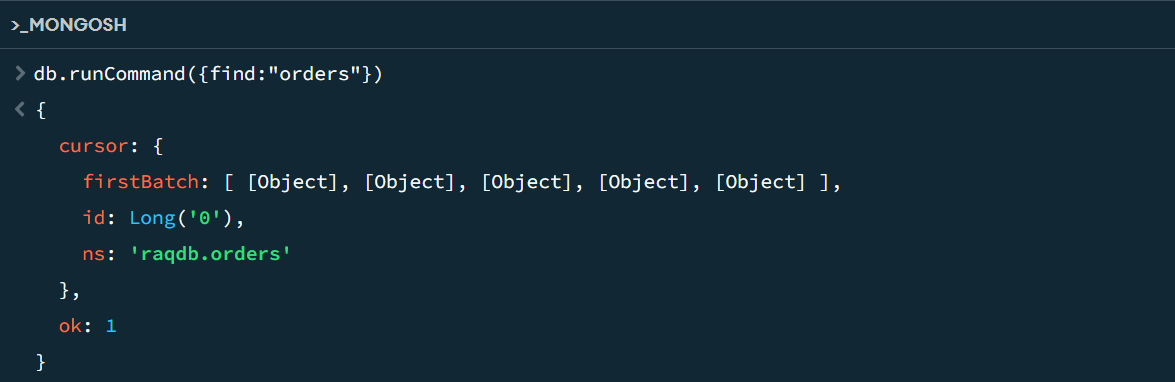
成功返回了游标。取出 1 条看看:
A3:按客户分组汇总订单金额,后续的计算就都一样了。
A4:使用 top 函数取前 3 大客户
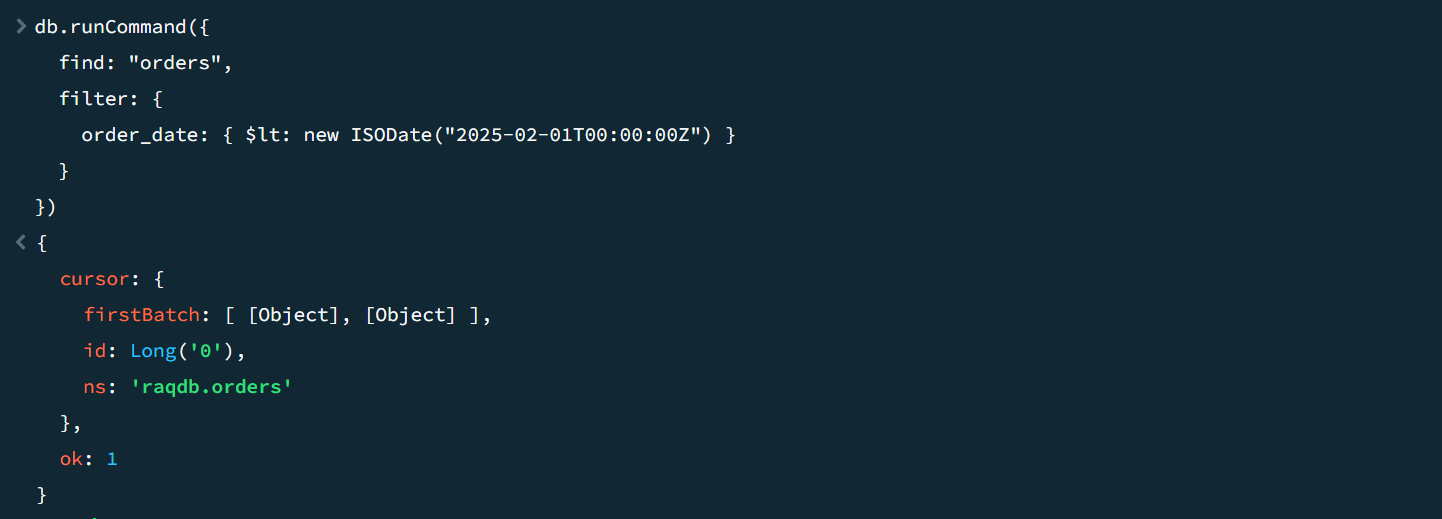
我们再做个过滤,查询 2025-02-01 之前的订单。
A2 改成:
=mongo_shell@d(A1,"{'find':'orders',filter: {order_date: { $lt: new ISODate('2025-02-01T00:00:00Z') } }}")
运行结果:

在 MongoDB 中执行同样的命令,可以得到相同的结果。
这里以 MongoDB 来举例说明 SPL 连接特殊数据源时的处理方式。其他数据源也是类似配置外部库,然后使用对应的原生语法访问即可。
比如读取 Kafka 数据:
|---|-------------------------------------------------------|
| | A |
| 1 | =kafka_open("/kafka/my.properties", "topic1") |
| 2 | =kafka_poll(A1) |
| 3 | =A2.derive(json(value):v).new(key, v.fruit, v.weight) |
| 4 | =kafka_close(A1) |
访问 Elasticsearch:
|---|--------------------------------------------------------------------------------------------------------|
| | A |
| 1 | >apikey="Authorization:ApiKey a2x6aEF......KZ29rT2hoQQ==" |
| 2 | '{"counter": 1,"tags": "red" ,"beginTime":"2022-01-03","endTime":"2022-02-15"} |
| 3 | =es_rest("https://localhost:9200/index1/_doc/1", "PUT",A2;"Content-Type: application/x-ndjson",apikey) |
| 4 | =json(A3.Content) |
访问 HDFS:
|---|------------------------------------------------|
| | A |
| 1 | =hdfs_open("hdfs://192.168.0.8:9000", "root") |
| 2 | =hdfs_file(A1,"/user/root/orders.txt":"UTF-8") |
| 3 | =A2.read() |
| 4 | =A2.import@t() |
SPL 这种 Native 接口 + 简单封装的方式简单方便,可以保留数据源的特点,充分利用其存储和计算能力,不需要先把数据做"某种"入库动作,实时访问就可以;用户想要扩展也不难。但读数是写在 SPL 脚本里的,而且使用了原生接口,这就意味着如果数据源变化时还要修改脚本,没法做到像逻辑数仓那样对底层数据源完全透明。
逻辑数仓的数据源接入依赖的专用连接器,可以做到完全对底层透明。但连接器要针对每种数据源单独开发,复杂度很高,导致可用 Connector 数量明显不多,用户自行基于开源代码再开发的难度也很大,往往要等厂商支持。
逻辑数仓专用 Connector 和 SPL 使用 Native 接口简单封装没有好坏之分,前者可以做更深层次的支持和优化,可以做到一定程度的透明化;后者则更加灵活,支持的数据源丰富且扩展灵活,要根据具体需要选择。
至此我们已经学会了用 SPL 查询数据库、CSV/XLS、Restful/JSON、MongoDB,这些数据接入后都可以进行混合计算了。
esProc SPL是开源免费的,下载试用~