openssl-aes-ctr使用openmp加速
- openssl-aes-ctr
- [openmp omp for](#openmp omp for)
openssl-aes-ctr
本文采用openssl-1.1.1w进行开发验证开发;因为aes-ctr加解密模式中,不依赖与上一个模块的加/解密的内容,所以对于aes-ctr加解密模式是比较适合进行并行加速的算法。
其代码如下
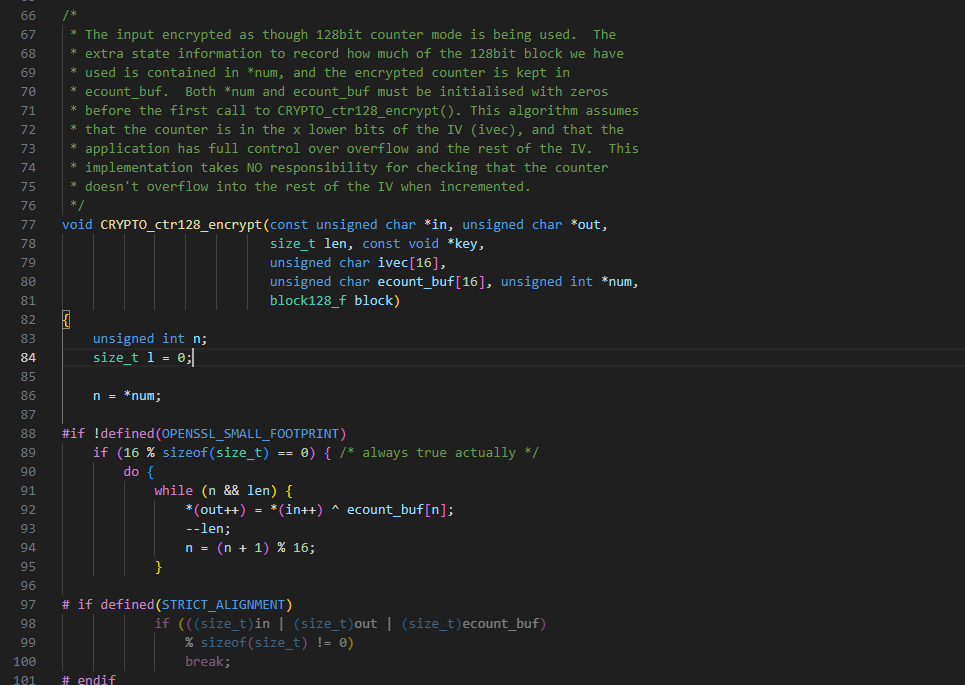
void CRYPTO_ctr128_encrypt(const unsigned char *in, unsigned char *out,
size_t len, const void *key,
unsigned char ivec[16],
unsigned char ecount_buf[16], unsigned int *num,
block128_f block) {
...
while (len >= 16) {
(*block) (ivec, ecount_buf, key); // encrypt
ctr128_inc_aligned(ivec); // ivec = ivec + 1
for (n = 0; n < 16; n += sizeof(size_t)) // out = in ^ ecount_buf
*(size_t_aX *)(out + n) =
*(size_t_aX *)(in + n)
^ *(size_t_aX *)(ecount_buf + n);
len -= 16;
out += 16;
in += 16;
n = 0;
}
...
}
从代码不难看出,每层循环,以16字节为一组进行加密;组与组之间不存在关联,下一组变更的只有ivec,所以对其进行加速处理,可以考虑并行处理的方式进行并行处理。
可以提前计算好ivec,ivec+1,ivec+2,...,ivec+255;此处因为单次加解密的长度是4096,所以函数内最长为256组会在一次函数调用中进行加解密。
openmp omp for
使用#pragma omp parallel for 对加密过程进行并行加速处理,处理过程中,在进入for循环前,首先将ivec的值都计算好
int loop = len / 16;
unsigned char * new_ivec[4096]; // 此处有待优化,实际调用长度可能会超过4096
memcpy(new_ivec, ivec, 16);
for (int i = 1; i < loop; i++) {
memcpy(new_ivec + 16*i, new_ivec + 16*i - 16, 16);
ctr128_inc_aligned(new_ivec + 16*i);
}然后就是对分组进行并行加密处理
#pragma omp parallel for num_threads (16) private(n)
for (int i = 0; i < loop; i++) {
unsigned char current_ecount_buf[16] = {0};
(*block) (new_ivec + 16*i, current_ecount_buf, key);
unsigned char * current_in = in + 16*i;
unsigned char * current_out = out + 16*i;
for (n = 0; n < 16; n += sizeof(size_t))
*(size_t_aX *)(current_out + n) =
*(size_t_aX *)(current_in + n)
^ *(size_t_aX *)(current_ecount_buf + n);
}修改过后的函数如下:
void CRYPTO_ctr128m_encrypt(const unsigned char *in, unsigned char *out,
size_t len, const void *key,
unsigned char ivec[16],
unsigned char ecount_buf[16], unsigned int *num,
block128_f block)
{
unsigned int n;
size_t l = 0;
n = *num;
#if !defined(OPENSSL_SMALL_FOOTPRINT)
if (16 % sizeof(size_t) == 0) { /* always true actually */
do {
while (n && len) {
*(out++) = *(in++) ^ ecount_buf[n];
--len;
n = (n + 1) % 16;
}
# if defined(STRICT_ALIGNMENT)
if (((size_t)in | (size_t)out | (size_t)ecount_buf)
% sizeof(size_t) != 0)
break;
# endif
int loop = len / 16;
unsigned char * new_ivec[4096];
memcpy(new_ivec, ivec, 16);
for (int i = 1; i < loop; i++) {
memcpy(new_ivec + 16*i, new_ivec + 16*i - 16, 16);
ctr128_inc_aligned(new_ivec + 16*i);
}
#pragma omp parallel for num_threads (16) private(n)
for (int i = 0; i < loop; i++) {
unsigned char current_ecount_buf[16] = {0};
(*block) (new_ivec + 16*i, current_ecount_buf, key);
unsigned char * current_in = in + 16*i;
unsigned char * current_out = out + 16*i;
for (n = 0; n < 16; n += sizeof(size_t))
*(size_t_aX *)(current_out + n) =
*(size_t_aX *)(current_in + n)
^ *(size_t_aX *)(current_ecount_buf + n);
}
len -= loop * 16;
out += loop * 16;
in += loop * 16;
n = 0;
if (len) {
(*block) (ivec, ecount_buf, key);
ctr128_inc_aligned(ivec);
while (len--) {
out[n] = in[n] ^ ecount_buf[n];
++n;
}
}
*num = n;
return;
} while (0);
}
/* the rest would be commonly eliminated by x86* compiler */
#endif
while (l < len) {
if (n == 0) {
(*block) (ivec, ecount_buf, key);
ctr128_inc(ivec);
}
out[l] = in[l] ^ ecount_buf[n];
++l;
n = (n + 1) % 16;
}
*num = n;
}经过以上处理后,需要进行测试,本文采用给openssl,增加enc子命令的方式进行处理,通过增加aria-128-ctrm的方式,而后进行测试验证。
从测试结果看,确实能提高一定的性能,但效果不是很显著,大概可能和加解密时长,占openssl enc整个命令调用时长的占比不是很高,所以没有显著的性能提升。
尽管效果不是很明显,也算是针对openmp和openssl-aes-ctr的一次结合应用。