第1章 Instruction
在人工智能领域、多模态只语言模型的发展正迎来新的篇章。传统的大型语言模型(LLM)在理解和生成人类语言方面展现出了卓越的能力,但这些能力通常局限于 文本处理。然而,现实世界是一个本质上多模态的环境,生物体通过视觉、语言、声音和触觉等多种渠道感知和交换信息。在这样的背景下,一个有前景的目标是增强LLM,使其具备多模态感知能力。
最近的研究如Emu、SEED-LLaMA日和SpeechGPT已经在使 语言模型具备多模态理解和生成的能力上取得了重要进展。然而,这些模型仅集成了单一的非文本模态,如图像或音频。虽然将文本与一个额外的模态对齐相对简单,但在单一框架内整合多个模态 (N>3)并实现它们之间的双向对齐则是一个更为艰巨的挑战。
为了克服这些挑战,研究者推出了AnyGPT,一个任意到任意的多模态语言模型。
AnyGPT是一种多模态语言模型,通过离散表示统一处理语音、文本、图像和音乐等模态,无需改变LLM架构或训练范式。它依赖数据预处理,便于新模态无缝集成。通过以多模态文本为中心,包含10.8万个多轮对话样本的任意到任意多模态指令数据集。实验表明,AnyGPT在各模态性能与专门模型相当,验证了离散表示的有效性和便利性。
第二章 研究背景
2.1 实验动机
LLM的局限:
近年来,大语言模型(LLMs)在文本理解与生成上取得了巨大成功。但它们通常只能处理纯文本输入输出。
多模态的现实世界:
现实世界本质上是多模态的,生物体通过多种渠道感知和交换信息,包括视觉、语言、声音和触觉。
多模态LLM的局限:
基于 Transformer 的多模态基础模型 ,它可以在多模态语境中无缝生成图像和文本。
SpeechGPT 能够同时处理语音和文本输入,生成语音和文本输出,支持语音识别、语音合成、语音翻译等任务。
SEED-LLaMA 将图像离散化为一维视觉标记的机制,使得图像能够与文本一样,在自回归 Transformer 架构中进行处理。
2.2 挑战

2.3 解决方法
1.我们提出AnyGPT,一种基于令牌的任意到任意多模态语言模型,可以理解和生成各种模态,包括语音、文本、图像和音乐。
2.一个关键挑战是缺乏多模态交错指令跟随数据。我们开发了一个使用生成模型的管道来构建AnyInstruct-108k,这是一个包含108k个多轮对话的多模态交错元素的数据集。
3.我们证明了离散表示可以有效地在一个语言模型中统一多种模态。
第三章 实验方法
模型架构图
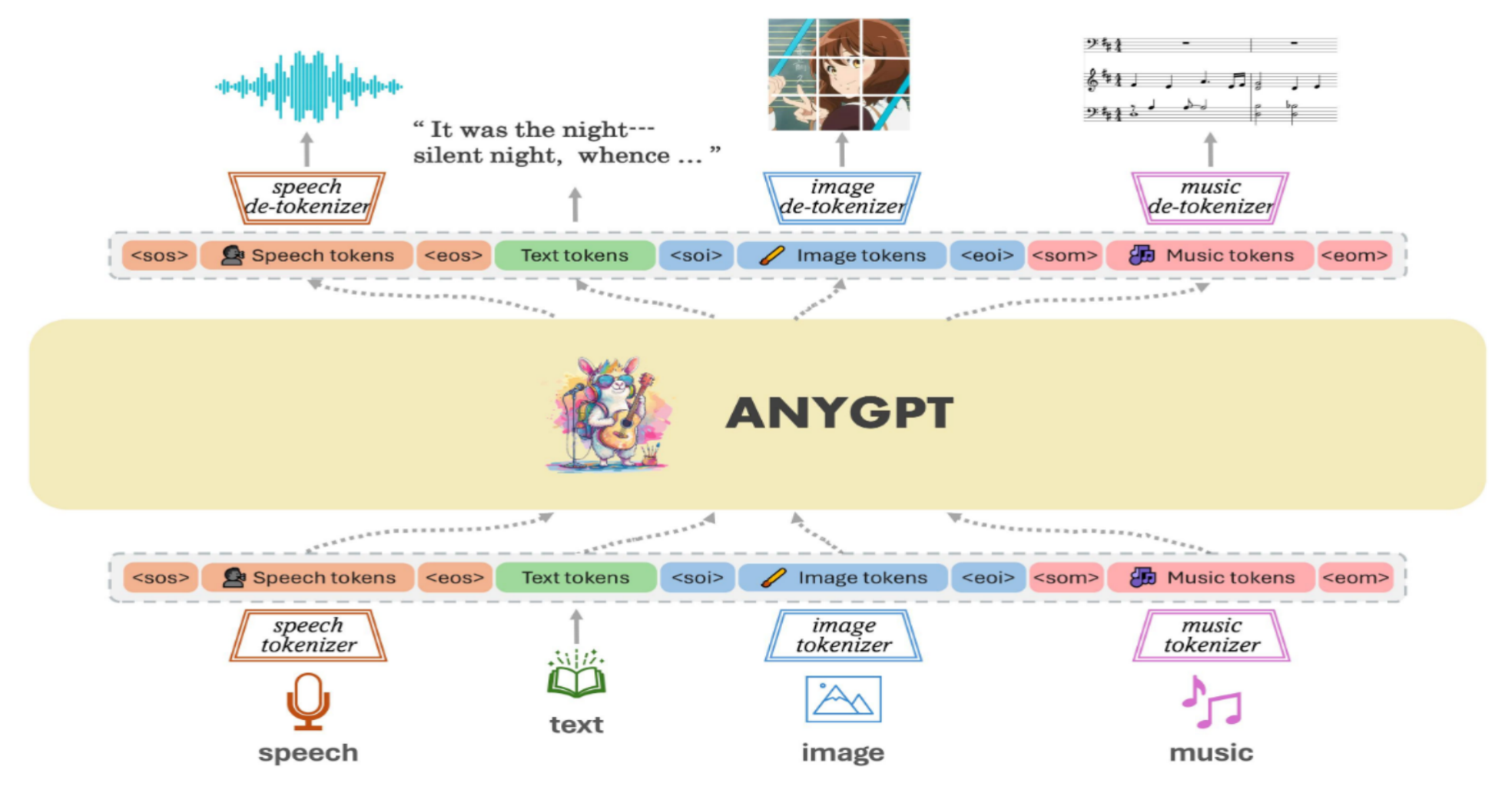
3.1 基础模型
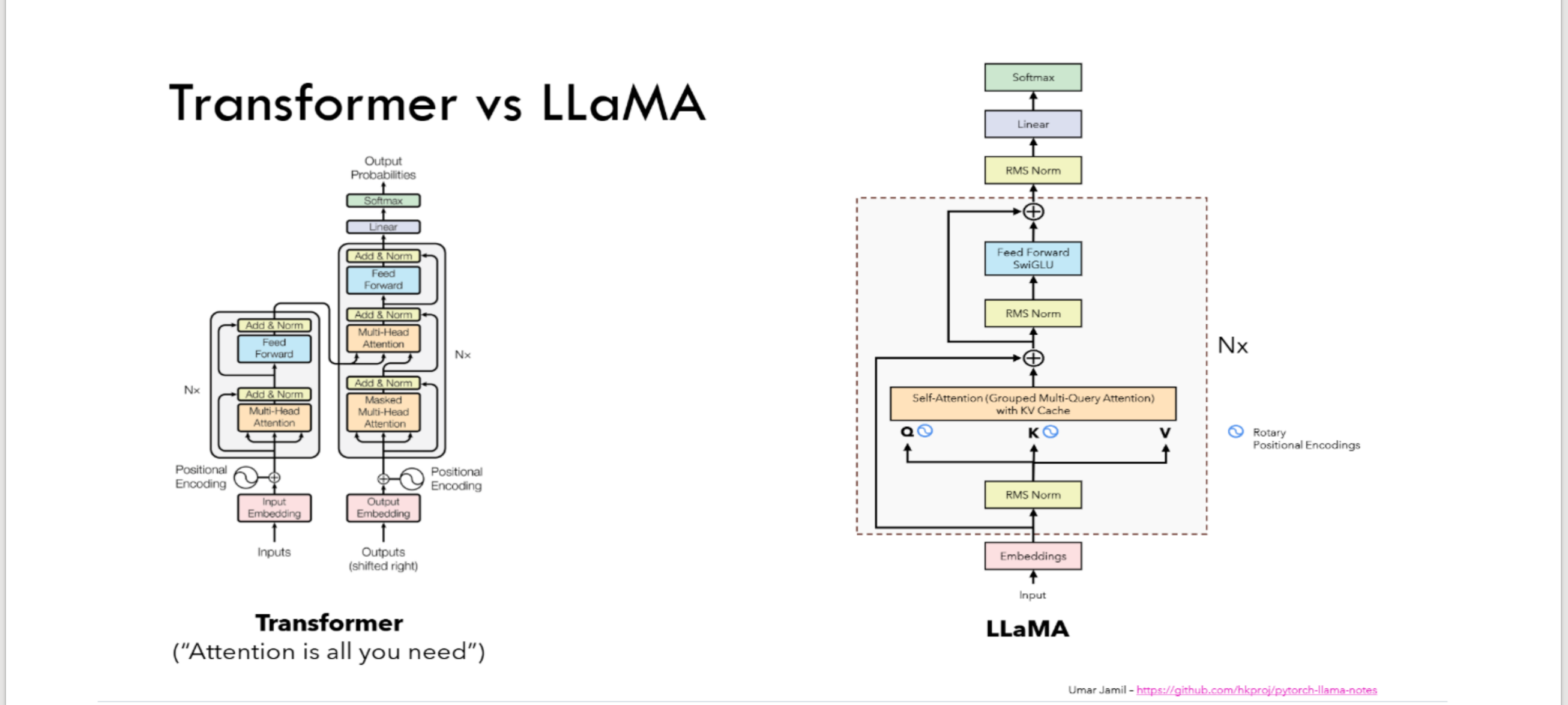
LLaMa2
结构图:
模型参数:
| Transformer blocks | 32层 |
| Token Embedding | 4096 |
| 注意力头数 | 32 |
| head dim | 128 |
| 前馈层维度 | 11008 |
| vocab size | 46000+(原始32,000) |
| 最大上下文长度 | 4096 |
| 前馈层激活函数 | SwiGLU |
| 正则化 | RMSNorm |
| 位置编码 | RoPE旋转位置编码(应用于Q,K) |
| 预训练量 | 2 TB token |
对比传统LLM:
- SwiGLU激活函数
结合Swish和GLU形成一个带自门控的激活结构更细致控制信息流 + 激活。 - RMSNorm正则化
对比LayerNorm,RMSNorm只用均方根归一化更高效,更稳定。 - RoPE旋转位置编码
将位置信息"旋转"地融合进 attention 中的 Q、K 向量,使得 dot(Q, K) 自带相对位置信息。
对比LLaMa1:
- 结构上大体一致,使用Adamw优化器。
- 使用更大更干净的训练集(RefinedWeb、Books、RedPajama)
RMSNorm
和 LayerNorm 不同,RMSNorm 只用均方根(RMS)来归一化,不去中心化。
x: 输入向量(如 B, T, D 中的一行)d: 向量维度γ: 可学习的缩放参数(形状为 d)ϵ: 防止除零的小常数(如 1e-6)

优势:
- RMSNorm省去了计算均值的步骤,减少了计算量。
- RMSNorm的梯度方差更小,有助于缓解梯度爆炸或消失问题,尤其在深层Transformer中。
RoPE
对Q,K 向量应用 RoPE,使其编码位置信息
构建旋转频率(θ)和位置索引
计算旋转角度(频率 × 位置)
计算 sin 和 cos 表
将输入向量按维度拆成偶数维 + 奇数维对
执行二维旋转

传统方法的缺陷:
绝对位置编码:只能标记每个token的绝对位置,难以直接建模token之间的相对关系(如距离、方向)。
相对位置编码:需要手动设计相对位置偏置,且通常受限于预设的窗口大小(如128),无法处理超长序列。
RoPE的解决方案: 通过旋转操作,将位置信息以角度形式注入查询(Query)和键(Key)向量中。
关键特性: 两个token之间的注意力分数仅依赖于它们的相对位置差(旋转角度的差值),因此天然支持相对位置关系,同时隐含了绝对位置信息。
SwiGLU
假设输入是 x,维度为 B, T, D
先通过一个线性层扩展成B, T, 2\*H
拆分成x1 和 x2,每个维度 B, T, H
x1经过Swish 激活函数 B, T, H
与x2逐元素相乘 B, T, H
最后经过线性层映射回维度 B, T, D

SwiGLU优势:
1.更平滑的梯度:Swish 比 Sigmoid 更平滑,训练更稳定。
2.更强的非线性表达能力:Swish 允许少量负值通过,避免 ReLU 的"死神经元"问题。
3.自适应门控:Swish 的 β 参数可学习,动态调整门控强度。
3.2 Tokenizer
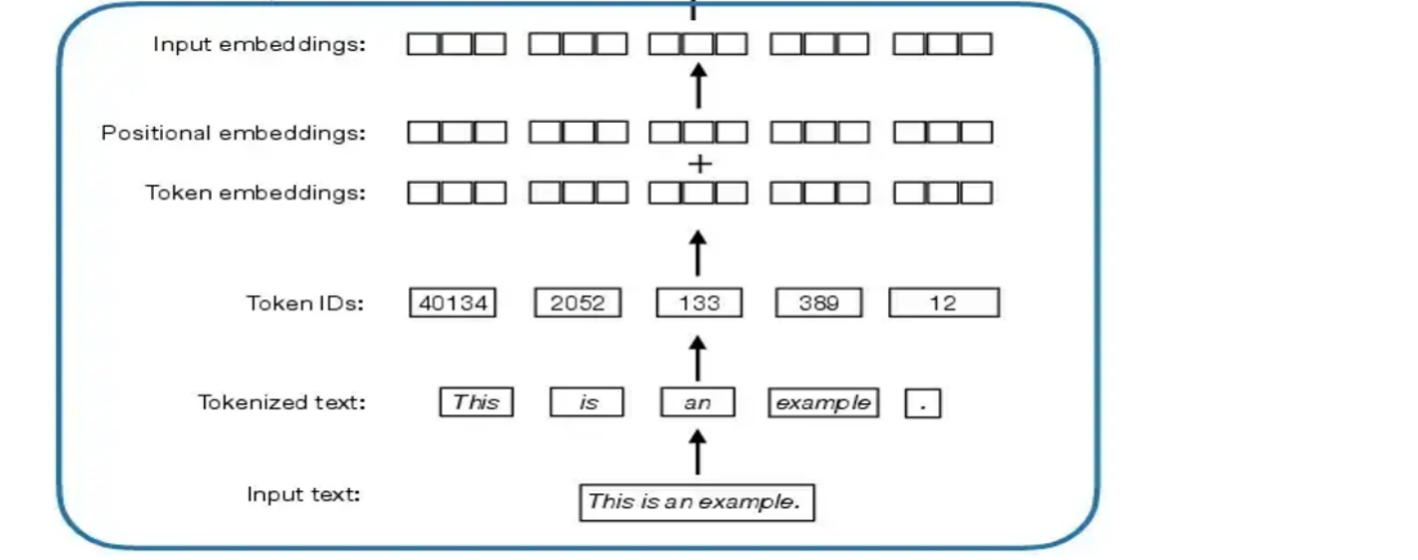
Tokenization
不同模态在编码时,不同参数要求。

TextTokenizer
SentencePiece-BPE
类型:基于字节(byte-level) 的 BPE
词表大小:32,000
分词方式:子词(subword),不会强制按单词边界切割
支持空格、标点、特殊符号编码(空格会被编码为 ▁)
所有文本输入先被转成 UTF-8 字节序列,再进行 BPE 分词
可处理多种语言,编码效率高,支持任意字符串,无需分词器依赖词典。
试例
Text :"你好,LLaMA 2!"
Split: '▁你好', ',', 'L', 'La', 'MA', '▁2', '!'
Decode: 1132, 984, 28, 419, 297, 4225, 800
ImageTokenizer
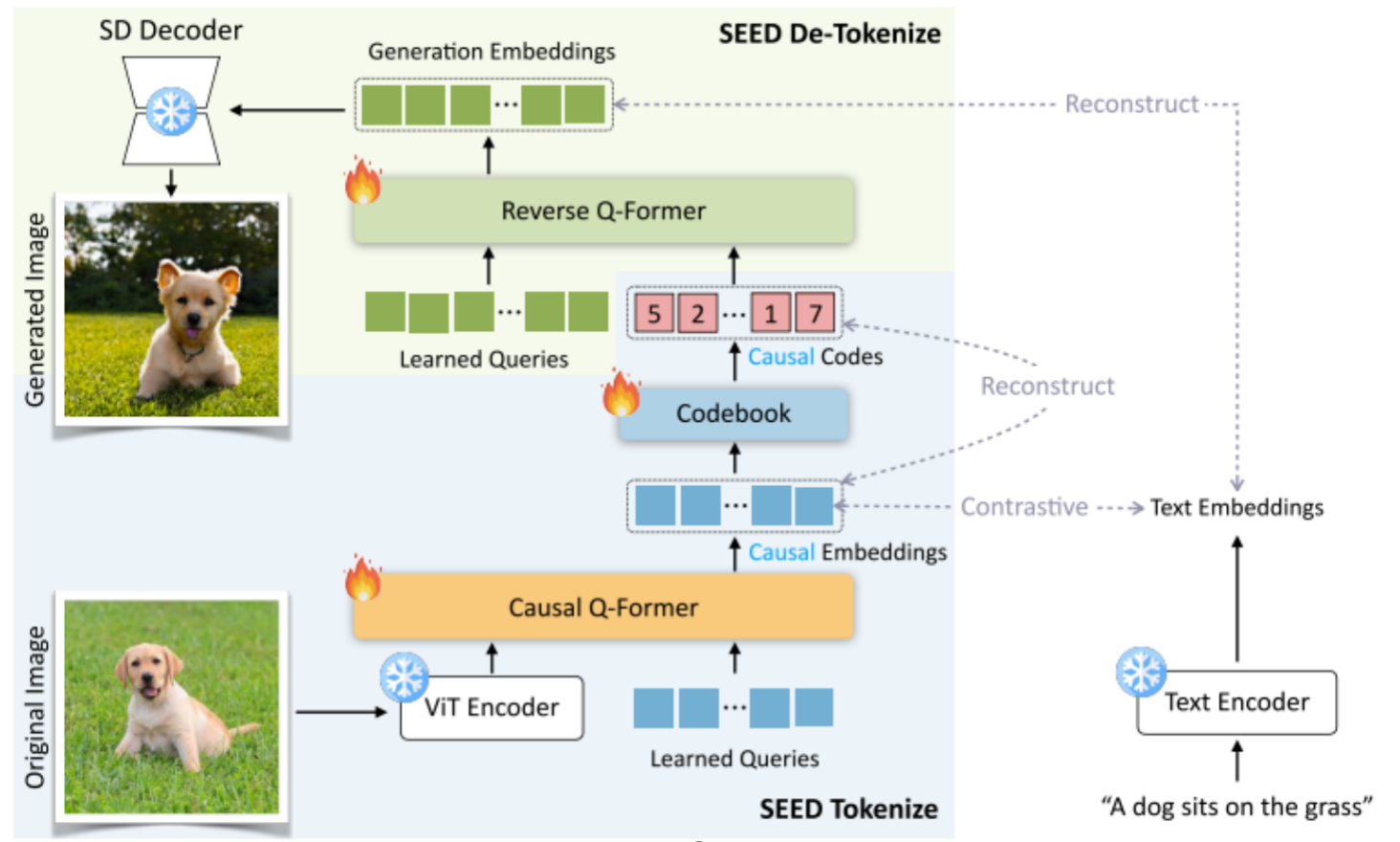
SEED Tokenizer
词表大小:8192
输入图片固定长度3224 224
ViT风格为卷积层,卷积核大小为16*16,步长16,个数为196。
因果 Q-Former类似于多头注意力,预先生成QB, 32, 1024,ViT结果作为KV,经过Cross-Attn,输出B, 32, 1024进入Causal-Attn生成掩码。
MLP相当于前馈层结构为Linear(1024,4096) → GELU → Linear(4096,1024),提升模型表达能力,让每个token的表示变得更复杂、更抽象。
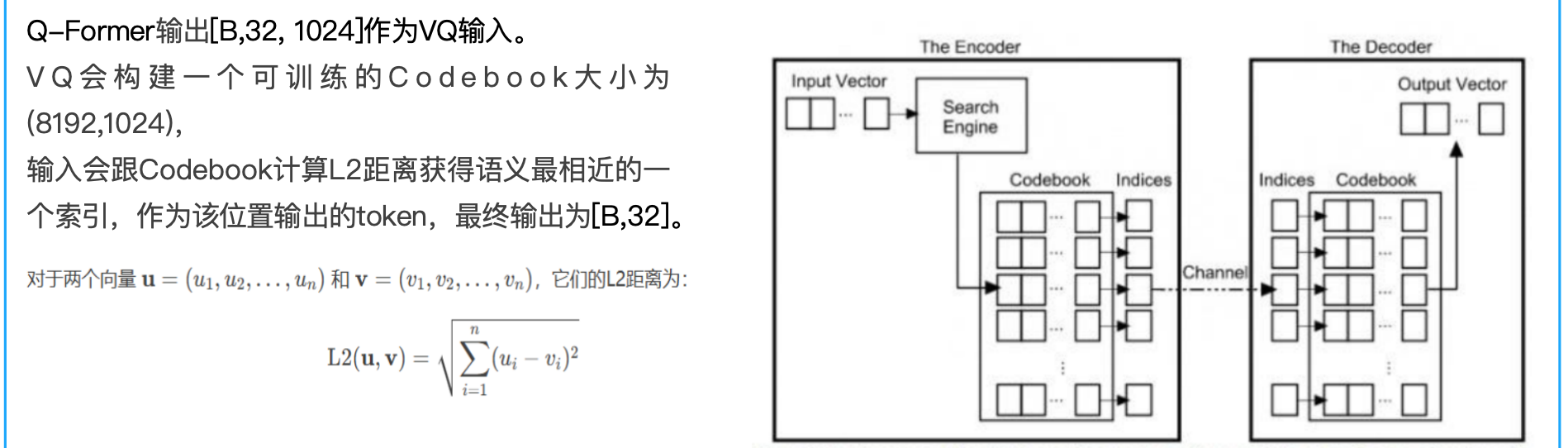
VQ 编码器 构建Codebook(8192,1024),计算每个token对于Codebook的L2距离,找到距离最近codebook向量作为输出。
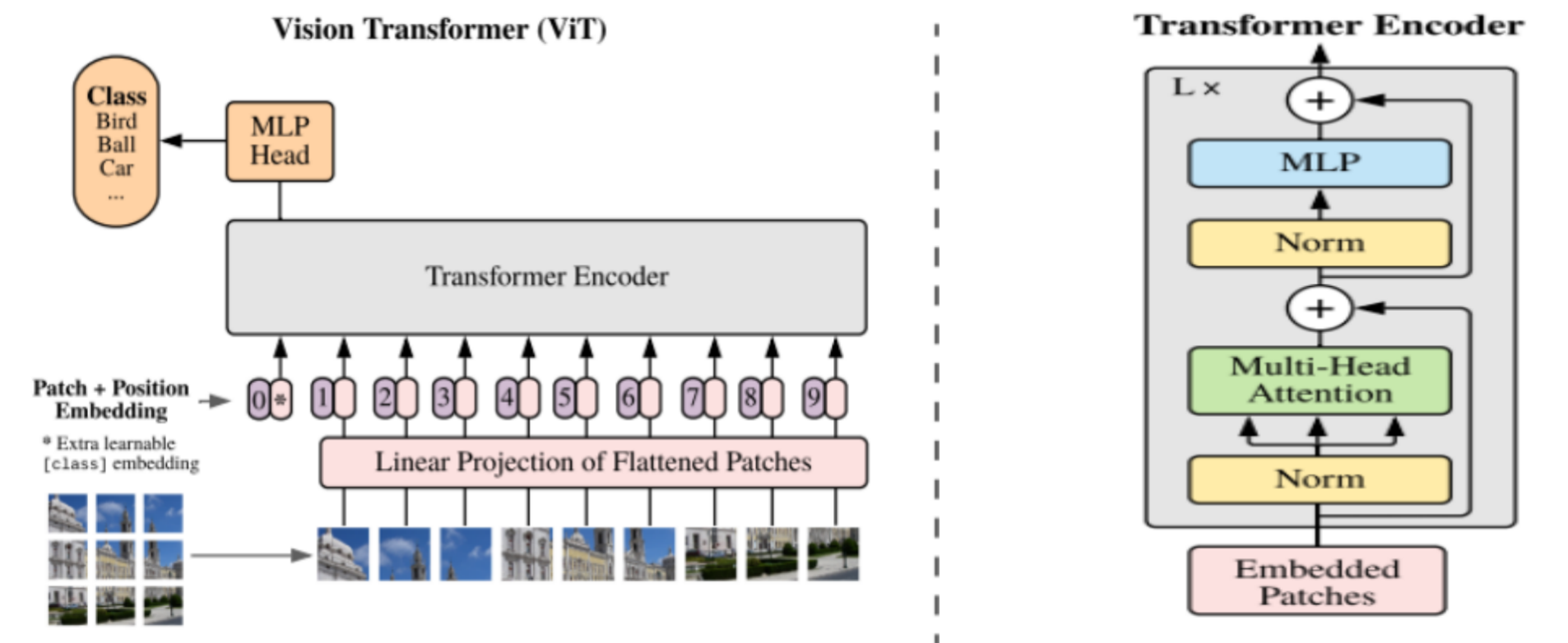
Vision Transformer
输入图片固定长度3224 224
ViT风格为卷积层,卷积核大小为16*16,步长16,个数为196
卷积层输出196,16,16,3展平为196,768。
卷积层结果经过线性层输出为196, 1024。
先性层输出加上绝对位置编码输出为196, 1024。
经过ViT Encoder,24层transformer block,
输出为196, 1024。
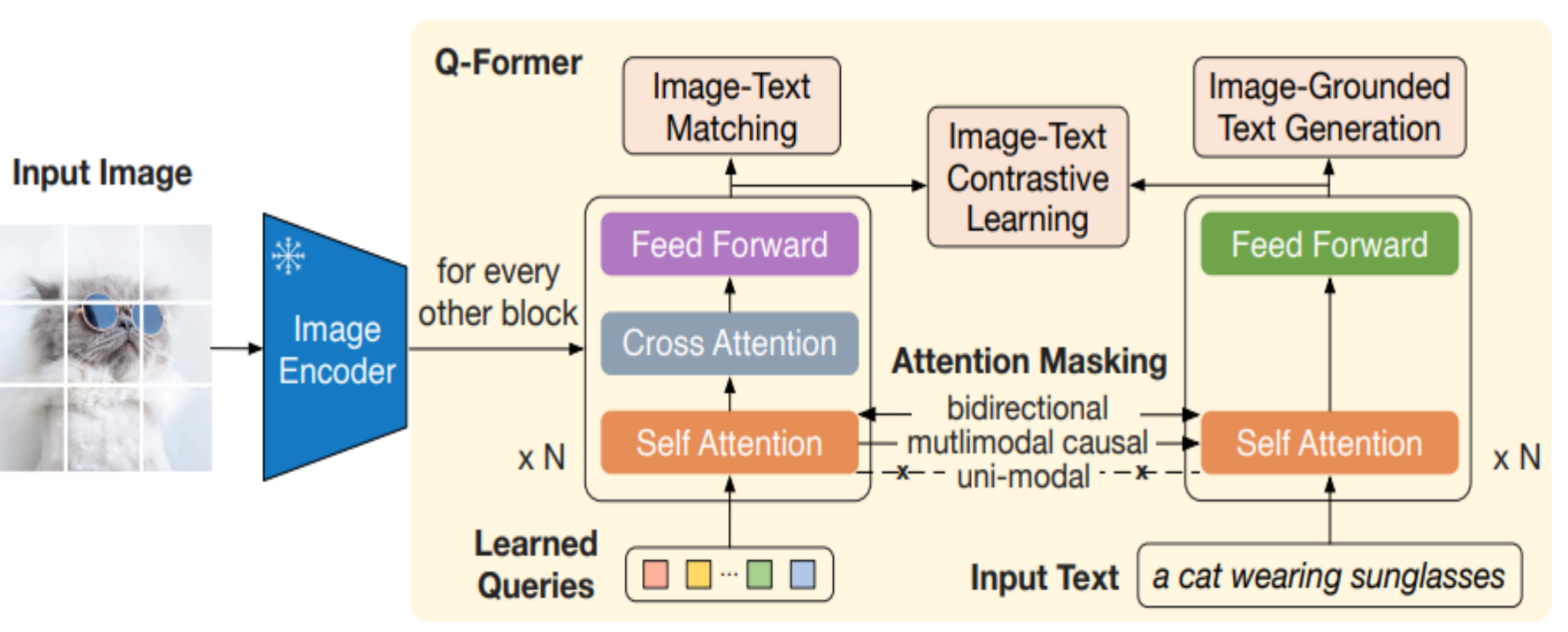
Q-Former
ViT输出B,196, 1024作为Q-Former输入。
Q-Former会创建一个可学习的查询矩阵q_w32,1024
,k_w,v_w冻结,经过qkv线性投影层后输入到交叉注意力,输出为B,32, 1024。
输入到因果注意力中,输出为B,32, 1024。
MLP相当于前馈层结构为Linear(1024,4096) → GELU → Linear(4096,1024),提升模型表达能力,让每个token的表示变得更复杂、更抽象。
共有6个transformer block。
VQ量化器
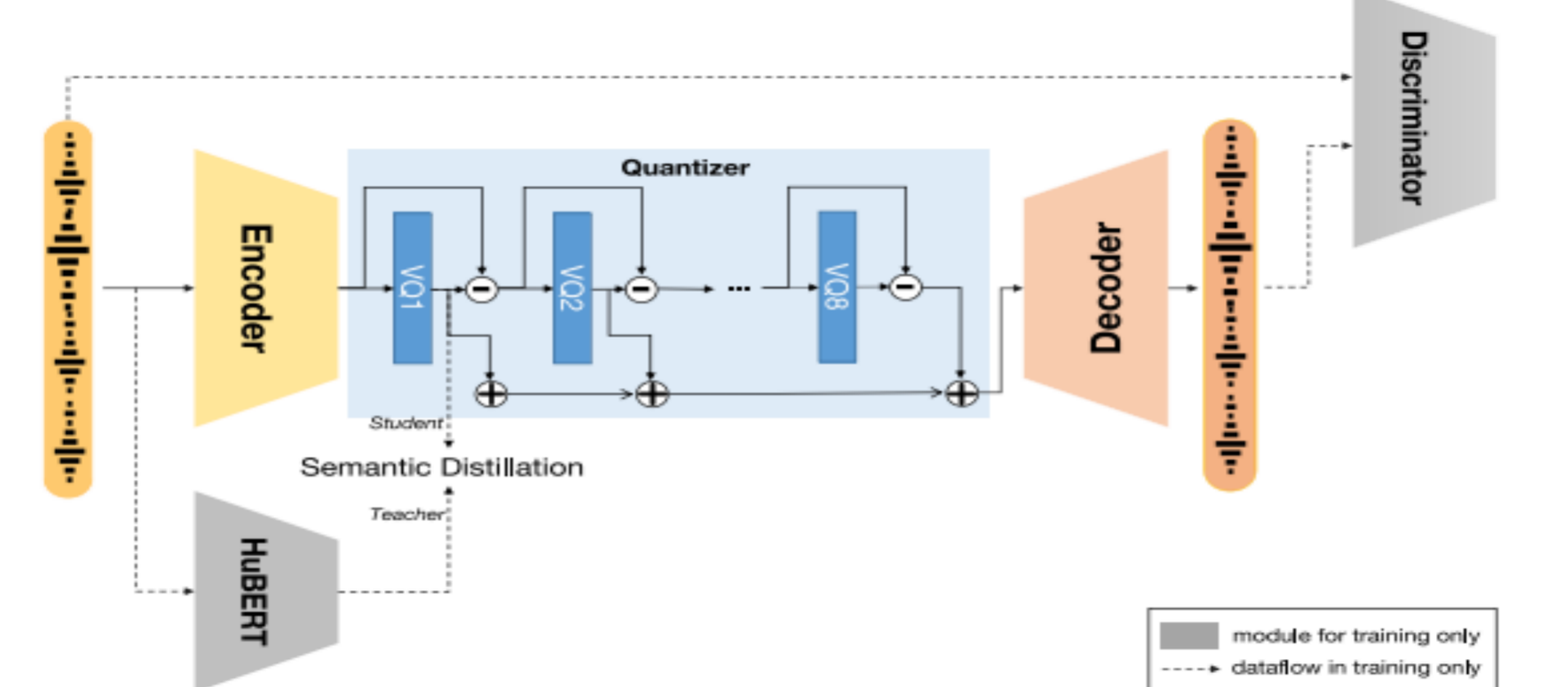
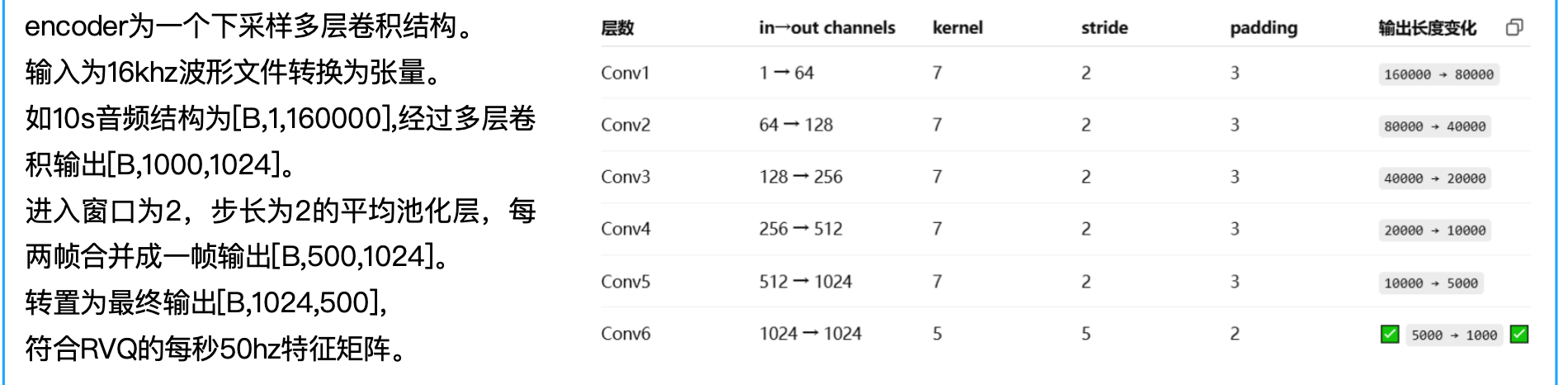
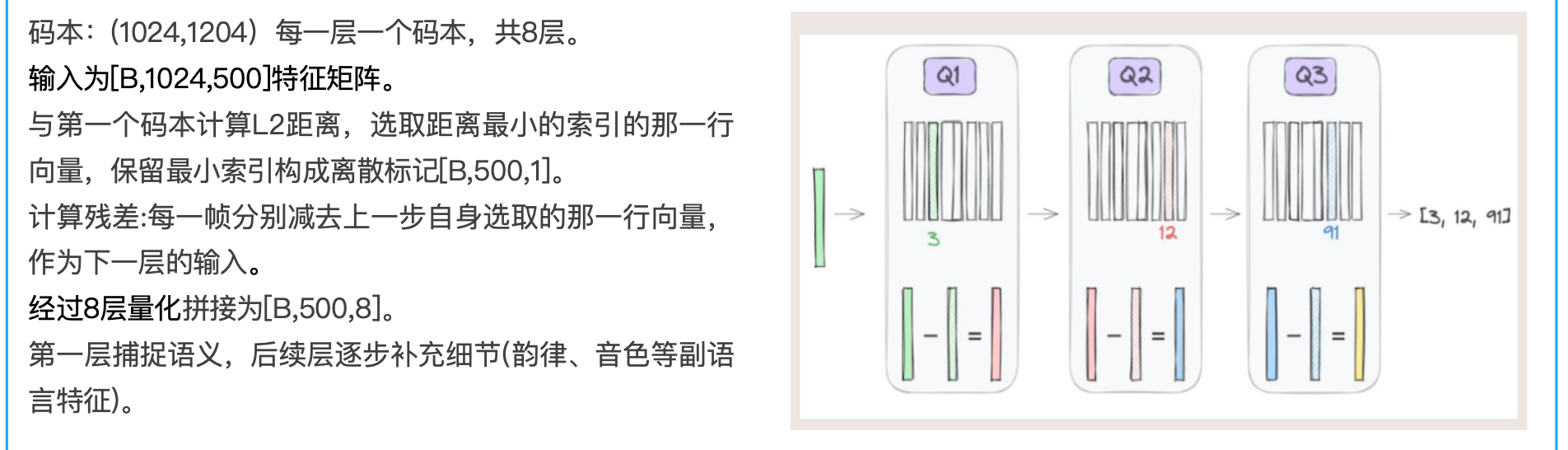
SpeachTokenizer
词表大小:1024
码本:(1024,1204)每一层一个码本
原始音频信号经过预处理转成一个连续的帧序列,帧率固定为50Hz。通过编码器得出500, 1024的特征向量,与码本计算L2距离,选取距离最小的索引的条目,计算残差(输入-结果索引条目)作为第二层输入,保留最小索引构成离散标记500,1。最终拼接八层,输出离散标记矩阵。
第一层捕捉语义,后续层逐步补充细节(韵律、音色等副语言特征)。
该输出模型只负责语义部分所以token序列为500
Encoder
RVQ
MusicTokenizer
Encodec
词表大小: 8192
码本:(2048,1024)每一层一个码本
例如音频为32 kHz单声道5秒,使用卷积网络将音频划分为潜在帧,50 Hz,(250, 1024),通过RVQ进行4层残差量化得到离散标记矩阵(250,4),最终展开为因果序列。
试例
| 原始音频输入 | (1,160000) |
| Encodec 编码 | (250, 1024) |
| RVQ 量化 | (250, 4) |
| 展平序列 | (1000,1) |
| 起止标识 | token序列 |
3.3 Detokenizer
Text DeTokenizer
使用LLaMa2 7B模型自身的文本词汇表,解码生成文本。
将 token ID 序列 → 查词表 → 拼接子词 → 还原自然语言文本。
Image DeTokenizer
模型输出image离散token1,32作为输入。
查码本得到latent32, 1024。
输入Reverse Q-former。与 Q-former结构类似,同样需要一个可学习的q_w1,196,1024,通过多个包含交叉和因果注意力与MLP的transformer block,输出1,196,1024.
经过线性层输出1,196,768,转置后输入符合生成模型的latent1,768,196。
继续进入预训练好的unCLIP Stable Diffusion(unCLIPSD),最后生成高质量图像。
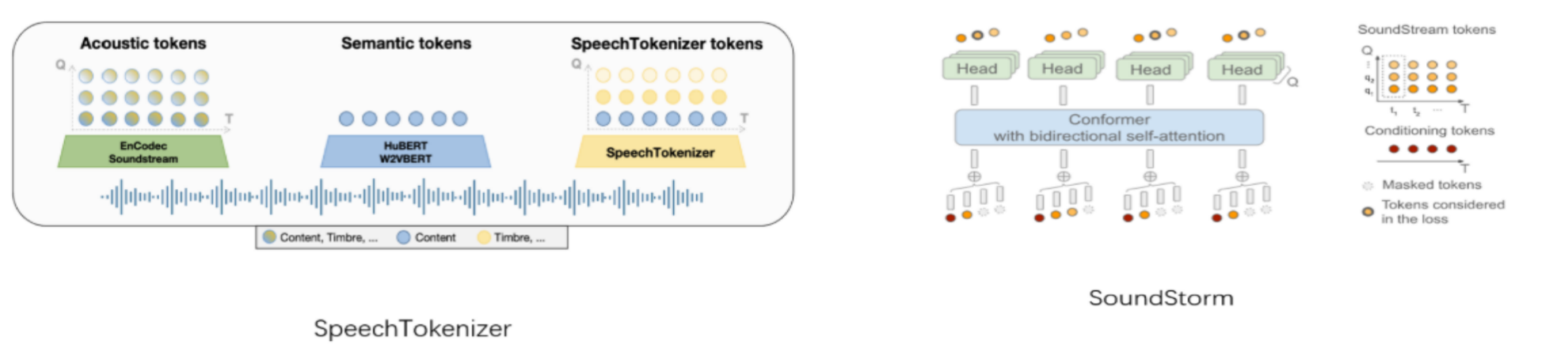
Speach DeTokenizer
Soundstorm
模型输出为离散token序列500。
作为输入进入根据码本预训练好的soundstorm还原Q2~Q8层。
sondstorm为类transform结构包含词嵌入层词向量维度1024,位置编码层,6层transformer block包含6头注意力,归一层,残差链接及前馈层。但仅根据当前输入每一个帧上分别预测各自下一个概率最高的token。
由Q1得到Q2,由Q2得到Q3,最终得到Q8。
反向RVQ
soundstorm还原Q1~Q8输出为500,8。
查询码本,进行残差求和输出为500,1024。
上采样
经过多层反卷积1,160000最终还原成音频文件。
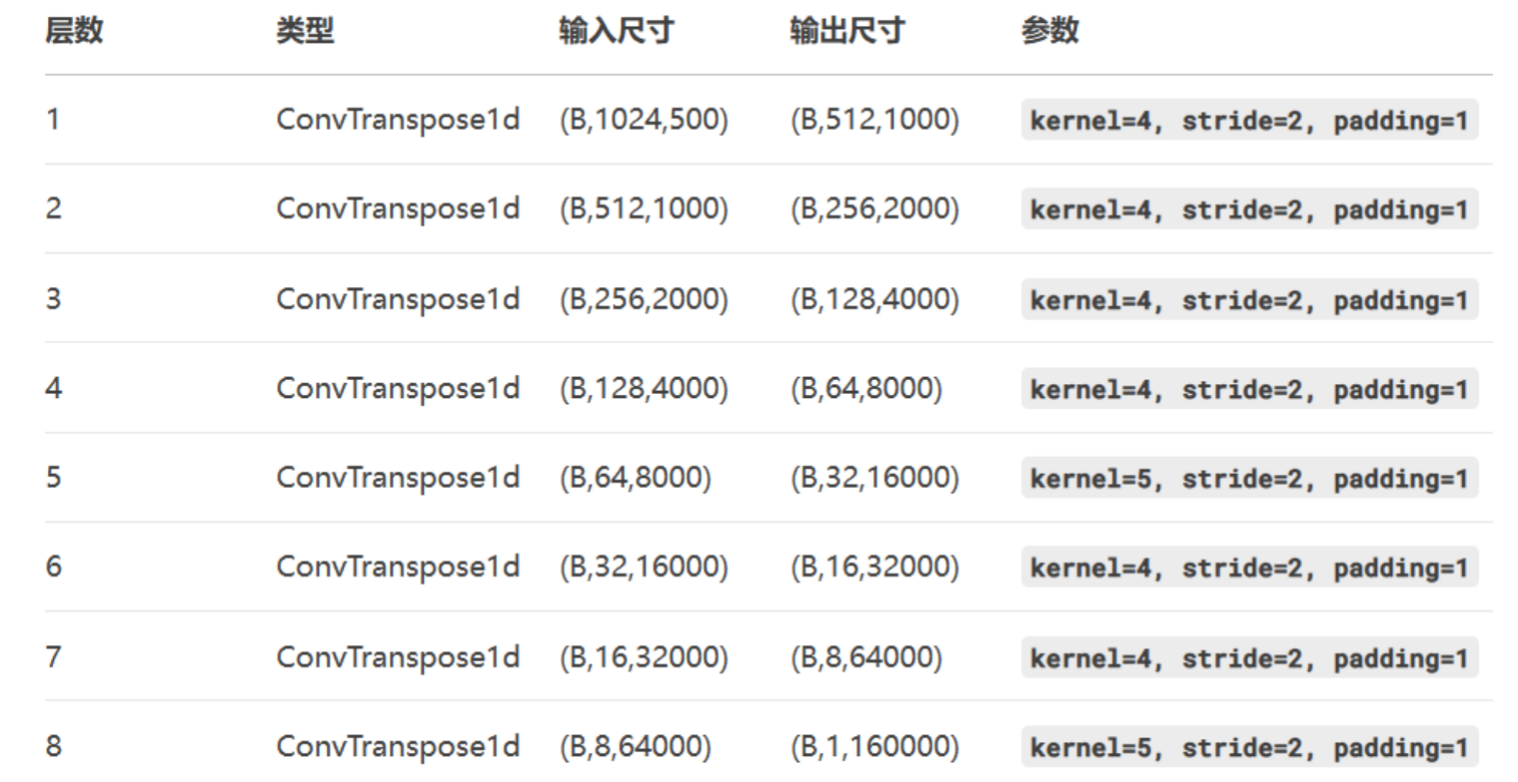
Music DeTokenizer
Encodec
模型输出1000作为输入。
于SpeachTokenizer类似,不需要补全Q1~Q4层
,输入调整为250,4,通过查询码本进行残差求和输出250,1024.
通过上采样,经过多层反卷积还原,原始音乐波形文件。
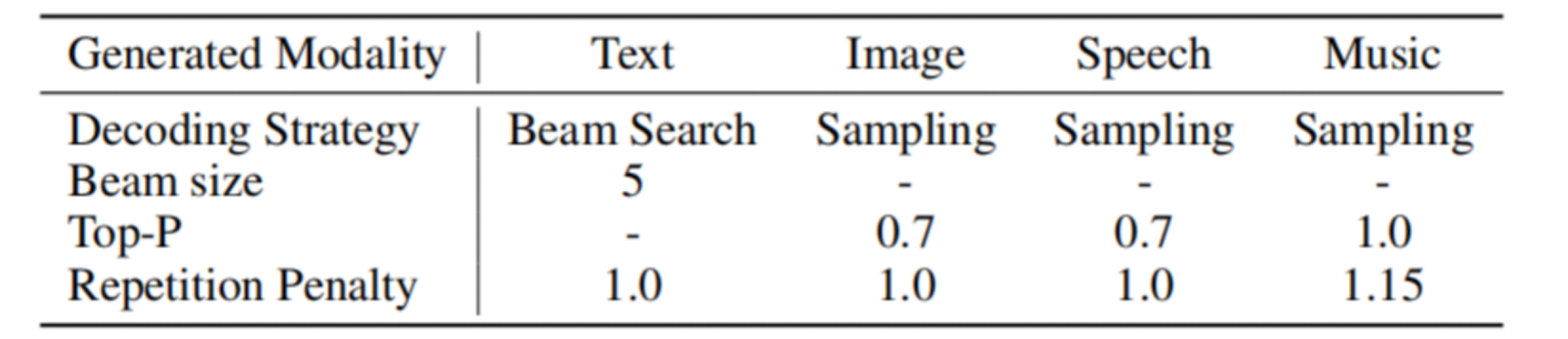
生成解码策略
文本生成
Beam size 为 5,意味着在生成过程中会同时考虑最优的 5 条路径来保留多样性与准确性。Repetition Penalty 为 1.0,未对重复进行惩罚
图像与语音生成
使用 Top-P Sampling 策略,P 值为 0.7:只从概率分布中累计前 70% 的 token 中采样,控制创造力和质量之间的平衡。
音乐生成
P 值设为 1.0:代表不截断采样分布,允许更自由的生成。
Repetition Penalty 为 1.15:略高于其他模态,用于防止音乐生成中过度重复旋律或节奏,提高音乐的多样性。
3.4 数据集
多模态统一数据集
挑战:
跨模态对齐数据稀缺(例如"图像-语音"直接配对数据极少)。
解决方案:
以文本为中心(Text-Centric):将文本作为中介桥梁,通过"文本-图像""文本-语音"等双模态数据,间接实现多模态对齐。
标准化量化:统一按 token数量 统计数据量,便于跨模态比较
数据平衡:对数据量少的模态(如音乐)进行过采样(oversampling),确保每个训练batch中模态均衡。
图像-文本数据
LAION-2B: 来自网络的噪声图像-alt文本对(20亿规模)。
LAION-COCO: LAION-2B的子集(6亿),使用BLIP模型重新生成高质量caption。
LAION-Aesthetics: 高审美质量图像-文本对。
JourneyDB: Midjourney生成的合成数据。

后处理:通过文本质量、图像长宽比、CLIP分数过滤,最终保留 3亿高质量配对。
混合数据:加入 MMC4(多模态交错文档,730万条),使模型适应图文交错输入。
语音-文本数据
ASR数据集:总规模:5.7万小时语音-文本对,覆盖多样说话人、领域和录音环境。
Gigaspeech(在线平台)
Common Voice(众包)
Multilingual LibriSpeech(有声书)

音乐-文本数据
通过 Spotify API 匹配视频标题与歌曲元数据(标题、描述、歌词等)。
使用 GPT-4 清洗噪声元数据,生成高质量音乐描述文本(减少幻觉)。
关键创新:利用大模型(GPT-4)自动化生成对齐的"音乐-文本"配对,解决人工标注稀缺问题。
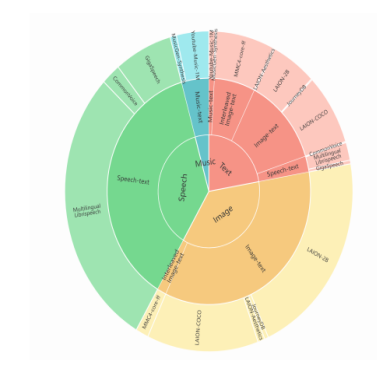
图示说明(Figure 2)
内环:模态类型(图像、文本、语音、音乐)。
中环:数据类型(配对数据、交错文档等)。
外环:具体数据集名称(如LAION-2B、Common Voice)
构建多模态统一数据集
目标
统一多模态训练:让语言模型(LM)处理文本、图像、语音、音乐等不同模态数据。
核心方法
多模态句子构造
非文本数据(如图片、语音)转换为 离散token(如IMG_123、AUDIO_456)。用模板拼接成混合序列,例如:
<文本> + <图像token> + <文本> + <语音token>
数据高效打包
同类型数据拼接:将短样本连成长序列(接近模型最大长度,如2048 token),避免显存浪费。示例:10条短语音 → 1条长序列。
训练细节
自回归学习:模型从左到右预测每个token(无论模态)。
全局损失计算:所有token(文本/图像/语音)的预测错误均参与梯度更新。
优势
高效训练:长序列填满GPU显存,提升计算利用率。
跨模态关联:强制模型学习不同模态的上下文关系(如图像token与描述文本)。
示例
输入序列:
"猫在沙发上IMG_111IMG_222它的叫声是AUDIO_789"
模型任务:
看到前半部分,预测后续token(包括图像、语音)
指令调优数据集
AnyInstruct-108k
AnyInstruct 是一个由 108k 多模态指令跟踪数据组成的数据集,以交错的方式集成了多种模态------文本、语音、图像和音乐。首先使用 GPT-4 合成文本多模态对话,然后分别使用 DALL-E 3、MusicGen 和 Azure 文本转语音 API 生成图像、音乐和语音。语音部分包含 39 种不同的音色,语速在一定范围内随机采样。
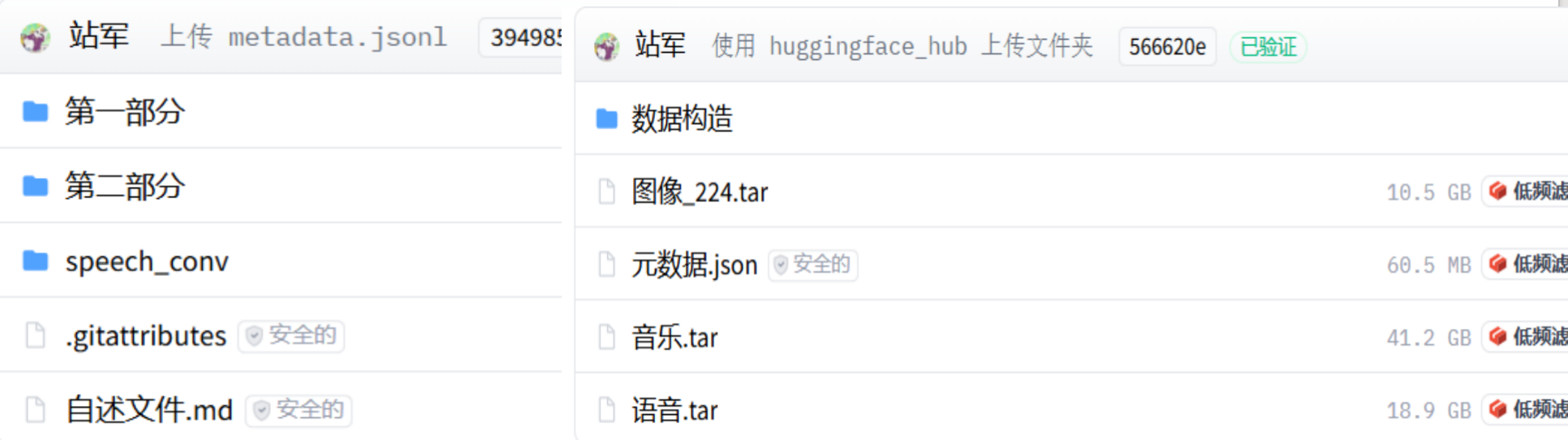
第一部分和第二部分的数据涵盖所有模态,总计 10.8 万条高质量多模态对话,包含多种多模态组合。该数据集包含约 20.5 万张图片、50.3 万条语音记录和 11.3 万首音乐曲目。而在data_construction文件夹中可以查看数据构建过程中的中间内容,例如主题、场景、图片和语音的字幕等。speech_conv目录包含语音对话。我们从现有的文本指令数据集中筛选出适合发声的对话,并进行语音合成,共计 108k 条。
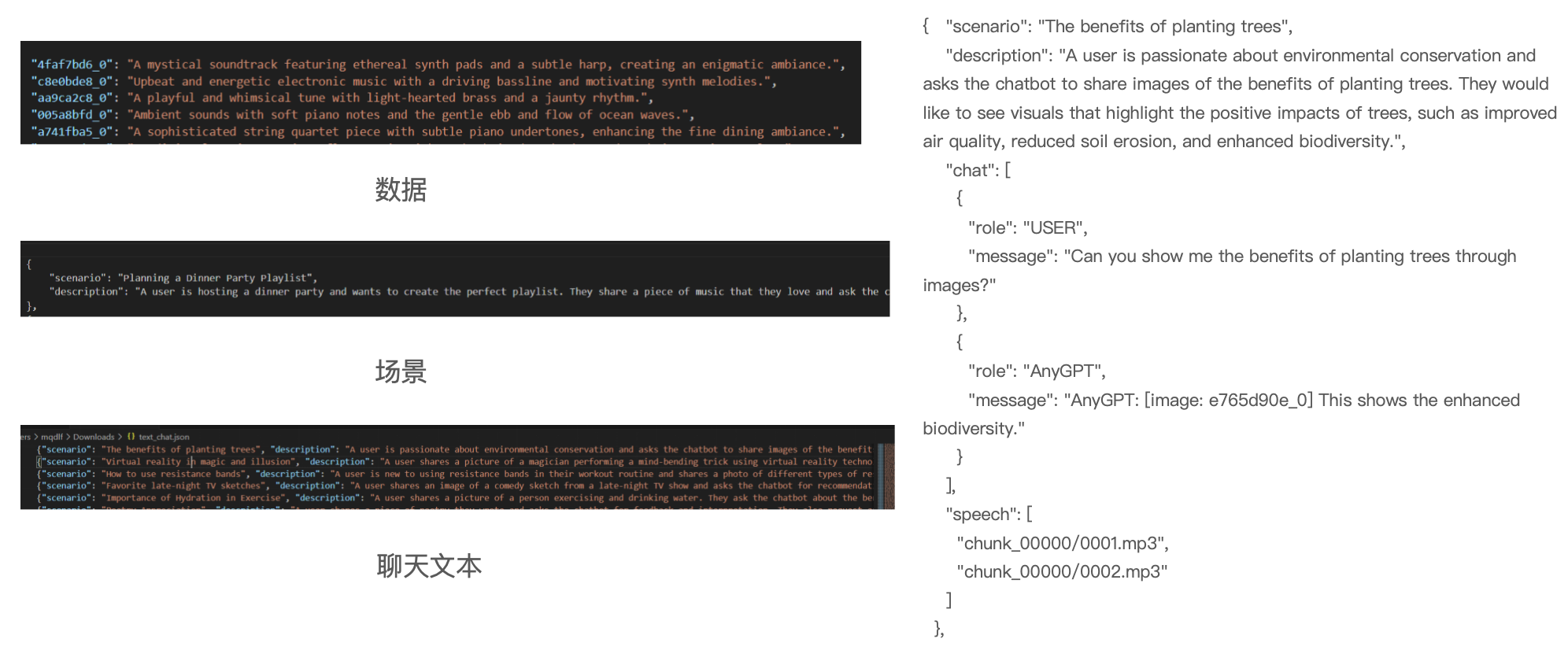
多模态交错指令数据构建
-
核心问题
现有数据缺陷:当前缺乏大规模、多模态(≥3种模态)的对话指令数据集,限制通用多模态模型的发展。人工收集多模态对话数据成本极高(需对齐文本、图像、语音、音乐等)。
-
解决方案
两阶段数据合成法:
文本阶段:用GPT-4生成含多模态文本描述的对话。
转换阶段:将文本描述转为真实多模态数据(图像、语音、音乐)
-
数据集规模:
10.8万条高质量多模态对话,覆盖任意模态组合(如"语音问答+图片生成+音乐推荐")。
-
方法创新:
文本中介化:先通过LLM生成文本描述,再转换为多模态数据,降低人工标注成本。
全自动流水线:从主题设计到最终多模态数据,无需人工干预。
阶段1:生成含多模态元素的文本对话
主题扩展:
人工设计100个元主题(如"电影配乐讨论")→ GPT-4扩展为2万具体话题。
场景生成:
提供多模态组合示例(如"用户发送图片+语音提问"),引导GPT-4生成多样化对话场景。
对话合成:
GPT-4基于场景生成多轮对话,用文本描述替代真实模态(如"<图片:一只猫在沙发上>")。
关键点:
通过示例提示(Few-shot)确保多样性。
纯文本中间格式便于规模化生成。
阶段2:文本到多模态转换
工具与输出:
| 模态 | 生成工具 | 数据量(108k对话中) |
|---|---|---|
| 图像 | DALL-E-3 | 20.5万张 |
| 语音 | Azure TTS API | 50.3万条 |
| 音乐 | MusicGen | 11.3万首 |
后处理:
过滤低质量数据(如图像模糊、语音不清晰)。
补充100k纯语音对话(从现有文本数据集+TTS合成)。
3.5 模型训练
第一阶段:多模态统一预训练
目标: 让LLaMA-2(base模型)学会跨模态自回归生成
输入: 混合多模态token序列(文本、图像、语音、音乐拼接成的长序列)。
任务: 纯自回归预测下一个token(无论模态),例如:
输入:"猫的图片是IMG_123IMG_456,它的叫声是"
模型应预测后续语音token AUDIO_789。
关键设计:
共享嵌入空间:所有模态token映射到同一向量空间。
无监督学习:不使用人工指令,仅学习模态间的统计关联
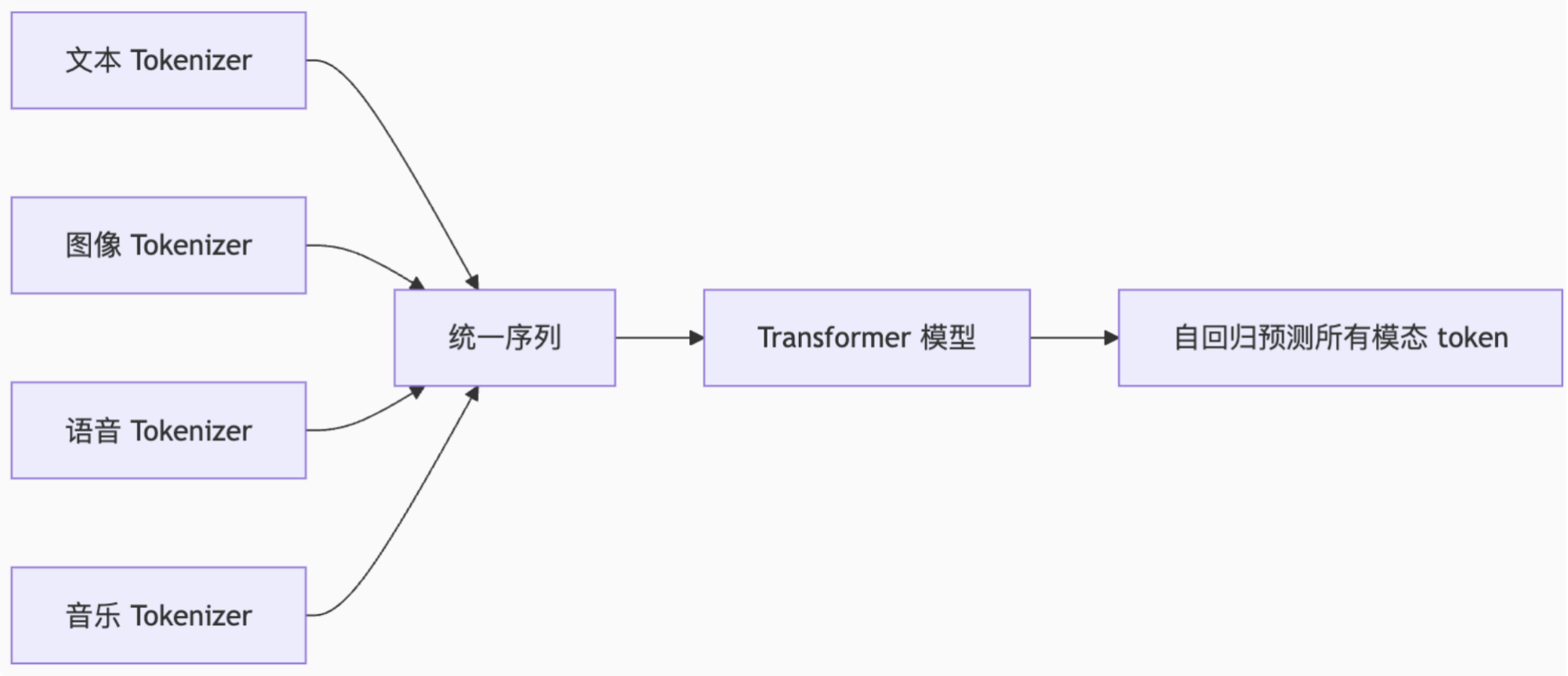
数据预处理与 Token 化
统一 Token 空间:
所有模态(文本、图像、语音、音乐)均被转换为 离散 token 序列,使用各自模态的专用 tokenizer:
文本:标准 BPE tokenizer(如 GPT-2)。
图像:VQ-VAE tokenizer(如 8192 词表,32 token/图)。
语音:SoundStream RVQ tokenizer(1024 词表,50 token/s)。
音乐:Encodec RVQ tokenizer(2048×4 词表,200 token/s)。
序列拼接:
多模态数据按对话顺序拼接为统一序列,例如:
java
[文本] + [图像token] + [语音token] + [音乐token] + [文本]模型架构设计
骨干网络:基于 LLaMA-2 架构的 Transformer 模型
多模态兼容性:
共享输入层:所有模态的 token 映射到同一嵌入空间。
位置编码:添加模态类型标识(如 IMG、AUDIO)以区分来源。
训练任务
自回归预测:
模型从左到右预测 所有模态的 token,无论下一个 token 是文本、图像还是音乐。
示例任务:
输入:"描述这张图:IMG_123IMG_456,它的背景音乐是"
目标:预测后续音乐 token MUSIC_789MUSIC_012。
多任务损失:
对所有 token 的预测损失求和,无论模态:(文本、图像、语音、音乐的 token 均参与梯度更新)
第二阶段:多模态指令微调
目标: 让模型学会遵循人类指令处理交错模态
输入: 合成的108k条多模态对话数据(含复杂指令如"根据语音生成图片+音乐")。
任务: 指令响应式生成,例如:
输入:用户语音AUDIO_111 + 文本"把这段话转成图片"
输出:IMG_222IMG_333。
关键设计:
保留自回归:延续第一阶段的token预测方式。
引入对话结构:学习"用户指令-模型响应"的交互逻辑。
第四章 实验结果
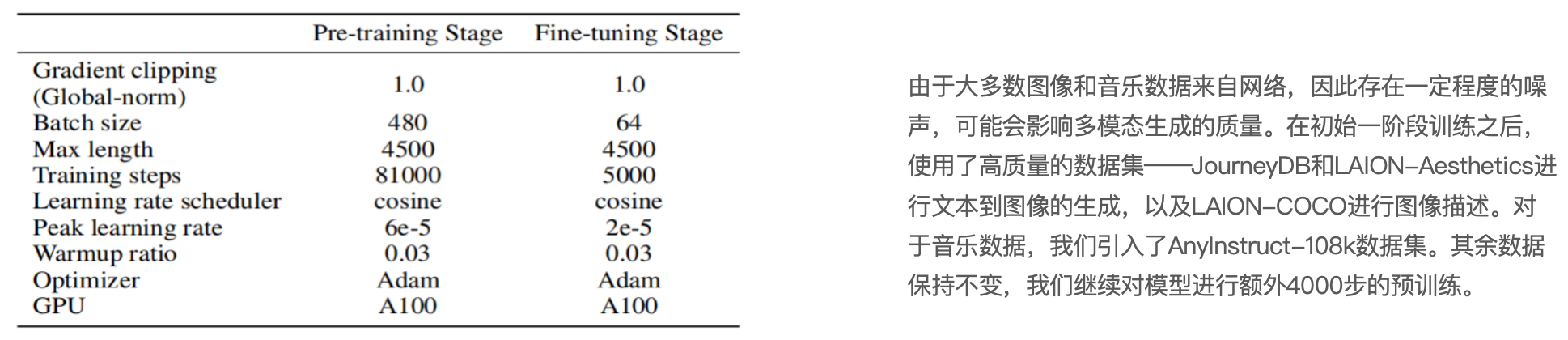
Image
图生文
文生图

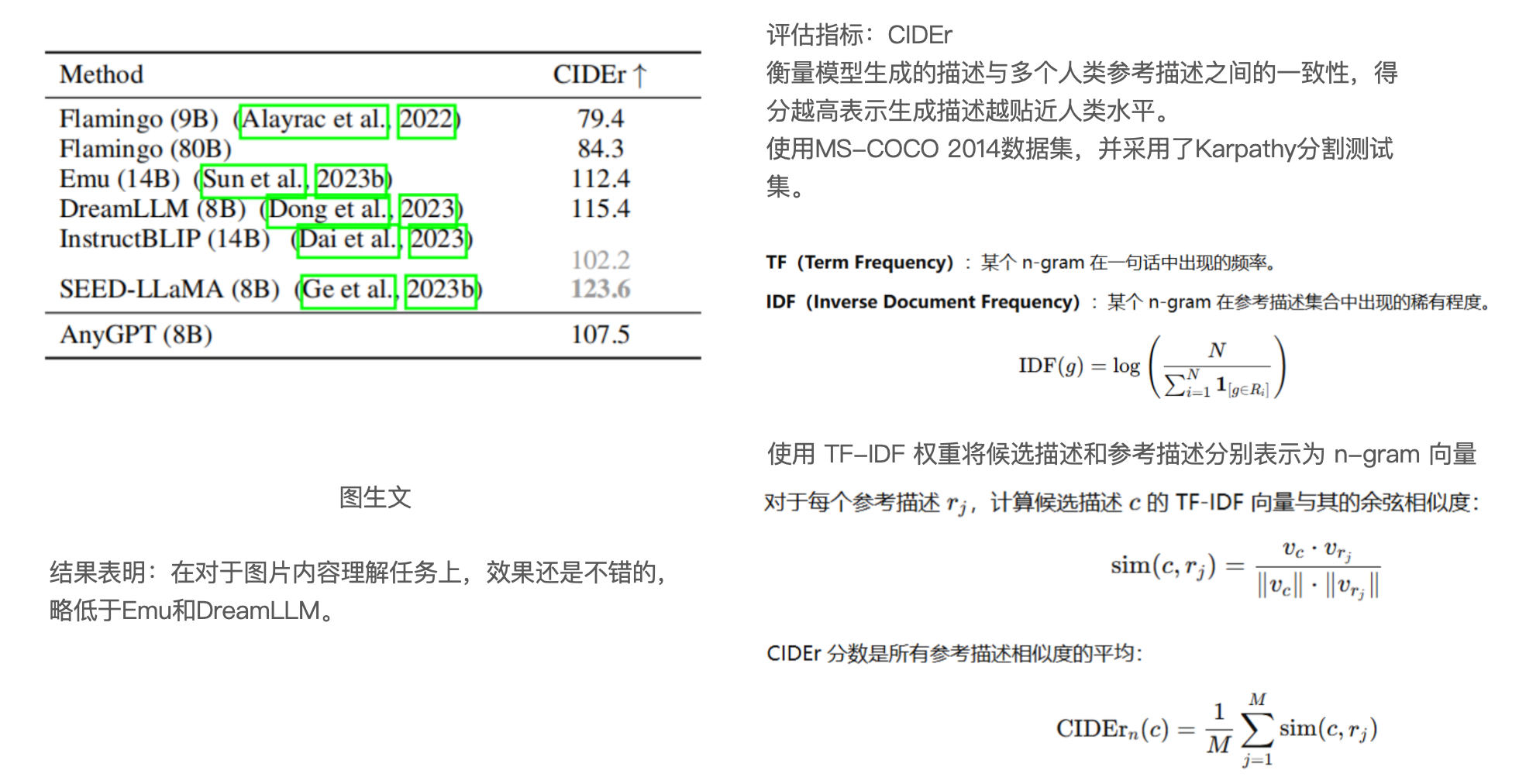
Speach
音频生文
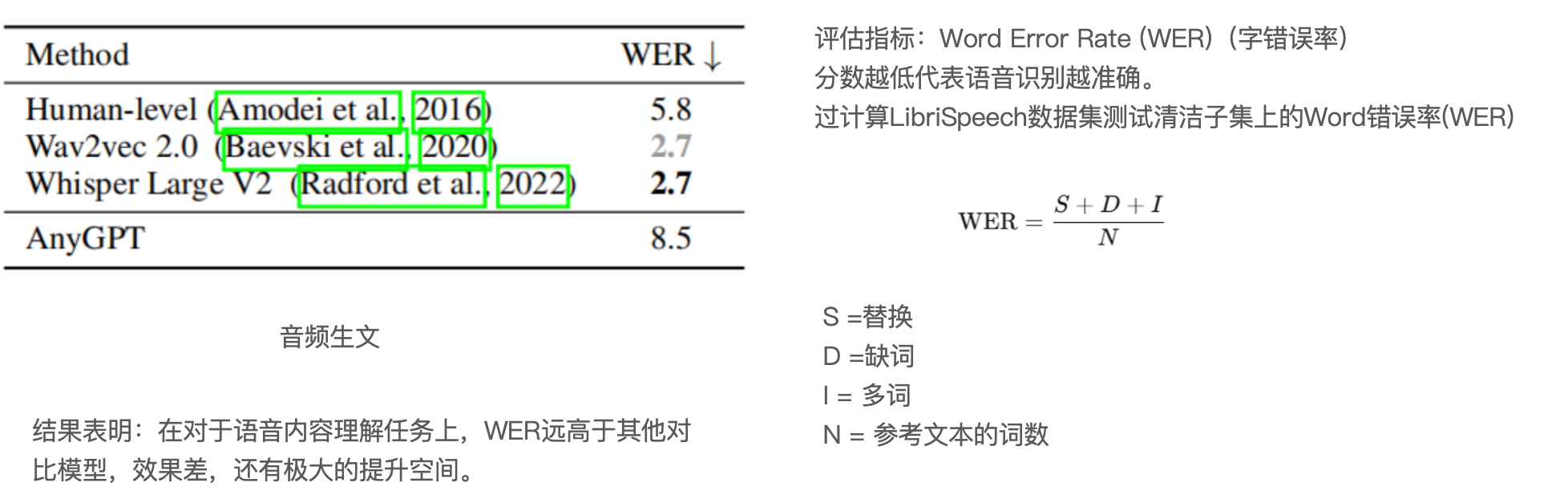
文生音频
Music
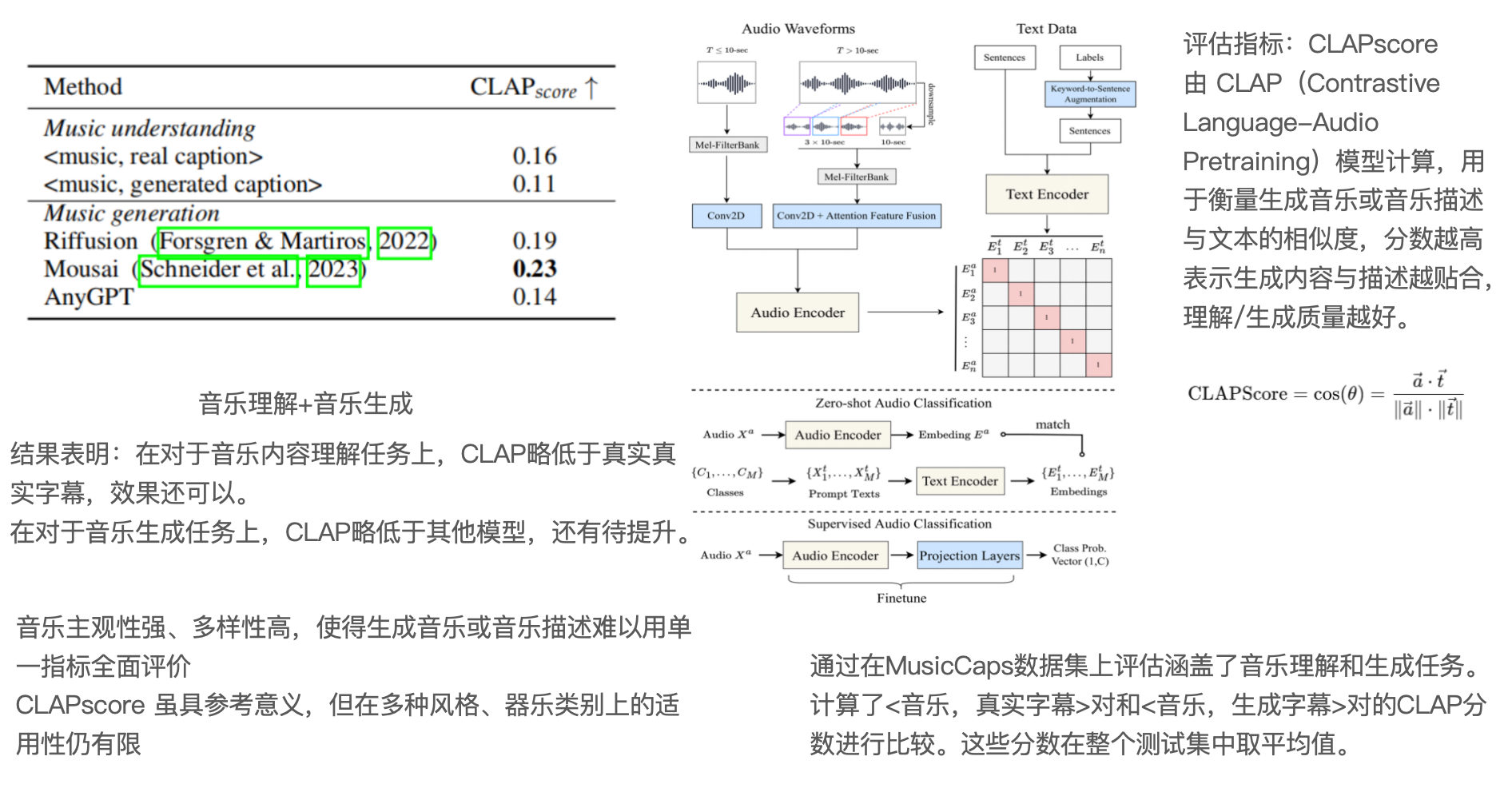
第五章 总结
贡献
AnyGPT 提出了一个统一的架构,允许使用同一个生成模型处理和生成文本、语音、图像等不同模态的内容。这种方式突破了传统多模态模型中各模态需要单独建模或解码器的局限。
AnyGPT 的关键组件之一是将所有模态(语音、图像、视频)转换为类似语言的离散 token,这些 token 可以被通用语言模型处理让所有模态都变成"可预测的 token 序列"。
由于模态间共享 token 表示,AnyGPT 很容易支持新的模态(如视频、动作等),只需提供相应的 tokenizer。框架具有高度模块化和扩展性,适合未来通用 AI 构建。
模型局限
LLMs领域是一个新兴的研究方向。然而,缺乏一个专门的基准来评估模型在多个维度上的能力,以及减少潜在风险,这构成了相当大的挑战。因此,构建一个全面的基准是势在必行的。
LLMs与单模态训练相比,观察到更高的损失,这阻碍了每个模态的最佳性能。提高多模态融合的潜在策略可能包括调整大语言模型和分词器,或采用专家混合(MOE)架构,以更好地管理多样化数据并优化性能。
在使用离散表示的多模态大语言模型中,分词器的质量决定了模型的理解能力和生成潜力的上限。提升分词器可以从多个角度入手,包括采用更优的代码本训练方法、开发更加连贯的多模态表示,以及在不同模态间应用信息解耦。
多模态内容,如图像和音频,通常跨越广泛的序列。例如,AnyGPT将音乐建模限制在5秒内,这大大限制了其音频输出的实际用途。此外,对于任意到任意的多模态对话,较长的上下文可以支持更多的对话交流,从而丰富互动的深度和复杂性。