慕然回首,发现这些年来涌现出了许多类型的数据库,今天抽空简单回顾一下,以便于后面用到时能快速选择。
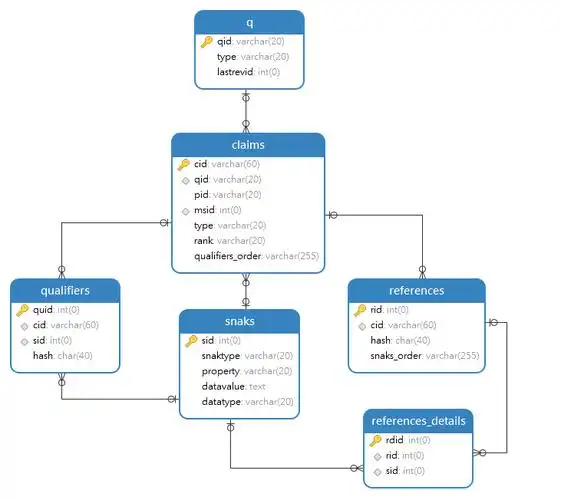
1. 关系型数据库(行式)
关系型数据库(RDBMS),我们常说的数据库就是指的关系型数据库。
它的全称是关系型数据库管理系统 (Relational Database Management System)。
在关系型数据库中,数据以类似二维表格 的方式以行式存储,表与表之间使用外键进行关联。
在大学的《数据库系统概论》中,里面提到的数据库范式 是关系型数据库中表关系的设计原则,但范式的约束往往仅存在于理论之中,是一种过于理想化的状态。在实际的应用中我们设计表时往往需要在性能和空间 之间做权衡,以反范式设计的数据表更是非常常见。
另外一点,在关系型数据库中还有一个很重要的特性:事务(transaction),这在与交易相关的应用场景中非常常用。
市面上常见的如Access、MySQL、PostgreSQL、MariaDB、Oracle、SQLite、H2、DB2、SQL Server、Sybase这些都是常见的支持关系型存储的数据库。
应用场景
RDBMS的应用场景最为经典 又广泛 ,如:电商平台的订单数据、金融交易平台的交易数据、医疗系统的病历、图书管理系统、成绩管理系统等各种强事务性的应用场景。
2. 列式存储数据库
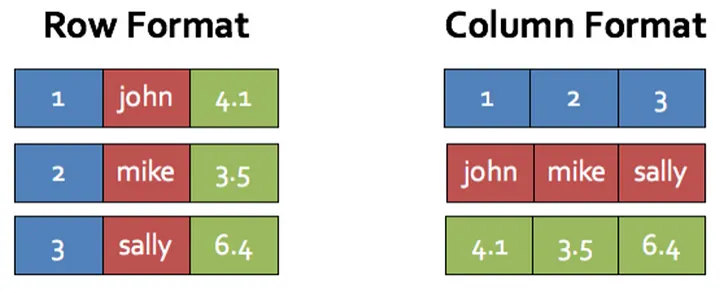
与前面介绍的RDBMS采用行式存储 对应的,还有一种采用列式存储的数据库。
如ClickHouse、Druid、HBase这些都是采用列式存储的经典代表。
列式存储 的数据库在大数据场景 中应用较多,非常适合OLAP (Online Analytical Processing,在线分析处理),因其在数据压缩 、字段查询 、高效查询方面都具有显著的优势。
常见的应用场景有:广告系统、分析系统、风控系统等。
在联想官网的《In-memory Computing with SAP HANA on Lenovo ThinkSystem Servers》一文中有对行式存储 和列式存储的详细介绍与对比,写得很好值得一读。
2.1 数据压缩优势
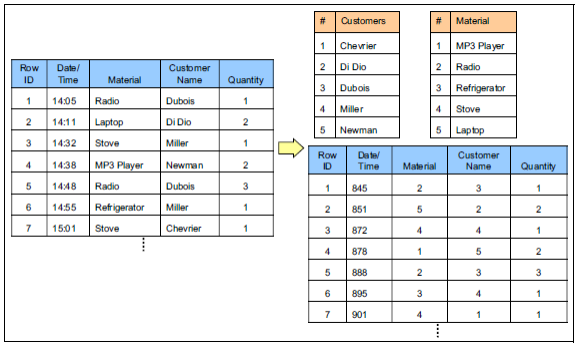
上图为列式存储 使用字典序号 进行数据压缩 的示例图:
左边的表格为原始数据,右下的表格为列式存储的最终数据。
从示意图中我们可知:在通过列式存储 的映射 后,最终存储的数据大小 要远小于原始数据。
且随着每列的重复数据值越多,它的压缩效果也更好。
2.2 字段查询优势
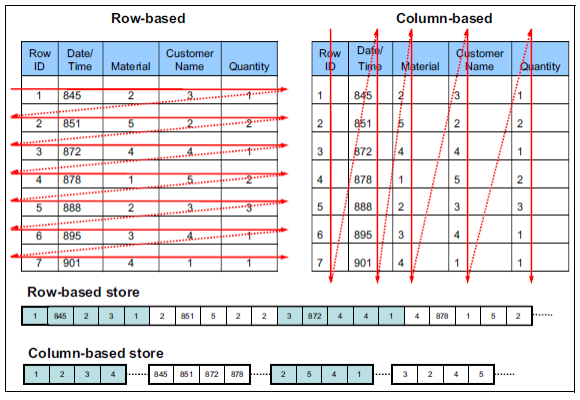
上图展示了行式存储 和列式存储 在数据落地时各自的存储模型。
在行式存储中,数据按照记录整块存储,在新增和更新的场景下有优势。
但在统计分析 场景中,往往是对整表的某一列 进行分析,在行式存储中如果被统计的列没有索引时,即便读取的只是一个字段,数据库的底层也要加载整行的数据到内存,在字段较多数据量较大的情况下,仅对某列的数据进行统计分析所消耗的时间也会随之增加。
而在采用列式存储时,因为底层存储的数据是按列连续存储 ,这也很符合计算机磁盘的顺序读取的机制。
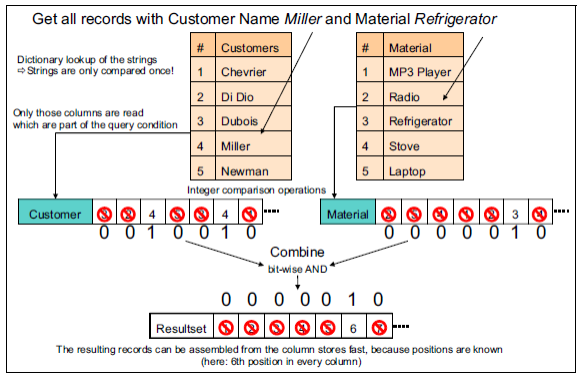
上图展示了:查询Customers列 ='Miller'且Material列 ='Refrigerator'的所有数据,在列式存储 中的数据库中进行检索的过程。
主要分为以下三步:
- 使用字典匹配,用index找到符合条件的序列。即:字符串匹配替换为数值匹配。这与字符串匹配相比,数值匹配能加快匹配时间
- 将匹配成功的所在列的索引标注为1,未匹配的标注为0,以此建立bitmap
- 将两个bitmap进行与运算
0010010
0000010
得到:
0000010
1234567
则第6个数据为满足查询条件的数据。
整个过程运算简单高效,即便数据量很大由于使用bitmap也很能在很小的空间下快速得出结果。
3. 分布式数据库
在大规模数据量 的场景中,随着数据量的增多,数据库的水平扩容能力也显得尤为重要。
以mysql为例,尽管它也有mysql cluster 这样的集群解决方案,但在实际应用中使用它的还不多。在最近几年中,取而代之的是直接使用成熟的分布式数据库 ,如tidb、oceanbase这些分布式数据库。
以TIDB为例,其具有数据可自动切分(Sharding / Region)、多节点协作提供读写、事务和高可用、支持容灾、跨机房部署等特性,且兼容通用SQL语法,且具有更好的性能。
尽管tidb具有很好的可扩展性,但对它的维护还得需要有专业的人员,如果数据规模不大且人员不多场景,继续使用mysql仍然是很好的选择。
毕竟稳定且几乎不需要后期的维护,真的很省心。
4. KV数据库
KV数据库即:使用key、value形式的键值对 存储数据的数据库。
一般为内存数据库,好常用的Redis、Etcd、LevelDB、Memcached这些。
因为是内存存储,具有读写性能高的特点,在所存储的数据结构简单的场景中非常适用。如:缓存、秒杀、配置中心、用户会话管理、分布式锁、资源协调器这些场景。
KV数据库的另一大特点是:在分布式场景中能发挥出较高的价值,所以如果项目的数据量不大且为单体项目 时,不要盲目使用它,毕竟网络IO 也有一定的开销。

单体项目中可以使用Caffeine(无持久化)或mapdb(有持久化)这类的组件代替。
5. 时序数据库
时序数据库(Time Series Database, TSDB)用于处理带有时间戳的时序数据(如传感器数据、监控指标、日志等),其设计目标是高效存储、查询和分析时间序列数据。
其中我们熟知的有:Prometheus和InfluxDB,在物联网、运维监控、工业数据等场景中应用广泛。
时序数据库的主要特点有:每条数据记录包含时间戳、支持数据保留策略(如 "保留最近 3 个月的数据")、高效的范围查询。
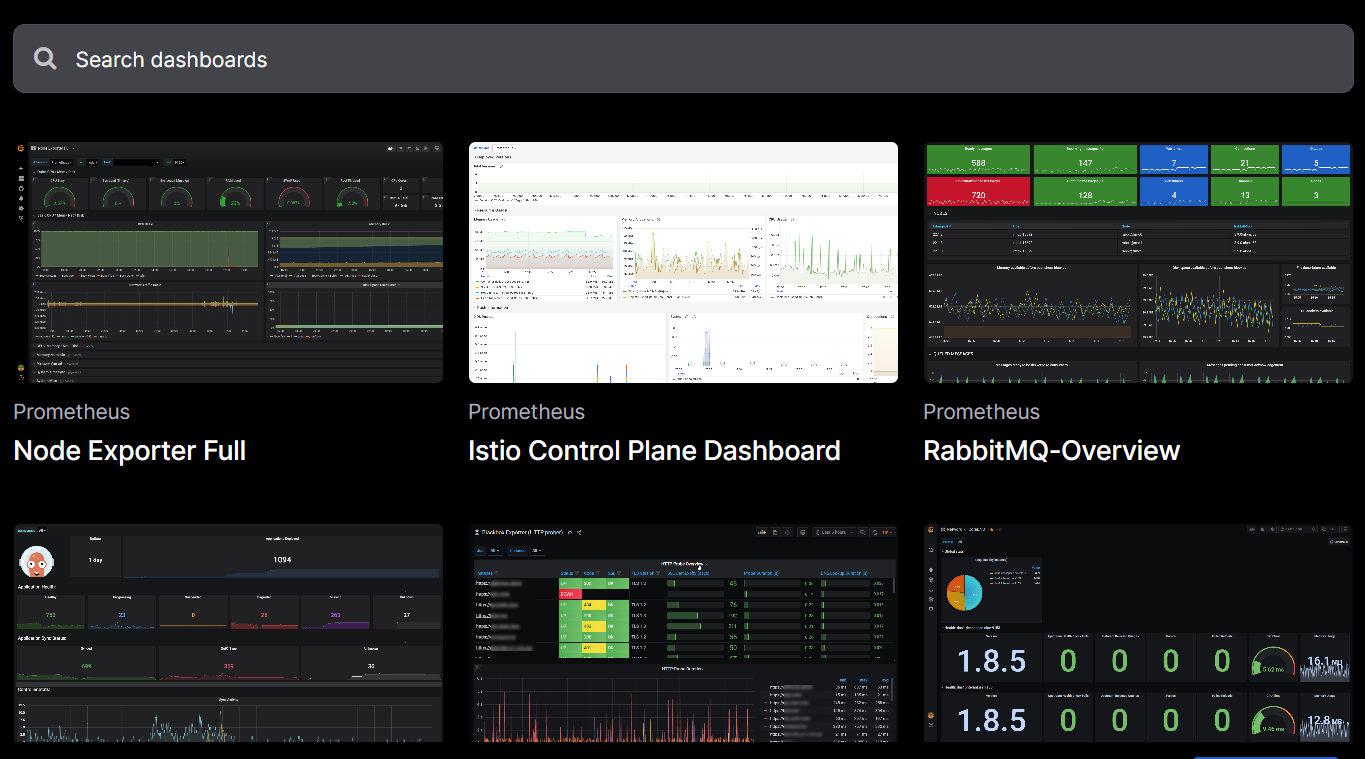
特别是最近几年在k8s的时代背景下,使用Prometheus+Grafana,再配合Grafana dashboards中的各种炫酷图形,Prometheus+Exporter+Grafana让一切都那么简单
6. 文档型数据库
在那个NOSQL(Not Only SQL)数据库逐渐流行起来的年代,MongoDB 作为文档型数据库中的代表,几乎已经成为了文档型数据库的代名词。
文档型数据库由于存储的数据格式类似json,具有非常大的灵活性,对于所存储的对象字段不一致的场景非常适用。
举一个存储公共考试成绩的场景:
英语CET考试详细成绩字段有:准考证号、姓名、证件号码、总分、听力、阅读、写作和翻译
计算机等级考试成绩字段有:准考证号、报名号、姓名、证件号、等级、成绩
如果每个类型的考试都要建立一张表来维护,过程繁琐又复杂。
而如果用mongodb这种文档型则方便很多,无论字段如何变化,都只需要一张表即可,省时省力。
MongoDB中没有table和row的概念,取而代之的是Collection和Document。(Collection类似于关系型数据库中的Table,Document类似于关系型数据库中的一条记录Row)
除了对非结构化的场景有优势外,MongoDB还支持watch功能,具有event的事件监听机制,对于内容审计场景很实用。
但它相比传统关系型数据库,MongoDB 的事务性能开销较高,不建议用于高频事务场景中。
而在如:存储文章、评论等半结构化数据,无需固定表结构这些场景比较推荐,很方便扩展字段。
7. 向量数据库
在最近几年大模型和智能体应用的迅猛发展下,越来越多的系统也开始开发自己的AI应用,特别是在RAG技术的带动下,向量数据库的应用数暴增了许多。
这也迫使得各种数据库的厂商开始支持了向量数据库,比如:Apache Cassandra, Azure Vector Search, Chroma, Milvus, MongoDB Atlas, Neo4j, Oracle, PostgreSQL/PGVector, PineCone, Qdrant, Redis, Weaviate等。
7.1 向量
向量(vector),也称为欧几里得向量 、几何向量,指具有大小 (magnitude)和方向 的量。
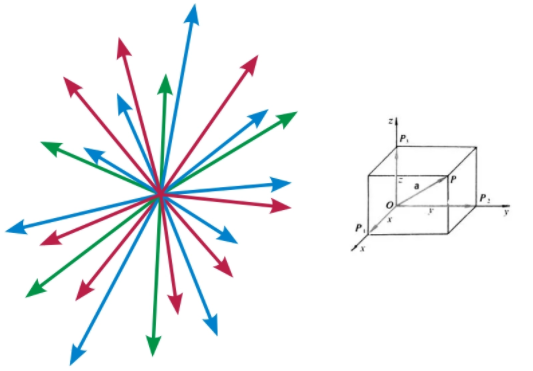
与向量对应的量叫做数量(物理学中称标量),数量(或标量)只有大小,没有方向,例如:成绩、人数、身高。
生活中我们接触到的很多东西都可以用向量表示,如用RGB法来表示颜色:黑色为RGB(0,0,0) 、红色为RGB(255,0,0);
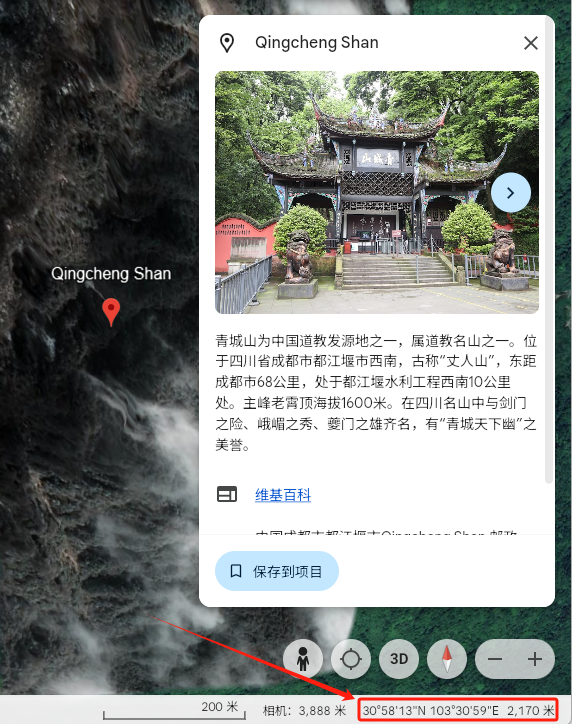
又或者我们爬山时用来表示坐标,在地图软件的右下角可以看到:30°58'13"N 103°30'59"E 2,170 米这样的文字,它是GPS的坐标,由经度、维度、海拔高度组成。
在近几年很火热的大模型中的embedding模型也是向量的典型应用。
在RAG中,它会将文本和图像通过Embedding Model 做完向量编码后保存到向量数据库 ,查询的时候先从向量数据库 检索到用户语义相关联的文本,再以Context的方式或者Prompt和用户的问题一起发送给大语言模型(LLM),再把问题结果返回给应用。通过这种方式解决了用户使用大语言模型遇到的数据私有化问题以及大语言模型的"幻觉"问题。
RAG的详细使用案例可参考我之前的文章:《使用Spring AI中的RAG技术,实现私有业务领域的大模型系统》
7.2 向量数据库常见的3种检索方式
将数据向量化入库 后的目的是为了后期的检索 ,与传统数据库的精确检索 不同的是,向量数据库中用的是近似匹配 ,所以返回的结果往往也是TOP-K(最相似的K条数据)。
向量数据库中向量与向量 之间的距离由距离函数决定,常见的距离函数有:
- Squared L2,欧几里得距离
- Inner product,点积相似度
- Cosine similarity,余弦相似度
详细公式如下图(摘自chroma-configure):

关于上面这几种距离函数的选择,这里简单总结一下。
7.2.1 欧几里得距离(Squared L2)
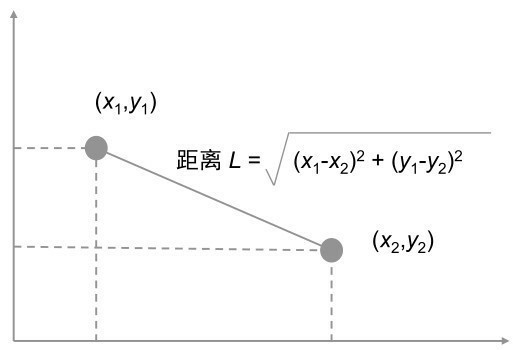
欧几里得距离(Squared L2),也就是中学时我们所学的两点间距离公式
多维空间时,坐标点的计算也随之增加,如三维时AB两点的距离为:
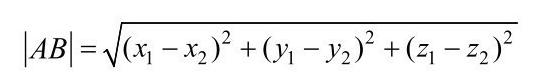
Squared L2距离函数适用于空间距离检索的场景,如搜索最近的地点。
当然,如仅为来做附近地点搜索使用elasticsearch这类的产品会更靠谱成熟一些。
7.2.2 点积相似度(Inner product)
点积相似度( Inner product,内积),把两个向量的元素对应相乘,然后把结果相加。
计算结果越大,表示两个向量越相似;结果越小,表示两个向量越不相似。
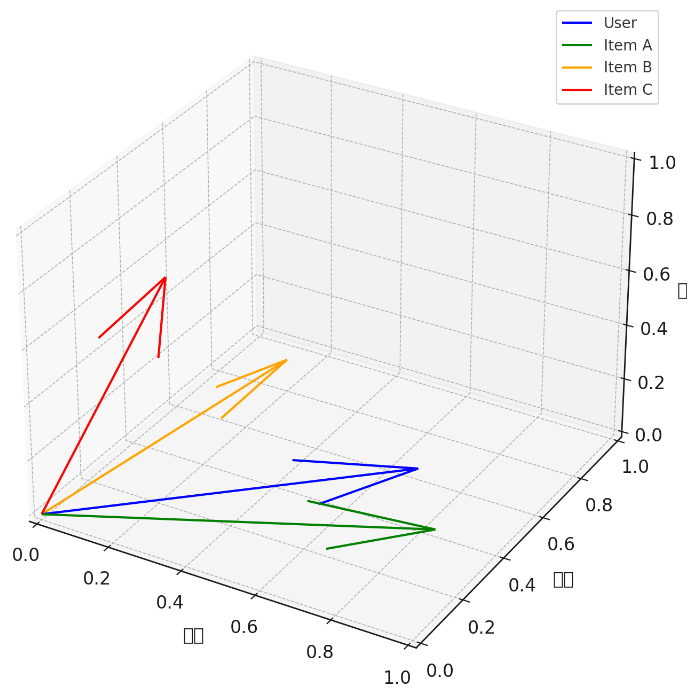
以下为在用户兴趣产品推荐场景中,使用点积相似度的python代码小例子:
python
import numpy as np
# 用户兴趣向量(表示对不同主题的兴趣程度)
# 维度依次代表:科技,时尚,体育
user_profile = np.array([0.9, 0.2, 0.4])
# 商品A的特征向量
item_A = np.array([1.0, 0.1, 0.3]) # 偏科技类
# 商品B的特征向量
item_B = np.array([0.2, 0.8, 0.1]) # 偏时尚类
# 商品C的特征向量
item_C = np.array([0.3, 0.1, 0.9]) # 偏体育类
# 定义函数:计算点积相似度
def dot_similarity(user, item):
return np.dot(user, item)
# 计算相似度
score_A = dot_similarity(user_profile, item_A)
score_B = dot_similarity(user_profile, item_B)
score_C = dot_similarity(user_profile, item_C)
# 打印结果
print(f"用户兴趣向量: {user_profile}")
print(f"商品A 相似度: {score_A:.2f}")
print(f"商品B 相似度: {score_B:.2f}")
print(f"商品C 相似度: {score_C:.2f}")
# 推荐结果
recommended = max([(score_A, '商品A'), (score_B, '商品B'), (score_C, '商品C')])
print(f"\n✅ 推荐商品: {recommended[1]}(相似度: {recommended[0]:.2f})")输出信息为:
用户兴趣向量: [0.9 0.2 0.4]
商品A 相似度: 1.04
商品B 相似度: 0.38
商品C 相似度: 0.65
✅ 推荐商品: 商品A(相似度: 1.04)在Word2Vec、BERT 等模型生成的词向量 / 句向量时,可直接使用点积计算相似度。
7.2.2 余弦相似度(Cosine similarity)
余弦相似度(Cosine similarity),通过计算两个向量的夹角余弦值 来评估他们的相似度
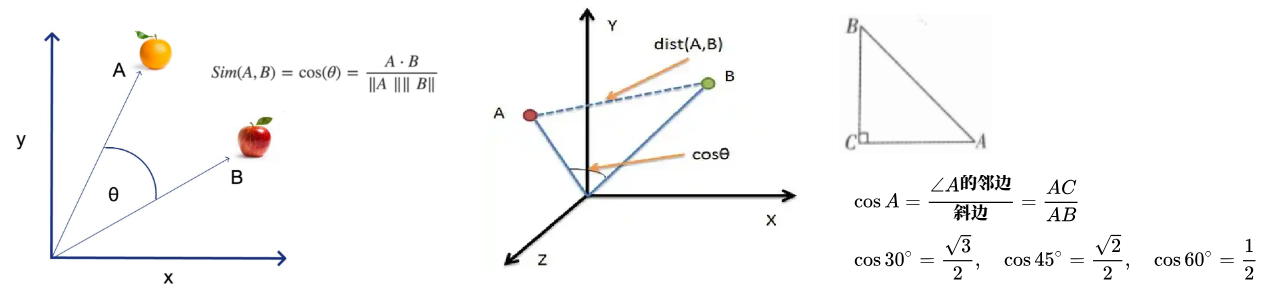
余弦 (yu xian):锐角的余弦被定义为其在直角三角形中的邻边与斜边 的比值,如上图中角A 的余弦为AC/AB 。
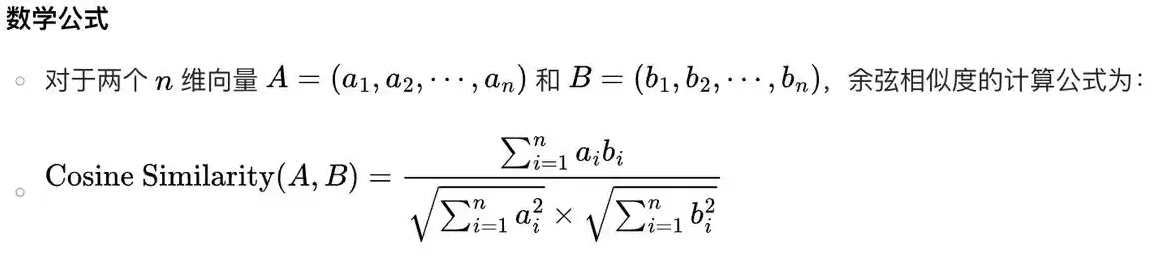
余弦相似度函数 常用于文本检索的场景中,计算结果的值越大代表越相似,取值范围为-1,1,为1时代表完全相似。
余弦相似度函数在文本/文档检索场景中较为常用,如一篇文章在进行TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率)向量化处理入库后,通过关键词检索相关文章时检索出相关度最高的文章。
示例代码:
python
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 示例问答库(常见问题)
documents = [
"去北京旅游需要几天比较合适?",
"有哪些适合家庭亲子游的国内旅游地点?",
"什么时候去西藏最合适?",
"从广州出发去张家界怎么安排路线?",
"三亚有哪些值得推荐的海滩?"
]
# 用户问题
query = "打算春节和家人一起旅游,适合去哪儿?"
# 中文分词函数
def tokenize(text):
return " ".join(jieba.cut(text))
# 分词处理
documents_tokenized = [tokenize(doc) for doc in documents]
query_tokenized = tokenize(query)
# TF-IDF 向量化
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(documents_tokenized + [query_tokenized])
# 计算余弦相似度
cos_similarities = cosine_similarity(tfidf_matrix[-1], tfidf_matrix[:-1]).flatten()
most_similar_idx = np.argmax(cos_similarities)
# 输出结果
print(f"查询句子: {query}\n")
print("与查询最相似的文档:")
print(f"- 文档内容: {documents[most_similar_idx]}")
print(f"- 相似度: {cos_similarities[most_similar_idx]:.4f}")运行结果:
查询句子: 打算春节和家人一起旅游,适合去哪儿?
与查询最相似的文档:
- 文档内容: 有哪些适合家庭亲子游的国内旅游地点?
- 相似度: 0.19247.3 向量数据库chroma简单使用
目前支持向量存储的数据库很多,这里以轻量级的chroma向量数据库演示下它的安装与使用。
这里以docker方式运行chroma为例,命令如下:
docker run -d --name chroma -p 8000:8000 chromadb/chroma:latest
chroma支持多种客户端,python、java、C++等都支持。同时chroma也支持内存、持久化、client-server多种方式运行,像传统数据库那种c/s架构方式运行的client端代码如下:
python
import chromadb
client = chromadb.HttpClient(host='192.168.6.66', port=8000)
client.delete_collection("all-my-documents")
# Create collection. get_collection, get_or_create_collection, delete_collection also available!
collection = client.create_collection("all-my-documents")
# Add docs to the collection. Can also update and delete. Row-based API coming soon!
collection.add(
documents=["This is document1", "This is document2"], # we handle tokenization, embedding, and indexing automatically. You can skip that and add your own embeddings as well
metadatas=[{"source": "notion"}, {"source": "google-docs"}], # filter on these!
ids=["doc1", "doc2"], # unique for each doc
)
# Query/search 2 most similar results. You can also .get by id
results = collection.query(
query_texts=["This is a query document"],
n_results=2,
# where={"metadata_field": "is_equal_to_this"}, # optional filter
# where_document={"$contains":"search_string"} # optional filter
)
# 输出查询结果
print("===== 查询结果 =====")
if results['ids'] and results['ids'][0]:
for i, (doc_id, doc, dist, meta) in enumerate(zip(
results['ids'][0],
results['documents'][0],
results['distances'][0],
results['metadatas'][0]
)):
print(f"匹配结果 {i+1}:")
print(f" - ID: {doc_id}")
print(f" - 文档内容: {doc}")
print(f" - 相似度距离: {dist:.4f}")
print(f" - 元数据: {meta}")
print("-" * 40)
else:
print("未找到匹配的文档")运行结果为:
===== 查询结果 =====
匹配结果 1:
- ID: doc1
- 文档内容: This is document1
- 相似度距离: 0.9026
- 元数据: {'source': 'notion'}
----------------------------------------
匹配结果 2:
- ID: doc2
- 文档内容: This is document2
- 相似度距离: 1.0358
- 元数据: {'source': 'google-docs'}
----------------------------------------8. 图数据库
这几年,社交网络、推荐系统、知识图谱(Knowledge Graph)等这些产品和技术的加持下,我们似乎对数据和数据之间关联关系的搜索的需求也越来越浓烈。
8.1 图(Graph)
先回顾一下在数据结构中,图的概念:
图 (graph)由顶点集 V(vertice)和边 E(edge)组成。
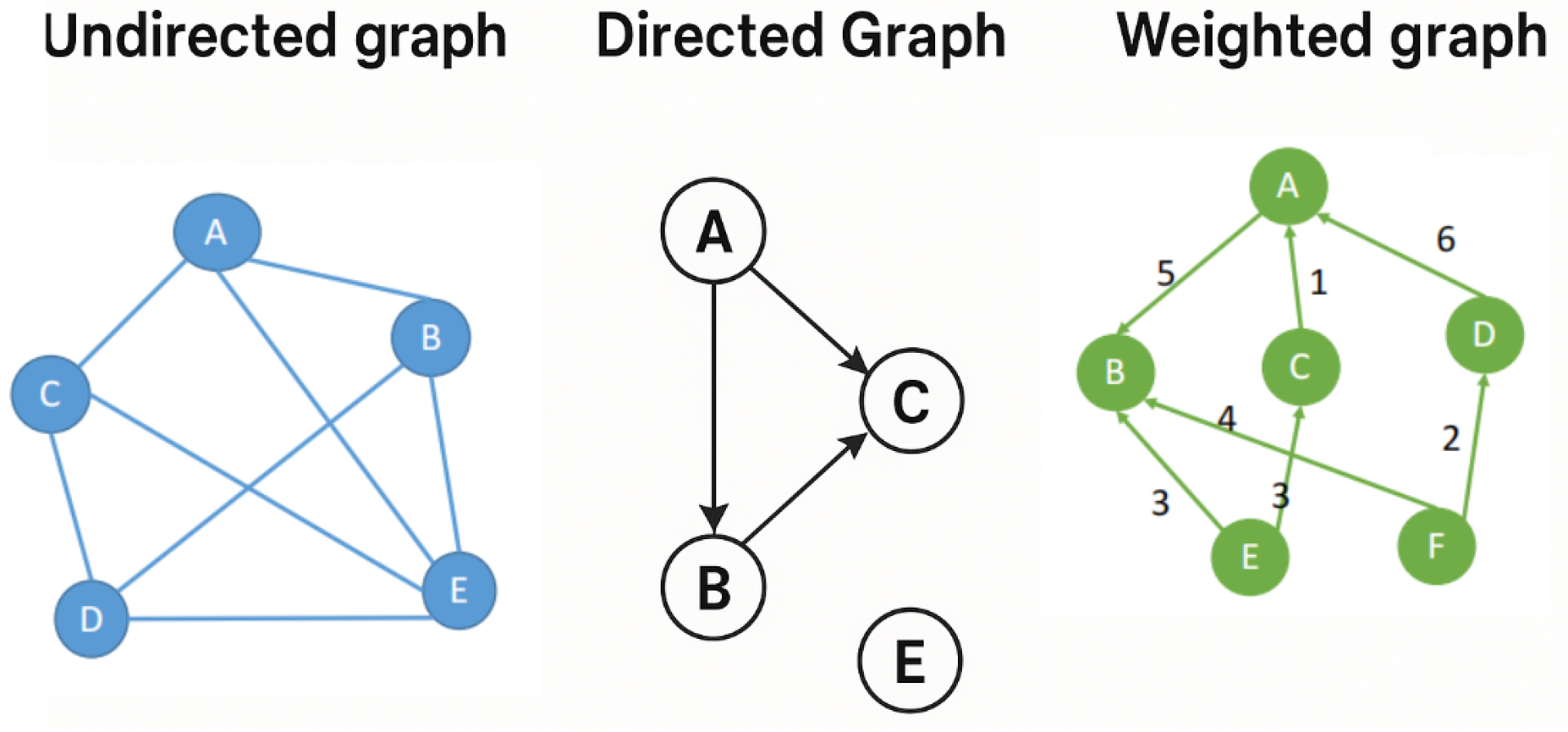
根据有无方向和权重,又可将图分为:
-
无向图(Undirected Graph),如地铁线路图

-
有向图(Directed Graph),如人物关系网络图

-
权重图(Weighted Graph),如带有时长的线路图

图可以使用矩阵(Matrix)、链表(List)、数组(Array)这些数据结构来实现。
同时,图也具有新增、删除、更新操作;
查找遍历方面,可以使用DFS (Depth-First Search,深度优先搜索)、BFS (Breadth-First Search,广度优先搜索)算法进行节点遍历;以及使用一些最短路径算法找到最短路径,如最小生成树、BFS最短路径、Dijkstra、Floyd这些算法。(它们的具体区域后期再写单独文章记录总结)
8.2 图数据库的应用场景与简单使用
与传统的关系型数据库 相比,图数据库在处理多层关联查询 之类的场景中具有更显著的优势。如:用户关系建模、识别异常交易、物流路线规划等场景。
下面再列举一个具体的例子,对比一下存储相同数据的情况下,在传统关系型数据库mysql ,以及在图数据库neo4j 中对于用户多层关系查询的性能对比。
8.2.1 neo4j安装
现在的图数据库也非常多,这里使用以java开发的开源图数据库neo4j。
在neo4j官方文档中的 installation部分可以找到具体的安装方式,这里为了方便使用docker方式运行:
docker run \
--restart always \
--publish=7474:7474 --publish=7687:7687 \
neo4j:2025.04.0运行截图为:
之后再根据服务的ip和端口 用浏览器访问下neo4j的管理控制台,如:http://192.168.6.66:7474/
输入默认的用户名和密码:neo4j/neo4j
8.2.2 neo4j简单使用
插入几条模拟数据,创建人物节点:
cypher
CREATE
(wukong:Character {
name: '孙悟空',
title: '齐天大圣',
weapon: '金箍棒',
species: '猴子',
origin: '花果山'
}),
(bajie:Character {
name: '猪八戒',
title: '天蓬元帅',
weapon: '九齿钉耙',
species: '猪',
origin: '高老庄'
}),
(shaseng:Character {
name: '沙僧',
title: '卷帘大将',
weapon: '降妖杖',
species: '沙妖',
origin: '流沙河'
}),
(tang:Character {
name: '唐僧',
title: '御弟唐僧',
weapon: '无',
species: '人类',
origin: '大唐长安'
}),
(guanyin:Character {
name: '观音菩萨',
title: '南海观世音',
weapon: '净瓶柳枝',
species: '神仙',
origin: '南海普陀'
})再添加人物关系:
cypher
MATCH
(wukong:Character {name: '孙悟空'}),
(bajie:Character {name: '猪八戒'}),
(shaseng:Character {name: '沙僧'}),
(tang:Character {name: '唐僧'}),
(guanyin:Character {name: '观音菩萨'})
CREATE
(wukong)-[:师傅]->(tang),
(bajie)-[:师傅]->(tang),
(shaseng)-[:师傅]->(tang),
(tang)-[:徒弟]->(wukong),
(tang)-[:徒弟]->(bajie),
(tang)-[:徒弟]->(shaseng),
(guanyin)-[:安排取经任务]->(tang),
(guanyin)-[:收服]->(wukong),
(guanyin)-[:收服]->(bajie),
(guanyin)-[:收服]->(shaseng)上面的语法为cypher。
之后再查看neo4j的控制台,可以看到如下关系:
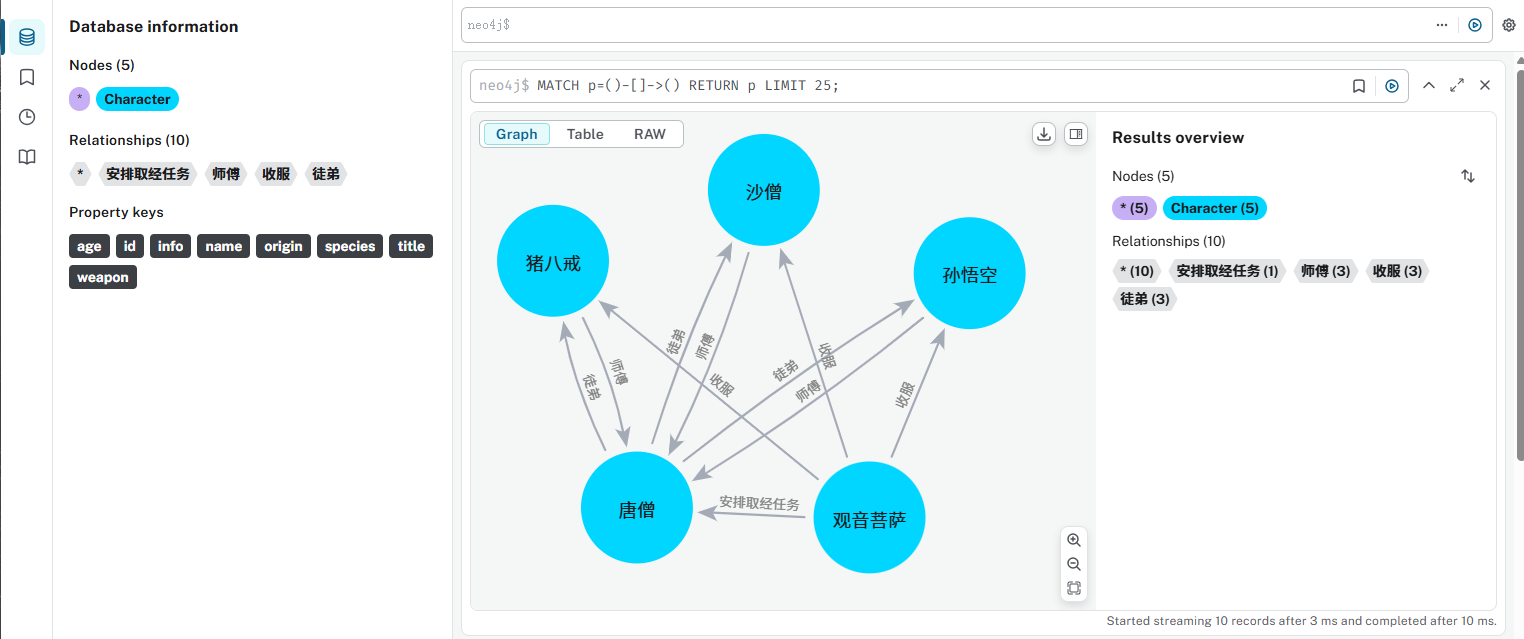
非常直观~
8.2.3 neo4j和mysql多层关系查询对比示例
下面模拟2000个用户,每人有20个好友,查询朋友的朋友的朋友的朋友的朋友列表(5度人脉)。
对比的关系型数据库为mysql,mysql也使用容器安装,使用 mysql 8.4.5:
docker run --name mysql -e MYSQL_ROOT_PASSWORD=123456 -p 3306:3306 -d mysql:8.4.5
使用如下代码进行验证:
python
import time
import random
import mysql.connector
from neo4j import GraphDatabase
# === 配置参数 ===
NUM_USERS = 2000
FRIENDS_PER_USER = 20
# === MySQL 部分 ===
def mysql_setup():
# CREATE DATABASE testdb;
conn = mysql.connector.connect(
host="192.168.6.66", user="root", password="123456", database="testdb"
)
cursor = conn.cursor()
cursor.execute("DROP TABLE IF EXISTS Friendships")
cursor.execute("DROP TABLE IF EXISTS Users")
cursor.execute("""
CREATE TABLE Users (
user_id INT PRIMARY KEY,
name VARCHAR(100)
)
""")
cursor.execute("""
CREATE TABLE Friendships (
user_id INT,
friend_id INT,
PRIMARY KEY (user_id, friend_id)
)
""")
# 插入用户
for i in range(1, NUM_USERS + 1):
cursor.execute("INSERT INTO Users (user_id, name) VALUES (%s, %s)", (i, f'User{i}'))
# 插入好友关系
for i in range(1, NUM_USERS + 1):
friends = random.sample(range(1, NUM_USERS + 1), FRIENDS_PER_USER)
for f in friends:
if f != i:
cursor.execute("INSERT IGNORE INTO Friendships (user_id, friend_id) VALUES (%s, %s)", (i, f))
conn.commit()
return conn
def mysql_query(conn):
cursor = conn.cursor()
start = time.time()
cursor.execute("""
SELECT DISTINCT u6.user_id
FROM Friendships f1
JOIN Friendships f2 ON f1.friend_id = f2.user_id
JOIN Friendships f3 ON f2.friend_id = f3.user_id
JOIN Friendships f4 ON f3.friend_id = f4.user_id
JOIN Friendships f5 ON f4.friend_id = f5.user_id
JOIN Users u6 ON f5.friend_id = u6.user_id
WHERE f1.user_id = 1 AND u6.user_id != 1
""")
results = cursor.fetchall()
duration = time.time() - start
print(f"MySQL 查询返回 {len(results)} 条记录,用时 {duration:.4f} 秒")
return duration
# === Neo4j 部分 ===
def neo4j_setup():
driver = GraphDatabase.driver("bolt://192.168.6.66:7687", auth=("neo4j", "neo4j"))
with driver.session() as session:
session.run("MATCH (n) DETACH DELETE n")
# 插入用户节点
for i in range(1, NUM_USERS + 1):
session.run("CREATE (:User {id: $id, name: $name})", id=i, name=f'User{i}')
# 插入好友关系
for i in range(1, NUM_USERS + 1):
friends = random.sample(range(1, NUM_USERS + 1), FRIENDS_PER_USER)
for f in friends:
if f != i:
session.run("""
MATCH (a:User {id: $id1}), (b:User {id: $id2})
MERGE (a)-[:FRIEND]->(b)
""", id1=i, id2=f)
return driver
def neo4j_query(driver):
with driver.session() as session:
start = time.time()
result = session.run("""
MATCH (u:User {id: 1})-[:FRIEND*5]->(fof)
WHERE fof.id <> 1
RETURN DISTINCT fof.id
""")
ids = [record["fof.id"] for record in result]
duration = time.time() - start
print(f"Neo4j 查询返回 {len(ids)} 条记录,用时 {duration:.4f} 秒")
return duration
# === 运行 ===
if __name__ == "__main__":
print("正在准备 MySQL 数据...")
mysql_conn = mysql_setup()
mysql_time = mysql_query(mysql_conn)
print("正在准备 Neo4j 数据...")
neo4j_driver = neo4j_setup()
neo4j_time = neo4j_query(neo4j_driver)
print("\n=== 查询耗时对比 ===")
print(f"MySQL: {mysql_time:.4f} 秒")
print(f"Neo4j: {neo4j_time:.4f} 秒")运行前记得安装对应的库:
pip install mysql-connector-python neo4j
执行结果:
正在准备 MySQL 数据...
MySQL 查询返回 1999 条记录,用时 6.4406 秒
正在准备 Neo4j 数据...
Neo4j 查询返回 1999 条记录,用时 0.3012 秒
=== 查询耗时对比 ===
MySQL: 6.4406 秒
Neo4j: 0.3012 秒Neo4j 查询耗时 0.3 秒,MySQL 查询耗时 6.4 秒,相差约:21 倍
由此可以看出,在多层关联查询 层次较深时,neo4j图数据库的查询效率 会远快于 传统的关系型数据库,且实现时代码也较少。
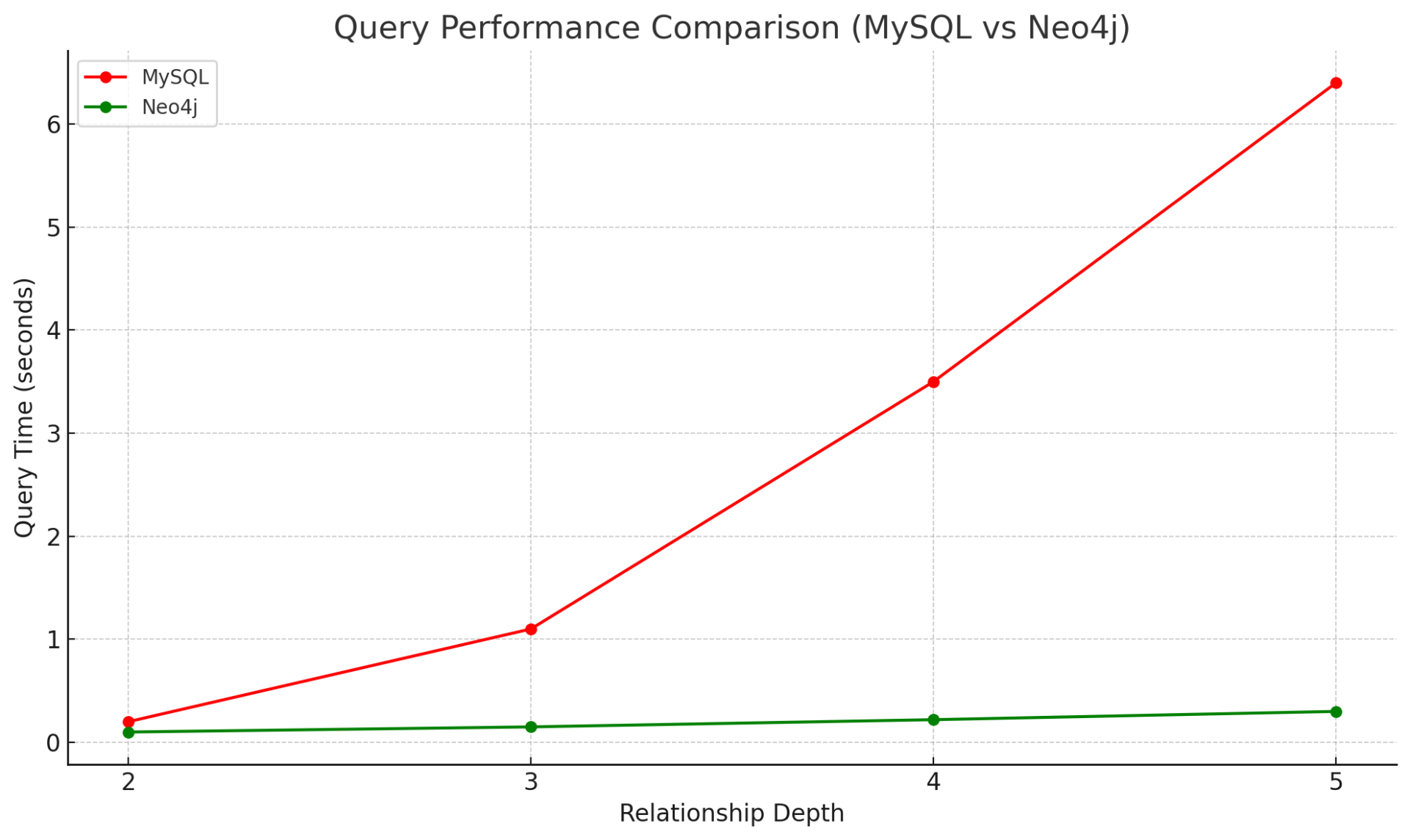
从实测我们可以得出类似上图的查询效率对比图,随着查询层数的增加,在mysql中所需要join的表越多,其查询效率呈指数分布;而在neo4j图数据库中变化不大仍然呈线性分布。
再从多维度对比关系型数据库和图数据库,总结出下表:
| 对比维度 | MySQL | Neo4j |
|---|---|---|
| 数据结构 | 表结构(users, friendships) | 图结构(节点+边) |
| 多层级关系查询 | 多次 JOIN | 一次图遍历 MATCH 语句 |
| 查询复杂度 | 指数增长 JOIN | 线性遍历 |
| 性能(层数增加) | 查询时间大幅增长 | 查询时间增长较缓 |
9. 小结
最近读了《午夜图书馆》总会觉得:人生无论怎么选,都会觉得不够完美,充满遗憾。
这和做技术有点类似,过一段时间之后再回过头看之前的技术方案,我们也总会觉得还不够完美,想要再改改完善。
所以,在做决策前做好充分的调研,在一定程度上能尽量减少一些遗憾,毕竟对已上线的项目进行调整也往往伴随着一定的风险。
在本文中总结了各种数据库的特点,写完后自己感觉有种浅尝辄止的样子,后期有机会再针对某些细节进行一步展开。
放假第一天,端午快乐~