在日常工作中,无论是处理销售数据、分析用户行为,还是统计气象信息,我们常常需要从大量数据中提取关键信息。
在PostgreSQL里,聚集函数就能帮你搞定这些事。它能从多行数据中计算出一个结果,如:
count(计数): 能数出有多少条记录
sum(和) :能算出数值的总和
avg(均值) :能得出平均值
max(最大值) 和 min(最小值):能找出最大值和最小值。
假设查询天气表weather记录城市的最低温度temp_low。
SELECT max(temp_lo) FROM weather;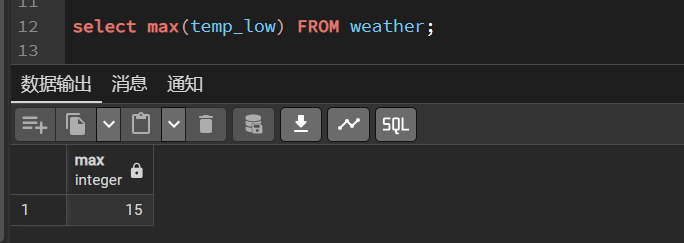
一.WHERE子句进行条件筛选****
WHERE子句的作用是在聚集计算之前筛选出符合条件的行,而聚集函数的结果是在行筛选之后才计算出来的。
SELECT city FROM weatherWHERE temp_low = (SELECT max(temp_low) FROM weather);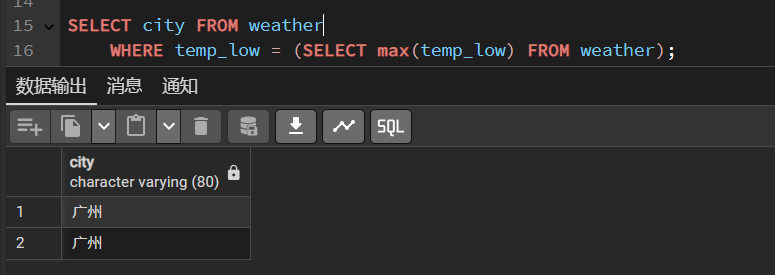
注意:不能直接在WHERE子句里用max(temp_low)。
二.GROUP BY分组统计
当数据量大且包含多种分类时,GROUP BY子句就派上用场了。
比如,我们想看看每个城市的天气记录数量以及城市的最低温度中最高值,就可以这样写:
SELECT city, count(*), max(temp_low)FROM weatherGROUP BY city;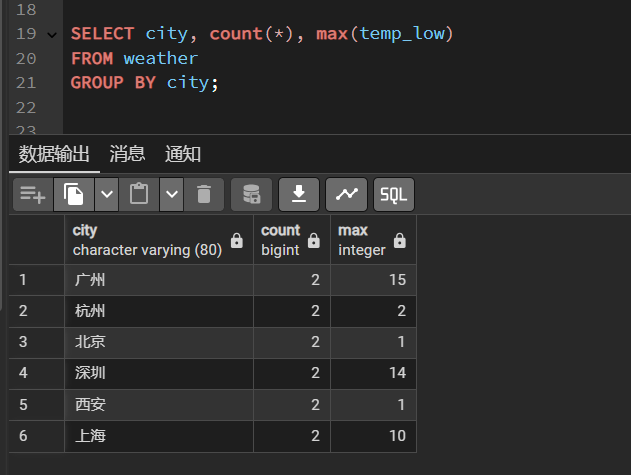
把天气表数据按城市分类,然后将分类数据进行统计,显示每个城市有多少条记录,以及每个城市最低温度中的最高值。
还可以用HAVING子句来过滤上面分组后的数据。比如只看每个城市最低温度中最高值小于10的城市,可以在上面语句上加having条件,如下
SELECT city, count(*), max(temp_low)FROM weatherGROUP BY cityHAVING max(temp_low) < 10;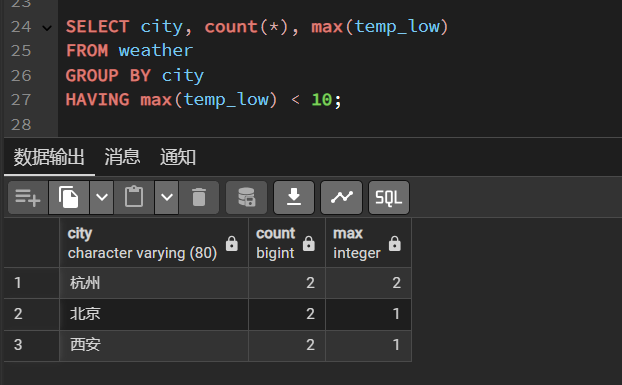
分类统计之后,再把不符合要求的分类结果去掉。
注意:where和having的区别。where 是在分组和聚集计算之前筛选数据,而having是在分组和聚集计算之后筛选分组。
三.FILTER 精细化聚集控制
PostgreSQL还提供了一个很实用的功能------filter。可以让聚集函数只对符合条件的行进行计算。
比如统计每个城市中最低温度小于10的数量,但又不影响其他聚集函数的计算,可以这样写:
SELECT city, count(*) FILTER (WHERE temp_low < 10), max(temp_low)FROM weatherGROUP BY city;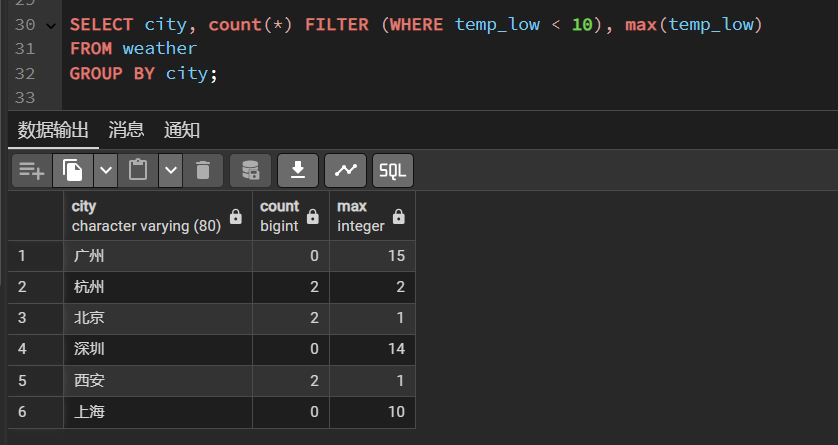
为count函数加了一个"过滤器",只即使最低温度小于10的行,而max函数还是对所有记录计算,实现更加灵活的精细化控制。
最后
PostgreSQL的聚集函数是一个强大的工具。通过合理使用WHERE、GROUP BY、HAVING和FILTER,可以精确地控制数据的筛选、分组和统计过程,让数据为我们更好地服务。
掌握这些技巧能让我们在数据处理的道路上更加得心应手。