学会如何拆分问题,使其能够高效地分配到多个核心上并行处理
- 把一个大问题拆成多个小任务
- 让这些任务能独立运行在多个 CPU 核心上
- 充分利用多核架构提升性能和吞吐量
- 同时避免任务间过多依赖或冲突,保证并行效率
- 星星计数问题
一个相对简单的问题,适合用来学习和接触多核并行处理的基本要点。 - n 体问题
更复杂一点,需要重新组织结构,
通过递归的方式解决,
同时能获得更好的缓存利用率(cache locality),提升性能。
这段关于并行化原则的重点:
-
主要挑战
找出程序中任务之间最少交互、因而可以逻辑上并行执行的部分。
-
并行化是科学与艺术的结合
既要发现已有的并行性(算法或数据结构中固有的),
又要创造或选用新算法,重构、简化或近似问题。
-
过程
发现并行性 → 选择/发明适合的算法 → 重构和简化 → 实现并行。
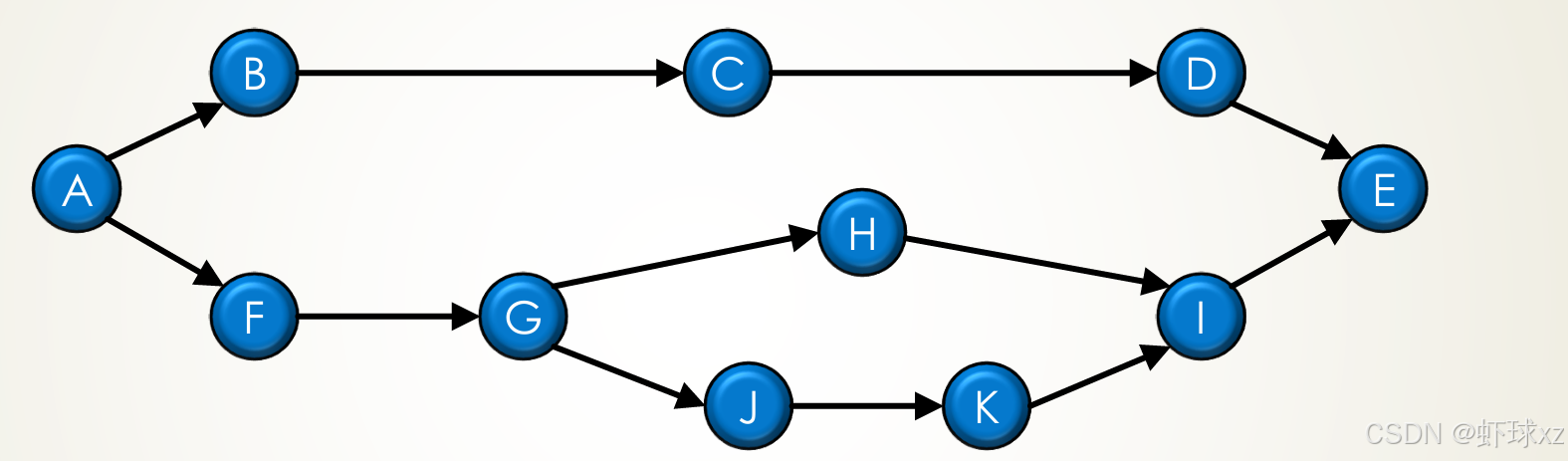
这段内容讲的是并行性 从算法角度看是一种图论性质:
-
图中节点代表任务,边表示依赖关系(箭头方向表示控制流,依赖是反向的)。
-
例如:
- A ≺ B 和 A ≺ F:A 先于 B 和 F 执行(A 是 B 和 F 的前驱)。
- B ∥ F:B 和 F 之间无依赖,可以并行执行。
- K ≻ G:K 在 G 之后执行。
- K ∥ H,K ∥ B,K ∥ C:K 与 H、B、C 互相独立,可以并行。
总结:
-
并行任务是图中没有依赖关系的节点,可以同时执行。
-
依赖关系限制了并行度。
这段代码展示了Cilk™ Plus语言的基本并行控制结构,用来教学并行编程概念:
cpp
int fib(int n)
{
if (n < 2)
return n;
// 并行调用fib(n-1),不等待其完成
int a = cilk_spawn fib(n - 1);
// 这里同步调用fib(n-2)
int b = fib(n - 2);
// 等待所有cilk_spawn启动的任务完成,保证a可用
cilk_sync;
return a + b;
}
// 函数结束时有隐式同步,确保所有并行任务完成
// 并行循环示例
cilk_for (auto i = vec.begin(); i != vec.end(); ++i)
{
// 循环体内容,迭代可并行执行
}
// cilk_for 结束时隐式同步,保证所有迭代完成cilk_spawn启动fib(n-1)异步执行。fib(n-2)同步执行。cilk_sync等待fib(n-1)结束,保证安全使用a。cilk_for实现循环并行。
如果你需要,我可以帮你写更多示例!cilk_spawn:异步调用,函数fib(n-1)会被并行启动,调用线程不会等待它完成。cilk_sync:同步点,等待所有用cilk_spawn启动的任务完成,保证a计算完毕再使用。- 隐式同步:函数体结束时隐式执行同步,确保所有派生任务完成。
cilk_for:并行循环,循环迭代可以并发执行 ,并且循环结束时隐式同步。
总结:cilk_spawn是并行启动任务的关键。cilk_sync等待所有异步任务完成。- 通过隐式同步,代码简洁且安全。
cilk_for使循环并行化容易实现。
这些特性使得 Cilk Plus 适合教学并行编程的基本概念和实践。
"星星计数"(star-counting)的问题,逐步引导你:
- 问题介绍
说明什么是星星计数问题,任务目标是什么。 - 串行实现
用单线程写出基础版本,方便理解算法和逻辑。 - 发现并行性
找出哪些计算可以同时进行,没有数据依赖。 - 使用原子变量修复竞态条件
并行后多个线程可能写同一个变量,导致竞态,用原子操作解决。 - 用归约(reduction)进一步提升性能
用归约操作减少同步开销,更高效地统计结果。
如果你想,我可以帮你写对应的代码示例,比如:
- 单线程星星计数实现
- OpenMP 并行加 atomic 修复竞态
- OpenMP 用 reduction 提升性能
给出的代码是星星计数问题的串行实现示例:
cpp
long count_stars(const Image& img)
{
long count(0);
// 遍历图像中所有像素
for (int x = 0; x < img.width(); ++x)
for (int y = 0; y < img.height(); ++y)
if (is_center_of_star(img, x, y))
++count;
return count;
}含义:
- 遍历整张图片的每个像素 (x, y)
- 判断该点是否为"星星的中心"(假设有个函数
is_center_of_star) - 如果是,就把计数器加一
- 最后返回计数值
这段代码是并行化的起点,先确保串行逻辑正确,再考虑怎样拆分任务、并行执行。
cpp
long count_stars(const Image& img) {
long count(0);
// Iterate over the pixels of the image
for (int x = 0; x < img.width(); ++x)
for (int y = 0; y < img.height(); ++y)
if (is_center_of_star(img, x, y)) ++count;
return count;
}- 这段代码里 每个像素点的判断
is_center_of_star(img, x, y)是完全独立的,可以同时执行(潜在的并行任务)。 - 但
++count操作是对同一个变量的写操作,有数据竞争问题,不能直接并行。 - 循环本身是发现并表达并行性的一个好地方,因为每次迭代任务基本独立。
换句话说: - 逻辑上,"每个像素是否是星星中心"是并行的。
- 但是"累加计数器"需要同步,否则会有竞态条件(race condition)。
cpp
long count_stars(const Image& img) {
long count(0);
// Iterate over the pixels of the image
cilk_for(int x = 0; x < img.width(); ++x)
cilk_for(int y = 0; y < img.height(); ++y)
if (is_center_of_star(img, x, y))
++count;
return count;
}这段代码用 cilk_for 并行遍历二维像素点,但 ++count 是多个线程共享变量的写操作,产生 数据竞争(data race) ,结果不正确。
具体原因是:
- 多个线程同时执行
++count,导致操作不是原子性的,计数器会出错,计数不准确。
这说明简单地把循环并行化,还要注意对共享变量的访问同步。
接下来可以通过以下两种方法解决:
- 使用原子操作(atomic) 保护计数器增量。
- 用并行归约(reduction) 把每个线程局部计数后合并。
这段代码使用了 std::atomic<long> 来解决并发写入 count 时的数据竞争问题:
cpp
std::atomic<long> count(0);这样确实解决了数据正确性 的问题,但它也引入了性能瓶颈(contention):
问题:Atomic Variable Contention(原子变量争用)
发生什么?
多个线程频繁对同一个原子变量执行 ++count 操作时,会发生:
- 缓存一致性流量(比如通过 MESI 协议)变高
- 总线锁(或 cache line ping-pong)造成延迟
- 每次原子加法都阻塞其他线程对该变量的写访问
结果就是:性能下降,尤其在核心数较多时变得明显。
更好的解决方案:reduction(归约)
使用像 Cilk 的 reducer,这样每个线程维护自己的局部变量,最后合并。
示例代码(使用 Cilk Reducer):
cpp
#include <cilk/reducer_opadd.h>
long count_stars(const Image& img)
{
cilk::reducer<cilk::op_add<long>> count(0);
cilk_for (int x = 0; x < img.width(); ++x)
{
cilk_for (int y = 0; y < img.height(); ++y)
{
if (is_center_of_star(img, x, y))
++count;
}
}
return count.get_value();
}为什么更好?
| 方法 | 正确性 | 性能 | 并发友好 |
|---|---|---|---|
std::atomic |
✔️ | (高争用) | |
Cilk reducer |
✔️ | ✔️(局部累加) | ✔️ |
总结
std::atomic是 简单但慢 的解决方案,适合低并发场景或调试reducer是 更高性能的并行归约方案,适合生产环境
"Cache Ping-Pong on atomic count"
什么是 Cache Ping-Pong?
当多个线程频繁对一个共享的原子变量(如 count)执行写操作时,该变量所在的 cache line 在多个核心之间不断移动(被"踢来踢去"),这就叫做:
Cache Ping-Pong(缓存乒乓)
背后的原理(基于 MESI 缓存一致性协议)
关键概念:MESI 状态机
缓存行在 CPU 缓存中可能是以下四种状态之一:
- Modified(已修改)
- Exclusive(独占)
- Shared(共享)
- Invalid(无效)
发生什么?
- 线程 A 执行
++count:count被加载到线程 A 的 L1 cache 并进入 Modified 状态。
- 线程 B 也想执行
++count:- 它必须让线程 A 的 cache line 失效(invalidate)。
- 然后从主内存中拉取更新后的
count。 - 进入它自己的 cache,并进入 Modified 状态。
- 重复以上过程...
每个原子操作都触发缓存失效 + 重读 ,称为 false sharing 或 ping-pong effect。
为什么慢?
- 每次原子增加都导致 缓存同步成本很高(数百个 CPU 周期)
- 主存带宽和一致性协议压力剧增
- 并行越多,性能下降越明显
怎么解决?
- 使用局部变量 + reduction(归约)
- 每个线程单独计数,最后合并:
cpp
cilk::reducer<cilk::op_add<long>> count(0);- 或者在 OpenMP 中用:
cpp
#pragma omp parallel for reduction(+:count)并行累加方法:reduction(归约)。
下面是对这段代码的详细解释和背后原理的总结:
这段代码做了什么?
cpp
long count_stars(const Image& img)
{
cilk::reducer<cilk::op_add<long>> count_r(0);
cilk_for (int x = 0; x < img.width(); ++x)
cilk_for (int y = 0; y < img.height(); ++y)
if (is_center_of_star(img, x, y))
++*count_r;
return count_r.get_value();
}什么是 reducer?
cilk::reducer<T> 是 Cilk Plus 提供的一种 线程安全的并行累加器 。
它解决了原子变量争用问题的方法是:
每个线程 / 工作单元都有自己的局部副本(view),并在最终汇总所有结果。
如何工作?
执行过程:
cilk_for并行地运行任务。- 每个并发线程(worker)会:
- 拥有一个自己的
count_r副本(view); - 在本地对其执行
++操作,无需加锁或原子;
- 拥有一个自己的
- 最后
get_value():- 所有局部副本通过 归约操作
op_add<long>合并为一个总结果。
- 所有局部副本通过 归约操作
优点
| 优点 | 原因说明 |
|---|---|
| 无锁竞争(No contention) | 每个线程写自己的副本,无需频繁同步 |
| 高性能 | 避免 cache ping-pong 和原子操作的成本 |
| 正确性保证 | cilk::reducer 自动处理并行结果合并,线程安全 |
| 接口友好 | 像指针一样使用:++*count_r,并通过 .get_value() 获取 |
reducer 的概念性执行过程 ------解释了 为什么 reducer 在并行累加中是高效且正确的。下面我帮你逐条拆解它的含义:
Reducer Operation(归约操作)的核心思想:
场景:并行地统计星星数量
cpp
++*count_r;这句代码在多个线程上并发执行,count_r 是 cilk::reducer<cilk::op_add<long>> 类型。
图解说明:CPU 0 和 CPU 1 的执行
并行环境中:
| 线程 | 本地 view(局部副本) | 操作 |
|---|---|---|
| CPU 0 | view0_count |
3 次 ++,因为有 3 个星星中心 |
| CPU 1 | view1_count |
2 次 ++,因为有 2 个星星中心 |
| 每个线程只操作自己的局部 view: |
cpp
view0_count == 0 + 1 + 1 + 1 = 3
view1_count == 0 + 1 + 1 = 2汇总阶段(归约)
归约操作将所有 view 合并为一个值:
cpp
count == view0_count + view1_count
== 3 + 2
== 5为什么高效?
- 每个线程操作自己的副本,不会产生缓存失效(cache ping-pong)或原子锁竞争(lock contention)。
- 汇总操作只在并行循环结束后进行一次,代价极小。
- L1 cache 中的
viewX_count保持在本核可修改状态,避免频繁地在 CPU 之间来回传递数据。
关键词理解
view:每个线程的本地视图(副本)reducer:统一接口,负责在最后整合这些局部视图op_add<long>:归约操作符,定义了如何合并 view(这里是加法)
总结一句话:
Reducer 的并行归约设计,通过"每线程局部视图 + 最后汇总",同时解决了性能和正确性问题,是并行编程中非常实用的模式。
**n-body 问题(多体问题)**的并行处理介绍完整的学习和实现路径。
下面是详细解释每一步的含义,帮助你真正"理解":
The N-Bodies Problem(n体问题)是什么?
物理模拟中,每个物体都受到其它所有物体的引力,需要计算所有物体之间的相互作用力,然后更新位置与速度。
复杂度:O(n²),因为每个物体都要跟所有其他物体交互。
学习路径的五个步骤解释:
1. Introduction to the problem
- 解释什么是 n-body 问题(上面我们刚讲了)
- 它在物理、游戏、天体模拟中的实际用途
2. Basic implementation framework
- 写出一个串行版本 的基础框架
- 遍历所有粒子对:双重循环
- 计算力、更新加速度
- 积分更新速度与位置
3. Parallelize the parts with parallel loops
- 对于外循环或内循环,使用
cilk_for或parallel_for做并行化处理 - 例如:每个粒子计算受力时,可以在多个线程上同时处理
4. Try different approaches to mitigate data races
- 由于多个线程可能对同一个粒子更新力,需要处理 数据竞争(data races)
- 方法:
- 使用
atomic(性能差) - 每线程独立数组 + 汇总(高效)
- Reducer(取决于操作)
- 使用
- 方法:
5. Restructure the code into an elegant recursive algorithm with excellent cache locality
- 这一步是重构 + 优化
- 使用空间划分(如 Barnes-Hut 或 Fast Multipole Method)将粒子按空间分组
- 递归处理局部区域,显著减少计算量 + 提高缓存命中率
- 形成具有优秀 cache locality 的递归结构
总结重点:
| 阶段 | 目的 |
|---|---|
| 串行实现 | 搞清楚基本算法 |
| 并行循环 | 加速计算 |
| 处理数据竞争 | 保证正确性 |
| 结构重构 + 局部性 | 提升效率 + 可扩展性 |
| 这套过程不仅适用于 n-body 问题,也适合你之后处理所有复杂数据并行问题的场景。 |
引力模拟和行星运动的数值计算方法 ,是 n-body 问题的物理基础。下面是详细解释:
重力与行星运动模拟核心思想:
我们要模拟多个物体(行星、恒星等)在引力作用下的运动轨迹 。这是物理中的典型多体问题(n-body problem)。
每一步模拟的基本计算流程:
1. 计算引力
任意两个物体之间的引力为:
f i j = G ⋅ m i ⋅ m j d i j 2 f_{ij} = \frac{G \cdot m_i \cdot m_j}{d_{ij}^2} fij=dij2G⋅mi⋅mj
- G G G:万有引力常数
- m i , m j m_i, m_j mi,mj:两个物体的质量
- d i j d_{ij} dij:两者间的距离
2. 求合力
对于第 i i i 个物体,所有其他物体对它的合力是:
F i = ∑ j ≠ i f i j F_i = \sum_{j \ne i} f_{ij} Fi=j=i∑fij
注意这个步骤是 O(n²),因为每个物体都要与所有其他物体计算引力。
更新运动状态
根据牛顿第二定律 F = m ⋅ a F = m \cdot a F=m⋅a,得出加速度:
a i = F i m i a_i = \frac{F_i}{m_i} ai=miFi
然后使用离散时间步长 Δ t \Delta t Δt 更新速度和位置:
- 更新速度:
v i ′ = v i + F i m i ⋅ Δ t v_i' = v_i + \frac{F_i}{m_i} \cdot \Delta t vi′=vi+miFi⋅Δt - 更新位置:
x i ′ = x i + avg ( v i ) ⋅ Δ t x_i' = x_i + \text{avg}(v_i) \cdot \Delta t xi′=xi+avg(vi)⋅Δt
其中avg(v_i)是当前速度和更新后的速度的平均值(即半隐式欧拉法或梯形法)。
整体模拟流程:
- 对于每一个物体 i:
- 初始化力为 0
- 对每一个 j ≠ i:
- 计算 f_ij,加到 F_i
- 用 F_i 更新 v_i 和 x_i
- 重复以上步骤若干时间步
小结:
| 关键概念 | 意义 |
|---|---|
| f i j f_{ij} fij | 两个物体间的引力(平方反比) |
| F i F_i Fi | 所有其他物体对物体 i 的合力 |
| v i ′ , x i ′ v_i', x_i' vi′,xi′ | 更新后的速度和位置(欧拉或半隐式积分) |
| 每步都做 O ( n 2 ) O(n^2) O(n2) | 因为要计算所有 i-j 对 |
| 时间步长 Δ t \Delta t Δt | 模拟步进,用于连续地推进时间线上的位置和速度 |
n-body 模拟的一个实验性运行实例 ,用于演示模拟效果。以下是对这段话的逐行解释:
示例运行参数解析
模拟设置:
- 300 个天体(Bodies) :
- 这是模拟的规模,即 300 个互相吸引的物体,彼此之间都计算引力。
- 4000 个时间步(Time Steps) :
- 每一步表示时间向前推进一小段,模拟中每步都更新所有物体的位置和速度。
- 每 40 步输出一帧图像 :
- 用于可视化:每模拟 40 步,记录一个图像帧。
- 总帧数:
4000 40 = 100 帧 \frac{4000}{40} = 100 \text{ 帧} 404000=100 帧
动画说明:
- 不是实时动画 :
- 模拟可能花费了较长计算时间,渲染图像后再组合成动画。
- 制作方式 :
- 将这 100 帧图像按 每秒 10 帧(fps) 生成了一个 GIF 动画。
- 设置了 循环播放(loop),使动画不断重复显示模拟过程。
小结:
| 项目 | 含义 |
|---|---|
| 300 bodies | 多体系统的规模 |
| 4000 steps | 总模拟时间长度(更高精度、更真实轨迹) |
| 1 frame / 40 steps | 控制动画平滑度(每 40 步记录一个静态帧) |
| 100 frames | 最终生成的图像帧数量 |
| 10 fps | 生成的动画播放速度 |
| Looping | 动画持续循环播放,便于演示 |
这段代码示例展示了 n-body 模拟的核心数据结构和主循环框架。我帮你总结并解释一下关键点:
结构体 Body
cpp
struct Body {
double x; // x 位置
double y; // y 位置
double xv; // x 速度
double yv; // y 速度
double xf; // x 作用力
double yf; // y 作用力
double mass; // 质量
double density; // 密度
Pixel pix; // 颜色(绘制用)
};- 用于表示一个天体的所有重要属性。
- 位置、速度、力都是二维向量(x,y)。
- 质量和密度描述物理属性。
Pixel pix用于绘制时表示颜色。
主函数 main
cpp
int main(int argc, char* argv[])
{
int nbodies = argc > 1 ? atoi(argv[1]) : 300; // 天体数量,默认300
int nframes = argc > 2 ? atoi(argv[2]) : 100; // 帧数,默认100(这里你写错了argc>2时用了argv[1],应该是argv[2])
Body *bodies = new Body[nbodies]; // 动态分配天体数组
initialize_bodies(nbodies, bodies); // 初始化天体属性
draw_frame(0, nbodies, bodies); // 画第0帧
for (int frame_num = 1; frame_num < nframes; ++frame_num) {
for (int i = 0; i < steps_per_frame; ++i) { // 每帧模拟多步
calculate_forces(nbodies, bodies); // 计算天体间力
update_positions(nbodies, bodies); // 更新天体位置和速度
}
draw_frame(frame_num, nbodies, bodies); // 绘制当前帧
}
delete[] bodies; // 释放内存
}- 允许通过命令行参数指定天体数量和帧数,默认300个天体和100帧。
steps_per_frame控制每帧内部模拟多少时间步,保持动画平滑和数值精度。- 模拟流程:
- 初始化天体数据。
- 先画初始帧。
- 对每一帧:
- 循环计算力和更新位置若干次。
- 绘制当前帧。
- 释放资源。
小结
- 数据结构清晰,覆盖了天体动力学需要的所有信息。
- 主循环设计合理,分离计算和绘制。
计算了引力中,天体 bj 对天体 bi 施加的力(力的x和y分量),符合万有引力公式。
具体解释如下:
代码分析
cpp
void calculate_force(double *fx, double *fy,
const Body &bi, const Body &bj)
{
double dx = bj.x - bi.x; // 两个天体x坐标差
double dy = bj.y - bi.y; // 两个天体y坐标差
double dist2 = dx * dx + dy * dy; // 距离平方 d_ij^2
double dist = std::sqrt(dist2); // 距离 d_ij
double f = bi.mass * bj.mass * GRAVITY / dist2; // 引力大小 F = G * m_i * m_j / d^2
*fx = f * dx / dist; // 力在x方向的分量 = F * (dx / d)
*fy = f * dy / dist; // 力在y方向的分量 = F * (dy / d)
}物理背景
- 万有引力定律 :
f i j = G m i m j d i j 2 f_{ij} = \frac{G m_i m_j}{d_{ij}^2} fij=dij2Gmimj
这里 G G G 是万有引力常数, m i , m j m_i, m_j mi,mj 是两个天体的质量, d i j d_{ij} dij 是它们之间的距离。 - 力的方向是沿着两天体连线的方向,分解为 x,y 分量时,除以距离 d i j d_{ij} dij 来标准化方向向量。
结果
- 输出的 ∗ f x *fx ∗fx, ∗ f y *fy ∗fy 即为 bj 对 bi 施加的力在x和y方向的分量。
- 调用时,一般会对每个天体对所有其它天体调用这个函数,累加所有力。
实现了把计算得到的力分量 (fx, fy) 累加到目标天体 b 上的操作,具体作用是更新天体 b 受到的合力。
代码解析
cpp
void add_force(Body* b, double fx, double fy)
{
b->xf += fx; // 累加x方向的力
b->yf += fy; // 累加y方向的力
}b->xf和b->yf分别代表天体b当前受到的合力在 x 和 y 方向上的分量。- 每次调用该函数,都会把传入的
fx和fy累加进去。 - 这样,当你遍历所有其他天体计算
f_ij后,累加所有对天体 i 的力,最终xf和yf就是天体 i 受到的总力:
F i = ∑ j ≠ i f i j F_i = \sum_{j \neq i} f_{ij} Fi=j=i∑fij
物理意义
- 计算每个天体的合力是进行下一步更新速度和位置的基础。
- 合力 F i F_i Fi 决定了天体 i 的加速度,进而影响运动轨迹。
天体系统中更新每个天体速度和位置的串行实现。
代码解析
cpp
void update_positions(int nbodies, Body *bodies)
{
for (int i = 0; i < nbodies; ++i) {
// 记录当前速度
double xv0 = bodies[i].xv;
double yv0 = bodies[i].yv;
// 根据力计算加速度,更新速度
bodies[i].xv += TIME_QUANTUM * bodies[i].xf / bodies[i].mass;
bodies[i].yv += TIME_QUANTUM * bodies[i].yf / bodies[i].mass;
// 清零力,为下一步计算做准备
bodies[i].xf = 0.0;
bodies[i].yf = 0.0;
// 使用速度平均值,更新位置(简单的梯形积分法)
bodies[i].x += TIME_QUANTUM * (xv0 + bodies[i].xv) / 2.0;
bodies[i].y += TIME_QUANTUM * (yv0 + bodies[i].yv) / 2.0;
}
}物理背景
- 根据牛顿第二定律: a = F m a = \frac{F}{m} a=mF,加速度由力和质量决定。
- 速度更新:
v i ′ = v i + F i m i Δ t v_i' = v_i + \frac{F_i}{m_i} \Delta t vi′=vi+miFiΔt - 位置更新用了速度的平均值:
x i ′ = x i + v i ˉ Δ t = x i + v i + v i ′ 2 Δ t x_i' = x_i + \bar{v_i} \Delta t = x_i + \frac{v_i + v_i'}{2} \Delta t xi′=xi+viˉΔt=xi+2vi+vi′Δt
这种做法相比简单的 x i ′ = x i + v i Δ t x_i' = x_i + v_i \Delta t xi′=xi+viΔt 更精确。
并行更新思路
- 这个函数的每次循环迭代都只操作自己的
bodies[i],所以可以安全地并行化。 - 例如使用
cilk_for并行化循环:
cpp
void update_positions(int nbodies, Body *bodies)
{
cilk_for (int i = 0; i < nbodies; ++i) {
double xv0 = bodies[i].xv;
double yv0 = bodies[i].yv;
bodies[i].xv += TIME_QUANTUM * bodies[i].xf / bodies[i].mass;
bodies[i].yv += TIME_QUANTUM * bodies[i].yf / bodies[i].mass;
bodies[i].xf = 0.0;
bodies[i].yf = 0.0;
bodies[i].x += TIME_QUANTUM * (xv0 + bodies[i].xv) / 2.0;
bodies[i].y += TIME_QUANTUM * (yv0 + bodies[i].yv) / 2.0;
}
}这样,多个天体的位置和速度更新可以并行执行,加速计算。
几种主流的并行更新天体位置和速度的方法,示例包含了:
1. TBB 并行版本(Intel Threading Building Blocks)
cpp
tbb::parallel_for(0, nbodies, [&](int i) {
// 这里写每个体的更新代码
double xv0 = bodies[i].xv;
double yv0 = bodies[i].yv;
// 更新速度和位置的代码...
});- 利用
tbb::parallel_for分发任务,实现并行。
2. Cilk Plus 并行版本
cpp
cilk_for (int i = 0; i < nbodies; ++i) {
double xv0 = bodies[i].xv;
double yv0 = bodies[i].yv;
// 更新速度和位置的代码...
}cilk_for自动处理线程分配,简洁易用。
3. OpenMP 并行版本
cpp
#pragma omp parallel for
for (int i = 0; i < nbodies; ++i) {
double xv0 = bodies[i].xv;
double yv0 = bodies[i].yv;
bodies[i].xv += TIME_QUANTUM * bodies[i].xf / bodies[i].mass;
bodies[i].yv += TIME_QUANTUM * bodies[i].yf / bodies[i].mass;
bodies[i].xf = 0.0;
bodies[i].yf = 0.0;
// 位置更新
bodies[i].x += TIME_QUANTUM * (xv0 + bodies[i].xv) / 2.0;
bodies[i].y += TIME_QUANTUM * (yv0 + bodies[i].yv) / 2.0;
}- 使用
#pragma omp parallel for使循环并行化。
核心思想总结:
- 每个天体的数据独立,更新速度和位置时没有交叉写入,天然适合数据并行。
- 并行的重点是给每个
i迭代分配独立线程,避免数据竞争。 - 使用这些并行框架可以大幅提升计算效率,尤其是天体数量很大时。
cpp
void calculate_forces(int nbodies, Body *bodies) {
for (int i = 0; i < nbodies; ++i) {
for (int j = i + 1; j < nbodies; ++j) {
// update the force vector on bodies[i] exerted
// by bodies[j].
}
double fx, fy;
calculate_force(&fx, &fy, bodies[i], bodies[j]);
add_force(&bodies[i], fx, fy);
add_force(&bodies[j], -fx, -fy);
}
}这段代码的核心逻辑是:
- 对于每个天体
i,遍历所有其他天体j(除了自己), - 计算
j对i的引力calculate_force(&fx, &fy, bodies[i], bodies[j]), - 然后把这个力累加到
i的受力上add_force(&bodies[i], fx, fy)。
复杂度和问题
- 这是一个经典的 O(n²) 计算,
n(n-1)次力的计算。 - 串行版本 每次迭代都会累加力到同一个
bodies[i]对象中,没有数据竞争问题。 - 但是当想做并行化时,这种方式就会产生写共享(多个线程写
bodies[i].xf和bodies[i].yf),导致数据竞争。
你可以考虑的下一步是:
- 如何并行计算所有
i的力,同时避免数据竞争?(比如给每个线程分配一个私有的力累加器,最后归约) - 结构上有没有优化(比如Barnes-Hut算法)减少计算复杂度?
计算力时的迭代空间:
- 横轴是
j,从 0 到 n(粒子索引) - 纵轴是
i,从 0 到 n(另一粒子索引) - 通常只计算当
j > i时的力,因为力是作用对称的(f_ij和f_ji互为反向)
这样可以避免重复计算同一对粒子间的力,也减少一半的计算量。
尝试用 cilk_for 并行计算所有粒子对之间的引力:
cpp
void calculate_forces(int nbodies, Body *bodies) {
cilk_for (int i = 0; i < nbodies; ++i) {
for (int j = i + 1; j < nbodies; ++j) {
double fx, fy;
calculate_force(&fx, &fy, bodies[i], bodies[j]);
add_force(&bodies[i], fx, fy);
add_force(&bodies[j], -fx, -fy); // 作用力和反作用力
}
}
}说明:
- 通过并行化外层循环
i,不同线程同时计算不同的i。 - 对于每个
i,内层循环遍历j > i,保证每对粒子力只计算一次。 - 力是作用与反作用,故对
bodies[i]和bodies[j]分别调用add_force,传入正负力。
但这段代码有数据竞争风险:
多个线程可能同时修改同一个bodies[j]的力(xf、yf),导致竞态条件(race condition),因为add_force更新的是共享变量。
并行执行流程中:
- 不同线程同时执行
calculate_force和add_force。 - 当线程
i=1和i=2几乎同时运行时,它们可能都对bodies[2]调用add_force。 - 这就导致多个线程竞相修改
bodies[2].xf和bodies[2].yf,发生 数据竞争(race condition) 。
这就是为什么简单并行化外层循环时,针对共享变量(力的累加)的写操作会造成错误结果。
通常解决方案包括: - 使用 原子操作(atomic)保护力的累加(但性能受限,频繁争用缓存行)。
- 为每个线程分配独立的累加空间,最后合并结果(reduction 或者 局部力缓冲区)。
- 重构算法(如 Barnes-Hut 树等),减少必要的交互写入。
思路是给每个 Body 添加一个互斥锁(SmallMutex),在更新力(add_force)时对对应的身体加锁,避免多个线程同时写同一个 Body 的力值,防止数据竞争。
伪代码示意:
cpp
struct Body {
// 其他成员...
SmallMutex mutex; // 互斥锁,可能是自旋锁
};
void calculate_forces(int nbodies, Body* bodies) {
cilk_for (int i = 0; i < nbodies; ++i) {
for (int j = i + 1; j < nbodies; ++j) {
double fx, fy;
calculate_force(&fx, &fy, bodies[i], bodies[j]);
{
std::lock_guard<SmallMutex> g(bodies[i].mutex);
add_force(&bodies[i], fx, fy);
}
{
std::lock_guard<SmallMutex> g(bodies[j].mutex);
add_force(&bodies[j], -fx, -fy);
}
}
}
}- 对每个
Body的力累加操作都被保护了,避免了竞态条件。 - 但是,锁的频繁请求和释放会带来性能开销,尤其是高竞争时会导致性能下降。
这是"明显的解决方案",简单粗暴但不高效。
这是另一种思路,叫做 "hashed mutexes"(哈希互斥锁):
- 不为每个 Body 维护独立的锁 ,而是创建一个固定数量的锁数组(这里是
mutex_array[64])。 - 通过对
Body对象地址的哈希(size_t(this) / sizeof(Body))来决定用哪个锁。 - 这样多个
Body共享同一个锁,但锁的数量远小于 Body 数量,减少内存开销。 - 使用共享锁的代价是,可能会产生更多锁竞争(因为不同的
Body可能映射到同一个锁),但减少了锁管理复杂度。
代码示例简化版:
cpp
struct Body {
// ...数据成员...
};
static std::mutex mutex_array[64];
std::mutex& mutex_for_body(const Body* b) {
size_t hash = size_t(b) / sizeof(Body);
return mutex_array[hash % 64];
}
// 使用示例
{
std::lock_guard<std::mutex> g(mutex_for_body(&bodies[i]));
add_force(&bodies[i], fx, fy);
}
{
std::lock_guard<std::mutex> g(mutex_for_body(&bodies[j]));
add_force(&bodies[j], -fx, -fy);
}优点:
- 减少了每个 Body 的锁开销(内存和管理复杂度)。
- 如果
mutex_array数量足够大,锁竞争会相对减少。
缺点: - 可能会出现"锁冲突",两个不同的 Body 需要同一个锁,导致不必要的串行化。
- 选择锁数组大小需要权衡:太小竞争多,太大浪费内存。
尝试用 std::atomic<double> 来避免锁的开销,直接对力(xf, yf)进行原子操作。
但这里有几个重要点:
1. std::atomic<double> 的限制
- C++ 标准库允许对浮点数做原子操作,但不支持直接的
fetch_add操作(对浮点数没有内置的原子加法指令)。 - 因此只能用
compare_exchange_weak或compare_exchange_strong来实现自旋锁式的原子加法。
2. 自旋循环实现原子加法
cpp
void add_force(Body* b, double fx, double fy)
{
double oxf = b->xf.load();
while (!b->xf.compare_exchange_weak(oxf, oxf + fx)) {
// oxf gets updated with current value if CAS fails, loop retries
}
double oyf = b->yf.load();
while (!b->yf.compare_exchange_weak(oyf, oyf + fy)) {
}
}- 这段代码会持续尝试将
xf从旧值改成新值(旧值+fx)。 - 如果在执行期间有其他线程更新了
xf,CAS 会失败,oxf会自动被新值更新,然后重试。 - 这是典型的无锁原子更新方式。
3. 性能和竞态
- 这避免了显式锁,减少了上下文切换开销。
- 但是如果线程竞争激烈(多个线程同时更新同一个力变量),CAS 循环会频繁失败,性能下降,导致"伪共享和自旋竞争"。
- 与哈希锁相比,适用于冲突少的情况。
总结对比
| 方案 | 优点 | 缺点 |
|---|---|---|
| 互斥锁 (mutex) | 简单,正确,适合高冲突 | 锁开销大,阻塞和上下文切换成本 |
| 哈希锁 | 减少锁数量,节省内存 | 锁冲突仍存在,可能串行化部分更新 |
| 原子CAS | 无锁,减少上下文切换,理论上快 | 高冲突时自旋开销高,代码更复杂 |
计算引力的朴素方法 ,即对每对体(i, j)都计算一次力,条件是 i ≠ j i \neq j i=j。
为什么说"counterintuitive: double the work"?
- 计算力的次数是 n × ( n − 1 ) n \times (n-1) n×(n−1),即对每个体 i,计算它与所有其他体 j 的力。
- 但实际上,力的作用是相互的:体 i 对体 j 的力和体 j 对体 i 的力大小相等,方向相反。
- 也就是说,计算 f i j \mathbf{f}{ij} fij 和 f j i \mathbf{f}{ji} fji 这两次计算是重复的(计算了两遍)。
优化思路
只计算一半的力,比如只计算 j > i j > i j>i 或 j < i j < i j<i 的部分:
cpp
for (int i = 0; i < nbodies; ++i) {
for (int j = i + 1; j < nbodies; ++j) {
double fx, fy;
calculate_force(&fx, &fy, bodies[i], bodies[j]);
add_force(&bodies[i], fx, fy);
add_force(&bodies[j], -fx, -fy); // 反方向的力
}
}这样:
- 计算力的次数减半,从 n ( n − 1 ) n(n-1) n(n−1) 降到 n ( n − 1 ) 2 \frac{n(n-1)}{2} 2n(n−1)。
- 同时,力的更新要同时作用到 i i i 和 j j j,保持力的守恒。
小结
虽然原始写法是简单直接,但会做重复计算,导致"看起来是做了双倍工作"。
通过只计算一半对称区间,结合对两个体的力更新,可以减少计算量,提高性能。
缓存友好的算法设计(Cache-Friendly Approach)
1. 问题背景:poor cache locality(缓存局部性差)
-
传统的双重循环:
cppfor (int i = 0; i < nbodies; ++i) for (int j = 0; j < nbodies; ++j) ... -
访问的
bodies数组元素跨度很大,导致CPU缓存行频繁失效(cache eviction),每次访问都可能要从主内存重新加载数据。 -
特别是在大数据和多核环境下,内存带宽成为瓶颈,严重影响性能。
2. 缓存局部性为什么对并行重要?
- 单核处理时缓存带宽就有限,多核并行时,多个核共享内存带宽,缓存未命中带来的开销更加突出。
- 缓存友好的访问模式能减少内存访问延迟,提高整体并行性能。
3. 2D 分块(2-D Tiling)技术
-
将二维循环空间划分为多个小的"块(tile)",使每个块内的数据访问都局部化,提升缓存命中率。
-
例如对图像的星星计数问题:
cppconstexpr int tile_size = 16; cilk_for (int x_tile = 0; x_tile < img.width(); x_tile += tile_size) cilk_for (int y_tile = 0; y_tile < img.height(); y_tile += tile_size) serial_count_stars(img, x_tile, tile_size, y_tile, tile_size); -
每个小块中处理一定数量的像素,数据集中,能更好地利用缓存。
4. cache-oblivious算法简介
- 这类算法不直接依赖具体缓存大小,但通过递归分块等方式自然产生良好的缓存行为。
- 设计时不必知道缓存参数,却能自动实现良好的缓存利用。
总结
- 优化目标是提高数据访问的缓存局部性。
- 分块技术(tiling)是常用手段。
- 并行时良好的缓存局部性能显著提高性能。
n-bodies问题 中 力计算的三角形迭代空间 ,使用 缓存无关的递归分块(cache-oblivious recursive tiling) 来优化并行和缓存局部性。
核心点总结:
1. 为什么传统的二维分块(tiling)不完全适用?
- n-bodies 问题中计算的迭代空间是上三角形(i < j),不是完整的矩形。
- 三角形的计算中,每对 (i, j) 计算要同时更新 bodiesi 和 bodiesj,存在依赖。
- 三角形区域的不同块之间有重叠的i或j范围,不能简单地全部并行。
2. 递归划分三角形与矩形
- 将迭代空间划分为:
- 两个三角形区域(上三角和下三角,形状类似原问题)
- 一个矩形区域(中间部分)
- 三角形之间的计算可以并行,因为它们的i范围不重叠,也不重叠j范围。
- 矩形被分成两个"组"A和B,这两组矩形内部可以并行,但A和B之间不并行。
3. 递归的好处
- 每个三角形和矩形区域可以继续递归细分成更小的三角形和矩形,形成递归树结构。
- 在每一层递归中,都能发现平行的子区域,继续并行处理。
- 这种递归划分方式不依赖具体缓存大小(cache-oblivious),但有效提升缓存局部性。
4. 并行性结构总结
- 两个三角形块并行。
- 矩形划分为A、B两组,组内可并行,组间串行。
- 递归细分保持了这种模式,递归深度与块大小共同决定性能和缓存效果。
简单示意伪代码框架
cpp
void compute_forces_recursive(int i_start, int i_end, int j_start, int j_end, Body* bodies) {
int size_i = i_end - i_start;
int size_j = j_end - j_start;
if (size_i <= base_case_threshold && size_j <= base_case_threshold) {
// 计算基准块(例如小块内的双循环)
for (int i = i_start; i < i_end; ++i)
for (int j = std::max(j_start, i + 1); j < j_end; ++j)
calculate_force_and_add(bodies, i, j);
return;
}
// 递归划分
int mid_i = (i_start + i_end) / 2;
int mid_j = (j_start + j_end) / 2;
// 分成两个三角形和一个矩形块,递归处理
cilk_spawn compute_forces_recursive(i_start, mid_i, j_start, mid_j, bodies); // 三角形A
cilk_spawn compute_forces_recursive(mid_i, i_end, mid_j, j_end, bodies); // 三角形B
compute_forces_recursive(mid_i, i_end, j_start, mid_j, bodies); // 矩形块
cilk_sync;
}结论
这种递归划分结合并行技术,既保证了:
- 计算的正确性和无数据冲突(避免重复计算和写冲突),
- 又提升了缓存局部性,
- 最大化并行度。
基于**缓存无关递归分块(cache-oblivious recursion)**的n-bodies算法核心代码。
1. 递归划分的核心思想
- triangle(n0, n1, bodies) 处理主三角区间 [n0, n1),保证 i < j。
- 当区间足够大时,递归划分为两个三角形子区间 + 一个矩形子区间:
- 两个三角形:分别处理左半和右半的"上三角区域"
- 矩形:连接两个三角形的交互区域,i在左半区,j在右半区
cpp
void triangle(int n0, int n1, Body *bodies) {
int dn = n1 - n0;
if (dn > 1) {
int nm = n0 + dn / 2;
cilk_spawn triangle(n0, nm, bodies);
triangle(nm, n1, bodies);
cilk_sync;
rect(n0, nm, nm, n1, bodies); // 连接矩形区域
}
}2. 矩形区域递归划分
- rect(i0, i1, j0, j1, bodies) 处理矩形子区间 [i0,i1) × [j0,j1)
- 分成四个更小的矩形,A和B两组交错并行:
- A组:左上和右下
- B组:左下和右上
- 使用阈值避免递归太深,递归到底部时用普通循环计算
- 并行使用
cilk_spawn和cilk_sync
cpp
void rect(int i0, int i1, int j0, int j1, Body *bodies) {
int di = i1 - i0, dj = j1 - j0;
constexpr int threshold = 16;
if (di > threshold && dj > threshold) {
int im = i0 + di / 2, jm = j0 + dj / 2;
cilk_spawn rect(i0, im, j0, jm, bodies); // A
rect(im, i1, jm, j1, bodies); // A
cilk_sync;
cilk_spawn rect(i0, im, jm, j1, bodies); // B
rect(im, i1, j0, jm, bodies); // B
cilk_sync;
} else {
// 基础情况,用循环计算
for (int i = i0; i < i1; ++i)
for (int j = j0; j < j1; ++j) {
double fx, fy;
calculate_force(&fx, &fy, bodies[i], bodies[j]);
add_force(&bodies[i], fx, fy);
add_force(&bodies[j], -fx, -fy);
}
}
}3. 优势和扩展
- 缓存无关:不依赖硬件缓存参数,递归自然带来良好的空间局部性。
- 并行效率高:不同递归子块可以并行处理,减少冲突和同步。
- 阈值优化:底层小块使用循环避免递归开销。
4. 还有哪些可以改进?
- 数据结构优化(比如结构体数组改为数组结构体)以适配SIMD向量化。
- 性能分析工具定位新的瓶颈。
- 实际硬件测试,验证理论优化效果。
总结
- 并行化的核心 是把问题拆分成相互独立的部分,能同时执行。
- 除了最简单的算法,并行化设计需要创造性思考,尤其在避免数据争用和保持高效缓存访问方面。
- 代码虽然逻辑正确,但负面缓存影响和锁竞争会拖慢程序,必须关注这些细节。
- 性能分析和反复调优是实现高效并行程序的关键。