本周基本就是在踩坑,没什么实质性的进展
下载模型文件
推荐一个网站,可以简单计算下模型推理需要多大显存:https://apxml.com/tools/vram-calculator
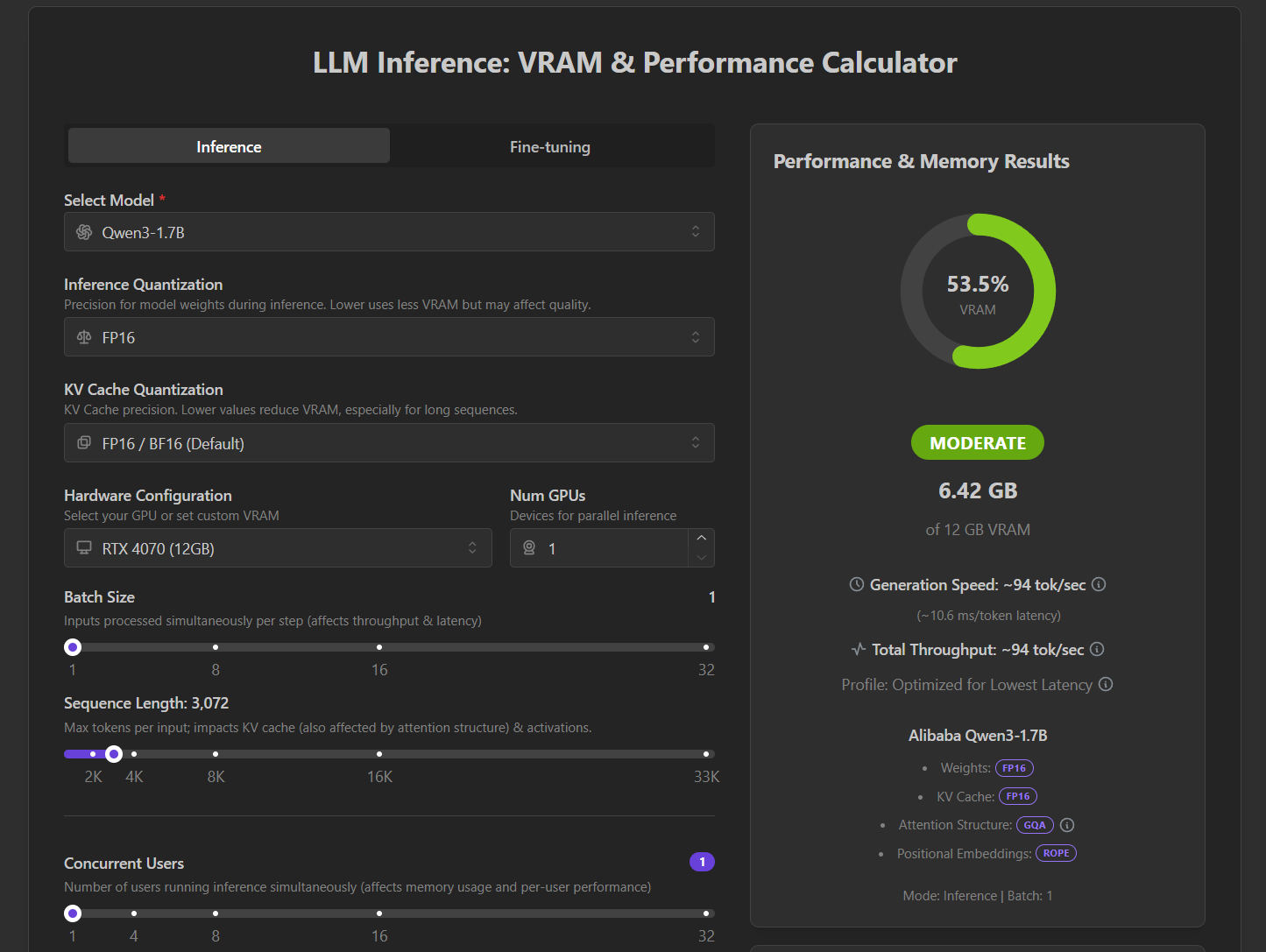
我的显卡是RTX 4070,有12GB的显存,部署一个1.7B的Qwen3应该问题不大。有之前使用LLM Studio的经验,这次我打算直接使用VLLM运行模型,用Openapi的接口调用。
从huggingface下载的全部文件如下:
bash
---- ------------- ------ ----
-a--- 2025/5/31 10:58 726 config.json
-a--- 2025/5/31 10:59 239 generation_config.json
-a--- 2025/5/31 10:58 1570 gitattributes
-a--- 2025/5/31 10:59 1671853 merges.txt
-a--- 2025/5/31 15:00 3441185608 model-00001-of-00002.safetensors
-a--- 2025/5/31 17:32 622329984 model-00002-of-00002.safetensors
-a--- 2025/5/31 10:59 25605 model.safetensors.index.json
-a--- 2025/5/31 10:58 13963 README.md
-a--- 2025/5/31 11:00 9732 tokenizer_config.json
-a--- 2025/5/31 11:00 11422654 tokenizer.json
-a--- 2025/5/31 11:01 2776833 vocab.jsonWSL
官方的教程只提到了Linux,那我首选当然是在WSL下部署。不过我的WSL并没有安装CUDA,Windows也没有。我决定先不装,看看直接安装VLLm会怎么样。
安装一行就够了:
bash
pip install vllm -i https://mirrors.aliyun.com/pypi/simple我用的阿里云镜像(因为之前下载了太多的apt库被清华源封禁了orz)
然后使用如下命令部署openai接口的llm server(vllm版本为0.9.0.1):
bash
python3 -m vllm.entrypoints.openai.api_server --model Qwen3-1.7B --host 0.0.0.0 --port 8000 --served-model-name qwen3--model后面需要接本地的模型位置,如果是在线模型会自动下载。--served-model-name可以为你部署的模型起一个别名,这样方便在post请求中访问
我也编写了测试的代码用于验证模型是否返回成功
python
import requests
import json
import time
# 服务地址
api_base = "http://127.0.0.1:8000/v1"
api_key = "none" # vLLM不需要API密钥,填任意值
# 请求头
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
# 请求参数
payload = {
"model": "qwen-3.5b-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "请问Python有哪些常用的深度学习框架?"}
],
"temperature": 0.7,
"max_tokens": 1024
}
# 发送请求
start_time = time.time()
response = requests.post(
f"{api_base}/chat/completions",
headers=headers,
data=json.dumps(payload)
)
end_time = time.time()
# 处理响应
if response.status_code == 200:
result = response.json()
print(f"生成时间: {end_time - start_time:.2f}秒")
print(f"模型: {result['model']}")
print(f"回复: {result['choices'][0]['message']['content'].strip()}")
else:
print(f"请求失败: {response.status_code}")
print(response.text)然而事实上是,VLLM运行成功了,而且我能明显看到显存占用:
显存占用如下:
bash
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.02 Driver Version: 560.94 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4070 On | 00000000:01:00.0 On | N/A |
| 30% 36C P8 10W / 215W | 11772MiB / 12282MiB | 15% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 1216 C /python3.10 N/A |
+-----------------------------------------------------------------------------------------+因为我没有限定token,也没有指定初始化参数,这个占用几乎就是贴着显存上限跑的。不过具体进程的显存占用就看不到了,因为如下原因:
bash
Processes
GPU instance ID : N/A
Compute instance ID : N/A
Process ID : 1216
Type : C
Name : /python3.10
Used GPU Memory : Not available in WDDM driver model我的显卡当前处于 WDDM 模式,WDDM模式下,nvidia-smi无法获得每个进程的显存占用,因为所有进程都是在WDDM这个抽象框架下运行的,nvidia驱动只能获得使用的进程名,无法准确获得每个进程所占用的显存.我可以选择拔掉显示器切换到TCC模式,这样就能看见显存占用了,但是显卡也显示不了图像了。。。
当然这不是最大的问题,最大的问题是就算在WSL本地,我也无法访问LLM的地址:
bash
bluebonnet27@bluebonnet27:~$ curl 127.0.0.1:8000
curl: (7) Failed to connect to 127.0.0.1 port 8000 after 0 ms: Connection refused由于VLLM的server是uvicorn驱动的,因此我怀疑是不是uvicorn的问题,一方面,我先使用python自带的http-server起一个服务器:
bash
python3 -m http.server 8000结果curl直接超时。。。
bash
bluebonnet27@bluebonnet27:~$ curl localhost:8000
curl: (28) Failed to connect to localhost port 8000 after 133901 ms: Connection timed out这个网络问题到现在我也没解决,如果下周还没解决,我只能先在代码里用本地调用的方式起大模型了。
Windows
Windows倒也能装VLLM,和WSL一个命令。安装过程会报一个诡异的错误:
bash
error: could not create 'build\bdist.win-amd64\wheel\.\vllm\model_executor\layers\fused_moe\configs\E=128,N=384,device_name=AMD_Instinct_MI300X,dtype=fp8_w8a8,block_shape=[128,128].json': No such file ordirectory这个报错的原因是Windows默认不支持超过260个字符的文件路径。去注册表解除限制即可:
- 按 Win + R 打开运行窗口,输入
regedit并回车。 - 导航到
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystem。 - 找到
LongPathsEnabled项,将其值设置为1。
然后我安装的VLLM在起模型的时候就报错了:
bash
PS D:\Codes\models> python -m vllm.entrypoints.openai.api_server --model Qwen3-1.7B --host 0.0.0.0 --port 8000 --served-name qwen3
INFO 06-02 17:18:26 [importing.py:16] Triton not installed or not compatible; certain GPU-related functions will not be available.
WARNING 06-02 17:18:26 [importing.py:28] Triton is not installed. Using dummy decorators. Install it via `pip install triton` to enable kernel compilation.
INFO 06-02 17:18:26 [__init__.py:243] Automatically detected platform cuda.
Traceback (most recent call last):
File "<frozen runpy>", line 189, in _run_module_as_main
File "<frozen runpy>", line 112, in _get_module_details
File "C:\privatePrograms\Lib\site-packages\vllm\__init__.py", line 12, in <module>
from vllm.engine.arg_utils import AsyncEngineArgs, EngineArgs
File "C:\privatePrograms\Lib\site-packages\vllm\engine\arg_utils.py", line 20, in <module>
from vllm.config import (BlockSize, CacheConfig, CacheDType, CompilationConfig,
File "C:\privatePrograms\Lib\site-packages\vllm\config.py", line 32, in <module>
from vllm.model_executor.layers.quantization import (QUANTIZATION_METHODS,
File "C:\privatePrograms\Lib\site-packages\vllm\model_executor\__init__.py", line 3, in <module>
from vllm.model_executor.parameter import (BasevLLMParameter,
File "C:\privatePrograms\Lib\site-packages\vllm\model_executor\parameter.py", line 9, in <module>
from vllm.distributed import get_tensor_model_parallel_rank
File "C:\privatePrograms\Lib\site-packages\vllm\distributed\__init__.py", line 3, in <module>
from .communication_op import *
File "C:\privatePrograms\Lib\site-packages\vllm\distributed\communication_op.py", line 8, in <module>
from .parallel_state import get_tp_group
File "C:\privatePrograms\Lib\site-packages\vllm\distributed\parallel_state.py", line 149, in <module>
from vllm.platforms import current_platform
File "C:\privatePrograms\Lib\site-packages\vllm\platforms\__init__.py", line 275, in __getattr__
_current_platform = resolve_obj_by_qualname(
^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\privatePrograms\Lib\site-packages\vllm\utils.py", line 2191, in resolve_obj_by_qualname
module = importlib.import_module(module_name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\privatePrograms\Lib\importlib\__init__.py", line 90, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\privatePrograms\Lib\site-packages\vllm\platforms\cuda.py", line 14, in <module>
import vllm._C # noqa
^^^^^^^^^^^^^^
ModuleNotFoundError: No module named 'vllm._C'核心在于最后一行,可能是因为我电脑上没有安装CUDA Toolkit,所以安装的VLLM版本不对,应该是CPU版本的
bash
PS D:\Codes\models> pip show vllm
Name: vllm
Version: 0.9.0.1
Summary: A high-throughput and memory-efficient inference and serving engine for LLMs
Home-page:
Author: vLLM Team
Author-email:
License:
Location: C:\privatePrograms\Lib\site-packages
Requires: aiohttp, blake3, cachetools, cloudpickle, compressed-tensors, depyf, einops, fastapi, filelock, gguf, huggingface-hub, lark, lm-format-enforcer, mistral_common, msgspec, ninja, numpy, openai, opencv-python-headless, opentelemetry-api, opentelemetry-exporter-otlp, opentelemetry-sdk, opentelemetry-semantic-conventions-ai, outlines, partial-json-parser, pillow, prometheus-fastapi-instrumentator, prometheus_client, protobuf, psutil, py-cpuinfo, pydantic, python-json-logger, pyyaml, pyzmq, regex, requests, scipy, sentencepiece, setuptools, six, tiktoken, tokenizers, tqdm, transformers, typing_extensions, watchfiles
Required-by:能看出来少了很多GPU相关的库,比如torch。鉴于官方没有对Windows的支持,只能暂时继续回去折腾WSL。