文章目录
- 前言
-
- 项目结果演示
- 技术栈:
- 结构与总体思路
- compiler编译功能
-
- [-common/util.hpp 拼接编译临时文件](#-common/util.hpp 拼接编译临时文件)
- [-common/log.hpp 开放式日志](#-common/log.hpp 开放式日志)
- [-common/util.hpp 获取时间戳方法-秒级](#-common/util.hpp 获取时间戳方法-秒级)
- [-common/util.hpp 文件是否存在](#-common/util.hpp 文件是否存在)
- [-compile_server/compiler.hpp 编译功能编写(重要)](#-compile_server/compiler.hpp 编译功能编写(重要))
- runner运行功能
-
- [-common/util.hpp 拼接运行临时文件](#-common/util.hpp 拼接运行临时文件)
- [-compile_server/runner.hpp 运行功能编写](#-compile_server/runner.hpp 运行功能编写)
- compile_run编译运行
-
- [-common/util.hpp 生成唯一文件名](#-common/util.hpp 生成唯一文件名)
- [-common/uti.hpp 写入文件/读出文件](#-common/uti.hpp 写入文件/读出文件)
- [-compile_server/compile_run.hpp 编译运行整合模块(重要)](#-compile_server/compile_run.hpp 编译运行整合模块(重要))
- compiler_server网络服务
-
- 安装cpp-httplib第三方库以及升级GCC版本
- [-compile_server/compile_server.cpp 编译运行网络服务](#-compile_server/compile_server.cpp 编译运行网络服务)
前言
本篇记录负载均衡oj项目设计的整体思路和部分代码。
负载均衡oj项目基于http网络请求,通过简单的前后端交互:前端的页面编辑已经提交代码,后端控制模块和编译运行的模块分离整合(负载均衡式的选择后端编译运行服务),从而实现在线oj的正常使用。
使用语言:C/C++,使用环境:Linux centos7,gcc -v 9.3.1-2。
项目结果演示
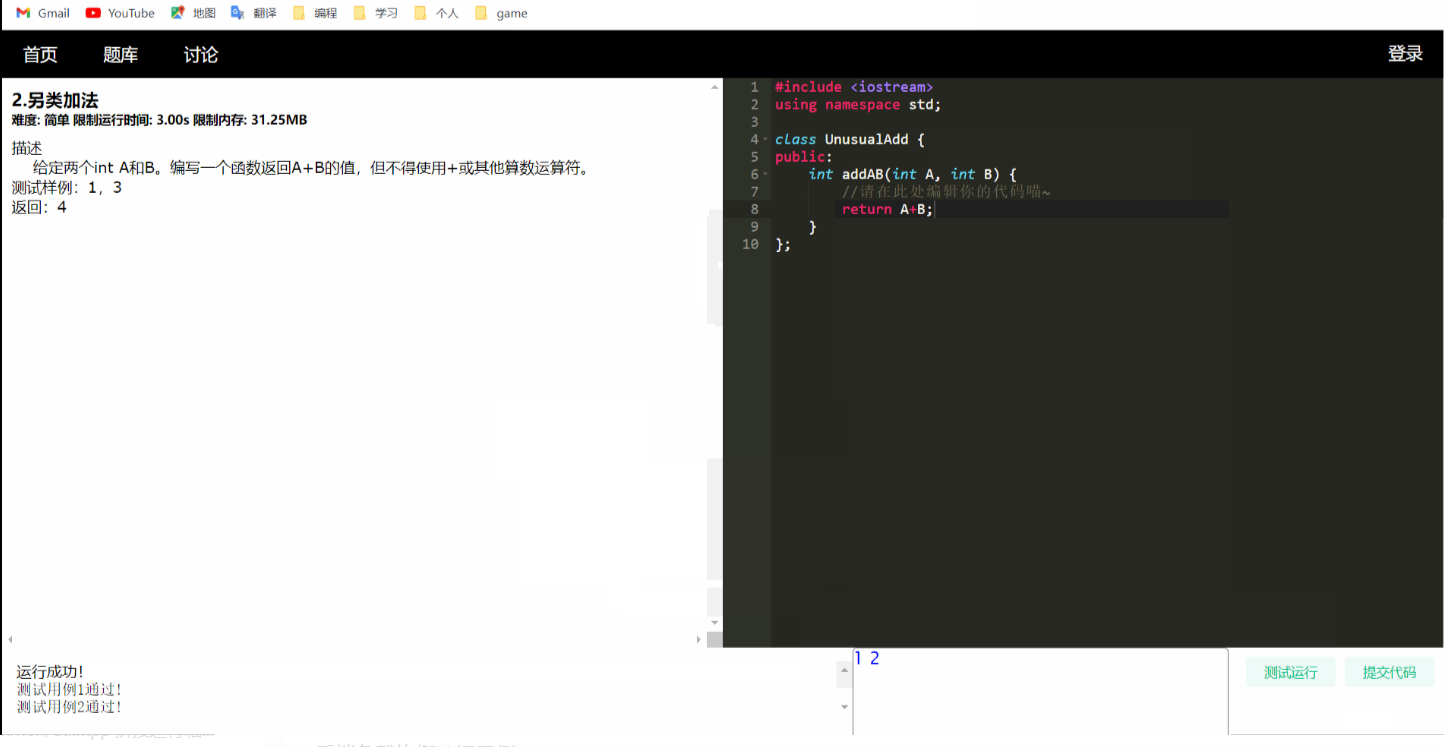
后端负载均衡选择示例:

技术栈:
对于负载均衡在线oj项目,我所使用的开发技术和环境如下:
技术如下:
1.C++STL (选择C++语言作为后端开发自然需要使用到里面的各种容器,比如string、vector)
2.cpp-h ttplib** (http应用层通信我们使用第三方库快速解决,如果编写套接字接收会很麻烦)
3.jsoncpp (网络通信时重要的一点就是将一个待发送的信息转换为json串进行发送。为了简单完成序列化和反序列化
4.Boost (C++准标准库内提供了一些好用的方法比如字符串切割spilt方法,能够快速帮助我们完成字符串切割为几个小块并且保存起来而不用自己编码实现)
5.MySQL C connect (当后端采用mysql数据库存储数据的时候,需要程序访问mysql数据库需要使用)
6.ctemplate (当想往网页html利用程序填充变量的时候,需要用到第三方渲染库,开源的前端渲染库)
7.ACE前端在线编辑器 (前端知识,让我们的oj代码编辑变得好看)
8.js/jquery/ajax (前端向后端发起http请求)
9.多进程多线程 (第三库中实现,本身代码没有体现)
10.负载均衡算法 (前端请求,后端根据编译服务主机的负载情况进行择少选择)
环境:Linux centos 7云服务器、vscode、Navicat。
结构与总体思路
我们对外提供的是在线OJ编译运行服务 。那么在线自然通过实现web服务器 在浏览器实现功能(利用前端制作网页,对应web服务器的路由实现功能),后端自然需要提供编译运行服务。
为了更加灵活的控制后端的编译运行服务,我们可以将后端编译运行服务也设置为网络服务,这样的化我们可以利用不同的主机部署编译运行服务,web服务器(在线OJ和前端交互的)后端可以负载均衡式 的选择主机。(这样的话在未来存在很多人使用的情况下就可以不用导致一台主机压力过大而被干掉)题目来源题库,只需要web服务器根据路由选择提供题目列表或者单个题目信息了,题库的话设计版本有文件版本 和mysql数据库版本。
这样的话我们的思路就被明确出来了。web服务器路由整合和前后端交互内容模块我们称之为oj_server模块,编译运行服务模块称为compiler_server模块。很明显,这就是一种bs模式(浏览器/服务器模式)。
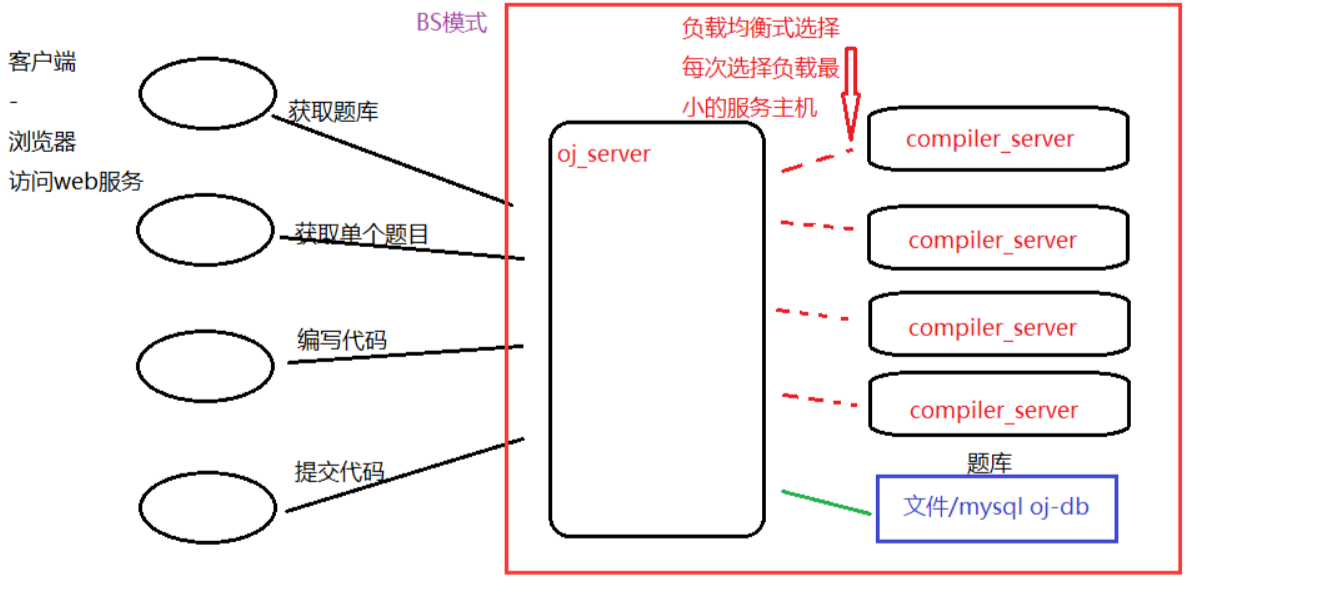
如上图,此项目就是设计红色区域内的内容。
针对此,我们在我们的项目目录结构上率先划分出三个区域出来:
1.oj服务 - oj_server(前端提供路由,前后端结合,后端提供功能,并且负载均衡选择后端)
2.编译运行服务 - compiler_server(后端提供编译运行功能)
3.公共模块 - common (上面两个模块共同使用的文件存放处)
下面我们针对不同的模块分开设计最后整合起来完成项目的编写。
1.compiler_server模块编写
编译运行服务。很明显,是存在两个步骤的:先编译,后运行。
在打包为网络服务之前,我们需要设计出编译功能和运行功能,然后在将两个功能整合起来。
compiler编译功能
一个C/C++程序源文件,需要经过gcc/g++工具进行预处理、编译、汇编、链接最终形成可执行文件。
平时,我们将一个源文件编译形成可执行文件只需要gcc/g++ -o... 一步到位即可。但是现在我们需要在程序中实现这个功能。难道我们要实现gcc/g++的功能?自然不是,需要用到操作系统接口:exec*进程替换。
但是,在执行程序替换时我们需要一些必要的需求。
首先是源文件的来源(之后由编译运行服务提供,负责将提供的code源码形成临时文件CPP提供编译服务),其次编译可能出现报错,报错的话gcc/g++程序时输出到stderr文件中的,那么需要我们进行重定向到错误文件中去,最后,因为需要返回编译结果,那么程序替换需要在子进程中进行,父进程等待后返回结果不受程序替换的影响。
所以,此模块的设计思路如下:
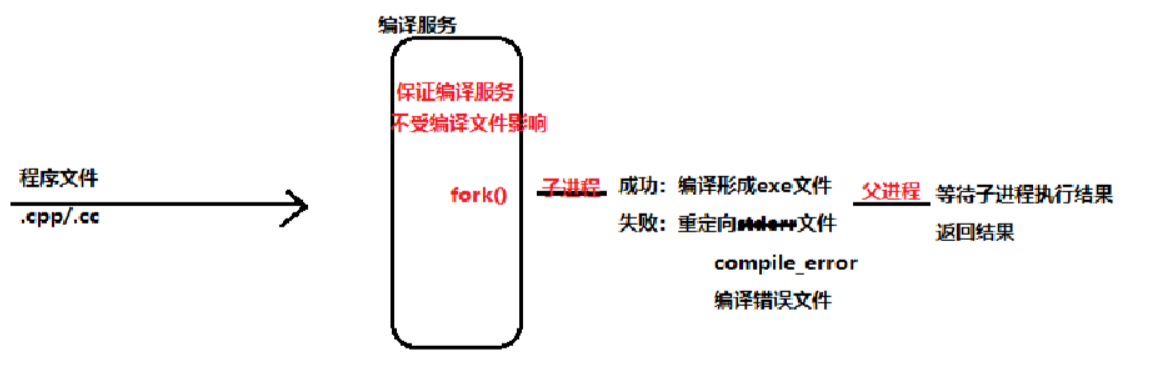
因为需要程序文件的路径。在项目设计中我们需要将编译运行服务所需要的临时文件都存放在一个temp目录下。那么每次变得就只是文件名。可以利用这个特点,在传给编译服务的时候只需要传文件名即可,拼接路径由common公共模块下的util.hpp提供路径拼接,与此同时,因为编码运行过程中难免存在差错,我们需要差错处理就需要一个简单的开放式日志功能,我们也可以存放在common下log.hpp。
拼接文件想一下,编译服务需要的临时文件存在三种:编译前的.cpp文件、编译后的.exe文件、错误重定向的compile_error文件(stderr-重定向)。
-common/util.hpp 拼接编译临时文件
拼接路径名我们写在类PathUtil中即可。
cpp
namespace ns_util
{
const std::string path = "./temp/";
// 合并路径类
class PathUtil
{
public:
// 拼接函数
static std::string splic(const std::string& str1, const std::string& str2)
{
std::string temp = path;
temp += str1;
temp += str2;
return temp;
}
// 编译临时文件
// 拼接源文件 文件名+cpp
static std::string Src(const std::string& file_name)
{
return splic(file_name, ".cpp");
}
// 拼接可执行文件 文件名+exe
static std::string Exe(const std::string& file_name)
{
return splic(file_name, ".exe");
}
// 拼接保存标准错误文件
static std::string CompileError(const std::string& file_name)
{
return splic(file_name, ".compile_error");
}
}
}-common/log.hpp 开放式日志
一个日志需要等级,时间,当前调日志的文件,行数,描述信息。显示我们利用屏幕显示即可,所以可以利用cout遇到'\n'刷新到屏幕上的策略编写日志文件。日志文件中只需要显示除开描述信息之外的信息即可。
为了方便外层文件调用,我们可以利用宏编写,减少参数的传递。
cpp
namespace ns_log
{
using namespace ns_util;
// 日志等级
enum{
INFO, // 正常
DEBUG, // 调试
WARING, // 警告
ERROR, // 错误
FATAL // 致命
};
// 开放式输出日志信息
inline std::ostream& Log(const std::string& level, const std::string& file_name, int line)
{
// #ifndef MYLOGDEBUG
// if (level == "DEBUG"){
// return std::cout << "\n";
// }
// #endif
std::string log;
// 添加日志等级
log += "[";
log += level;
log += "]";
// 添加输出日志文件名
log += "[";
log += file_name;
log += "]";
// 添加日志行号
log += "[";
log += std::to_string(line);
log += "]";
// 添加当前日志时间戳
log += "(";
log += TimeUtil::GetTimeStamp();
log += ") ";
std::cout << log; // 不使用endl进行刷新,利用缓冲区 开放式日志文件
return std::cout;
}
// 利用宏定义完善一点 - LOG(INFO) << "一切正常\n";
#define LOG(level) Log(#level, __FILE__, __LINE__)
}
#endif上面的获取时间利用的是时间戳,我们在util工具类中编写获取时间戳的代码即可。(利用操作系统接口:gettimeofday即可)
-common/util.hpp 获取时间戳方法-秒级
获取时间轴我们可以写入TimeUtil时间工具类中。
cpp
// 时间相关类
class TimeUtil
{
public:
static std::string GetTimeStamp()
{
// 使用系统调用gettimeofday
struct timeval t;
gettimeofday(&t, nullptr); // 获取时间戳的结构体、时区
return std::to_string(t.tv_sec);
}
}准备好这些工作后,就可以进行编译服务的编写了,根据传入的源程序文件名,首先创建子进程,子进程对stderr进行重定向到文件compile_error中,使用execlp(系统路径下找命令,可变参数传参)进行程序替换,父进程在外面等待子进程结果,等待成功后根据是否生成可执行程序决定是否编译成功。
是否生成可执行程序如何确定?可以利用stat系统接口进行查看,查看文件属性成功说明存在文件,否则就是不存在。我们将此小工具写入common/util.hpp中。
-common/util.hpp 文件是否存在
因为是和文件相关,我们可以放入FileUtil文件工具类中。
cpp
// 文件相关类
class FileUtil
{
public:
// 判断传入文件(完整路径)是否存在
static bool IsFileExist(const std::string& pathFile)
{
// 使用系统调用stat查看文件属性,查看成功说明存在文件,否则没有
struct stat st;
if (stat(pathFile.c_str(), &st) == 0)
{
// 说明存在文件
return true;
}
return false; // 否则不存在此文件
}
}现在就可以编写compile.hpp文件了,注意利用log文件进行差错处理。
-compile_server/compiler.hpp 编译功能编写(重要)
cpp
#ifndef __COMPILER_HPP__
#define __COMPILER_HPP__
// 编译模块
#include <iostream>
#include <string>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/wait.h>
#include "../common/util.hpp"
#include "../common/log.hpp"
namespace ns_compiler
{
using namespace ns_util;
using namespace ns_log;
class Compiler
{
public:
Compiler()
{}
~Compiler()
{}
// 编译函数 编译临时文件
// 输入:需要编译的临时文件名(存在./temp/文件名.cpp文件,不需要带cpp/cc后缀)
// 输出:编译成功true,false失败
static bool compile(std::string &file_name)
{
pid_t childPid = fork();
if (childPid < 0)
{
// 子进程创建失败
LOG(ERROR) << "内部错误,当前子进程无法创建" << "\n";
return false;
}
if (childPid == 0)
{
// 子进程
// 如果编译失败,需要将错误信息输入到错误文件内,利用重定向
umask(0); // 防止平台的影响,影响文件权限
int errFd = open(PathUtil::CompileError(file_name).c_str(), O_CREAT | O_WRONLY, 0644); // rw_r__r__
if (errFd < 0)
{
// 异常,终止程序
LOG(ERROR) << "内部错误,错误输出文件打开/创建失败" << "\n";
exit(1);
}
// 打开成功重定向
dup2(errFd, 2); // 将标准错误重新向到错误文件内,这样出错就可以将错误信息写入其中
execlp("g++", "g++", "-o", PathUtil::Exe(file_name).c_str(), PathUtil::Src(file_name).c_str(), "-D", "COMPILE_ONLINE", NULL); // p默认从环境变量下搜索
LOG(ERROR) << "g++执行失败,检查参数是否传递正确" << "\n";
exit(2); // 如果执行这一步说明上面的exec程序替换函数执行失败
}
// 父进程
waitpid(childPid, nullptr, 0); // 阻塞等待子进程
// 判断是否编译成功可以根据是否生成exe可执行文件进行判断
if (FileUtil::IsFileExist(PathUtil::Exe(file_name)))
{
// .exe文件存在
LOG(INFO) << "编译成功!" << "\n";
return true; // 编译成功
}
LOG(ERROR) << "编译失败!" << "\n";
return false; // exe文件不存在,编译失败
}
};
}
#endif这条 execlp 调用的作用是启动 g++ 编译器,编译指定的源文件,并生成目标可执行文件。具体来说:
"g++"
这是传递给 g++ 的第一个参数,通常是程序名本身。在 execlp 中,第一个参数和第二个参数通常是相同的,表示要执行的程序名。
"-o"
这是 g++ 的一个选项,表示指定输出文件的名称。-o 后面需要跟一个文件名,表示生成的可执行文件的名称。
"-D"
这是 g++ 的一个选项,用于定义预处理器宏。-D 后面可以跟一个宏定义,例如 -DDEBUG 或 -DNAME=value。
编译器:g++
输出文件:PathUtil::Exe(file_name).c_str() 指定的路径
输入文件:PathUtil::Src(file_name).c_str() 指定的路径
定义的宏:COMPILE_ONLINE
如果 execlp 调用成功,当前进程会被替换为 g++ 编译器进程,并开始执行编译操作。如果调用失败,程序会继续执行 LOG(ERROR) 和 exit(2)。
execlp 是一个系统调用,用于在当前进程中启动一个新的程序。它会用指定的程序替换当前进程的映像。execlp 的原型如下:
cpp
int execlp(const char *file, const char *arg, ...);file 是要执行的程序的文件名。
arg 是传递给程序的第一个参数(通常是程序名本身)。
后续的参数是传递给程序的其他参数。
最后一个参数必须是 NULL,表示参数列表的结束。
runner运行功能
运行模块很简单,只需要一个可执行程序即可,还是利用exec*程序替换进行执行即可。
只不过,运行的话就分为运行成功和运行失败。存在运行成功但是结果不正确的原因,但这不是运行功能处理的事情,运行模块只需要关心是否运行成功,运行出错比如段错误、空指针引用等。
除此之外,我们需要想到程序运行的时候默认打开的三个文件:stdin、stdout、stderr。需要进行重定向,这也就是运行模块需要的临时文件(PathUtil需要编写)。其中stdin就是未来上层传来的用户测试用例,stdout就是运行成功后输出结果,stderr就是运行失败后的输出结果。
因为存在各种函数以及打开文件,那么可能出现内部错误(非程序运行报错),所以在返回上层结果的时候,我们需要规定值表示不同的错误类别。为了保持运行出错所返回的信号中断,我们可以设置>0就是运行报错(直接返回运行返回值即可),<0设置为内部错误(比如打开文件失败),等于0就是运行成功。
所以,此模块的设计思路如下:

另外,程序运行时为了防止破坏计算机的事情(比如申请过大内存、很长时间浪费编译服务资源)也或者一些编程的限制空间和资源。我们需要对运行程序进行资源限制。资源限制可以利用系统接口setrlimit进行,分别根据传入的时间和空间进行约束。
我们直到,当OS终止程序的时候,都是通过信号进行终止的。而此资源限制限制的内存就是6号信号,cpu的执行时间限制就是24号信号。可以利用signal函数捕捉验证一下。(当然也可以查看返回值)
-common/util.hpp 拼接运行临时文件
和拼接编译运行文件一样,同样放在PathUtil工具类中。
cpp
// 运行临时文件
// 拼接保存标准输入文件
static std::string Stdin(const std::string& file_name)
{
return splic(file_name, ".stdin");
}
// 拼接保存标准输出文件
static std::string Stdout(const std::string& file_name)
{
return splic(file_name, ".stdout");
}
// 拼接保存标准错误文件
static std::string Stderr(const std::string& file_name)
{
return splic(file_name, ".stderr");
}-compile_server/runner.hpp 运行功能编写
同理,我们还是需要创建子进程进行程序替换,父进程阻塞等待获取子进程结果从而返回结果。需要注意资源限制函数,我们根据接口传入的参数在子进程的环境下进行限制运行即可。
cpp
#ifndef __RUNNER_HPP__
#define __RUNNER_HPP__
// 运行模块
#include <string>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/time.h>
#include <sys/resource.h>
#include "../common/util.hpp"
#include "../common/log.hpp"
namespace ns_runner
{
using namespace ns_util;
using namespace ns_log;
class Runner
{
public:
Runner() {}
~Runner() {}
public:
// 资源限制接口
// cpu_limit时间限制s men_limit空间限制KB
static void SetProCLimit(int cpu_limit, int mem_limit)
{
// 时间限制
struct rlimit cpuLimit;
//rlimit 是一个结构体,用于描述资源限制。
cpuLimit.rlim_max = RLIM_INFINITY;
//rlim_max 是最大限制值,这里设置为无穷大(RLIM_INFINITY)。
cpuLimit.rlim_cur = cpu_limit;
//rlim_cur 是当前限制值,这里设置为传入的 cpu_limit 参数(单位为秒)。
setrlimit(RLIMIT_CPU, &cpuLimit);
//setrlimit(RLIMIT_CPU, &cpuLimit) 调用系统调用 setrlimit,设置CPU时间限制。
// 空间限制
struct rlimit memLimit;
//同样使用 rlimit 结构体,设置内存空间限制。
memLimit.rlim_max = RLIM_INFINITY;
memLimit.rlim_cur = mem_limit * 1024; // byte->kb
//mem_limit 的单位是KB,因此乘以1024转换为字节。
setrlimit(RLIMIT_AS, &memLimit);
//RLIMIT_AS 表示地址空间限制,这里设置为传入的 mem_limit 参数。
}
// 运行模块
// 输入可执行文件名 在temp目录下的.exe文件
// 返回值:0表示运行成功、<0表示内部错误,>0表示运行出错
// 时间限制:cpu_limit 空间限制:men_limit
// 返回值: <0 内部错误 =0运行成功,成功写入stdout等文件 >0运行中断,用户代码存在问题
//定义了一个静态方法 Run,用于运行指定的可执行文件,并设置资源限制。
static int Run(const std::string& file_name, int cpu_limit, int mem_limit)
{
// 在父进程中先将运行所需要的三个临时文件打开
//使用 open 系统调用打开三个文件:
//标准输入文件(stdin):以只读方式打开。
//标准输出文件(stdout):以写入方式打开。
//标准错误文件(stderr):以写入方式打开。
//PathUtil::Stdin(file_name) 等函数是工具函数,用于生成文件路径。
int _stdin = open(PathUtil::Stdin(file_name).c_str(), O_CREAT | O_RDONLY, 0644);
int _stdout = open(PathUtil::Stdout(file_name).c_str(), O_CREAT | O_WRONLY, 0644);
int _stderr = open(PathUtil::Stderr(file_name).c_str(), O_CREAT | O_WRONLY, 0644);
// 打开文件进行差错处理
if (_stdin < 0 || _stdout < 0 || _stderr < 0)
{
// 文件打不开运行程序没有意义了
LOG(ERROR) << "内部错误, 标准文件打开/创建失败" << "\n";
return -1;
}
//使用 fork 创建一个子进程。
pid_t childPid = fork();
if (childPid < 0)
{
// 创建子进程失败
// 创建失败,打开的文件需要收回-否则占用无效资源!
close(_stdin);
close(_stdout);
close(_stderr);
LOG(ERROR) << "内部错误, 创建子进程失败" << "\n";
return -2;
}
if (childPid == 0)//如果当前是子进程:
{
// 子进程
// 资源限制
SetProCLimit(cpu_limit, mem_limit);//调用 SetProCLimit 设置资源限制。
//使用 dup2 将 _stdin、_stdout 和 _stderr 分别重定向到文件描述符 0、1 和 2。
dup2(_stdin, 0);
dup2(_stdout, 1);
dup2(_stderr, 2);
//使用 execl 执行可执行文件。如果执行失败,调用 exit(-1) 退出。
execl(PathUtil::Exe(file_name).c_str(), PathUtil::Exe(file_name).c_str(), nullptr); // execl函数,不从环境变量下找,直接根据路径找可执行文件 路径、可执行文件
exit(-1); // 程序替换出错
}
// 父进程
close(_stdin);
close(_stdout);
close(_stderr);
//父进程等待子进程,查看返回情况
int status; //输出参数,接收状态信息
waitpid(childPid, &status, 0); // 阻塞等待
if (status < 0)
{
//信号不等于0说明执行失败
LOG(ERROR) << "内部错误, execl参数或者路径不正确" << status << "\n";
return status;
}
else LOG(INFO) << "运行完毕!退出码为: " << (status & 0x7F)<< "\n";
return (status & 0x7F);
}
};
}
#endif这段代码实现了一个简单的进程运行器,能够运行指定的可执行文件,并限制其CPU时间和内存空间。它还记录运行过程中的日志信息,方便调试和监控。
compile_run编译运行
上面将编译和运行模块分开了,正常流程则是先编译后运行。那么我们需要将这两个流程整合起来实现编译运行模块的后端工作。
想要编译,那么我们就需要源文件,源文件从哪里来?用户通过网络发送而来。所以用户发送过来就是前端序列化后的json串,反序列化后得到的数据写入源文件中,交给编译功能编译后形成可执行文件然后交给运行功能运行,最后整合结果也向对方返回结果json串完成工作。
那么,上面的四个步骤就是compile_run编译运行需要执行的步骤:
首先是前端序列化后的json串,我们需要规定其返回什么。一份源文件自然需要一份完整的代码,如果用户输入的话还需要用户的input数据。另外每个程序都需要对应的时间和空间限制。综上,用户返回的json串格式如下:
cpp
{
"code": code,
"input": input,
"cpu_limit": S,
"mem_limit": kb
}(需要注意CPP实验json库在linux下需要sudo yum install jsoncpp-devel安装json开发库,并且在编译选项中加上-ljsoncpp方可编译)
反序列化得到数据后,我们需要将code部分写入.cpp源文件中去。 写入文件很简单(利用C++的ofstream简单IO即可),但是需要注意,之后此模块的功能是被打包为网络服务的。也就是说可能同时出现了很多用户提交的代码。如果此时名字冲突就会发生问题,不同用户之间执行的不同题或者编程内容就会出现问题。
所以当一份用户提交代码后,我们为其生成的源文件名需要具有唯一性 。名字生成唯一性我们可以利用毫秒级时间戳加上原子性的增长计数实现。
毫秒级时间戳可以利用gettimeofday函数调用实现(返回的结构体存在微秒级的属性,简单转换就可以得到微秒),原子性的增长计数(同一时刻不同执行流调用-利用static的变量)利用C++11的特性atomic_uint即可实现。
-common/util.hpp 生成唯一文件名
获取毫秒时间戳在TimeUtill工具类中,生成唯一文件名在FileUtil工具类中。
cpp
// 获取毫秒级时间戳
static std::string GetTimeMs()
{
struct timeval t;
gettimeofday(&t, nullptr);
return std::to_string((t.tv_sec * 1000 + t.tv_usec / 1000)); // 秒+微秒
}
//......
// 生成唯一的文件名
// 利用微秒时间戳和原子性的唯一增长数字组成
static std::string UniqueFileName()
{
// 利用C++11的特性,生成一个原子性的计数器
static std::atomic_uint id(0);//定义一个静态的原子变量 id,初始值为 0。
//std::atomic_uint 是 C++11 提供的原子类型,用于确保对变量的访问和操作是线程安全的。
id++;
std::string ms = TimeUtil::GetTimeMs();
return ms + "-" + std::to_string(id);
}1.获取毫秒级时间戳解析:
struct timeval t;
定义一个 timeval 结构体变量 t,用于存储时间信息。timeval 结构体包含两个字段:
tv_sec :表示秒数。
tv_usec :表示微秒数(0 到 999999)。
gettimeofday(&t, nullptr);
调用 gettimeofday 函数,获取当前时间并存储到 t 中。
gettimeofday 的第一个参数 是一个指向 timeval 的指针,第二个参数 是一个指向 timezone 的指针(这里传入 nullptr,表示不获取时区信息)。
return std::to_string((t.tv_sec * 1000 + t.tv_usec / 1000));
计算当前时间的毫秒级时间戳:
t.tv_sec * 1000 :将秒数转换为毫秒。
t.tv_usec / 1000 :将微秒数转换为毫秒。
两者相加得到当前时间的毫秒级时间戳。
使用 std::to_string 将结果转换为字符串并返回。
2.生成唯一的文件名:
id++;
原子性地将 id 的值加 1。每次调用 UniqueFileName 时,id 都会递增,从而保证生成的文件名是唯一的。
std::string ms = TimeUtil::GetTimeMs();
调用 GetTimeMs 函数获取当前的毫秒级时间戳,并将其存储到字符串变量 ms 中。
return ms + "-" + std::to_string(id);
将毫秒级时间戳 ms 和原子变量 id 的值拼接起来,中间用连字符 - 分隔。
返回拼接后的字符串,作为唯一的文件名。
-common/uti.hpp 写入文件/读出文件
现在能够生成唯一文件名后,我们可以根据此路径写入文件中。为了方便,我们一并将写入文件和读取文件写入util工具类中,方便项目文件进行调用。利用的就是C++的fstream类。
因为是和文件相关,所以也放入FileUtil工具类中。
cpp
// 根据路径文件进行写入
static bool WriteFile(const std::string& path_file, const std::string& content)
{
// 利用C++的文件流进行简单的操作
std::ofstream out(path_file);
// 判断此文件是否存在
if (!out.is_open()) return false;
out.write(content.c_str(), content.size());
out.close();
return true;
}
// 根据路径文件进行读出
// 注意,默认每行的\\n是不进行保存的,需要保存请设置参数
static std::string ReadFile(const std::string& path_file, bool keep = false)
{
// 利用C++的文件流进行简单的操作
std::string content, line;
std::ifstream in(path_file);
if (!in.is_open()) return "";
while (std::getline(in, line))
{
content += line;
if (keep) content += "\n";
}
in.close();
return content;
}现在已经能够生成唯一名字的源文件了,我们利用此源文件执行编译运行流程,最终将结果返回给用户。需要注意,这个过程中仍然出现很多差错,我们类似运行模块那样,首先将错误分为几类,最后将这些转换为描述发送出去。
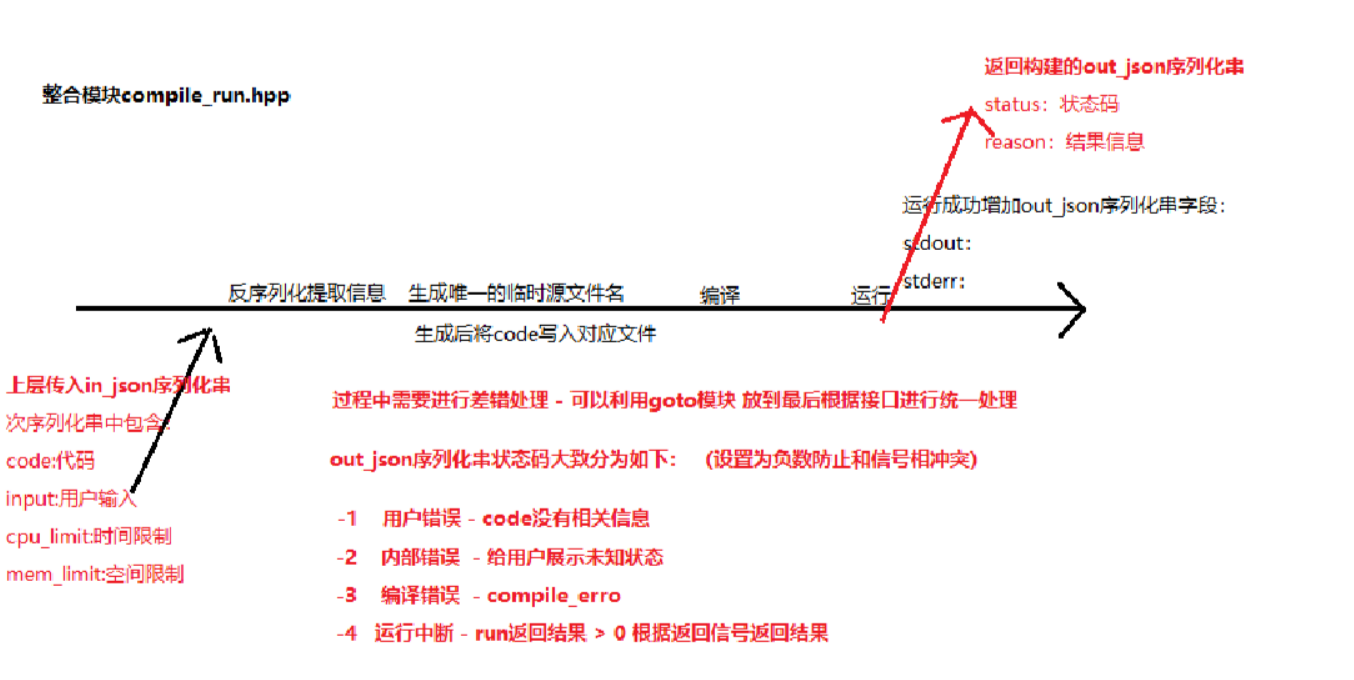
因为运行报错会返回>0的数(对应信号),所以其余错误我们均定为负数,方便后续的错误描述。首先,一开始用户发送给我们的code可能为空,为空的话就没有继续执行下去的必要了,可以定义用户错误。此外可能打开文件失败,写入文件失败,以及运行模块返回<0都是内部的错误,对外应该显示为未知错误,之后编译错误、正常返回即可。
状态码和状态描述我们可以将其返回回去。另外,如果运行成功我们还需要将运行生成的stdout和stderr文件返回回去。所以,返回结果完整的json串如下:
cpp
{
"status": status,
"reason": reason,
"stdout": stdout,
"stderr": stderr
}对于状态码描述我们可以单独写一个函数进行整合选择,写入json串中。另外因为每次编译运行会产生很多的临时文件(temp/),当这一切执行完后临时文件就没有意义了,就需要进行清理。删除文件可以利用unlink接口进行删除,需要注意其文件是否存在。
综上,思路我们可以整理为如下图:
-compile_server/compile_run.hpp 编译运行整合模块(重要)
cpp
#ifndef __COMPILE_RUN_HPP__
#define __COMPILE_RUN_HPP__
// 编译运行整合模块
#include <unistd.h>
#include <jsoncpp/json/json.h>
#include "compiler.hpp"
#include "runner.hpp"
#include "../common/util.hpp"
#include "../common/log.hpp"
namespace ns_compile_and_run
{
using namespace ns_compiler;
using namespace ns_runner;
using namespace ns_log;
using namespace ns_util;
class CompileAndRun
{
public:
// 删除与指定文件名相关的临时文件
static void RemoveFile(const std::string& file_name)
{
// 因为临时文件的存在情况存在多种,删除文件采用系统接口unlink,但是需要判断
std::string src_path = PathUtil::Src(file_name);
//使用 PathUtil::Src(file_name) 获取源代码文件路径。
if (FileUtil::IsFileExist(src_path)) unlink(src_path.c_str());
//使用 FileUtil::IsFileExist 检查文件是否存在。
//如果文件存在,调用 unlink 删除文件。
//类似地,代码依次删除了标准输出文件、标准输入文件、标准错误文件、编译错误文件和可执行文件。
std::string stdout_path = PathUtil::Stdout(file_name);
if (FileUtil::IsFileExist(stdout_path)) unlink(stdout_path.c_str());
std::string stdin_path = PathUtil::Stdin(file_name);
if (FileUtil::IsFileExist(stdin_path)) unlink(stdin_path.c_str());
std::string stderr_path = PathUtil::Stderr(file_name);
if (FileUtil::IsFileExist(stderr_path)) unlink(stderr_path.c_str());
std::string compilererr_path = PathUtil::CompileError(file_name);
if (FileUtil::IsFileExist(compilererr_path)) unlink(compilererr_path.c_str());
std::string exe_path = PathUtil::Exe(file_name);
if (FileUtil::IsFileExist(exe_path)) unlink(exe_path.c_str());
}
// 根据不同的状态码进行解析结果输入信息
// > 0 运行中断 6-内存超过范围、24-cpu使用时间超时、8-浮点数溢出(除0异常)
// = 0 运行成功
// < 0 整个过程,非运行报错(内部错误、编译报错、代码为空)
static std::string CodeToDesc(int status, const std::string& file_name)
{
std::string desc;
switch(status)
{
case 0:
desc = "运行成功!";
break;
case -1:
desc = "代码为空";
break;
case -2:
desc = "未知错误";
break;
case -3:
desc = "编译报错\n";
desc += FileUtil::ReadFile(PathUtil::CompileError(file_name), true);
//对于某些状态码(如 -3 编译报错),还会读取编译错误文件的内容并附加到描述信息中。
break;
case 6:
desc = "内存超过范围";
break;
case 24:
desc = "时间超时";
break;
case 8:
desc = "浮点数溢出";
break;
case 11:
desc = "野指针错误";
break;
default:
desc = "未处理的报错-status为:" + std::to_string(status);
break;
}
return desc;
}
/***********************
* 编译运行模块
* 输入:in_json输入序列化串 *out_json 输出序列化串(输出参数)
* 输出
* in_json {"code":..., "input":..., "cpu_limit":..., "mem_limit":...}
* out_json {"status":..., "reason":...[, "stdout":..., "stderr":...]}
***********************/
static void Start(const std::string& in_json, std::string* out_json)
{
std::string code, input, file_name;
int cpu_limit, mem_limit; // s, kb
int status, run_reason; // 状态码, 运行返回码
// 首先反序列化in_json,提取信息
Json::Value in_value;
Json::Reader read;
read.parse(in_json, in_value); // 序列化可能出问题
//使用 Json::Reader 将输入的JSON字符串解析为 Json::Value 对象。如果解析失败,可能会导致后续逻辑出错。
code = in_value["code"].asString();
input = in_value["input"].asString();
cpu_limit = in_value["cpu_limit"].asInt();
mem_limit = in_value["mem_limit"].asInt();
//从 Json::Value 对象中提取代码、输入数据、CPU限制和内存限制等信息。
// 首先检测code是否存在数据-如果代码为空,设置状态码为 -1 并跳转到结束标签 END。
if(code.empty())
{
status = -1; // 用户错误
goto END;
}
// 首先生成唯一的临时文件名
file_name = FileUtil::UniqueFileName();
// code写入文件
if(!FileUtil::WriteFile(PathUtil::Src(file_name), code))
{
// 如果写入失败,内部报错
status = -2;
goto END;
}
// 写入文件成功的话,我们进行编译步骤
if (!Compiler::compile(file_name))
{
status = -3; // 编译失败,导入结果compile_error
goto END;
}
// 将input标准输入写入文件
if(!FileUtil::WriteFile(PathUtil::Stdin(file_name), input))
{
// 如果写入失败,内部报错
status = -2;
goto END;
}
// 编译步骤成功,我们进行运行步骤
run_reason = Runner::Run(file_name, cpu_limit, mem_limit);
if (run_reason < 0)
{
// 内部错误
status = -2;
}
else
{
// 运行成功或者中断
status = run_reason;
}
END:
// 构建返回序列化串
//使用 Json::Value 构建输出JSON对象。
//添加状态码和原因描述字段。
Json::Value out_value;
out_value["status"] = status;
out_value["reason"] = CodeToDesc(status, file_name); // 需要接口
// 如果运行成功,那么构建可选字段
//如果运行成功,读取标准输出和标准错误文件的内容,并添加到输出JSON对象中。
if (status == 0)
{
out_value["stdout"] = FileUtil::ReadFile(PathUtil::Stdout(file_name), true);
out_value["stderr"] = FileUtil::ReadFile(PathUtil::Stderr(file_name), true);
}
//使用 Json::StyledWriter 将输出JSON对象序列化为字符串,并存储到 out_json 指针指向的变量中。
Json::StyledWriter write;
*out_json = write.write(out_value);
//调用 RemoveFile 方法删除所有临时文件。
RemoveFile(file_name);
}
};
}
#endif这段代码实现了一个完整的编译和运行流程,包括:
1.解析输入JSON,提取代码、输入数据、资源限制等信息。
2.将代码写入文件并进行编译。
3.如果编译成功,运行生成的可执行文件,并根据运行结果设置状态码。
4.构建输出JSON,包含运行状态、原因描述以及运行结果(如果成功)。
5.删除所有临时文件,清理资源。
6.通过这种方式,代码能够高效地处理编译和运行任务,并提供详细的运行结果和错误信息。
compiler_server网络服务
现在已经有了编译服务这个模块了,只需要打包成网络服务就可以完成我们的目的了。
首先,自然可以写套接字实现http网络服务,服务器端绑定ip、端口,因为http是基于TCP的,所以需要设置监听。最后利用多进程、多线程或者epoll高级IO模式(epoll)获取每一个链接,接收json串(应用层处理数据粘包或者不全的问题),然后传递给编译运行模块执行结果后再通过http发送json串完成一次网络通信。
首先可行,但是在项目中这么写太多太麻烦了。就像我们利用C++的STL库一样,如果这套http网络服务我们能直接使用就减轻了网络服务编写的负担了。由于C++官方本身没有提供网络库的相关库,但是我们可以利用cpp-http第三方库进行使用,方便我们的网络服务的创建。
安装cpp-httplib第三方库以及升级GCC版本
在gitee搜索cpp-httplib 0.7.15版本,标签进行查找版本。(点此链接直接访问:cpp-httplib: cpp-httplib - Gitee.com)
下载上传后,找到httplib.h文件拷贝到common目录下即可。
但是编译cpp-httplib需要更高版本的GCC,我们需要进行升级。
cpp
// 安装scl
sudo yum install centos-release-scl scl-utils-build
// 安装新版本GCC
sudo yum install -y devtoolset-9-gcc devtoolset-9-gcc-c++
ls /opt/rh
// 启动 只有本次会话有效
scl enable devtoolset-9 bash
gcc -v
// 可选,每次登录都是较新的GCC,添加到~/.bash_profile中 自己的家目录
scl enable devtoolset-9 bash
注意:升级到789都可以,换版本只需要将上面的数字进行替换即可。另外,httplib是一个阻塞式多线程原生库,需要引入原生线程库 -lpthread;
现在我们可以利用httplib库将compile_run打包为一个网络编译运行服务。
httplib存在Server服务器对象,其中存在Post和Get方法分别对应客户端向服务器发送请求报文中请求首行的执行方法。其中Get可以时获取资源,Post则是提交资源...
我们利用此方法,根据两个(一个const属性的请求Request,另一个输出型的Response)参数的函数对象,进行返回结果(构建Response的正文和响应报头)。对方提交json串的时候自然使用是Post方法,利用其获取json(请求正文),调用编译运行服务构建响应json,再写入响应报文中(类型 + 正文),完成compile_run路由设置,最后绑定ip(0.0.0.0),端口(需要设置命令行参数,端口不可定死,并且后续存在编译服务器的配置文件,为上层oj_server灵活的提供主机选择)从命令行参数设置,cpp-httplib使用listen方法执行即可。
-compile_server/compile_server.cpp 编译运行网络服务
这段代码实现了一个简单的HTTP服务器,提供以下功能:
- 通过 /hello 路径返回一条欢迎信息。
- 通过 /compile_and_run 路径接收POST请求,处理JSON格式的编译和运行请求。
- 使用 CompileAndRun 类执行编译和运行操作,并返回结果。
- 通过命令行参数指定服务器的监听端口。
通过这种方式,代码将编译和运行功能封装为一个网络服务,便于与其他系统集成。
cpp
#include "compile_run.hpp"
//包含了 compile_run.hpp,这是之前定义的编译和运行模块的头文件。
#include "../common/httplib.h"
//包含了 httplib.h,这是用于创建HTTP服务器的库。
using namespace ns_compile_and_run;
using namespace httplib;
//定义了一个函数 User,用于打印程序的使用说明。它提示用户程序需要一个端口号作为参数。
void User(char * use)
{
std::cout << "User:" << "\n\t";
std::cout << use << " port" << std::endl;
}
int main(int argc, char* argv[])
{
if (argc != 2)
{
// 满足传递 ./ port
User(argv[0]);
return 1;
}
// 将我们的编译运行服务打包为网络服务 - 为负载均衡做准备
//创建了一个 Server 对象 svr,用于处理HTTP请求。
//注册了一个GET请求处理器,当访问 /hello 路径时,返回一条欢迎信息。
//使用 resp.set_content 设置响应的内容和内容类型。
Server svr;
svr.Get("/hello", [](const Request& req, Response& resp){
resp.set_content("你好呀,这里是编译运行服务,访问服务请访问资源/compile_and_run", "text/plain;charset=utf-8");
}); // 请求资源
//注册了一个POST请求处理器,当访问 /compile_and_run 路径时,处理编译和运行请求。
svr.Post("/compile_and_run", [](const Request& req, Response& resp){
// 首先提取用户提交的json串
std::string in_json = req.body;
std::string out_json;
// 判断json串是空的吗?空的拒绝服务
//如果 in_json 不为空,调用 CompileAndRun::Start 方法执行编译和运行操作,并将结果存储到 out_json 中。
if(!in_json.empty())
CompileAndRun::Start(in_json, &out_json);
// 返回out_json串给客户端
//使用 resp.set_content 设置响应的内容为 out_json,并指定内容类型为 application/json
resp.set_content(out_json, "application/json;charset=utf-8");
}); // 提交json串,返回json串
// 注册运行
//调用 svr.listen 方法启动服务器,监听所有网络接口(0.0.0.0)。
//使用 atoi(argv[1]) 将命令行参数中的端口号转换为整数。
svr.listen("0.0.0.0", atoi(argv[1]));
return 0;
}注意响应正文对应的响应报头中写的类型(ConnectType)可以参考此网站进行对照:HTTP 响应类型 ContentType 对照表 - 爱码网