视频教程:
一个强大的语音分离和降噪软件
SoloSpeech 是由约翰霍普金斯大学、香港中文大学、南洋理工大学、清华大学及布拉格理工大学等多所高校共同主导开源的一个创新的语音处理项目,旨在解决在多人同时说话的环境中,准确提取并清晰呈现特定说话者声音的问题。该项目通过构建一个级联生成式管道(cascaded generative pipeline),实现了对混合语音信号的高效处理,提升了目标语音的清晰度和质量。
SoloSpeech 的核心用途是目标语音提取(Target Speech Extraction, TSE),即从包含多个说话者声音的混合音频中,分离并提取出特定说话者的声音。这一技术可以广泛应用于各种需要清晰分离和识别特定声音的场景,如语音识别系统、会议记录、语音识别训练数据预处理等。
SoloSpeech功能特点
提高语音识别的准确性:通过分离目标语音,减少背景噪音和其他说话者的干扰,从而提高语音识别的准确率。
改善会议记录体验:在多人参加的会议中,可以提取出每个发言人的声音,方便后续整理和回顾。
优化语音训练数据:在语音识别或语音合成模型的训练过程中,可以使用SoloSpeech来处理嘈杂或混合的语音数据,提高模型的训练效率和性能。
SoloSpeech的应用领域
智能语音识别:在智能家居、车载语音助手等智能设备中,通过提取目标语音,实现更精准的语音控制。
远程会议与协作:在远程会议软件中,利用SoloSpeech技术,可以清晰地听到每个参会者的发言,提升会议效率。
教育领域:在教育视频中,可以提取出教师的声音,帮助学生更好地理解和记忆知识。
音频编辑与后期制作:在音频制作过程中,使用SoloSpeech可以快速分离和提取出需要的声音元素,提高制作效率和质量。
使用教程: (建议N卡,显存12G起。基于CUDA12.1)
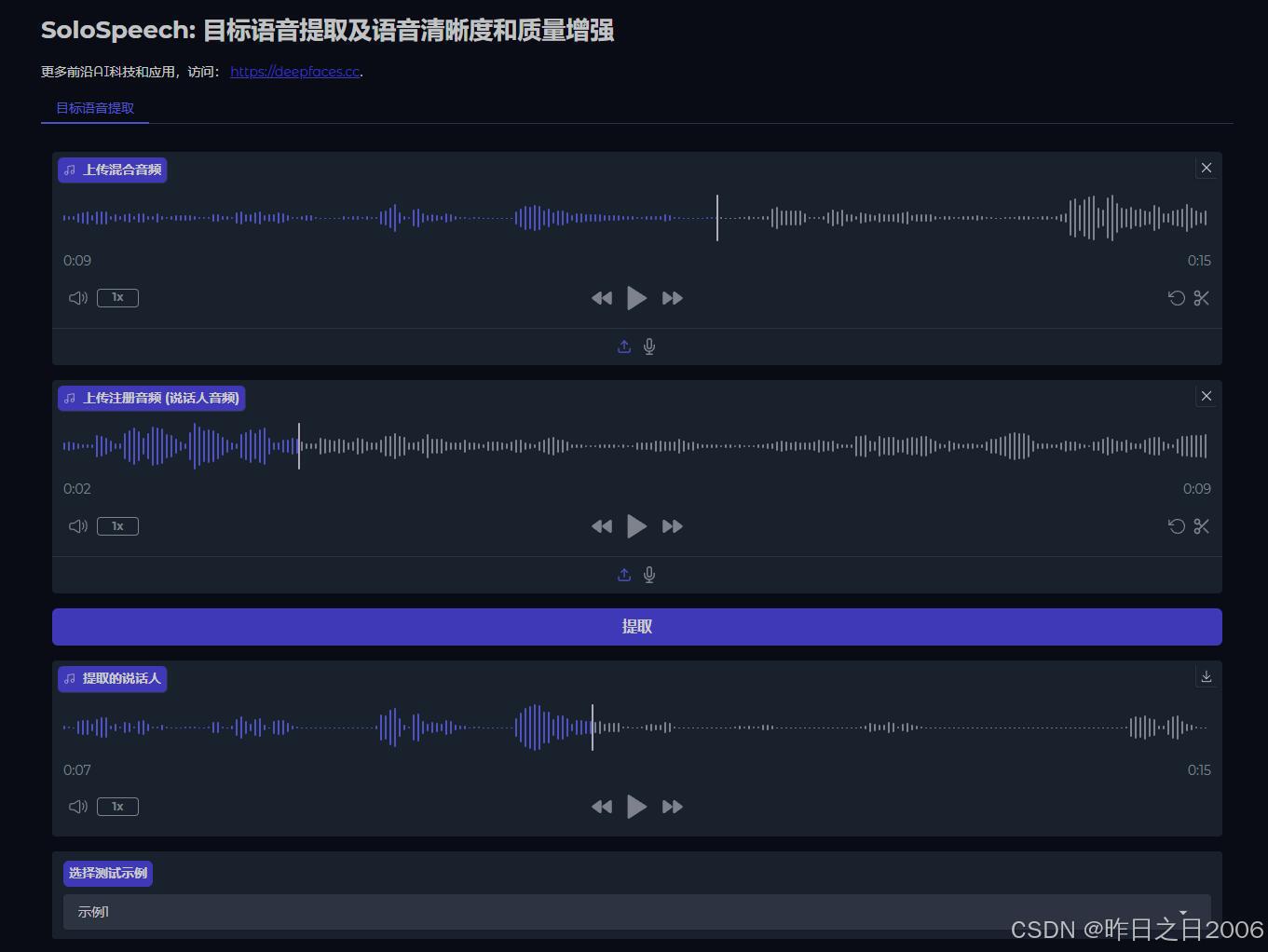
上传一段需要提取的多人说话人音频,再上传一段需要提取的说话人音频,提取即可。
比如先上传一段音频中包含A和B两个说话人,再上传一段只有A说话的音频,即可从A和B说话的音频中精准提取A说话的纯净高质量音频。
音频降噪教程:软件同样支持一键音频降噪,混合音频和说话人音频分别上传需要降噪的音频,也就是都上传需要降噪的音频,提取即可。
测试下来,这个降噪效果非常棒,音质几乎没有损失。比之前分享的 ClearerVoice降噪效果都要好。