目录
[1 问题背景:重启后设置失效](#1 问题背景:重启后设置失效)
[2 核心概念解析](#2 核心概念解析)
[2.1 什么是分片(Shard)?](#2.1 什么是分片(Shard)?)
[2.2 cluster.max_shards_per_node的作用](#2.2 cluster.max_shards_per_node的作用)
[2.3 默认值是多少?](#2.3 默认值是多少?)
[3 参数设置的两种方式](#3 参数设置的两种方式)
[3.2 持久性设置(persistent)](#3.2 持久性设置(persistent))
[3.2 临时设置(transient)](#3.2 临时设置(transient))
[4 问题解决方案](#4 问题解决方案)
[5 深入理解设置存储机制](#5 深入理解设置存储机制)
[6 生产环境最佳实践](#6 生产环境最佳实践)
[7 常见问题解答](#7 常见问题解答)
[8 总结](#8 总结)
前言
作为Elasticsearch运维人员,我们经常需要调整集群参数以适应业务需求。其中cluster.max_shards_per_node是一个关键配置,它控制着每个节点可以承载的最大分片数量。本文将深入探讨这个参数的设置方式、持久性问题以及最佳实践,特别是解决" 设置后集群重启恢复默认值"的问题。
1 问题背景:重启后设置失效
最近有用户反馈了一个典型问题:
"通过curl命令行方式成功设置了cluster.max_shards_per_node参数,但是当集群重启后,这个值又恢复成了默认值,这是为什么?"
# 用户使用的设置命令
curl -X PUT "192.168.10.33:9200/_cluster/settings" -H "Content-Type: application/json" -d'
{
"transient": {
"cluster.max_shards_per_node": 8000
}
}
'这个问题实际上涉及Elasticsearch集群设置的持久性机制,让我们先了解一些基础概念。
2 核心概念解析
2.1 什么是分片(Shard)?
分片是Elasticsearch中数据存储的基本单元,每个索引由一个或多个分片组成。分片分为:
- 主分片(Primary Shard):负责数据写入和读取
- 副本分片(Replica Shard):提供高可用和读取负载均衡
2.2 cluster.max_shards_per_node 的作用
这个参数限制单个数据节点可以承载的分片总数(主分片+副本分片),主要作用包括:
- 防止单个节点过载
- 平衡集群资源使用
- 避免分片过多导致的性能下降
2.3 默认值是多少?
不同版本默认值可能不同:
- Elasticsearch 6.x及之前:无硬性限制
- Elasticsearch 7.0+:默认1000
-
可以通过API查询当前默认值:
curl -X GET "192.168.10.33:9200/_cluster/settings?include_defaults=true&pretty" | grep max_shards_per_node
3 参数设置的两种方式
- Elasticsearch提供了两种设置集群参数的方式,它们的持久性完全不同:
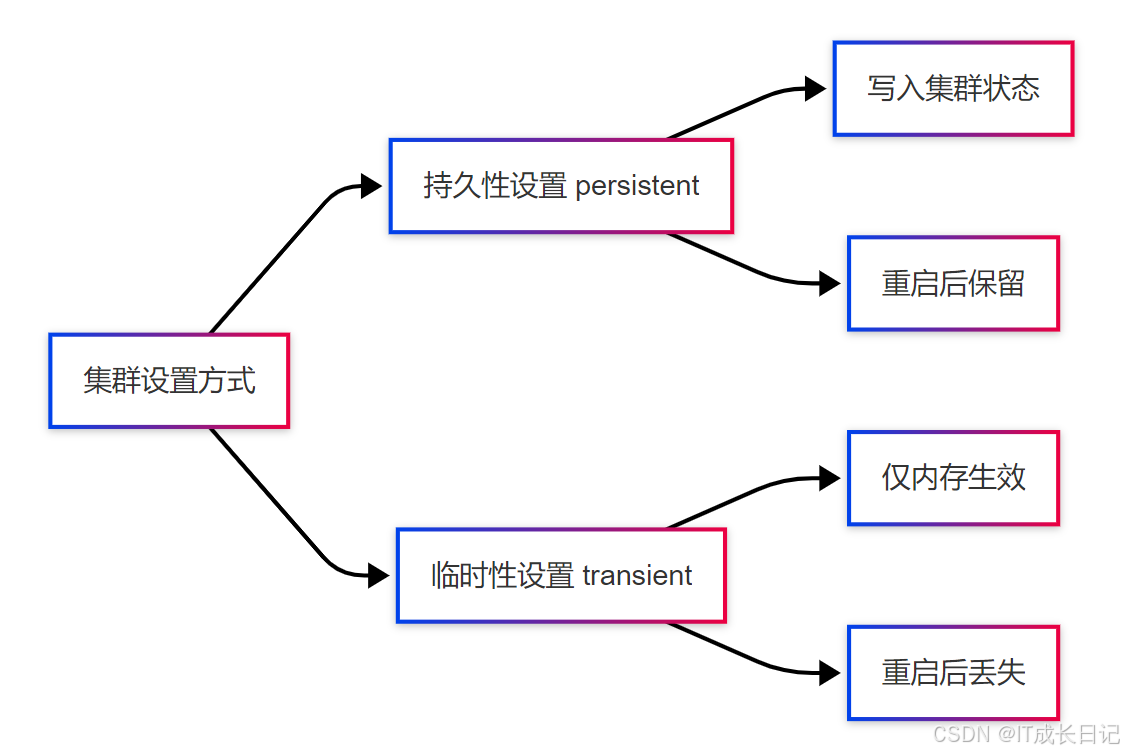
3.2 持久性设置(persistent)
特点:
- 写入集群状态
- 重启后仍然有效
-
适合生产环境
-
设置命令:
curl -X PUT "192.168.10.33:9200/_cluster/settings" -H "Content-Type: application/json" -d'
{
"persistent": {
"cluster.max_shards_per_node": 8000
}
}
'
3.2 临时设置(transient)
特点:
- 仅在内存中生效
- 重启后恢复默认值
-
适合临时测试
-
设置命令:
curl -X PUT "192.168.10.33:9200/_cluster/settings" -H "Content-Type: application/json" -d'
{
"transient": {
"cluster.max_shards_per_node": 8000
}
}
'
4 问题解决方案
-
针对开头提出的问题,解决方案很简单:使用persistent替代transient设置
-
完整解决方案步骤:

-
检查当前设置:
curl -X GET "192.168.10.33:9200/_cluster/settings?pretty"
-
使用persistent方式设置:
curl -X PUT "192.168.10.33:9200/_cluster/settings" -H "Content-Type: application/json" -d'
{
"persistent": {
"cluster.max_shards_per_node": 8000
}
}
' -
验证设置:
curl -X GET "192.168.10.33:9200/_cluster/settings?pretty"
- 重启测试:重启集群后再次检查设置是否保留
5 深入理解设置存储机制
- 为了更深入理解为什么transient设置会丢失,我们需要了解Elasticsearch的配置存储架构:
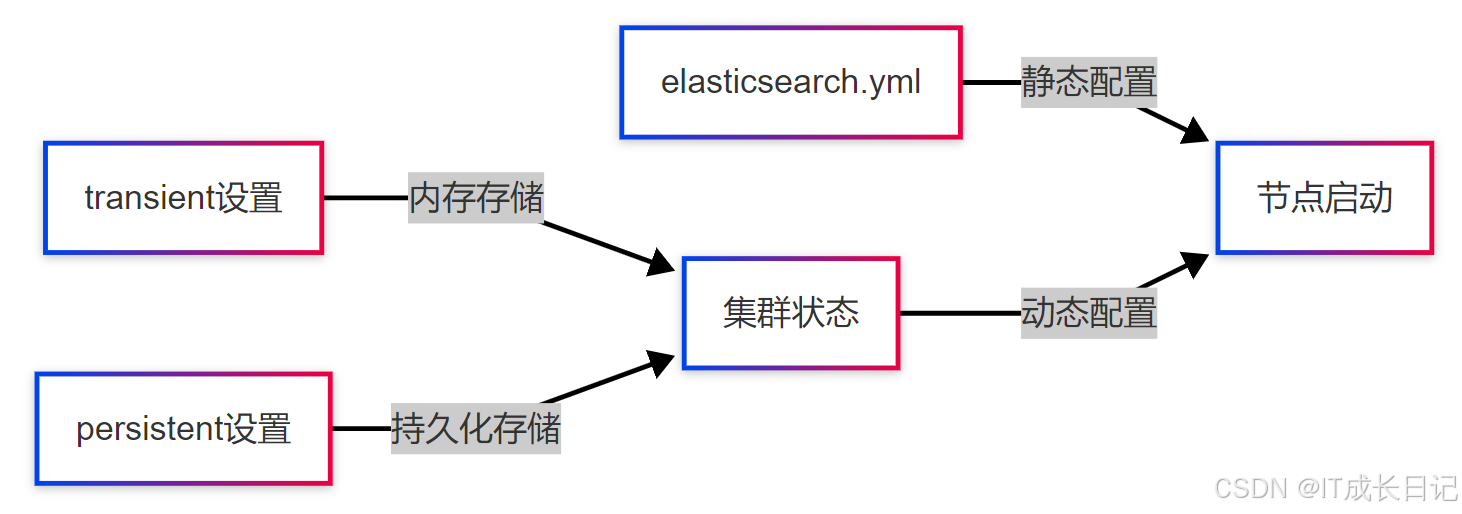
- 静态配置:通过elasticsearch.yml文件配置,需要重启生效
- 动态配置 :通过API实时修改
- transient:仅保存在内存中的集群状态
- persistent:持久化到磁盘的集群状态
6 生产环境最佳实践
- 合理设置分片数:
- 不是越大越好,需考虑节点资源
-
一般建议:总分片数 ≤ 节点数 × max_shards_per_node × 0.8
-
监控分片数量:
查看当前分片分布
curl -X GET "192.168.10.33:9200/_cat/shards?v"
查看节点分片负载
curl -X GET "192.168.10.33:9200/_cat/nodes?v&h=name,shards"
- 结合ILM管理索引生命周期:
- 自动滚动创建新索引
- 自动删除过期索引
-
控制历史数据保留时间
-
设置恢复建议:
推荐设置公式
建议值 = min(5000, 节点内存GB * 20)
示例:64GB内存节点
curl -X PUT "192.168.10.33:9200/_cluster/settings" -H "Content-Type: application/json" -d'
{
"persistent": {
"cluster.max_shards_per_node": 2000
}
}
'
7 常见问题解答
Q1:为什么需要限制最大分片数?
A:每个分片都会消耗内存、CPU和文件描述符资源。过多的分片会导致:
- 性能下降
- 集群不稳定
-
恢复时间变长
Q2:如何判断当前分片数是否合理?计算当前分片使用率
总分数=(curl -s -X GET "192.168.10.33:9200/_cat/shards?h=index,shard,prirep" | wc -l) 节点数=(curl -s -X GET "192.168.10.33:9200/_cat/nodes?h=ip" | wc -l)
max_shards=(curl -s -X GET "192.168.10.33:9200/_cluster/settings?include_defaults=true" | jq '.defaults.cluster.max_shards_per_node') 使用率=((总分数 * 100 / (节点数 * max_shards)))
echo "当前分片使用率: ${使用率}%"
Q3:设置过大有什么风险?
- 可能导致节点OOM
- 影响查询性能
- 延长故障恢复时间
8 总结
通过本文,我们深入理解了:
- cluster.max_shards_per_node参数的重要性
- persistent和transient设置的区别
- 解决重启后设置恢复默认值的问题
- 生产环境的最佳实践
希望这篇文章能帮助您更好地管理Elasticsearch集群分片数量,避免因设置不当导致的性能问题