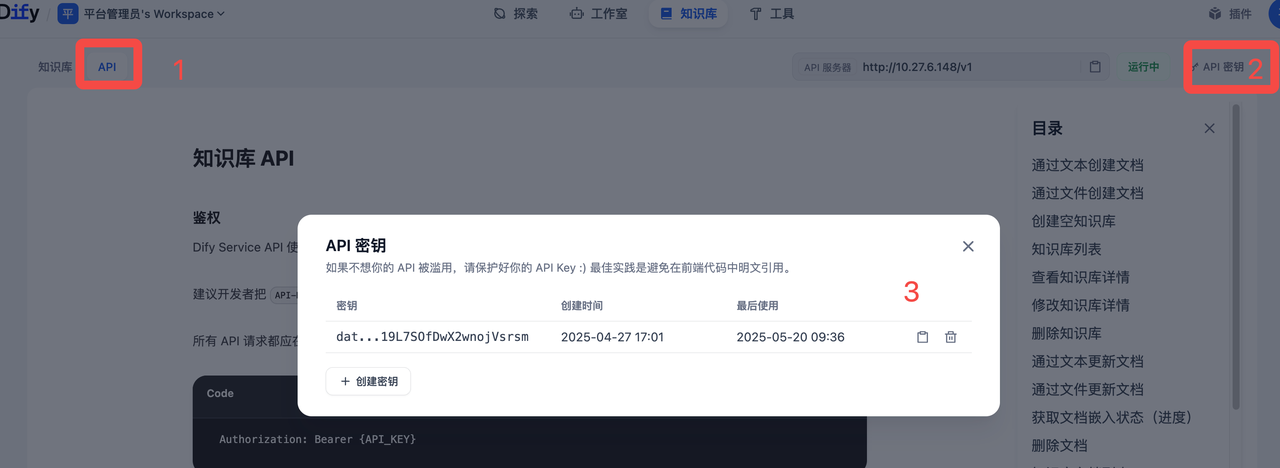
一、Dify配置
1.查看或创建知识库的API
二、下载程序配置
1. 安装依赖resquirements.txt
######requirements.txt#####
flask==2.3.3
psycopg2-binary==2.9.9
requests==2.31.0
python-dotenv==1.0.0
#####安装依赖
pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/2. 主程序代码app.py
##app.py
from flask import Flask, render_template, jsonify, Response
import requests
import os
from dotenv import load_dotenv
import io
import zipfile
import urllib.parse
from config import API_KEY, BASE_URL
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
@app.route('/api/datasets')
def get_datasets():
headers = {
'Authorization': f'Bearer {API_KEY}',
'Content-Type': 'application/json'
}
response = requests.get(
f'{BASE_URL}/v1/datasets?page=1&limit=20',
headers=headers
)
if response.status_code == 200:
data = response.json()
datasets = [{'id': item['id'], 'name': item['name']} for item in data.get('data', [])]
return jsonify(datasets)
return jsonify({'error': '获取知识库列表失败'}), response.status_code
@app.route('/api/files/<dataset_id>')
def get_files(dataset_id):
headers = {
'Authorization': f'Bearer {API_KEY}',
'Content-Type': 'application/json'
}
response = requests.get(
f'{BASE_URL}/v1/datasets/{dataset_id}/documents',
headers=headers
)
if response.status_code == 200:
data = response.json()
files = []
for item in data.get('data', []):
file_id = item['id']
file_name = item.get('data_source_detail_dict', {}).get('upload_file', {}).get('name', file_id)
files.append({'id': file_id, 'name': file_name})
return jsonify(files)
return jsonify({'error': '获取文件列表失败'}), response.status_code
def download_single_file(dataset_id, document_id):
headers = {
'Authorization': f'Bearer {API_KEY}',
'Content-Type': 'application/json'
}
# 获取文件下载地址
response = requests.get(
f'{BASE_URL}/v1/datasets/{dataset_id}/documents/{document_id}/upload-file',
headers=headers
)
if response.status_code == 200:
download_url = response.json().get('download_url')
if download_url:
# 拼接完整的下载URL
full_url = f'{BASE_URL}{download_url}'
file_response = requests.get(full_url, headers=headers)
if file_response.status_code == 200:
return file_response.content
return None
@app.route('/api/download/<dataset_id>/<document_id>')
def download_file(dataset_id, document_id):
content = download_single_file(dataset_id, document_id)
if content:
return Response(
content,
mimetype='application/octet-stream',
headers={'Content-Disposition': 'attachment'}
)
return jsonify({'error': '文件下载失败'}), 400
@app.route('/api/download-dataset/<dataset_id>')
def download_dataset(dataset_id):
# 获取文件列表
headers = {
'Authorization': f'Bearer {API_KEY}',
'Content-Type': 'application/json'
}
response = requests.get(
f'{BASE_URL}/v1/datasets/{dataset_id}/documents',
headers=headers
)
if response.status_code != 200:
return jsonify({'error': '获取文件列表失败'}), response.status_code
files = []
for item in response.json().get('data', []):
file_id = item['id']
file_name = item.get('data_source_detail_dict', {}).get('upload_file', {}).get('name', file_id)
files.append({'id': file_id, 'name': file_name})
# 创建ZIP文件
memory_file = io.BytesIO()
with zipfile.ZipFile(memory_file, 'w') as zf:
for file in files:
content = download_single_file(dataset_id, file['id'])
if content:
zf.writestr(file['name'], content)
memory_file.seek(0)
return Response(
memory_file.getvalue(),
mimetype='application/zip',
headers={'Content-Disposition': f'attachment;filename=dataset_{dataset_id}.zip'}
)
if __name__ == '__main__':
app.run(debug=True)3. 配置知识库的Base_URL和API_key
配置dify知识库和数据库鉴权信息,如下:
# 知识库API配置
API_KEY = 'dataset-YNXAxOyNucHoyzVUN6MlPJXT'
BASE_URL = 'http://10.1.140.33'三、启动服务
#python3 app.py
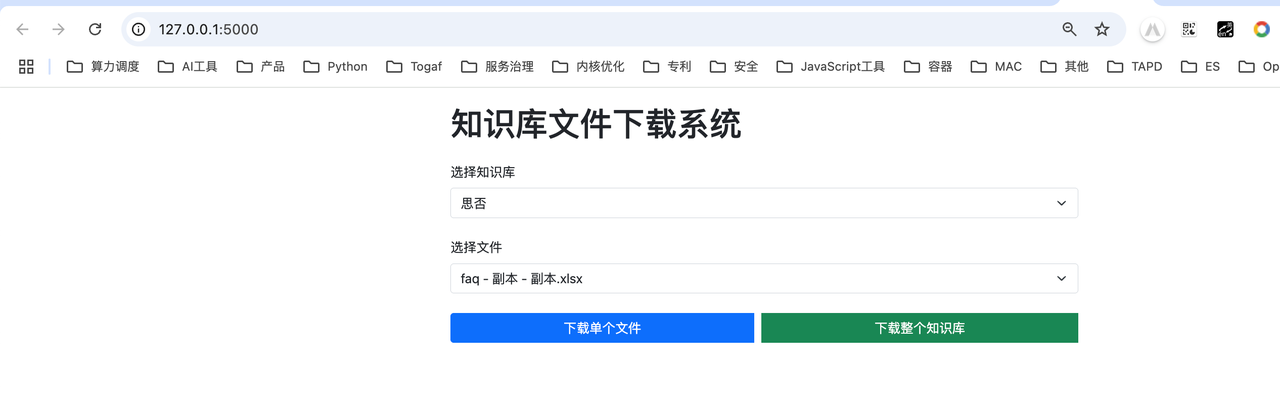
访问 http://127.0.0.1:5000/ 进行下载文件或整个知识库