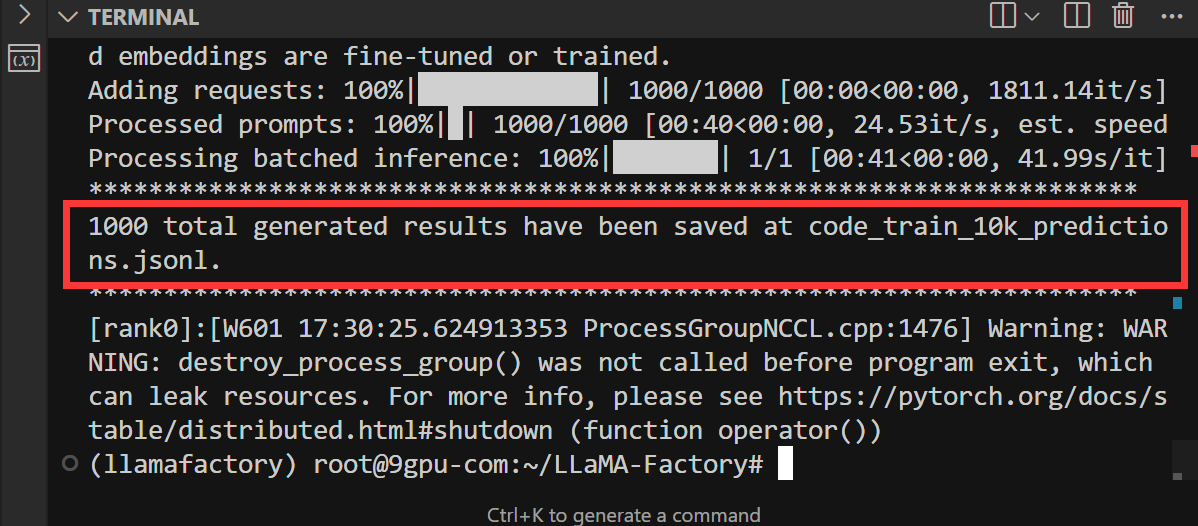
scripts/vllm_infer.py 是 LLaMA-Factory 团队用于批量推理(inference)的脚本,基于 vLLM 引擎,支持高效的并行推理。它可以对一个数据集批量生成模型输出,并保存为 JSONL 文件,适合大规模评测和自动化测试。
一、 环境准备
激活LLaMaFactory环境,进入LLaMaFactory目录
python
cd LLaMA-Factory
conda activate llamafactory已安装 vLLM
你需要先安装 vLLM(https://github.com/vllm-project/vllm),否则脚本无法运行。
python
pip install vllm已安装 fire
该脚本用 fire 作为命令行参数解析器。
python
pip install fire准备好模型和数据集
讲待推理文件放到LLaMA-Factory/data目录下
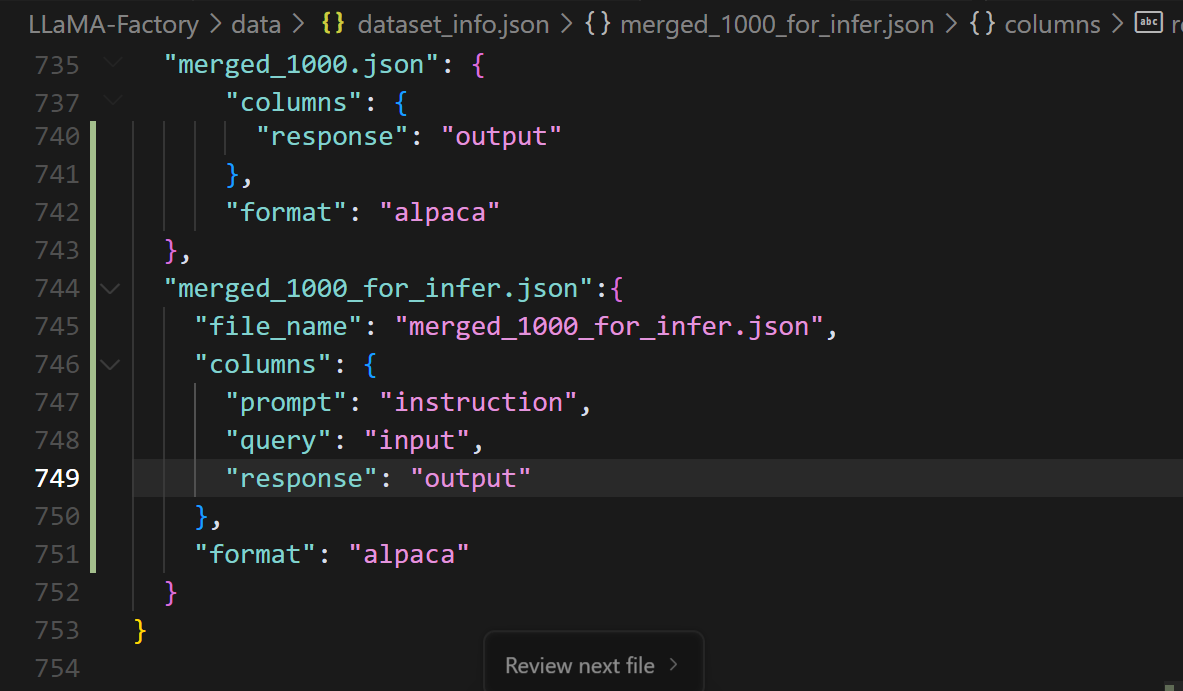
修改dataset_info.json文件
二、如何用 vLLM 正确加载 LoRA/adapter 微调模型进行批量推理?
1. 指定主模型和 adapter
vLLM 支持加载主模型+adapter(LoRA)权重。你需要:
- --model_name_or_path 指向主模型目录(如 /root/.cache/modelscope/hub/models/XGenerationLab/XiYanSQL-QwenCoder-3B-2504)
- --adapter_name_or_path 指向adapter目录(如 /root/LLaMA-Factory/output/qwencoder-sft)
2. 命令
python
python scripts/vllm_infer.py \
--model_name_or_path /root/.cache/modelscope/hub/models/XGenerationLab/XiYanSQL-QwenCoder-3B-2504 \
--adapter_name_or_path /root/LLaMA-Factory/output/qwencoder-sft \
--dataset merged_1000_for_infer.json \
--dataset_dir data \
--template qwen \
--save_name code_train_10k_predictions.jsonl \
--max_new_tokens 2563. 运行效果