本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
还在为大语言模型微调的高门槛而头疼吗?代码复杂、资源消耗大、实验管理繁琐......这些问题是否阻碍了你探索AI更大潜力的脚步?
今天,我们要介绍一个革命性的开源项目------LLaMA-Factory 。它能够让你统一、高效地微调100+个大语言模型与视觉语言模型,堪称ACL 2024的明星工具!

概述
LLaMA-Factory是一个统一的大模型微调框架,它集成了目前主流的大语言模型和视觉语言模型,并提供了高效、便捷的微调方案。无论你是研究者、开发者,还是企业用户,都可以通过这个工具轻松实现模型的定制化训练。
痛点场景
在大模型微调的过程中,我们常常会遇到以下问题:
- 代码复杂:不同模型的微调代码差异大,学习成本高。
- 资源消耗:训练大型模型需要大量的计算资源和时间。
- 实验管理:多次微调实验的管理和比较非常繁琐。
- 模型兼容:不同架构的模型需要不同的处理方式,难以统一操作。
LLaMA-Factory的出现,正是为了解决这些痛点,让微调变得简单高效。
核心功能
- 统一框架:支持100+种大语言模型和视觉语言模型,包括LLaMA、BLOOM、ChatGLM、Baichuan、Vision Transformer等。
- 高效训练:采用先进的高效微调技术(如LoRA、QLoRA),大幅降低计算资源和时间成本。
- 便捷操作:提供清晰易懂的API和命令行工具,无需深入底层代码即可完成微调。
- 实验管理:内置实验跟踪和比较功能,方便用户管理多次微调结果。
- 多模态支持:不仅支持纯文本模型,还支持视觉语言模型,满足多模态应用需求。
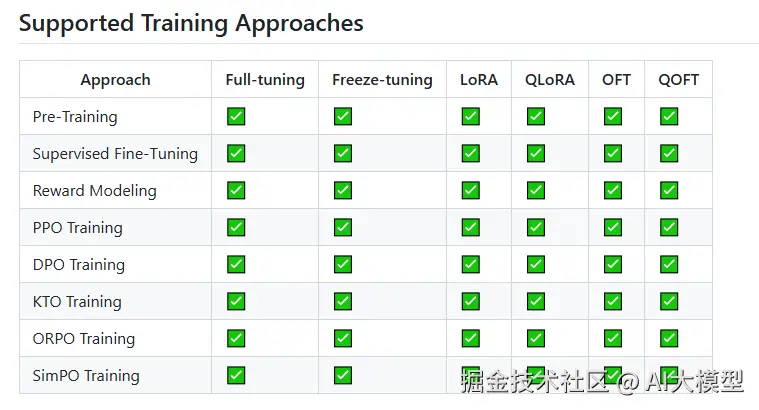
应用场景
- • 学术研究:研究者可以快速验证不同微调方法对模型性能的影响。
- • 企业定制:企业可根据自身业务需求,定制化训练专属的大模型。
- • 个人学习:开发者和个人爱好者可以低成本地体验和大模型微调的全过程。
- • 多模态应用:适用于需要结合图像和文本的任务,如图像描述、视觉问答等。
部署
使用LLaMA-Factory非常简单,只需几步即可开始微调你的模型:
- 安装依赖:
bash
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -r requirements.txt-
准备数据: 将你的训练数据整理成JSON格式,并配置到数据目录中。
-
配置参数: 修改配置文件,选择模型、设置超参数、指定数据路径等。
-
开始训练:
css
python src/train_bash.py \
--model_name_or_path path_to_your_model \
--data_path path_to_your_data \
--output_dir path_to_save_checkpoints- 推理测试: 训练完成后,使用内置的推理脚本测试模型效果。
更多详细的使用方法,请参考项目的GitHub文档。
总结
LLaMA-Factory是一个强大且易用的工具,极大地降低了大模型微调的门槛。无论你是想要进行学术研究,还是为企业构建定制化AI解决方案,它都能为你提供强有力的支持。
高效、统一、便捷------LLaMA-Factory让你轻松驾驭百个大模型,开启AI微调的新时代!
项目地址
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。