使用 Loki + Promtail + Grafana 搭建轻量级容器日志分析平台
摘要
本文介绍如何通过 Docker Compose 快速搭建 Loki 日志存储、Promtail 日志采集和 Grafana 日志可视化/告警的完整流程。用最小化示例演示核心配置、常见问题排查和告警规则设置,帮助读者快速上手。
1、部署步骤
当前环境:
- host4:192.168.0.224 (已部署prometheus+grafana) 上期搭建过程
- host1:192.168.0.221(Web主机, 已部署tomcat, mysql)
1.1、部署server端
1.1.1. 创建Loki专用docker-compose文件(host4)
#创建网络
docker network create monitor-net
mkdir -p /opt/monitor/loki && cd /opt/monitor/loki
nano docker-compose.yml
yaml
services:
# 新增Loki日志服务
loki:
image: grafana/loki:3.4.1
container_name: loki
restart: unless-stopped
networks:
- monitor-net
ports:
- "3100:3100" # HTTP 接口(读取/写入日志)
- "9096:9096" # GRPC 端口(可选对外暴露给开发者调试)
command:
- "--config.file=/etc/loki/local-config.yml"
- "--config.expand-env=true"
- "--target=all" #让 Loki 在单体(monolithic)模式下启动,所有组件都在同一个进程里
# - "--pattern-ingester.enabled=false" # 直接禁用
volumes:
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
- loki_data:/loki
- ./loki-config.yml:/etc/loki/local-config.yml:ro
# - /data:/data # 挂载整个数据目录
environment:
- TZ=Asia/Shanghai
healthcheck:
test: ["CMD-SHELL", "wget -qO- http://localhost:3100/ready > /dev/null || exit 1"]
interval: 15s
timeout: 10s
retries: 30
start_period: 90s # 给 Loki 更多启动时间
deploy:
resources:
limits:
cpus: '1' # 中等负载日志量
memory: 2G # 保留缓冲区空间
# 新增Promtail(采集host4自身日志)
promtail:
image: grafana/promtail:3.4.1
user: "0:996"
container_name: promtail
restart: unless-stopped
networks:
- monitor-net
volumes:
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
- /var/lib/docker/containers:/var/lib/docker/containers:ro
- /var/run/docker.sock:/var/run/docker.sock:ro
- ./promtail-config.yml:/etc/promtail/config.yml
command:
- "-config.file=/etc/promtail/config.yml"
environment:
- TZ=Asia/Shanghai
- LOKI_URL=http://loki:3100
depends_on:
loki:
condition: service_healthy
deploy:
resources:
limits:
cpus: '0.3'
memory: 300M
volumes:
loki_data:
networks:
monitor-net:
external: true小结:将宿主机时区挂载到容器,避免时间偏移;Loki 部署在 host4,Promtail 同时采集本机日志。
1.1.2. 配置文件详解
1.Loki配置 (loki-config.yml):
yaml
auth_enabled: false
server:
http_listen_port: 3100
grpc_listen_port: 9096
log_level: debug
grpc_server_max_concurrent_streams: 1000
common:
instance_addr: 127.0.0.1
path_prefix: /tmp/loki
storage:
filesystem:
chunks_directory: /tmp/loki/chunks
rules_directory: /tmp/loki/rules
replication_factor: 1
ring:
kvstore:
store: inmemory
query_range:
results_cache:
cache:
embedded_cache:
enabled: true
max_size_mb: 100
limits_config:
reject_old_samples: false # 允许旧时间戳日志
reject_old_samples_max_age: 168h # 接受7天内的旧日志
metric_aggregation_enabled: true
schema_config:
configs:
- from: 2020-10-24
store: tsdb
object_store: filesystem
schema: v13
index:
prefix: index_
period: 24h
pattern_ingester:
enabled: true # 禁用此组件(单体模式不需要)
metric_aggregation:
loki_address: localhost:3100
ruler:
alertmanager_url: http://localhost:9093
frontend:
encoding: protobuf生产建议:
- 将
filesystem改为s3或gcs - 添加
retention_period: 720h# 日志保留30天
3. Grafana数据源配置 (grafana-datasources.yml):
nano grafana-datasources.yml
yaml
apiVersion: 1
datasources:
- name: Loki
type: loki
access: proxy
url: http://loki:3100
isDefault: false
version: 1
jsonData:
maxLines: 2000
derivedFields: # 日志关联追踪(关键配置!)
- datasourceUid: 'prometheus' # 关联Prometheus
matcherRegex: 'traceID=(\w+)' # 从日志提取TraceID
name: 'TraceID'
url: '$${__value.raw}' # 跳转到Trace查看作用:实现日志与分布式追踪(Jaeger/Tempo)的联动
4. Promtail配置(host4自身日志)
nano promtail-config.yml
yaml
server:
http_listen_port: 9080
grpc_listen_port: 0 # 禁用gRPC
positions:
filename: /tmp/positions.yaml
clients:
- url: http://loki:3100/loki/api/v1/push
scrape_configs:
- job_name: host1_dockerlog # Docker服务发现
docker_sd_configs:
- host: unix:///var/run/docker.sock
refresh_interval: 15s
relabel_configs: # 标签重写规则
- source_labels: ['__meta_docker_container_name']
regex: '/(.*)' # 提取容器名(去除前缀/)
target_label: 'container'
action: replace
- source_labels: ['__meta_docker_container_log_stream']
target_label: 'logstream'
pipeline_stages:
- docker: {}
- job_name: host4_syslog
static_configs:
- targets: [localhost]
labels:
job: syslog
host: host4
__path__: /var/log/*log标签意义 :
host: 服务器标识
container: 容器名称
job: 日志类型(syslog/docker)
1.1.3.启动容器 Loki 与 Promtail
cd /opt/monitor/loki
docker compose up -d验证:
docker exec loki curl -s http://localhost:3100/ready应返回ready。docker logs promtail | grep -i error确认无明显报错。
1.1.4. 监控Loki自身
在Prometheus配置中prometheus.yml添加:
scrape_configs:
- job_name: 'loki'
static_configs:
- targets: ['loki:3100'] # 容器内地址
- job_name: 'promtail'
static_configs:
- targets: ['promtail:9080'] # 容器内地址1.2、多主机采集配置
1.2.1. 在host1创建Promtail配置
cat > promtail-config-host1.yml <<EOF
yaml
server:
http_listen_port: 9080
positions:
filename: /tmp/positions.yaml
clients:
- url: http://192.168.0.224:3100/loki/api/v1/push # 使用IP地址确保可达
scrape_configs:
- job_name: host1_dockerlog
docker_sd_configs:
- host: unix:///var/run/docker.sock
refresh_interval: 15s
relabel_configs:
- source_labels: ['__meta_docker_container_name']
regex: '/(.*)'
target_label: 'container'
replacement: '$1'
action: replace
- source_labels: ['__meta_docker_container_log_stream']
target_label: 'logstream'
pipeline_stages:
- docker: {}
- job_name: host1_syslog
static_configs:
- targets: [localhost]
labels:
job: syslog
host: host1
__path__: /var/log/**/*.log # 递归匹配所有日志
- job_name: tomcat-host1
static_configs:
- targets: [localhost]
labels:
job: tomcat
host: host1
app: webapp
__path__: /tomcat_logs/*.log # 使用挂载路径
pipeline_stages:
- regex:
expression: '^(?P<timestamp>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}.\d{3}) (?P<level>\w+)'
- labels:
level:
clients.url填写 Loki-Service 的 IP__path__确保只采集.log文件,避免提取到.gz产生"timestamp too old"报错
1.2.2. 启动host1的Promtail
nano docker-compose.yaml
bash
services:
promtail_host1:
image: grafana/promtail:3.4.1
container_name: promtail_host1
network_mode: host
restart: unless-stopped
volumes:
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
- /var/lib/docker/containers:/var/lib/docker/containers:ro
- /var/run/docker.sock:/var/run/docker.sock:ro
- /var/log:/var/log:ro # 系统日志目录
- /var/lib/docker/volumes/app_tomcat_logs/_data:/tomcat_logs:ro # Tomcat 日志目录
- ./promtail-config-host1.yml:/etc/promtail/config.yml
command:
- "-config.file=/etc/promtail/config.yml"
- "-config.expand-env=true"
environment:
TZ: "Asia/Shanghai"docker compose up -d
或者直接启动
bash
docker run -d --name promtail_host1 \
--network=host \
-v /etc/localtime:/etc/localtime:ro \
-v /etc/timezone:/etc/timezone:ro \
-v /var/lib/docker/containers:/var/lib/docker/containers:ro \
-v /var/run/docker.sock:/var/run/docker.sock:ro \
-v /var/log:/var/log:ro \
-v /var/lib/docker/volumes/app_tomcat_logs/_data:/tomcat_logs:ro \
-v ./promtail-config-host1.yml:/etc/promtail/config.yml \
grafana/promtail:3.4.1 \
-config.file=/etc/promtail/config.yml注意 :记得挂载
/etc/localtime,确保容器时间与宿主机一致。
检查Promtail状态
docker logs -f promtail_host1
docker logs promtail_host1 --tail 50 | grep -i "error\|warn"1.3 验证
需安装jq
apt update && apt install -y jq
1.3.1. 检查标签集合是否完整
bash
#检查标签集合
curl -sG "http://localhost:3100/loki/api/v1/label/host/values" | jq
# 应该输出
"status": "success",
"data": [
"host1",
"host4"
]
# 查询所有标签键(在host4执行)
curl -sG "http://localhost:3100/loki/api/v1/labels" | jq
#应输出
"status": "success",
"data": [
"app",
"container",
"filename",
"host",
"job",
"logstream",
"service_name"
]1.3.2. 验证主机日志采集
bash
# 检查host1的日志是否采集成功(在host4执行)
curl -sG "http://localhost:3100/loki/api/v1/query_range" \
--data-urlencode 'query={host="host1"}' \
--data-urlencode 'limit=5' | jq '.data.result[].values'1.3.3. 检查容器日志
bash
# 检查Tomcat日志(在host4执行)
curl -sG "http://localhost:3100/loki/api/v1/query_range" \
--data-urlencode 'query={container="ry-tomcat"}' \
--data-urlencode 'limit=5' | jq
# 检查MySQL错误日志
curl -sG "http://localhost:3100/loki/api/v1/query_range" \
--data-urlencode 'query={container="ry-mysql", logstream="stderr"}' \
--data-urlencode 'limit=5' | jq1.3.4.其他调试
1.网络连通性测试:
bash
# 在host1上测试连接Loki
docker exec promtail_host1 curl -v http://192.168.0.224:3100/ready2.promethus Target 状态
https://192.168.0.224/prometheus/targets
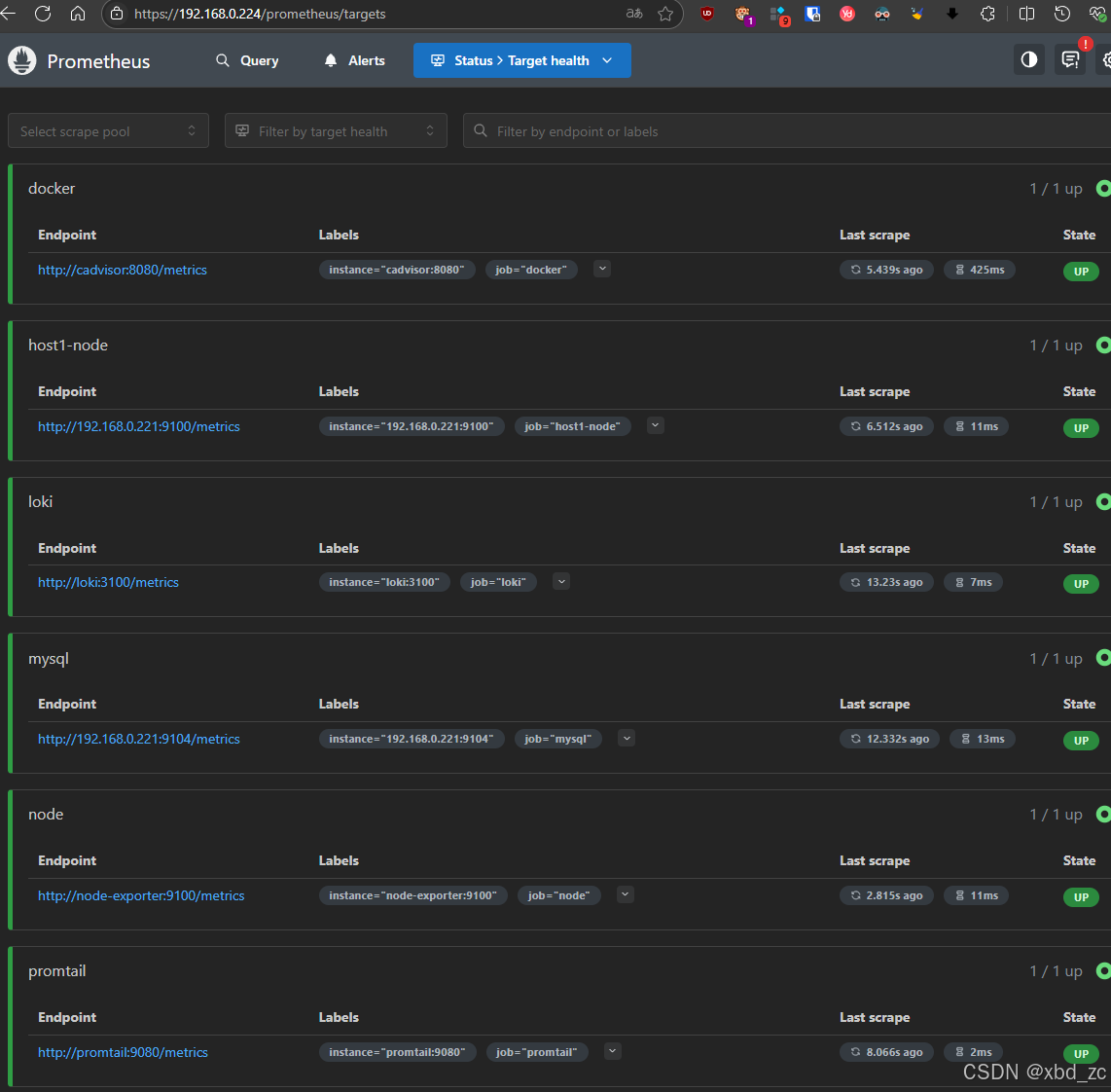
3.grafana 数据源状态
https://192.168.0.224/grafana/connections/datasources/
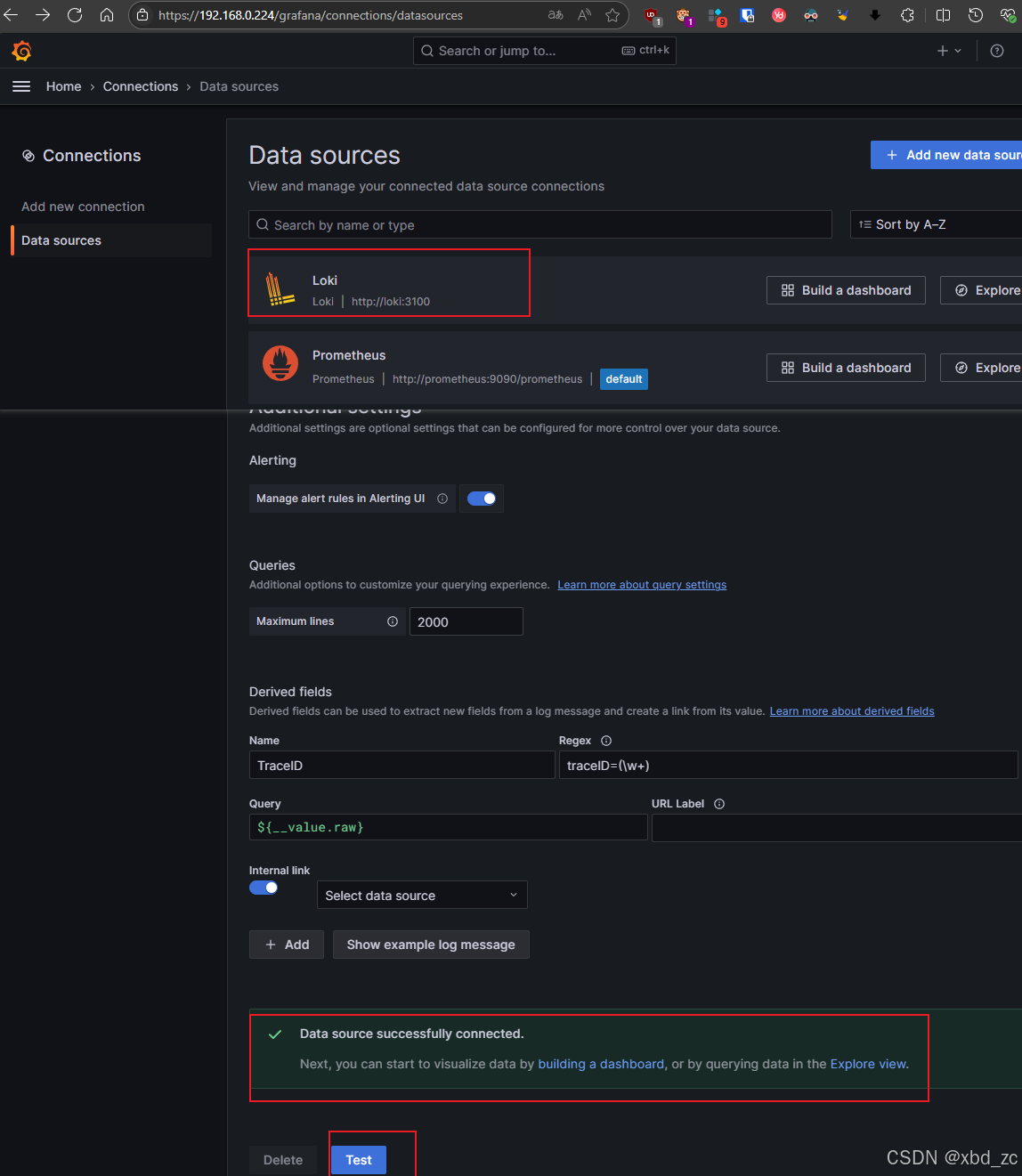
2、配置Grafana日志分析
2.1、Grafana配置
2.1.1:创建基础日志查询
- 访问Grafana:http://192.168.0.224:3000
- 左侧菜单 ➔ Explore ➔ 选择Loki数据源
- 输入查询:
{host="host1"} - 点击"Run query"查看所有host1的日志
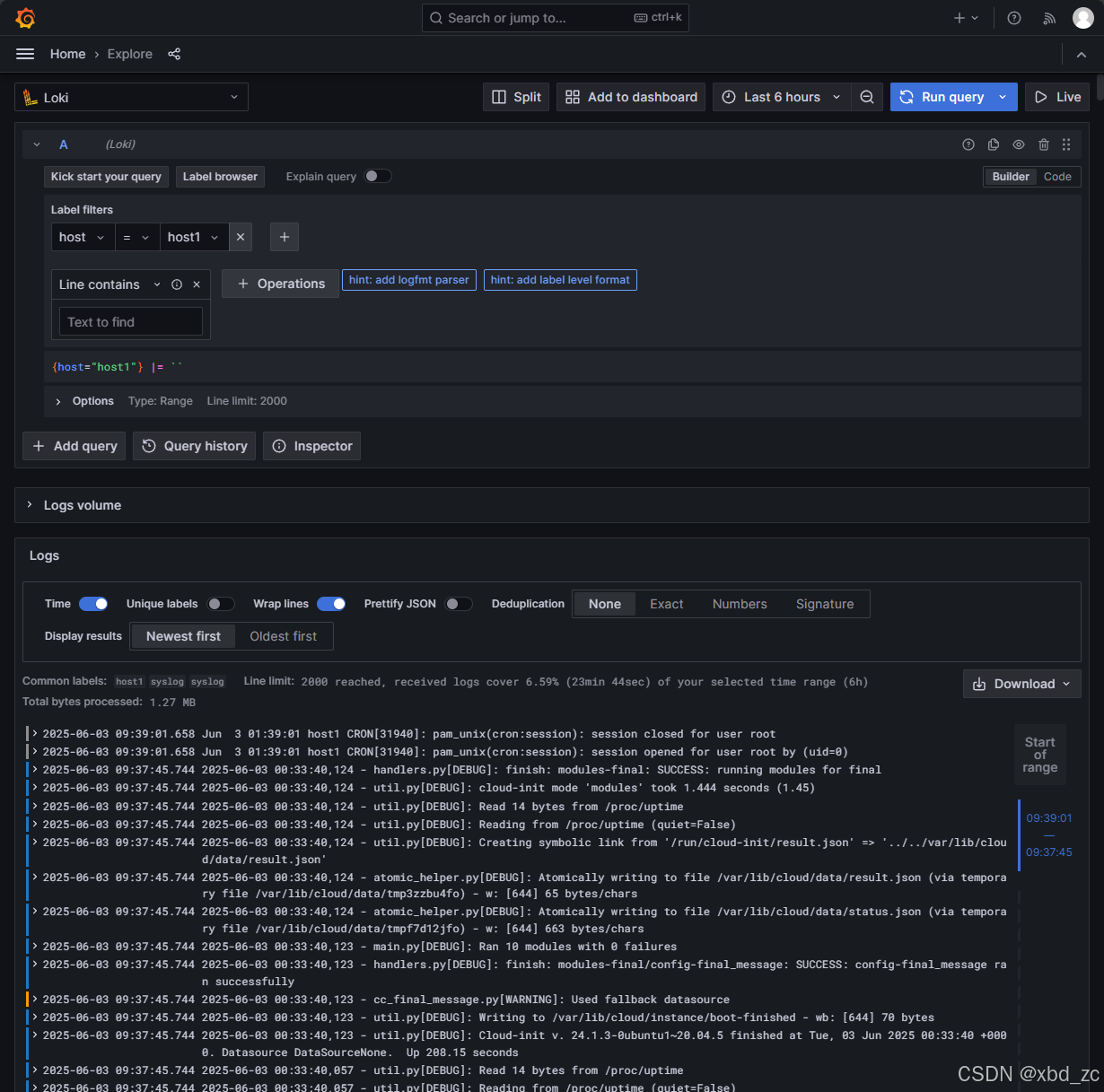
2.1.2:创建专用仪表板
- 左侧菜单 ➔ Dashboards ➔ New ➔ Import
- 导入预置的Loki仪表板(ID:
13639)- 这将自动创建完整的日志监控仪表板-设置-保存
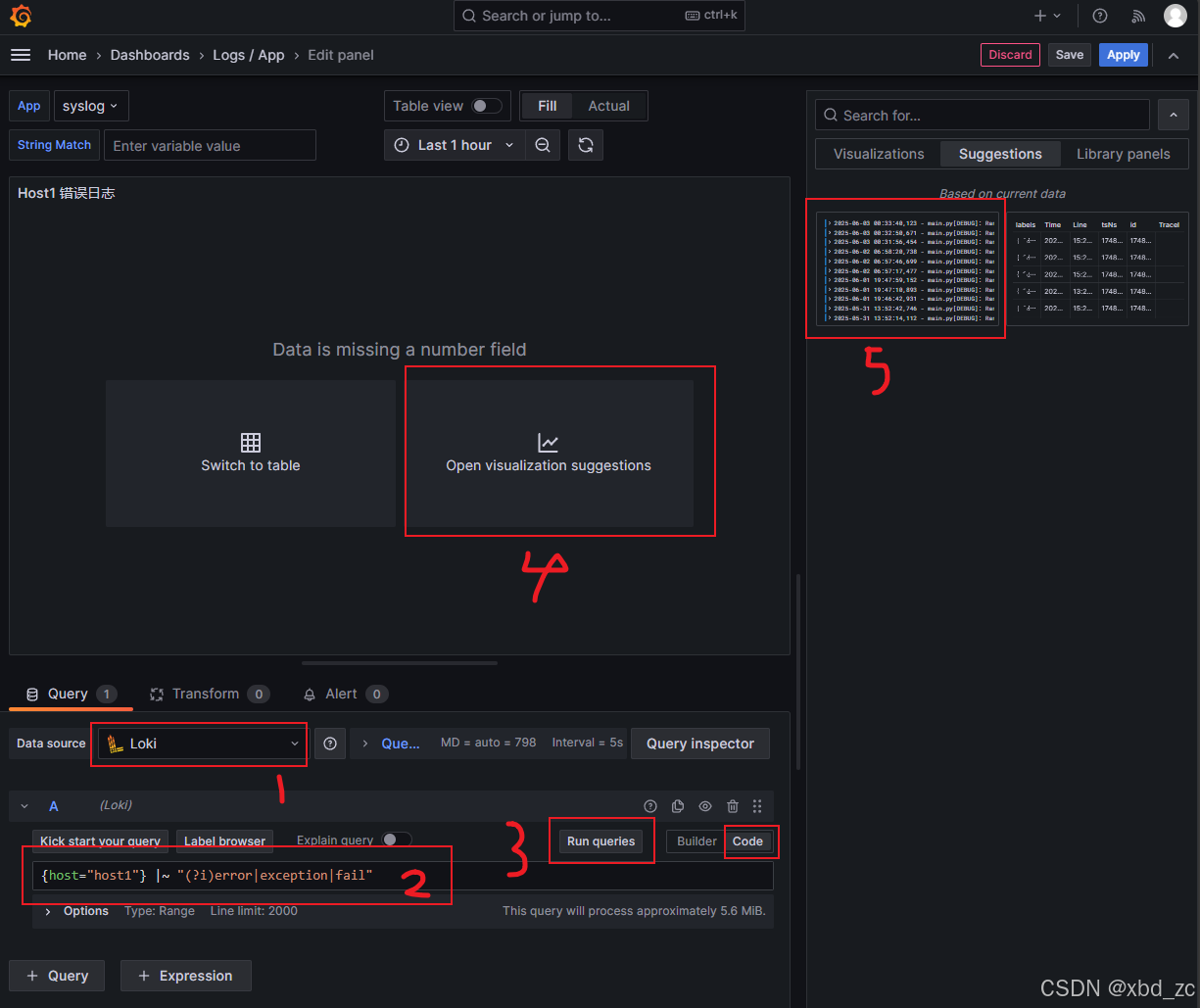
2.1.2:配置错误日志实时监控面板
- 在查询编辑区:
- 数据源选择:Loki
- 输入查询语句:
{host="host1"} |~ "(?i)error|exception|fail" - 点击 Run query
- 右侧面板配置:
- Visualization 选择:Logs
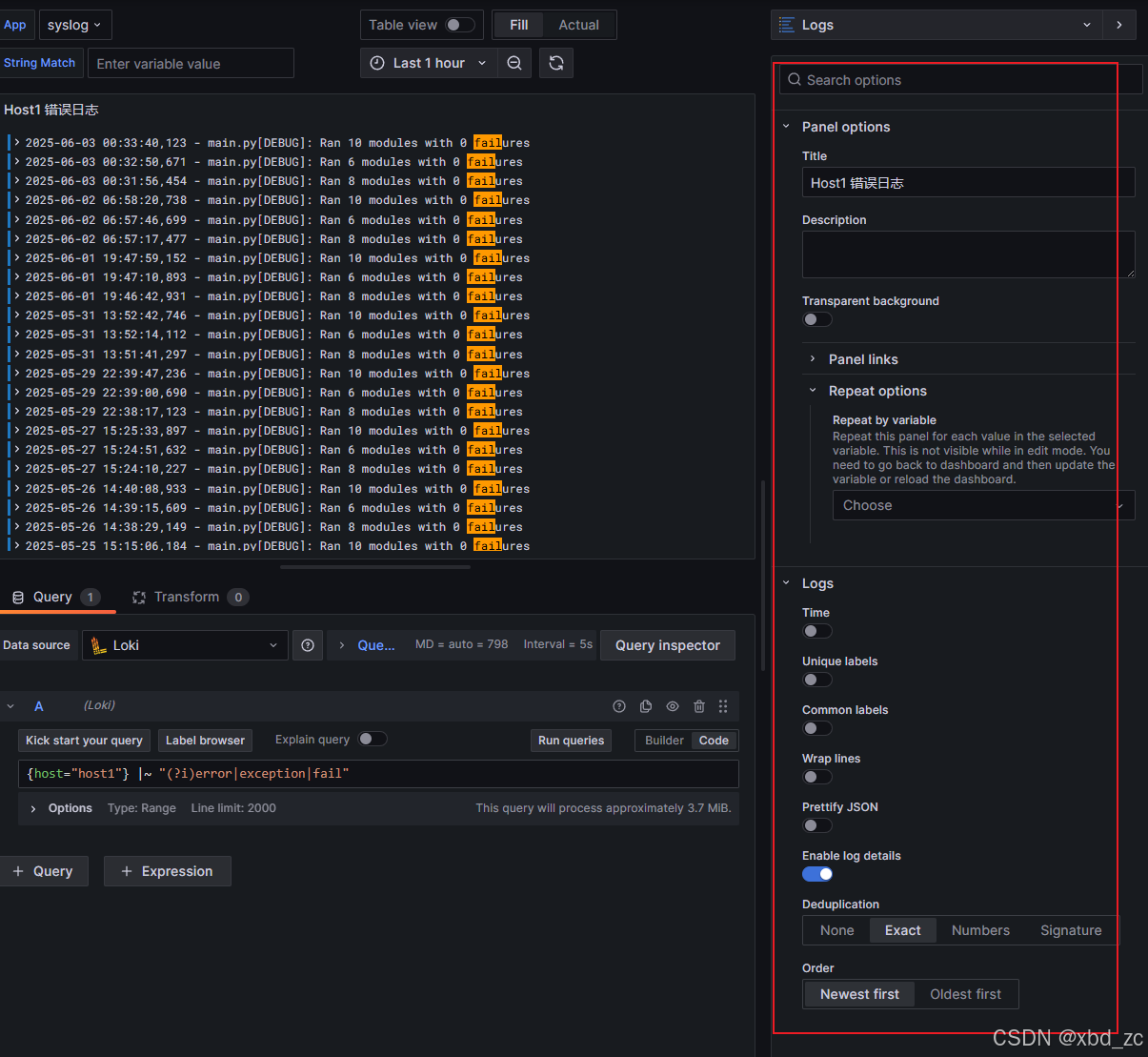
- Options 选项卡:
- Show log details:ON
- Deduplication:Exact match
- Panel options :
- Title:输入 "Host1 错误日志"
- Description:添加描述(可选)
- 点击右上角 Apply 保存面板
2.1.3:添加 Tomcat 应用日志分析面板
-
在仪表板页面,点击顶部 Add panel 图标(+号)
-
选择 Add new panel
-
配置查询:
{app="webapp"} | logfmt | detected_level != "info"怎么确定哪些字段(labels)可用?
*curl -sG "http://localhost:3100/loki/api/v1/query_range" --data-urlencode 'query={host="host1"}' --data-urlencode 'limit=1' | jq '.data.result[]' { "stream": { "detected_level": "unknown", "filename": "/var/log/auth.log", "host": "host1", "job": "syslog", "service_name": "syslog" },- 可以随便点击一条日志可以看到Fields
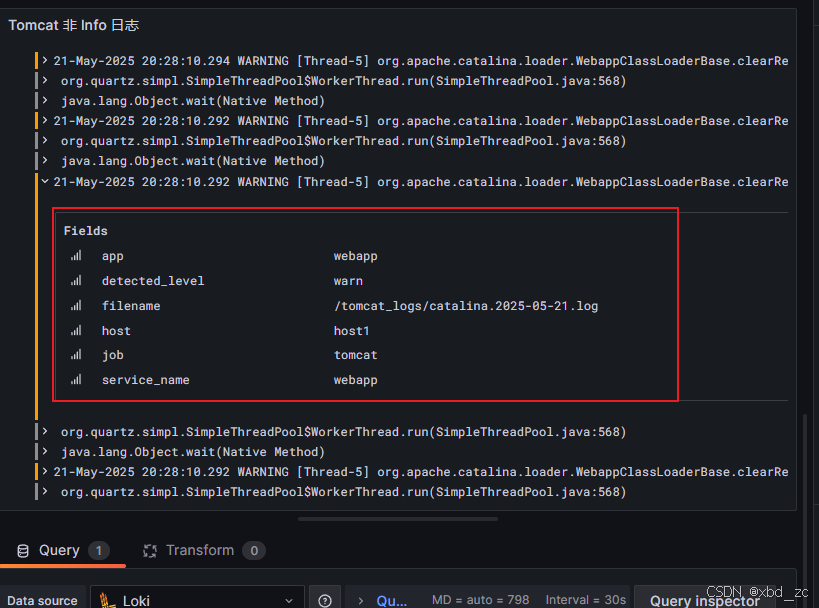
-
右侧配置Extract fields(可选):
- Visualization:Logs
- 在 Transform 选项卡:
- 搜索 ➔ Extract fields
- 选择 logfmt 解析器
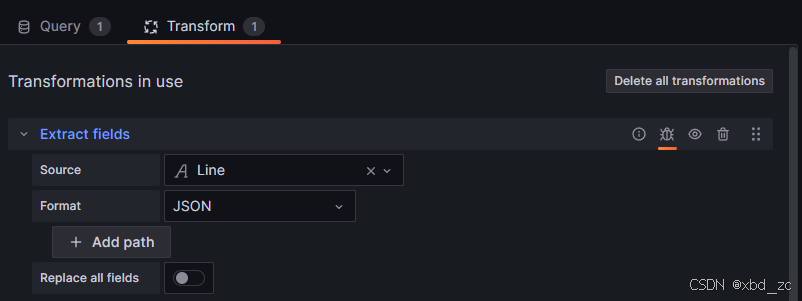
配置项 说明 Source 选择你日志的源字段:-- 如果日志行在"Line"字段里,就选 Line。-- 如果日志在某个自定义 label,下拉里也能看到labels.<xxx>,但一般默认Line。Format 如果你日志是 JSON,就选 JSON;如果你的日志行是以 key=value 形式(logfmt)写的,就选Key+value pairs;如果不确定,可以先试Auto,Grafana 会自动探测。+ Add path 点击后会出现一个新的行,用来指定要抽取的字段名。 Replace all fields 通常保持关闭(Off)。关闭时,它会保留原来的所有列,只把新抽取出来的字段加进来。开了之后,面板里只会剩下抽取后的字段。 - 只有当你希望拆出"labels 里没有、却只在原文文本里出现的那段"时,才考虑用 Extract fields 从"Line"里做复杂的解析。但绝大部分场景下,生产端/Promtail 端把好用的 KV 先丢到 labels 就已经足够,Grafana 只要把这些 labels 拆一拆就能用了
设置面板标题:"Tomcat 非 Info 日志" --> Apply
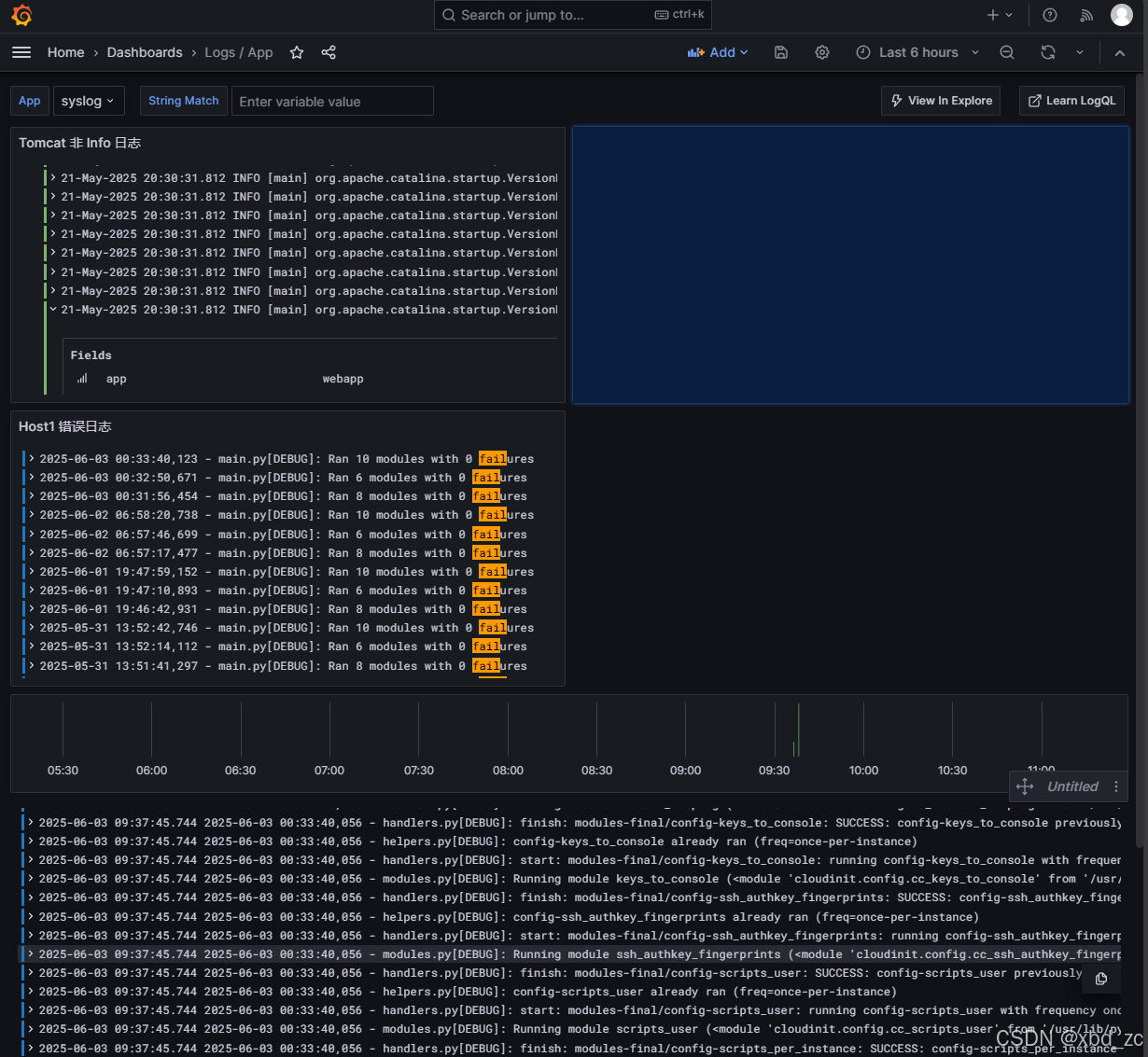
2.1.4:创建日志源分布饼图
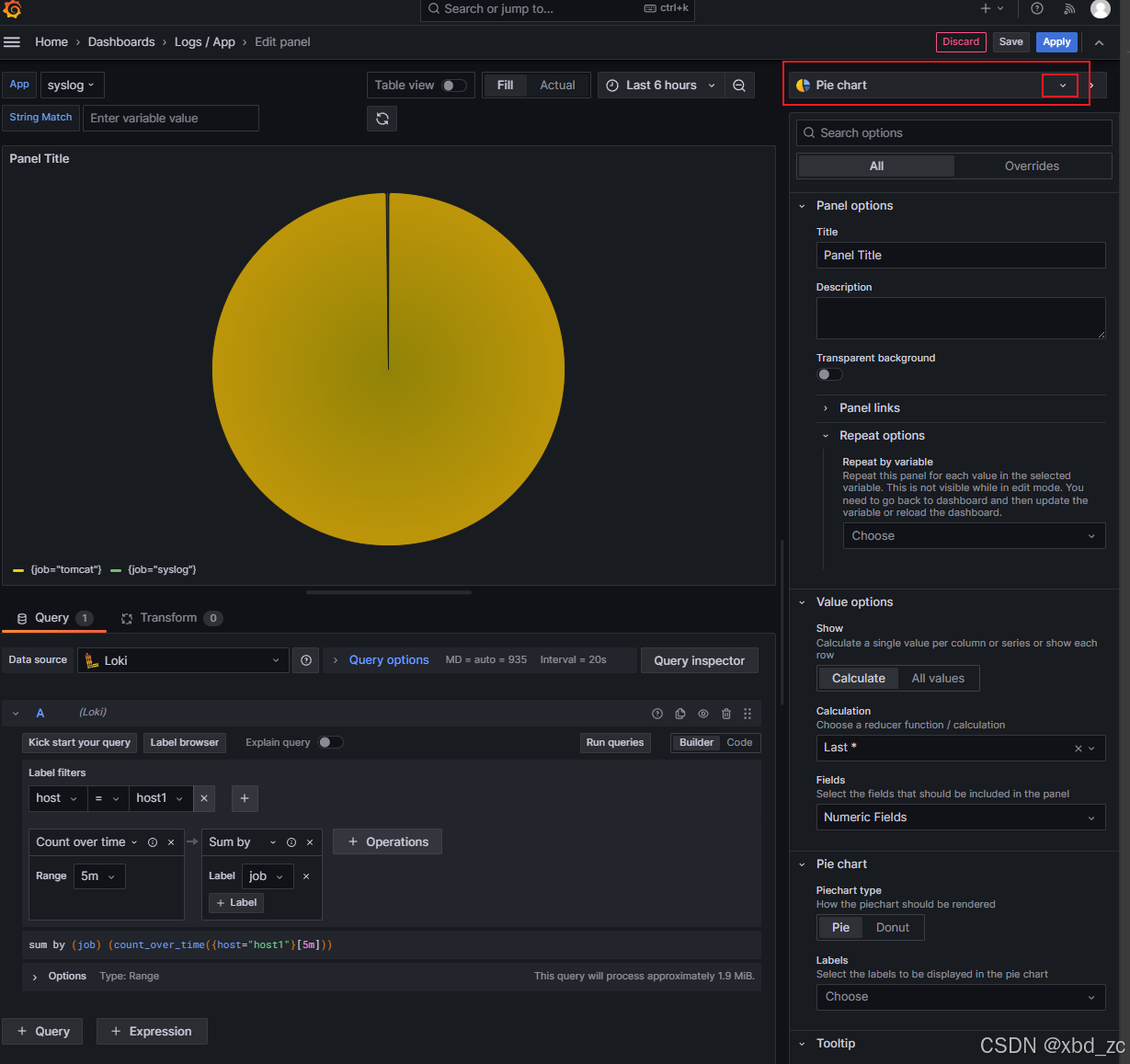
-
再次 Add panel
-
输入查询:
sum by (job) (count_over_time({host="host1"}[5m])) -
可视化配置:
- 右上角Visualization搜索:Pie chart
- Pie chart type:Pie
-
设置标题:"Host1 日志源分布"
2.1.5:使用 "Explore" 功能
-
左侧菜单 ➔ Explore(指南针图标)
-
选择 Loki 数据源
-
在查询框中输入:
{container="ry-tomcat"} | logfmt | level = "error"或者手动选择
Builder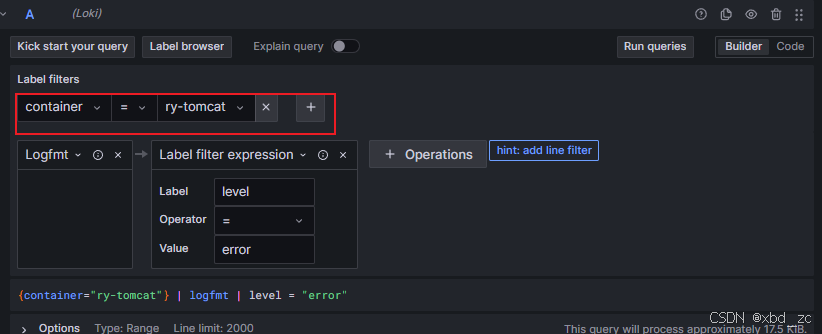
-
点击 Run query 查看结果
-
点击右上角 Add to dashboard 可将此查询保存为面板
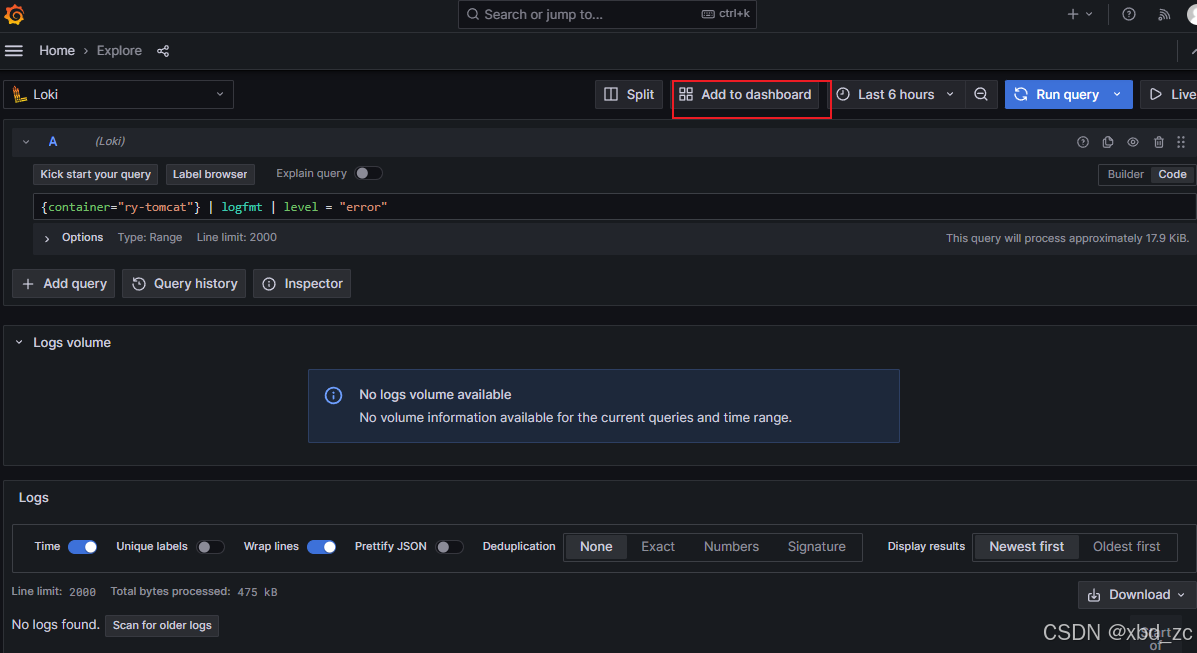
- 点击右上角 "Add to dashboard" → 选择 "Existing dashboard" → 指定 "Host1 日志监控" → 点击 "Add"随后会弹出一个面板编辑的对话框,你可以给它取个名称(例如 "Tomcat 错误等级日志"),调好格式(Logs、Color by level、Deduplication 等),然后点击 "Apply" 就会把它放到仪表板里。一旦完成,进入仪表板就能看到一个新的"Tomcat 错误等级日志"面板。
最后别忘了按仪表板右上角的"Save"图标,把整个仪表板保存一次
- 输入名字(例如 "Host1 日志监控"),选择合适的文件夹,然后点击 Save。
- 这样即使下次重启 Grafana,或者别人在别的浏览器打开,你都能看到刚才做的所有面板。
2.2、 为仪表板添加模板变量(Variables),让它更灵活
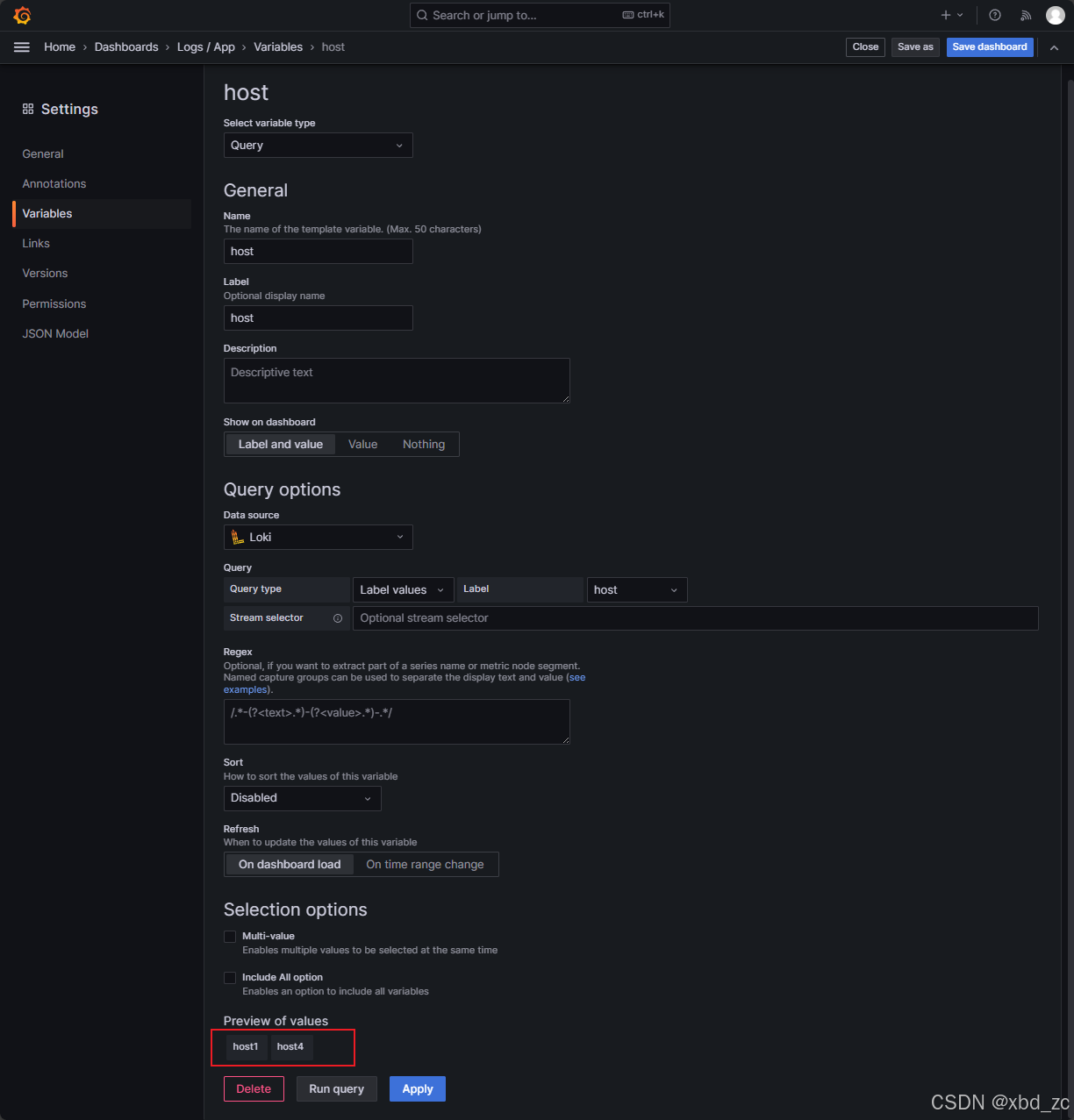
目前很多查询里,你都写死了 {host="host1"}、{app="webapp"}、{job="tomcat"}。如果后续想让同一个仪表板用于监控不同主机/不同应用/不同环境,建议改用变量(Dashboard → Settings → Variables)来动态控制。简单示例:
-
创建
host变量-
Dashboard 右上角点击 Settings(齿轮) → Variables → New
-
Name:
host -
Type: Query
-
Data source: 选择你的 Loki
-
Query:
- Query type : Label values
- Label : host
这会列出当前时段(Global 时间范围)内所有打上过
host标签的值,比如host1、host2等。 -
Preview of values:确认下拉里能看到
host1。 -
保存。
-
-
创建
job变量-
同样再添加一个变量:
-
Name:
job -
Type: Query
-
Data source: Loki
-
Query:
- Query type : Label values
- Label : job
这一步会列出在选定 host(比如
host1)范围内可见的所有 job 标签值(如tomcat、syslog)。
-
-
这样当你从下拉里先选
host1,下面job下拉就会自动只展示host1上跑过的 job。
-
-
修改面板 Query,让它使用变量
-
例如,之前写死的"Tomcat 错误日志"面板:
{host="host1", job="tomcat"} |~ "(?i)error|exception|fail"改成:
{host="$host", job="$job"} |~ "(?i)error|exception|fail" -
"Host1 日志源分布"饼图原来是:
sum by (job) (count_over_time({host="host1"}[5m]))改成:
sum by (job) (count_over_time({host="$host"}[5m])) -
这样在仪表板左上角会自动多出两个下拉菜单
[ host ] [ job ],你切换主机或切换 job,所有面板都会联动刷新。
-
-
再把"Tomcat 应用日志分析"用同样思路改写为:
{host="$host", app="$job"} | logfmt | detected_level!="info"- 或者把
app、job再区分开。 - 关键点是:所有原来写死的标签都改用
${变量名},多一个灵活性。
- 或者把
好处:
- 同一个仪表板可以横向监控多台主机、多套应用,只要有人在下拉里选,这些面板就自动帮你刷新。
- 也方便后续别人拿这套 Dashboard 只改少量变量就能直接套用,不用再手动跑那些长查询。
2.3、在 Promtail 端或 Loki pipeline 里提取 msg
2.3.1.在 Loki 查询中用 regexp 把"消息体"抽到 msg Label
假设你的 Tomcat 日志长这样(没有现成的 msg= 字段,只有纯文本):
21-May-2025 20:30:32.098 INFO [main] org.apache.catalina.startup.HostConfig.deployWAR Deploying web application archive [/opt/tomcat/webapps/ROOT.war]
21-May-2025 20:30:32.059 ERROR [main] org.apache.catalina.loader.WebappClassLoaderBase.clearReferencesThreads The web application [ROOT] appears to have started a thread named [quartzScheduler_Worker-7] which has failed to stop it. This is very likely to create memory leak. Stack trace of [quartzScheduler_Worker-7] [Thread-5]我们想把 Deploying web application archive ...、The web application [ROOT] appears to have started... 这一整段当作 msg。常见的做法是:
- 先用
| logfmt处理一遍,保证所有的app="webapp"、detected_level="error"之类的 KV 都被拆进了labels; - 再接一个
| regexp管道,把](也就是最后一个方括号加一个空格)之后的所有字符,用一个 named capture 抓到msglabel。
例如,你当前的查错误日志语句(近 30 分钟)可能是:
{host="host1"} | logfmt | detected_level="error"要让它"把 msg 也抽出来",可以改成:
swift复制编辑{host="host1"}
| logfmt
| detected_level="error"
| regexp "\\] (?P<msg>.*)"解释一下这行:
{host="host1"}:筛选出 Host1 上的所有日志;| logfmt:把已经打到detected_level、app等 KV 拿出来,并存到labels;| detected_level="error":只保留detected_level是error的那一条;| regexp "\\] (?P<msg>.*)":- 这里的正则
\\]匹配到日志中最后一个](也就是[main]、包名这种结束的那个),以及紧跟着的一个空格; (?P<msg>.*)则把这个]后面所有剩余的字符全部"抓"到一个名叫msg的 label 里。
- 这里的正则
做完这一步之后,Loki 会把每条符合条件的日志多加一个标签 msg="<日志正文>"。你可以在 Grafana → Explore 里把这条管道跑一遍,展开任意一条错误日志,检查 Fields ,就会看到多了一个 msg 字段,并且它的值就是那条日志最后面的文字内容。
2.3.2.直接用正则从 syslog 行里提取 msg
假设你的 syslog 行像这样:
May 21 20:30:32 host1 zabbix_agentd[12345]: UserParameter=/foo/bar Check OK
May 21 20:31:00 host1 zabbix_agentd[12345]: ERROR: something went wrong最简单的做法是在 Loki 查询里,用:
{host="host1", job="syslog"}
| regexp ": (?P<msg>.*)"意思是:
:匹配到冒号和一个空格(因为进程后面总是 "进程名PID: "),(?P<msg>.*)则把余下全部当作msg这个标签。
完整示例:
{host="host1", job="syslog"}
| regexp ": (?P<msg>.*)"
|~ "(?i)error"解释:
{host="host1", job="syslog"}:先把所有 Host1 上的 syslog 日志挑出来;| regexp ": (?P<msg>.*)":把每行中 "冒号 空格 后面剩余的那段" 都存到labels.msg;|~ "(?i)error":按正则再只保留包含(不区分大小写)"error" 的行。
在 Explore 里测试:
-
切到 Explore → 选 Loki 数据源 → Logs 模式 ,把上面三行拷进去,点 Run query。
-
下方返回的日志行,点击任一行最右侧的">"展开它,你会看到:
Fields ───────────────────────── host host1 job syslog msg ERROR: something went wrong如果有多种情况,第一行的
msg也会是 "UserParameter=/foo/bar Check OK" 这种。只要能看到msg,说明我们的正则生效了。
2.3.3、在 Promtail/Loki Pipeline 里预先提取 msg
有时候我们会把"提取消息体"这件事提前放在 Promtail 端做,或者在 Loki 的 pipeline_stages(如果你在 Loki 单独搭了一个 ingester pipeline)里就已帮你把 msg 做成了 label。此时,Grafana 就可以跳过"使用 regexp 抽取 msg" 这一步,直接用 TopK 去统计现成的 msg。
举例:如果你在 Promtail 的配置里,已经用过 json stage 或者 regex stage,把像下面这样的配:
scrape_configs:
- job_name: tomcat-host1
static_configs:
- targets: [ localhost ]
labels:
job: tomcat
host: host1
app: webapp
__path__: /tomcat_logs/*.log
pipeline_stages:
- regex:
expression: '\\] (?P<msg>.*)' # 比如,提取日志中"] "后面的全部内容到 msg
# expression: '^(?P<timestamp>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}.\d{3}) (?P<level>\w+)'
- labels:
msg:
# level:
#测试
echo "03-Jun-2025 11:00:00.000 INFO [main] com.example.Test Something happened MSG_TAG" >> /var/lib/docker/volumes/app_tomcat_logs/_data/test4.log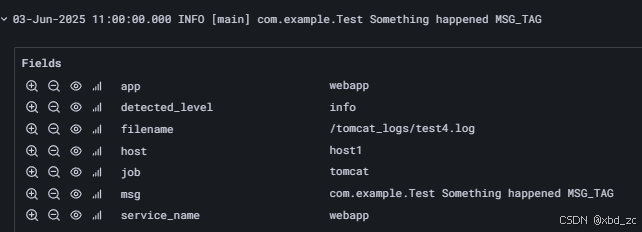
那么进到 Loki 里的每条日志就自动带有 msg="<正文>" 这个标签。此时,你在 Grafana 里只要写:
topk(10, sum by (msg) (
count_over_time(
{host="$host", job="tomcat", detected_level="error"}[30m]
)
))就能直接拿到 Top 10 的 msg 次数,无需再在 Query 里加 | regexp。然后同样把它可视化为 Table,Field Name 用 ${msg},就能列出"过去 30 分钟最热的 10 条错误消息"。
⚠️ 注意事项
避免 label 爆炸 :
把 level 做成 label 没问题,因为值有限(INFO、ERROR、WARN 等),但 msg 做 label 不建议用于大规模生产环境 ,因为它的值太多样,容易导致 label cardinality 爆炸。建议只在调试期间用 msg 做 label。
2.4、增加更细化的统计面板
除了"错误日志"、"非 Info 日志"、"日志源分布",可以再添加一些下列常见的、对运维和分析很有帮助的面板:
2.4.1. 日志量趋势折线图
-
Query:
sum by (job) (rate({host="$host"}[1m]))或者
sum by (job) (count_over_time({host="$host"}[1m]))这个指标能实时显示各 job 在"过去 1 分钟"里的日志条数变化趋势,比饼图侧重"时间序列"更直观。
-
Visualization:选择 Time series (或 Graph ),设置 legend 为
${job}。 -
这样可以观察日志峰值、流量突增、平稳期等。
2.4.2.各级别日志分布柱状图(Bar chart)
-
Query:
sum by (detected_level) (count_over_time({host="$host", job="$job"}[5m]))- 这会告诉你在所选主机+应用下,"过去 5 分钟"里各个
ERROR/WARN/INFO/DEBUG级别日志的数量。
- 这会告诉你在所选主机+应用下,"过去 5 分钟"里各个
-
Visualization:选择 Bar chart → X 轴填
detected_level,Y 轴是 数量。 -
既能看到"错误日志剧增",也能做服务健康度的大致评估。
-
Top N 错误消息(Table)
-
如果你已经在 Loki pipeline 或 在 Grafana Transform 里把"消息"字段(msg)拆出来,那就可以做一个 Table 面板,列出"过去 30 分钟最常出现的 10 条错误文本":
topk(10, sum by (msg) (count_over_time({host="$host", detected_level="error"}[30m]))) -
Visualization:Table
-
这样你一眼就能看到,当前系统里"最热"的那几条错误堆栈或关键字。
-
-
异常数量告警阈值面板(Stat/Gauge)
-
Query:
sum by (job) (count_over_time({host="$host", detected_level="error"}[1m]))或者
sum(count_over_time({host="$host", detected_level="error"}[5m])) -
Visualization:Stat (或者 Gauge)
-
配置一个阈值:比如当"过去 1 分钟错数量 > 5"时变红、提示报警。
-
也可以把它做成 Alert 规则,当数值超过阈值时触发通知。
-
-
日志大小/行数占比面板(Bar gauge)
-
Query:
sum by (job, detected_level) (count_over_time({host="$host"}[5m])) -
然后把 Visualization 选 Time series 并打开 "Stacking" → "Normal" 模式,这样能看到在一段时间里,各 job、各级别的日志是如何堆叠,哪个 job 占的百分比多、哪个级别最热。
-
3、为关键面板添加告警(Alerting)
3.1、配置 Grafana SMTP(编辑 grafana.ini)
Grafana 要能发邮件,必须在其配置文件 grafana.ini 中启用并填写 smtp 段。下面以"用 Docker Compose 方式部署 Grafana"为例,演示如何挂载、修改和重启。
3.1.1. 准备一个自定义的 grafana.ini
-
编辑配置文件
mkdir -p grafana-provisioning/config nano grafana-provisioning/config/grafana.ini nano grafana.ini -
在该目录下新建
grafana.ini,将默认配置复制过来并加以修改。最简单的做法是从 Grafana 官方仓库拷贝 "默认grafana.ini"(也可以先在已有容器里导出一份)。这里我们直接创建一个精简版,专门覆盖 SMTP 部分:ini#################################### SMTP / Emailing qq为例 ############################# [smtp] ;enabled = false ; ← 把 enabled 改为 true enabled = true host = smtp.qq.com:465 ; ← 修改为你的 SMTP 服务器地址和端口 user = 123321@qq.com ; ← SMTP 登录用户名 # If your SMTP server requires a password, 设置成真实密码 password = osdfdsfsadfsa # 邮箱SMTP授权码(非登录密码) ; If your SMTP server SPEFICALLY不需要登录,以空用户名为例 ; user = ; password = ;skip_verify = false ; 如果你想跳过 TLS 验证,可改成 true from_address = 123321@qq.com ; ← 邮件 From 字段,与上面的邮箱保持一致 from_name = Grafana ; ← 发件人名称 ; EHLO identity in SMTP dialog (defaults to instance_name if set, else hostname of the system) ;ehlo_identity = # ****************************************************** # 下面三行是 TLS/SSL 相关,如果你的 SMTP 需要 SSL 直接用 465 端口,则: ; startTLS policy (defaults to true if port is 587) #startTLS_policy = NoStartTLS # 例如: #host = smtp.example.com:465 #skip_verify = true #startTLS_policy = NoStartTLS # ****************************************************** # 如果你的 SMTP 服务地址是 Gmail,可以参考: # host = smtp.gmail.com:587 # user = yourgmail@gmail.com # password = your_gmail_app_password ; ← 注意:Gmail 要用 "应用专用密码" # from_address = yourgmail@gmail.com # from_name = Grafana ################## 下面其余配置保持默认不动 ####################### [log] mode = console level = info [paths] data = /var/lib/grafana logs = /var/log/grafana plugins = /var/lib/grafana/plugins provisioning = /etc/grafana/provisioning- 以上内容示例了最小化启用 SMTP 的方式,实际生产中可以保留
grafana.ini里更多其他模块的配置。重点是把[smtp]里的enabled = true、host、user、password、from_address、from_name等项补充好。 - 注意:
host = smtp.example.com:587:如果你的 SMTP 只在 587/STARTTLS 上跑,就填:587,如果是真正的 SSL over TLS(如某些服务用 465 端口),就写smtp.xxx.com:465并设置startTLS_policy = NoStartTLS、skip_verify = true。user/password:请按真实账户或"应用专用密码"填写。from_address:建议与user保持一致或在你所使用域名下的一个死信箱。
- 以上内容示例了最小化启用 SMTP 的方式,实际生产中可以保留
-
保存
grafana-provisioning/config/grafana.ini,确保文件权限正常且 Docker 进程可以读到它:ls -l grafana-provisioning/config/grafana.ini
3.1.2. 修改 Docker Compose,将自定义 grafana.ini 挂载进容器
假设你原来已有一个类似下面的 docker-compose.yml(含 Grafana 服务):
services:
grafana:
volumes:
# 这一行需要挂载我们自己的 grafana.ini:
- ./grafana-provisioning/config/grafana.ini:/etc/grafana/grafana.ini将以上 docker-compose.yml 放到 ~/grafana/ 目录下,调整好相对路径后,执行:
docker compose down # 如果 Grafana 已经在跑,先停掉
docker compose up -d # 再后台启动
docker exec -it grafana cat /etc/grafana/grafana.ini3.1.3. 验证 Grafana 内部是否正确加载了 SMTP 配置
-
查看 Grafana 容器日志,确认它没有报 "failed to load grafana.ini" 或者 "smtp disabled" 等错误:
docker logs grafana --tail 50如果看到开头有大段 "Starting Grafana ..." 然后没有特别的关于 SMTP 的 WARN/ERROR,就说明配置文件没问题。
-
进入 Grafana Web UI (假设地址为
http://<你的服务器IP>:3000),登录后:- 左侧菜单 → "Alerting" → "Contact points"(旧版面板可能在 "Alerting → Notification channels")
- 点击右上角 "New contact point"(或 "New channel")。
- 如果 SMTP 配置生效,当你选择 "Email" 这个类型时,表单下方不会出现 "SMTP is not configured" 的警告,而是可以直接填写邮箱相关字段(例如 "To" 地址等)。
-
填入收件地址,点击
Test, 验证邮箱是否能收到邮件, 通过后保存
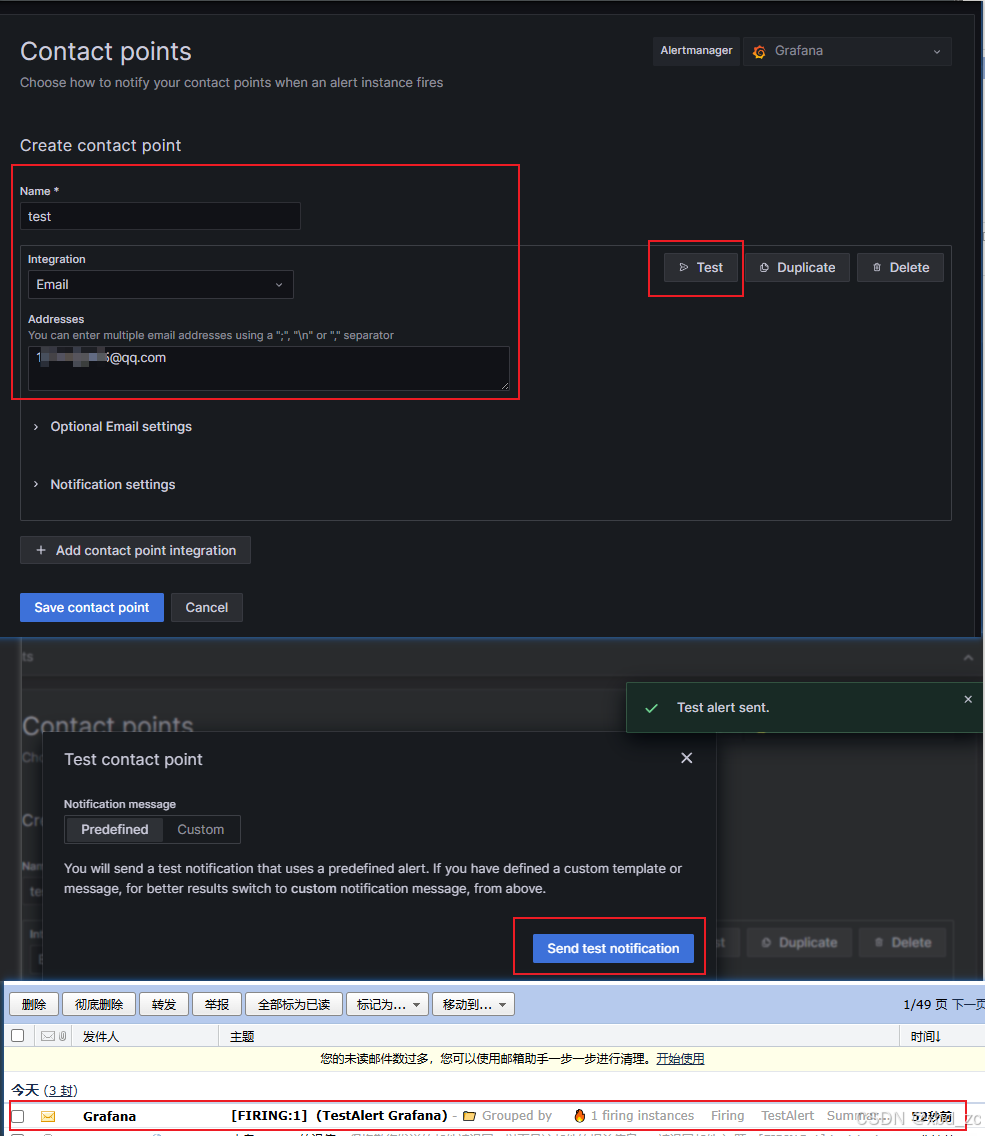
-
Notification policies通知策略默认选择刚创建的邮箱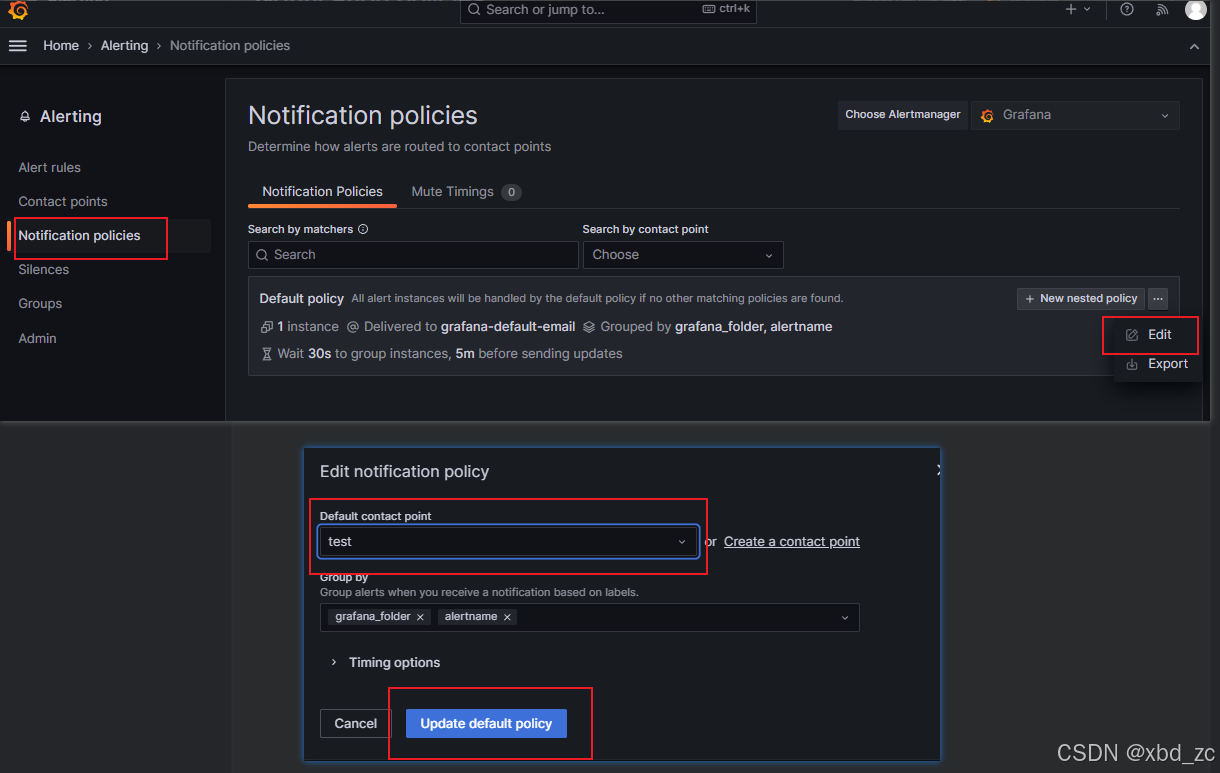
3.2、为关键面板添加告警(Alerting)
日志分析如果仅是"看"和"追踪",有时当问题发生时你才去察觉。更高级的做法是:
-
定位告警场景
- 例如"过去 5 分钟里 Tomcat 错误日志条数 > 10,就要发邮件/短信告警"。
- 或者 "syslog 里出现关键字 'CRITICAL' 超过 5 条,就要通知值班人员立即干预"。
-
在面板里创建 Alert 规则
-
打开某个面板(比如前面做的 Stat 面板,显示"过去 1 分钟内 Tomcat 错误日志条数"),点击右上角 **+**号。
-
Create alert rule ,新建一个告警:
-
Query:保留你当前的 LogQL Metric 查询,如
sum(count_over_time({host="host1", job="tomcat"}|detected_level="error" [1m])) -
如果你只在 Grafana 查询层用
| logfmt拆detected_level,那就只能按管道过滤#这里的level是在promtail-config-host1.yml配置的 - job_name: tomcat-host1 static_configs: - targets: [ localhost ] labels: job: tomcat host: host1 app: webapp __path__: /tomcat_logs/*.log pipeline_stages: - regex: expression: '^(?P<timestamp>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}.\d{3}) (?P<level>\w+)' - labels: level: -
条件(Condition):
IS ABOVE 10。 -
触发时:
Notification policies→ 选择你已配置好的通知渠道(Email、Slack、PagerDuty 等) -
测试是否有数据, 最近没有日志可以调时间范围, 如:1天
-
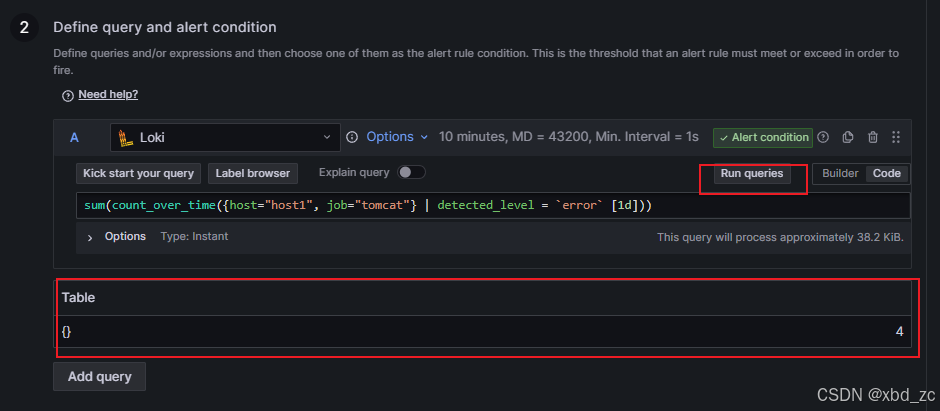
-
测试规则: 5分钟内10调info就触发
sum(count_over_time({host="host1", job="tomcat"} | detected_level = `info` [5m]))
-
-
保存告警后,只要指标持续超过阈值,Grafana 就会主动推送警报给你。
-
注意:
- Loki 原生对日志告警的支持是"基于 LogQL Metric"查询,所以你要先把"Error 日志条数"写成
count_over_time(...)这种 Metric,再去做阈值判断。- 如果你在 5 分钟内累积出现了 20 条错误,那么
count_over_time(...[5m])会在"此时" 直接返回 20,符合范围就报警。- 最好把告警面板放在仪表板最显眼的位置,比如第一行第一个格子,这样一目了然。
4. 常见问题 & 解决
4.1 Promtail 报 timestamp too old
- 原因 :采集到旧归档(
.gz)文件里的日志行,造成时间戳比 Lokireject_old_samples_max_age还要早。 - 解决 :
- 把
promtail-config-host1.yml中的__path__: /var/log/**/*.log改为只匹配.log,不含.gz; - 或者在
scrape_configs下加ignore_older: 24h,忽略超过 24 小时前修改的文件。
- 把
4.2 Alert Rule 报 "No data" 或 "failed to execute query"
- 常见原因 :在 Alert 编辑页没把查询模式切为 Metrics ,而是留在 Logs;
- 输入的 LogQL 语法写错,比如把
.Status写成.State; - 告警条件写成
IS ABOVE 0,但查询表达式返回的是 instant vector,需用sum(count_over_time(...))明确聚合成单值。 - 解决 :确保 Mode = Metrics ,Condition 中引用 query(A, 1m, now),并用
.Status而非.State;设置"无数据→OK、错误→Alerting"。
4.3 容器时区与宿主机不一致,导致日志时间错位
- 原因:默认 Docker 容器时区为 UTC,Promtail 采集时若不指定时区,可能把无时区后缀的日志当成 UTC 解析,造成时差。
- 解决 :
- 在所有关键容器(Promtail、Tomcat)里挂载
/etc/localtime:/etc/localtime:ro和/etc/timezone:/etc/timezone:ro; - 或者在 Promtail pipeline 中,用
timestamp阶段手动指定带有+0800的格式。
- 在所有关键容器(Promtail、Tomcat)里挂载
bash
docker run -d \
--name ry-tomcat \
-v /etc/localtime:/etc/localtime:ro \
-v /etc/timezone:/etc/timezone:ro \
-e TZ=Asia/Shanghai \
tomcat:9或在 docker-compose.yml 中配置:
yaml
services:
tomcat:
image: tomcat:9
volumes:
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
environment:
TZ: "Asia/Shanghai"4.4 Loki 启动报错:both grpc_client_config and (query_frontend_grpc_client or query_scheduler_grpc_client) are set
-
问题描述:使用 Loki 3.x 时出现如下错误,导致容器无法启动:
failed parsing config: both `grpc_client_config` and (`query_frontend_grpc_client` or `query_scheduler_grpc_client`) are set at the same time. -
原因分析:
- 在 Loki v3.0+ 中,模块间通信的配置方式有所改变;
- 你启用了
target=all单体模式,此时 不应再显式设置grpc_client_config; - 同时配置
grpc_client_config和新的query_frontend_grpc_client或query_scheduler_grpc_client会导致配置冲突。
-
解决方法:
-
如果使用
target=all单体模式(即 Loki 所有模块集中部署在一个进程中):- 删除 配置文件中
grpc_client_config:相关段落; - 让模块间使用内存自动通信,无需再显式配置 gRPC 客户端;
- 删除 配置文件中
-
示例修改前:
yamlquerier: frontend_worker: grpc_client_config: ...修改后:
yamlquerier: frontend_worker: frontend_address: 127.0.0.1:9095
-
-
建议:
- 使用
target=all模式时,配置应尽可能简洁; - 保持
frontend_address这类模块间引用,但移除grpc_client_config; - 或者使用 Loki 官方
local-config.yaml为基础,逐步扩展。
- 使用
4.5 仪表板面板无数据但Explore查询正常
问题现象:
- 在Grafana仪表板中添加新面板后显示"No data"
- 相同查询在Explore界面能正常返回数据
- 日志数据实际存在于Loki中
根本原因:
-
时间范围冲突:
- 仪表板使用固定时间范围(如
now-1h),而面板配置了不同的相对时间 - 示例:仪表板设置为
Last 6 hours,但面板覆盖为Last 15 minutes
- 仪表板使用固定时间范围(如
-
面板级数据源配置错误:
# 错误配置示例(使用未定义变量) datasource: $prometheus # 应该用具体数据源名 -
变量未设置默认值:
- 当查询使用
{app="$application"}时 - 变量
$application未设置默认值或默认值不匹配
- 当查询使用
-
面板缓存未刷新:
- Grafana未自动更新面板查询结果
解决方案:
-
检查时间范围:
- 编辑面板 → 右侧Time options → 关闭
Override relative time - 在仪表板右上角设置合理时间范围(推荐
Last 6 hours)
- 编辑面板 → 右侧Time options → 关闭
-
修正数据源配置:
- 编辑面板 → 查询编辑器底部 → Data source
- 直接选择
Loki(避免使用变量)
-
设置变量默认值:
yaml# 仪表板设置 → Variables - name: application query: label_values(app) default: webapp # 关键设置! -
强制刷新数据:
- 点击面板右上角 ⋮ → Refresh
- 浏览器按
Ctrl+Shift+R清除缓存
4.6 容器日志中缺失关键标签(如host)
问题现象:
- 在Grafana中无法通过
{host="host1"}过滤日志 label_values(host)返回空列表
排查步骤:
-
检查Promtail配置:
docker exec promtail_host1 cat /etc/promtail/config.yml # 确认static_configs中有host标签 -
验证标签注入:
curl -sG "http://loki:3100/loki/api/v1/series?match[]={job='syslog'}" | jq
解决方案:
yaml
- job_name: host_logs
static_configs:
- targets: [localhost]
labels:
host: host1 # 明确设置主机标签
job: syslog
__path__: /var/log/*.log4.7 Grafana日志面板显示原始JSON不解析
问题现象:
日志显示为完整JSON字符串:
{"time":"2023-01-01T12:00:00Z", "level":"error", "message":"Failed to connect"}解决方案:
-
添加解析管道:
pipeline_stages: - json: expressions: timestamp: time level: level msg: message - labels: level: # 提取为标签 -
Grafana字段提取:
-
在Explore或面板中:
{job="webapp"} | json -
点击 Detected fields → 选择要显示的字段
-
5. 小结
- Loki + Promtail + Grafana 提供了一个轻量级、可横向扩展的容器日志分析方案,适合云原生场景。
- 关键点在于:Promtail 负责采集并打标签,Loki 高效存储带标签的日志、Grafana 负责可视化与告警。
- 本文从两台服务器(host4、host1)端到端演示了:
- Docker Compose 快速部署 Loki 与 Promtail,挂载时区、排除旧日志、采集所有容器和系统日志;
- 在 Grafana 中创建多个面板:实时错误日志、Tomcat 非 Info 日志、日志源分布、动态变量、Top N 错误消息、日志量趋势等;
- 完整地将告警功能(SMTP 配置、Panel 告警规则)集成到 Grafana,达到主动通知运维的目的。
- 通过"常见问题 & 解决"部分,将遇到的各类坑点(时间戳过旧、Alert Rule 无数据、邮件模板失效、容器时区不同步)一并列出,方便以后快速排查。
后续优化思路:
- 将 Loki 存储由本地文件系统切换到 S3/GCS,提高可扩展性与持久化能力。
- 在 Promtail 端对日志做更细粒度的 pipeline 处理(如 geoip、user-agent 解析),把有价值的字段提前打成 labels。
- 利用 Grafana 的高级 Dashboard 功能(变量联动、模板化面板),实现多机房、多环境一键切换。
- 将告警规则提取到 Loki Ruler 或 Alertmanager,做更灵活的分组路由与抖动策略。