一、 消息队列的本质价值与核心特性
1.1 分布式系统的"解耦器"
- 异步通信模型
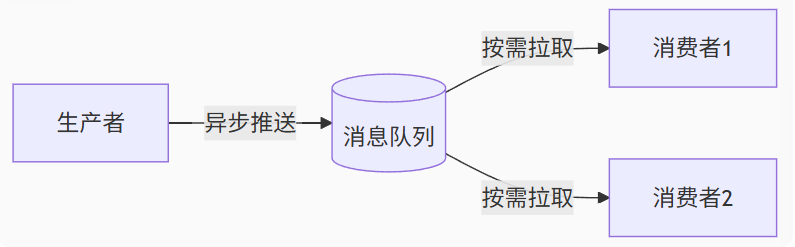
-
代码列表
graph LR
A[生产者] -->|异步推送| B[(消息队列)]
B -->|按需拉取| C[消费者1]
B -->|按需拉取| D[消费者2] -
生产者发送后立即返回,消费者以自己的节奏处理消息。
-
典型场景:电商订单创建后,通知库存系统扣减(无需堵塞主流程)
流量削峰实证
|---------|-------------|-------------|------------|
| 场景 | 无MQ QPS | 有MQ QPS | 资源成本 |
| 突发流量10倍 | 系统崩溃 | 稳定5000 | 服务器↓60% |
| 持续高负载 | 响应延迟>2s | 延迟<200ms | 数据库连接池↓80% |
1.2 数据可靠性的"保险箱"
-
持久化机制
Kafka消息存储结构
topic-order-0/
├── segment-0001.index # 索引文件(偏移量→物理位置)
├── segment-0001.log # 数据文件(存储实际消息)
└── segment-0002.log # 新消息追加写入 -
写入策略:先写Page Cache再异步刷盘(兼顾性能与安全)
-
保留策略:支持基于时间(默认7天)或大小(1GB/段)的滚动删除
端到端可靠性保障
|---------------|-----------------|----------|----------|
| 保证级别 | 配置方式 | 性能影响 | 适用场景 |
| At Most Once | ack=0 | 最高 | 日志收集 |
| At Least Once | ack=all + 幂等生产者 | 中等 | 支付订单 |
| Exactly Once | 事务API + 读已提交隔离级 | 最低 | 金融交易 |
二、 Kafka架构设计精析
2.1 核心组件协作模型
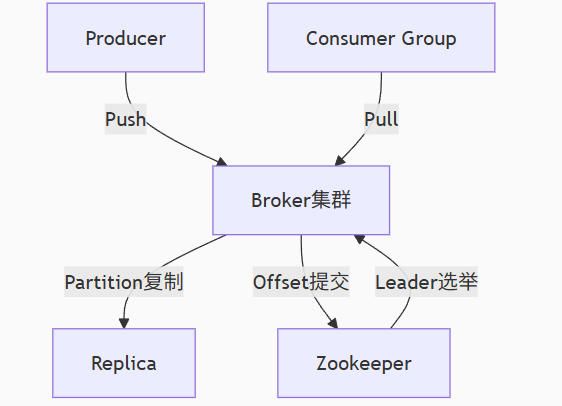
代码列表
graph TB
P[Producer] -->|Push| B[Broker集群]
B -->|Partition复制| R[Replica]
Z[Zookeeper] -->|Leader选举| B
C[Consumer Group] -->|Pull| B
B -->|Offset提交| Z2.2 Partition设计哲学
分区策略的工程智慧
// 生产者分区选择代码示例
int partition = key != null ?
hash(key) % numPartitions : // Key哈希分区(保证相同Key有序)
roundRobinSelector.next(); // 轮询分区(负载均衡)- **一致性Hash:**订单ID→固定分区,确保相同订单操作顺序性
- **轮询策略:**日志采集场景避免数据倾斜
分区数量黄金法则
*最佳实践公式:
Partition数 = max(
ConsumerGroup中消费者数量 × 3,
集群Broker数量 × 2,
预期吞吐量 ÷ 单分区限速(10MB/s)
)*
2.3 高性能内核揭秘
- 顺序写磁盘性能对比
|----------|---------------|----------|-----------|
| 写入方式 | 吞吐量(MB/s) | IOPS | 磁盘利用率 |
| 随机写HDD | 0.8-1.2 | 80-120 | >90% |
| 顺序写HDD | 120-160 | 12k-16k | <30% |
| NVMe SSD | 3000+ | 500k + | <10% |
-
零拷贝技术实现
// Linux系统调用实现零拷贝
sendfile(out_fd, in_fd, offset, count);
传统4次拷贝 vs 零拷贝2次拷贝:
- 用户态->内核态->网卡 (省去2次内核态拷贝)
- 磁盘->内核缓存->用户缓存->Socket缓存->网卡
三、 Zookeeper的分布式协调艺术
3.1 脑裂问题的终极解决方案
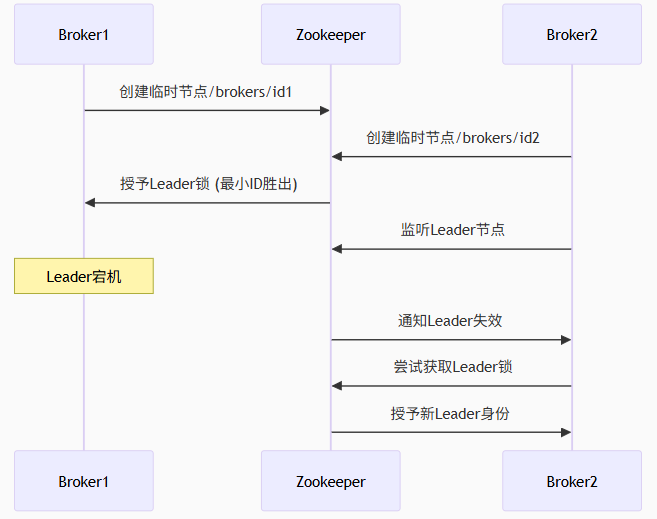
代码列表
sequenceDiagram
participant B1 as Broker1
participant ZK as Zookeeper
participant B2 as Broker2
B1->>ZK: 创建临时节点/brokers/id1
B2->>ZK: 创建临时节点/brokers/id2
ZK->>B1: 授予Leader锁 (最小ID胜出)
B2->>ZK: 监听Leader节点
Note over B1: Leader宕机
ZK->>B2: 通知Leader失效
B2->>ZK: 尝试获取Leader锁
ZK->>B2: 授予新Leader身份3.2 Kafka对ZK的深度依赖
|---------------------------|------------|----------|--------------|
| ZK节点路径 | 数据类型 | 生命周期 | 关键作用 |
| /brokers/ids/ 0-n | Ephemeral | 会话级 | Broker在线状态检测 |
| /brokers/topics/order | Persistent | 持久化 | Topic分区分布拓扑 |
| /consumers/group1/offsets | Persistent | 持久化 | 消费进度Offset跟踪 |
| /amdin/delete_topics | Persistent | 持久化 | Topic删除请求队列 |
3.3 ZAB协议的精妙设计
两阶段提交优化
# ZAB协议伪代码
def write_request(data):
leader.propose(data) # Phase1: 广播提案
if quorum.accepted(): # 获取多数派确认
leader.commit(data) # Phase2: 提交写入
return "SUCCESS"
else:
return "FAILURE"对比Raft协议:
|--------|-----------|-----------|-------------|
| 特性 | ZAB | Raft | 差异点 |
| 选举速度 | 200-500ms | 150-400ms | ZAB更注重数据连续性 |
| 日志复制 | 主从流水线 | 并行复制 | Raft吞吐更高 |
| 成员变更 | 受限 | 动态 | Raft更灵活 |
四、 生产者与消费者深度机制
4.1 生产者负载均衡策略对比
|----------|--------------------|-----------|----------------|
| 策略类型 | 实现方式 | 优点 | 缺点 |
| 四层负载 | IP哈希+固定映射 | 连接数少,简单 | 无法感知Broker动态变化 |
| ZK动态发现 | 监听/brokers/ids节点变化 | 实时负载均衡 | 增加ZK压力 |
| 客户端分区感知 | Producer内置元数据缓存 | 最快响应,去中心化 | 首次启动需ZK初始化 |
4.2 消费者组状态机模型
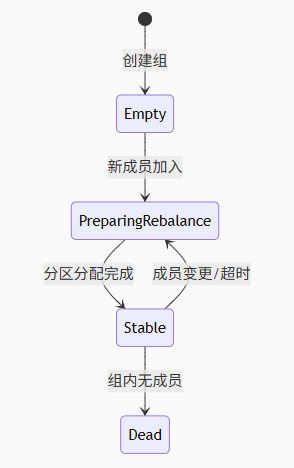
- 重平衡(Rebalance)成本分析
|----------|-----------|----------|
| 集群规模 | 重平衡耗时 | 业务影响 |
| 100分区 | <1s | 几乎无感知 |
| 10000分区 | 8-15s | 短时消费暂停 |
解决方案
静态成员 ↓70%耗时 需Kafka 2.3 +
增量重平衡 ↓90%暂停 需Kafka 2.4 +
五、 集群部署的工程实践
5.1 硬件规划黄金法则
|----------|------------------------|---------------------------|
| 资源类型 | 计算公式 | 示例(1TB/天吞吐) |
| Broker数量 | (总吞吐÷单Broker限速)×1.5 | (100MB/s ÷ 50MB/s)×1.5 =3 |
| 磁盘容量 | 数据量×副本数×1.3 | 1TB×3×1.3 = 4TB |
| CPU核心 | 每Broker: 分区数÷50 | 200分区 ÷ 50 = 4核 |
| 内存 | 每Broker:1GB+(分区数×50MB) | 1GB+(200×50MB)=11GB |
5.2 关键配置调优指南
# server.properties 核心参数
num.network.threads=32 # 网络线程数 ≈ 磁盘数×3
num.io.threads=64 # IO线程数 = CPU核数×8
log.flush.interval.messages=10000 # 刷盘消息数阈值
log.retention.hours=168 # 保留7天
compression.type=snappy # 压缩比≈40%, CPU消耗低5.3 集群扩展的优雅方案
-
横向扩展(Scale-out)流程
步骤1:滚动添加新Broker
bin/kafka-server-start.sh config/server-new.properties
步骤2:迁移分区(无停机)
bin/kafka-reassign-partitions.sh --topics-to-move-json-file topics.json
--broker-list "0,1,2,3" --execute
迁移前后对比:
|--------|---------|---------|--------|
| 指标 | 迁移前 | 迁移后 | 提升 |
| 总吞吐 | 80MB/s | 120MB/s | 50%↑ |
| 磁盘使用率 | 90% | 65% | 均衡化 |