zk3.9.2版本集群
说明
- 本文是基于一台服务器搭建zk集群的记录
- zk集群是主从架构
- 分别创建三个目录模拟三个节点
- 只要有半数以上节点存活,zk 集群就能正常服务,适合安装奇数台
下载
- 下载地址
- 选择版本3.9.2
解压&创建目录
- tar -zxvf zookeeper-3.9.2.tar.gz -C 12181/
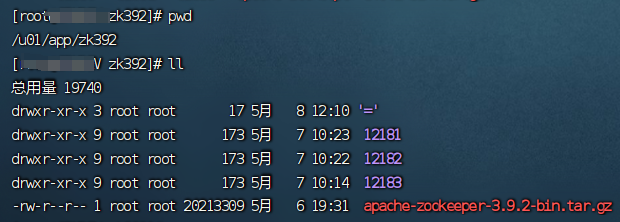
- 创建zkdata/zklogs目录

创建myid
-
配置节点(服务器)编号
-
在 /zkData 中,创建文件 myid(必须叫 myid,源码读取的文件是 myid)
echo 1 > /u01/app/zk392/12181/zkdata/myid echo 2 > /u01/app/zk392/12182/zkdata/myid echo 3 > /u01/app/zk392/12183/zkdata/myid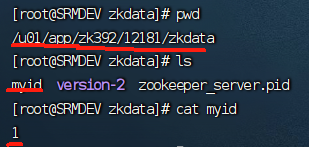
配置zoo.cfg
server.A=B:C:D 参数
- A 是一个数字,表示这个是第几号服务器;就是 myid中的值
- B:是服务器的主机名或 IP 地址
- C 当集群启动或 leader 崩溃时,各节点通过此端口进行投票选举新leader
- D 用于 leader 与 follower 之间的数据同步和复制端口
zk1
clientPort=12181
admin.serverPort=18081 # admin.serverPort 默认占8080端口
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
server.2=127.0.0.1:12887:13887
server.3=127.0.0.1:12888:13888
server.4=127.0.0.1:12889:13889zk2
clientPort=12182
admin.serverPort=18082 # admin.serverPort 默认占8080端口
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
server.2=127.0.0.1:12887:13887
server.3=127.0.0.1:12888:13888
server.4=127.0.0.1:12889:13889zk3
clientPort=12183
admin.serverPort=18083 # admin.serverPort 默认占8080端口
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
server.2=127.0.0.1:12887:13887
server.3=127.0.0.1:12888:13888
server.4=127.0.0.1:12889:13889启停
/u01/app/zk392/12181/bin/zkServer.sh stop; /u01/app/zk392/12182/bin/zkServer.sh stop;/u01/app/zk392/12183/bin/zkServer.sh stop;
/u01/app/zk392/12181/bin/zkServer.sh start; /u01/app/zk392/12182/bin/zkServer.sh start;/u01/app/zk392/12183/bin/zkServer.sh start;
/u01/app/zk392/12181/bin/zkServer.sh status; /u01/app/zk392/12182/bin/zkServer.sh status;/u01/app/zk392/12183/bin/zkServer.sh status;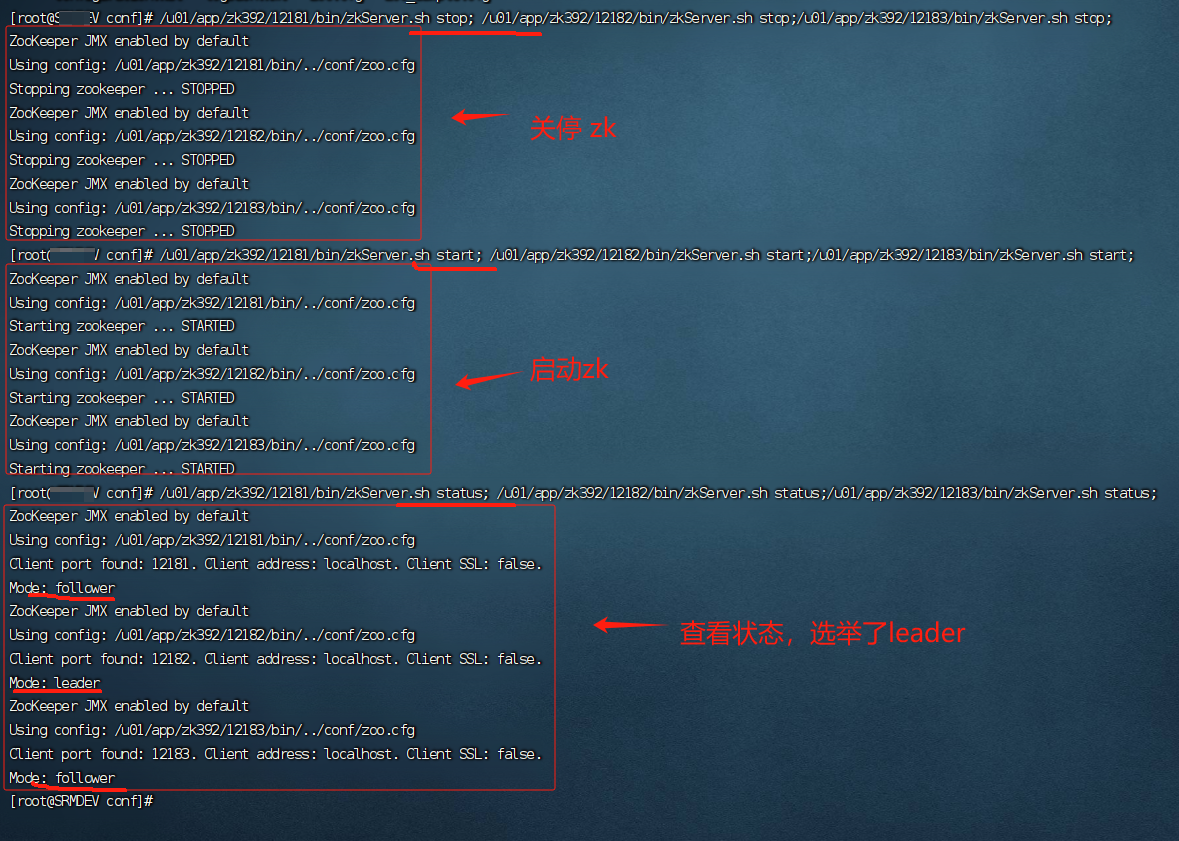
从读写步骤看主从
- zk集群是主从架构
- 但此主从,能做到从节点转为主的恢复
- 主节点的写入,也需要得到半数从节点成功写入的反馈
写
- 所有写操作必须通过 Leader 处理
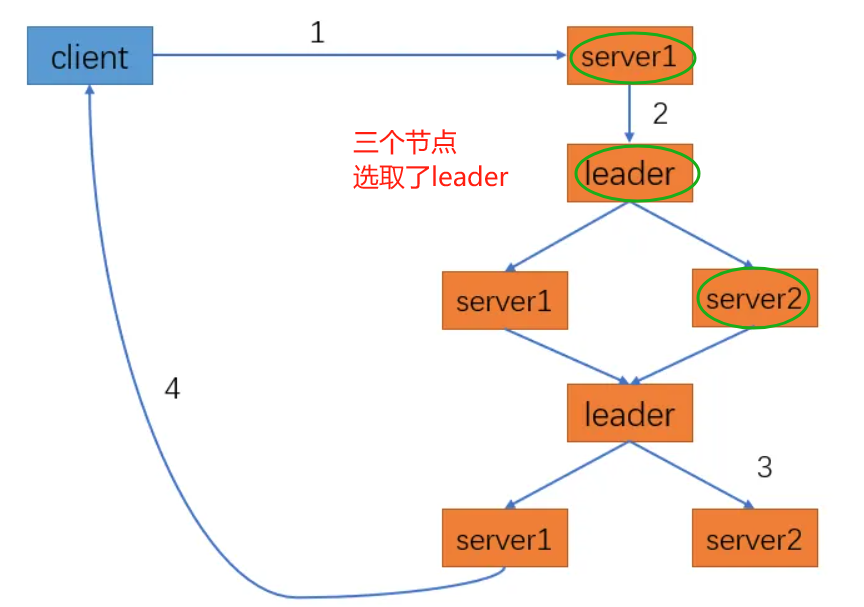
- client向zookeeper的server1发送一个写数据请求
- server1不是leader,server1把接收到的请求转发给leader
- leader将写数据请求广播给各个server,如server1和server2,各个server会将写数据请求加入待写队列,并回复leader
- 当leader收到半数以上server的成功信息,说明该写操作可以执行
- leader会向各个server发送提交信息
- 各个server收到信息后会落实队列里的写数据请求,写数据成功
- server1会进一步通知client写数据成功,这时认为整个写操作成功