前言:
上次介绍完二叉搜索树后,更新中断了一段时间,先向大家致歉。最近学习状态有些起伏,但我正在努力调整,相信很快会恢复节奏。今天我们继续深入探讨------关联容器,它在算法和工程中都非常常见和重要。
1.之前的遗漏
我之前写的二叉搜索树其实没有写完,我仅仅写了一个节点只能存储一个值的二叉搜索树。在我们日常的工作中,这种树的使用率其实还是比较低的。最受欢迎的是里面存储两个值的二叉搜索树,这个可以类比Python中的字典。相信学过python的读者对此不陌生,字典其实存放了一对值,分别是Key和Value,类比英文字典中的英语和汉字,我们通过英文(Key)来找到对应的中文(Value)。这其实才是我们常使用到的二叉搜索树,下面我通过举例来帮助各位理解这两棵树的区别。
1.1.Key搜索场景
举个例子,现在很多小区配有地下停车库。业主的车牌号会录入系统中,车辆进入时由系统识别并判断是否允许进入。这就是典型的 Key 搜索场景 ------ 只需根据一个关键字(车牌号)进行查找。
1.2.Key/Value搜索场景
还是以我们的生活举例,如今我们进入各大商场的时候,如果开车的话难免会需要停进商场专用的停车场,此时这就是停车场计费系统,我们需要录入两个值:车子的车牌号以及入场时间,记录好之后,当车辆想要离开停车场的时候,就会通过车牌(Key)来进行系统中管理的车辆信息进行检索,检索成功后会根据当前的时间减去入场的时间计算出车辆在停车场呆过的时间,从而计算出需要交付的金额。这边是Key/Value的搜索场景,Key其实不是关键,其中的Value才是关键,Key更像是一个标识符,我们通过这个符号来进行真正数据的获取。所以可以看出,它在我们日常的生活中使用的频率更大。
1.3.Key/Value类型的二叉搜索树的源码
由于难度不大,小编就不讲其中的细节了,其实它和上篇我们讲述的Key类型的二叉搜索数一样,只不过多了一个Value而已。
cpp
#include<iostream>
#include<vector>
using namespace std;
template<class K, class V>
struct BSTNode
{
// pair<K, V> _kv;
K _key;
V _value;
BSTNode<K, V>* _left;
BSTNode<K, V>* _right;
BSTNode(const K& key, const V& value)
:_key(key)
, _value(value)
, _left(nullptr)
, _right(nullptr)
{}
};
template<class K, class V>
class BSTree
{
typedef BSTNode<K, V> Node;
public:
BSTree() = default;
BSTree(const BSTree<K, V>& t)
{
_root = Copy(t._root);
}
BSTree<K, V>& operator=(BSTree<K, V> t)
{
swap(_root, t._root);
return *this;
}
~BSTree()
{
Destroy(_root);
_root = nullptr;
}
bool Insert(const K& key, const V& value)
{
if (_root == nullptr)
{
_root = new Node(key, value);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
return false;
}
}
cur = new Node(key, value);
if (parent->_key < key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}
Node* Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
cur = cur->_right;
}
else if (cur->_key > key)
{
cur = cur->_left;
}
else
{
return cur;
}
}
return nullptr;
}
bool Erase(const K& key)
{
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
if (cur->_left == nullptr)
{
if (parent == nullptr)
{
_root = cur->_right;
}
else
{
if (parent->_left == cur)
parent->_left = cur->_right;
else
parent->_right = cur->_right;
}
delete cur;
return true;
}
else if (cur->_right == nullptr)
{
if (parent == nullptr)
{
_root = cur->_left;
}
else
{
if (parent->_left == cur)
parent->_left = cur->_left;
else
parent->_right = cur->_left;
}
delete cur;
return true;
}
else
{
Node* rightMinP = cur;
Node* rightMin = cur->_right;
while (rightMin->_left)
{
rightMinP = rightMin;
rightMin = rightMin->_left;
}
cur->_key = rightMin->_key;
if (rightMinP->_left == rightMin)
rightMinP->_left = rightMin->_right;
else
rightMinP->_right = rightMin->_right;
delete rightMin;
return true;
}
}
}
return false;
}
void InOrder()
{
_InOrder(_root);
cout << endl;
}
private:
void _InOrder(Node* root)
{
if (root == nullptr)
{
return;
}
_InOrder(root->_left);
cout << root->_key << ":" << root->_value << endl;
_InOrder(root->_right);
}
void Destroy(Node* root)
{
if (root == nullptr)
return;
Destroy(root->_left);
Destroy(root->_right);
delete root;
}
Node* Copy(Node* root)
{
if (root == nullptr)
return nullptr;
Node* newRoot = new Node(root->_key, root->_value);
newRoot->_left = Copy(root->_left);
newRoot->_right = Copy(root->_right);
return newRoot;
}
private:
Node* _root = nullptr;
};以上便就是对上节课知识点的补充,下面我们就进入本文章正式的部分。
2.序列式容器和关联式容器
想必各位读者看我文章的题目时,会有疑问:关联式容器是什么玩意?其实很好理解,它的名字就点出了这个容器一个重要的特性:这个容器的数据应该是有关联性!下面我就分别说说序列式容器和关联式容器
1.序列式容器
小编在之前讲述了很多STL的容器,就比如:vector,list,dequeue,array等等,这些有个统一的名称:序列式容器,因为他们的逻辑结构是线性的,相邻两个位置存储的元素一般是没有关联的,如果我们把第一个元素和最后一个元素交换之后,它还是序列式容器。顺序容器中的元素是按他们在容器中的存储位置来顺序保存和访问的。
2.关联式容器
关联式容器也是用来存储数据的容器,和序列式容器不同的是,关联式容器的逻辑结构通常是非线性的,它存储的两个元素是有很强的关联关系的(map就是),如果我们把两个位置的元素进行交换,那么存储结构就被破坏了。顺序容器中的元素是按关键字来保存和访问的。关联式容器有map/set系列,后续也有一个系列也是关联式容器,这里我先浅浅的卖个关子,等到后期再给各位揭开谜底。
3.set容器的使用
3.1.set类的介绍
首先我们先进行set容器的讲解,因为它对比map容器,它的很多功能都是很简单的。它对应的是Key版本的二叉搜索树,这就说明这个容器存储的就是仅仅带有关键字的容器,我们可以看一下set源码的声明。
cpp
template < class T, // set::key_type/value_type
class Compare = less<T>, // set::key_compare/value_compare
class Alloc = allocator<T> // set::allocator_type
> class set;其中的T代表着set存储的类型,第二个参数代表着一个仿函数:这个仿函数是进行大小比较的,默认less代表着set所代表的树存储的值是左边比右边小;第三个是空间分配器,这个目前可以忽视。这边是set的声明,一般的情况下,后面两个我们一般用不上,用默认的就好。
容器的讲解我们往往会涉及到底层,set的底层其实是我们之后要学习的红黑树学习的,这是一颗比二叉搜索树还牛逼的一种树,set增删查改的效率是O(logN),容器的遍历是走的中序遍历,所以我们存入数据后,遍历一遍得到的数据为一组有序的数据。这些都是set的基础知识,各位了解就好,下面我们进入更加重要的部分:相关接口的介绍。
3.2.相关的接口
1.构造函数
对于一个容器,我们最先讲的自然就是如何构建它,所以构建函数的介绍往往是容器介绍的开始,下面小编分别说说他的构造函数。
1.无参构造
这个比较简单,我们仅需定义好set类型对象的名字即可,下面我们先来看一下关于其源码中构造函数是如何进行声明的。
cpp
// empty (1) ⽆参默认构造
explicit set (const key_compare& comp = key_compare(),
const allocator_type& alloc = allocator_type());其用法如下:
cpp
std :: set<int> s1; //这个存储的int类型的对象2.迭代器区间构造
cpp
// range (2) 迭代器区间构造
template <class InputIterator>
set (InputIterator first, InputIterator last,
const key_compare& comp = key_compare(),
const allocator_type& = allocator_type());相对于无参构造,迭代器区间构造使用的比较多一些,它的用法和vector迭代器区间构造是类似的,在这里我就不详细介绍了,您只需知道,此时这个的区间构造类似于vector就好,下面我展示它的用法:
cpp
std :: set<int> s1({12,34,13,54,77});
3.值得注意的点对了,小编刚才忘记讲了,set和小编之前实现的二叉搜索树一样,它不支持相同的值插入(即不支持值冗余),所以当我们插入相同的值的时候,它就会覆盖相同的值。这点请记住,如果想要冗余,那么就需要用到另一个类似set的容器------multiset,这个小编不打算精讲,文章末我可能会讲述。
4.拷贝构造函数
有构造函数,自然需要用到拷贝构造函数,如果没有拷贝构造函数的话,那么我们就只能浅拷贝,浅拷贝往往会造成不可逆的错误,就比如析构同一块空间等等,当然,这里涉及的知识点我之前讲过,现在讲就当温故而知新了,下面看看源码中拷贝构造函数的声明。
cpp
// copy (3) 拷⻉构造
set (const set& x);此时我们仅需把一个set类型的对象传给另一个需要拷贝构造的对象即可,这部分与前述类似,读者可参考 vector 使用方法。
cpp
std :: set<int> s1({1,2,43,4,5,13});
std :: set<int> s2 = s1; //或者是s1(s2) 这样我认为比较low,不优美5.列表构造
cpp
// initializer list (5) initializer 列表构造
set (initializer_list<value_type> il,
const key_compare& comp = key_compare(),
const allocator_type& alloc = allocator_type());在使用 C++ 中的 set 类进行列表构造时,实际上涉及到了拷贝构造函数和构造函数的相关知识。此时,我们可以通过使用一个用花括号 {} 包裹的初始化列表,其中包含我们希望插入到 set 中的元素。该初始化列表会作为参数传递给 set 的构造函数,从而构造出对应的 set 对象。最后通过拷贝构造给予我们定义的对象
cpp
std :: set<int> s1 = {1,2,43,4,5,13}; //这个用法其实走了一层拷贝构造函数以及构造函数,具体怎么走的,我会在后来的文章说明的2.迭代器
set 容器的迭代器是一个双向迭代器,这一点可能让不少读者产生疑惑:"啥是双向的?是不是能倒车?"别急,我们先来理一理 C++ 中迭代器的"家族谱系",搞清楚它们的"社会阶层",你就明白了。
🧭 C++ 迭代器的五大家族
C++ 标准库中,迭代器被按功能划分为以下五类,从"最低级搬砖工"到"全能打工人"不等:
-
输入迭代器(Input Iterator)
-
只能向前走一步,看一眼数据,过目即忘。
-
常用于只读算法,如
std::istream_iterator。
-
-
输出迭代器(Output Iterator)
-
也是只能向前走,但它不读,只写。
-
比如
std::ostream_iterator。
-
-
前向迭代器(Forward Iterator)
-
可以多次读写,也可以反复访问一个位置,但依旧只能往前。
-
比如
std::forward_list的迭代器。
-
-
双向迭代器(Bidirectional Iterator)
-
可以前进,也可以后退,一进一退如跳探戈。
-
std::set、std::list等容器的迭代器就属于这一类。
-
-
随机访问迭代器(Random Access Iterator)
-
简直就是迭代器界的"高铁"------不仅能前后移动,还能跳跃式访问任意位置。
-
std::vector、std::deque、原始数组用的就是它。
-
所以,set 的迭代器虽不能瞬间跳到任意元素(它不是"随机访问"的),但能前能后,足以在容器中灵活地来回走动,适合遍历和查找等操作。别看它不会飞,但在平稳可靠这方面,表现还是相当不错的!
下面我们来看一下set迭代器的源码的声明------
cpp
iterator -> a bidirectional iterator to const value_type因为set是双向迭代器,所以它是有我们熟悉的四个迭代器相关的接口:begin()、end()【正向迭代器】、rbegin()、rend()【反向迭代器】,它的用法其实和我们之前容器的使用方法是一样的,下面我通过一个简单的例子来给各位展现它们的用法:
正向迭代器:
cpp
set<int> s1 = { 12,4,3,5,6,89 };
auto it = s1.begin();
while (it != s1.end())
{
cout << *it << " ";
it++;
}
//运行后的结果:
3 4 5 6 12 89 //可以看出set其实是自带排序的,符合我们之前二叉搜索树中序具有排序的功能反向迭代器:
cpp
set<int> s1 = { 12,4,3,5,6,89 };
auto it = s1.rbegin();
while (it != s1.rend())
{
cout << *it << " ";
it++;
}
//运行后的结果
89 12 6 5 4 3想必各位已经知晓了关于set一些基础功能的认识,下面我们进入容器重要的部分------增删查(没有改)的讲解~
3.set的增删查
1.关于为啥没有改
这个问题可以追溯到 set背后的底层结构------二叉搜索树(Binary Search Tree,BST) 。在这种数据结构中,节点的排列遵循特定的规则:左子树中的所有节点小于根节点,右子树中的所有节点大于根节点 。正是由于这种有序的结构,set 才能高效地进行查找、插入和删除操作。
然而,一旦我们随意修改了某个元素的值,就可能破坏这种排序关系,使整棵树变得不再符合二叉搜索树的性质。比如,把一个本应在左子树的值变成了比根节点还大,那它就"走错片场"了。这不仅会导致查找失效,还可能引发更严重的逻辑错误。
因此,为了保持有序性和数据结构的完整性,std::set 不允许通过迭代器或引用来修改其中元素的值 。这是语言层面对"动了树根就塌房"的一种预防机制。就像盖了一栋讲究结构力学的别墅,你不能随手把承重墙给拆了。同样地,set 中的元素一旦被随意修改,整棵"树"可能就要歪了。C++ 为了不让你干这种"拆墙"的事,干脆一开始就不给你锤子:禁止修改元素值。
2.增相关接口
1.单个数据的插入
cpp
// 单个数据插⼊,如果已经存在则插⼊失败
pair<iterator,bool> insert (const value_type& val);这里涉及的pair各位先不用较真,关于pair,我会在之后的map讲解中详细讲述它,因为set用到它的时候真的不多,至于为什么它也会有pair类型,这里涉及到红黑树实现set时我会详细说的(不知不觉又埋了一个坑)。
其实源码就解释了set为什么会有去重的操作,因为当我们插入相同元素的时候,它不会插入,第二个模版参数会变成false,下面小编简单展示它的用法。
cpp
set<int> s1;
s1.insert(1);
s1.insert(13);
s1.insert(12);
s1.insert(32);
//s1里面存储的:
1 12 13 322.列表插入
cpp
// 列表插⼊,已经在容器中存在的值不会插⼊
void insert (initializer_list<value_type> il);列表插入的原理其实和列表构造差不多,里面的类型就是一个列表,它的实现会在后续文章体现,这里小编就不详细讲述了。老规矩,我还是通过一个例子来给各位展示用法。
cpp
set<int> s1;
s1.insert({1,13,12,32});
//存储结果同上:
1 12 13 323.迭代器区间插入
cpp
// 迭代器区间插⼊,已经在容器中存在的值不会插⼊
template <class InputIterator>
void insert (InputIterator first, InputIterator last);它的用法也是和之前的容器类似,所以小编直接上用例了。
cpp
set<int> s1;
s1.insert({1,13,12,32});
set<int> s2;
s2.insert(s1.begin(), s1.end());
//里面存储的还是和上面的一样以上就是关于set的增相关接口的介绍,其实还是蛮简单的。
2.查相关接口
1.查找并且返回相应迭代器
cpp
// 查找val,返回val所在的迭代器,没有找到返回end()
iterator find (const value_type& val);它的用法也是和之前容器一样,这里我就不多赘述了,下面我通过两个例子分别展示它的用法。
cpp
set<int> s1;
s1.insert({ 1,13,12,32 });
auto it = s1.find(1);
cout << *it << endl;
//结果是:
//1
set<int> s1;
s1.insert({ 1,13,12,32 });
auto it = s1.find(111);
cout << *it << endl;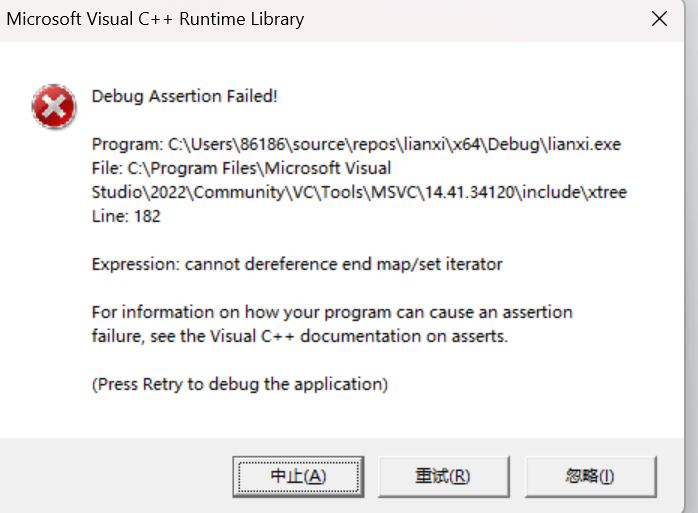
通过上图就可以知道如果find里面要查的结果对象没有,那么是会返回end()的,编译的时候是没有什么问题,因为语法没有错误,但是当我们运行,程序直接就崩溃了~
2.查找并返回相应的迭代器
cpp
// 查找val,返回Val的个数
size_type count (const value_type& val) const;可能很多读者到这就像吐槽小编:oi,狗小编,你不是说set里面的元素仅仅可以存放一个吗?那还整什么 count 函数?你这不是忽悠人吗?"别急别急,听我慢慢说。虽然 std::set 是一个集合 ,每个元素最多只能出现一次 ,但 count 函数依然不是"多余的"。
set.count(x) 的作用就是:判断元素 x 是否存在于集合中。
-
如果存在,返回
1; -
如果不存在,返回
0。
是的,它最多只能返回 1,但这其实就足够用了。虽然 set 里每个元素只出现一次,但 count() 就像是一个"有没有"检查器,不是统计重复,而是确认存在。它不是没用,而是刚刚好!
关于它的用法我就不在多展示了,和上面一样,这里先透露一下后面的内容:后面一个算法题是会用到它的哦~
3.删相关接口
1.根据迭代器删除值
cpp
// 删除⼀个迭代器位置的值
iterator erase (const_iterator position);此时虽然我们已经删除了相应位置的值,但是我们依然会返回删除值的迭代器,如果返回的是一个end()类型的迭代器,证明我们要删除的值不存在;这个接口最好搭配着find接口一起食用,下面给出例子。
cpp
set<int> s1;
s1.insert({ 1,13,12,32 });
s1.erase(s1.find(13));
//很轻易2.根据值删除
cpp
// 删除val,val不存在返回0,存在返回1
size_type erase (const value_type& val);这个接口我们还是比较时常实用的,因为迭代器还是比较繁琐的用起来,不过每个人有每个人的爱好,下面我直接展示用法:
cpp
set<int> s1;
s1.insert({ 1,13,12,32 });
s1.erase(13);
//很轻易3.删除一段迭代器区间的值
cpp
// 删除⼀段迭代器区间的值
iterator erase (const_iterator first, const_iterator last);这就是删除⼀段迭代器区间的值 iterator erase (const_iterator first, const_iterator last);经典左闭右开区间,难度不大,下面我给出一个例子讲解。
cpp
std::set<int> s = {1, 2, 3, 4, 5, 6};
auto it1 = s.find(2);
auto it2 = s.find(5);
s.erase(it1, it2); // 删除 2、3、4以上就是关于set相关接口的介绍,下面为了各位更好的掌握set的用法,小编特意准备了一个算法题来帮助各位了解set在算法的使用。
4.一个算法题
✅ 题目 1:判断数组中是否存在重复元素
描述: 给定一个整数数组,判断其中是否存在重复元素。如果存在至少一个值出现至少两次,返回 true;如果数组中每个元素都不相同,返回 false。
示例:
cpp复制编辑输入: [1, 2, 3, 4]
输出: false
输入: [1, 2, 3, 1]
输出: true解法提示: 使用 std::set 自动去重的特性。
本题的解法其实也是蛮容易的,不知道上面的内容各位读者是否认真阅读了,小编在文章某个位置曾经说过,set是具有去重的能力的,此时我们就可以用到这个特性进行题目的解答。具体的步骤小编就不细说了,如果有看不懂的朋友可以加一下文末小编的微信,小编会给出解答的。
cpp
bool containsDuplicate(std::vector<int>& nums) { //这个题目应该来自力扣~
std::set<int> s;
for (int num : nums) {
if (s.count(num)) return true;
s.insert(num);
}
return false;
}5.总结
set 是一个强大、高效、自动排序且不允许重复的关联容器,适用于需要快速查找、无重复数据的场景,其底层红黑树结构保证了优秀的性能表现。如果你理解了 set,那么恭喜你,迈出了 STL 关联容器的重要一步。接下来的 map 与 multiset、multimap 都会更加清晰易懂!
下节内容,我们将正式进入 map 的世界。作为 C++ STL 中最常用的键值对容器,map 的应用远比 set 更广泛,我们会重点解析其底层结构、插入/查找机制以及使用技巧,敬请期待!
本篇文章就到这里,各位大佬我们一篇文章见啦!
