Apache Druid 是一个为实时分析和大规模数据集设计的分布式数据存储系统。本文将深入解析 Druid 的架构设计,探讨其各个组件的功能与交互方式,帮助您理解如何利用 Druid 构建高性能的数据分析平台。

一、Druid 架构概述
Druid 采用分布式架构设计,专为云环境优化,具有高度可操作性和灵活性。其核心设计理念包括:
- 服务独立性与可扩展性:各组件可独立配置和扩展
- 增强的容错能力:单点故障不会导致整个系统瘫痪
- 高效的数据摄取与查询:优化的流式处理和批处理能力
下图展示了 Druid 的主要服务组件及其交互关系:
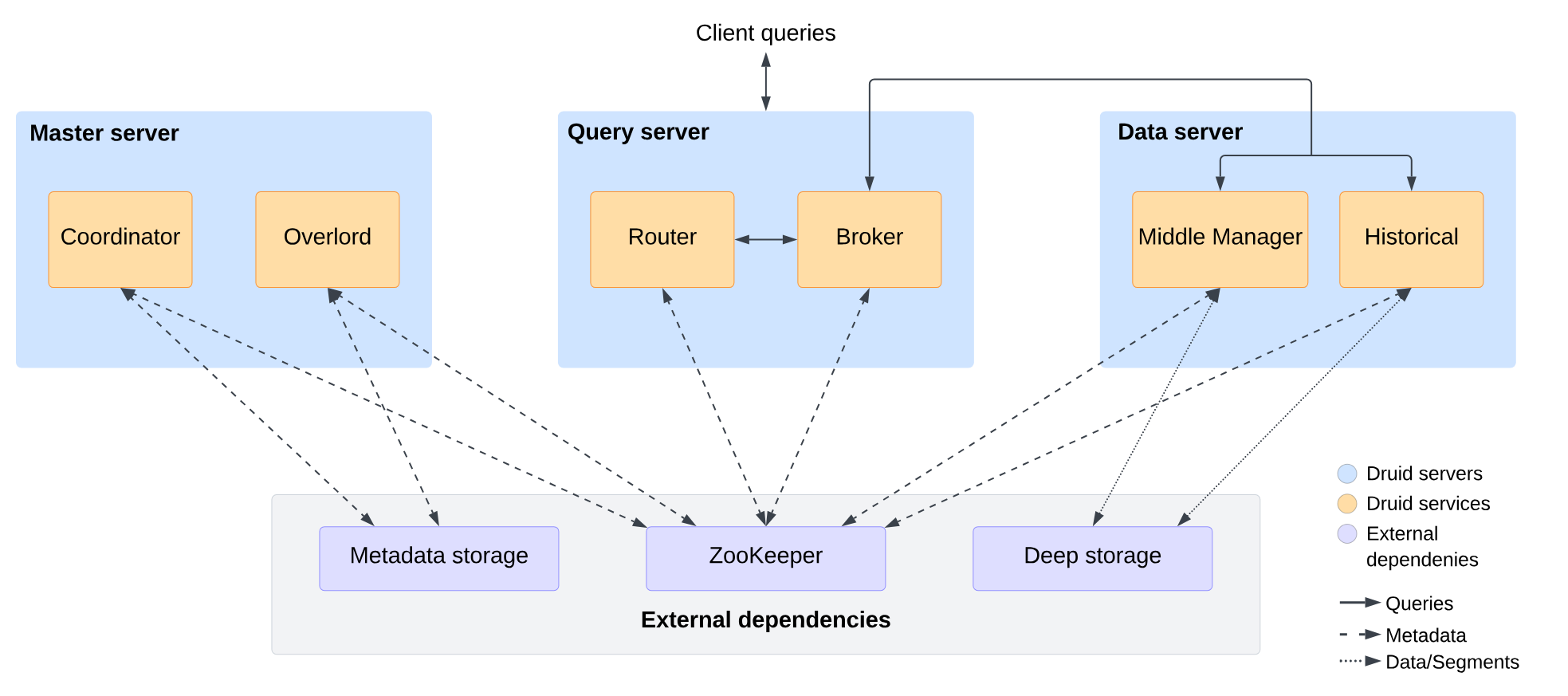
二、Druid 服务组件详解
2.1 核心服务类型
Druid 由多种服务组成,每种服务承担特定职责:
- Overlord:数据摄取工作负载的分配控制器
- Broker:处理外部客户端查询的路由服务
- Router:请求路由服务,将请求导向 Brokers、Coordinators 和 Overlords
- Indexer:替代 MiddleManager + Peon 任务执行系统的替代方案
2.2 服务器角色划分
为便于部署和管理,Druid 服务通常按以下三种服务器类型组织:
2.2.1 Master 服务器
负责数据摄取和可用性管理,包含:
- Coordinator:监控 Historical 服务,分配数据段到特定服务器,确保数据段在 Historical 间均衡分布
- Overlord:监控 MiddleManager 服务,控制数据摄取,分配摄取任务并协调数据段发布
2.2.2 Query 服务器
提供用户和客户端应用交互的端点,包含:
- Broker:接收外部查询并转发至 Data 服务器,合并结果后返回
- Router:提供统一API网关,运行Web控制台
2.2.3 Data 服务器
执行摄取作业并存储可查询数据,包含:
- Historical:处理历史数据存储和查询
- MiddleManager:处理新数据摄取
- Peon:MiddleManager 生成的任务执行引擎
- Indexer (可选):替代 MiddleManager + Peon 的任务执行系统
三、服务部署与配置策略
3.1 服务共置指南
合理的服务共置可提高硬件资源利用率:
- Coordinator 和 Overlord:在段数量极高的集群中,建议分离以提供更多资源给 Coordinator 的段平衡工作负载
- Historicals 和 MiddleManagers:高摄取或查询负载情况下,建议部署在不同主机以避免CPU和内存争用
3.2 外部依赖关系
Druid 依赖以下外部系统:
- Deep Storage (深度存储):
- 存储所有摄取的数据
- 典型实现:S3、HDFS 或网络挂载文件系统
- 单服务器部署可使用本地磁盘
- Metadata Storage (元数据存储):
- 存储共享系统元数据
- 集群部署通常使用 PostgreSQL 或 MySQL
- 单服务器部署可使用 Apache Derby
- ZooKeeper :
- 用于内部服务发现、协调和领导者选举
四、数据流与处理机制
4.1 数据摄取流程
- Ingestion:数据通过 MiddleManager (或 Indexer) 从外部源读取并发布为新 Druid 段
- Segment 分配:Coordinator 将段分配到 Historical 服务
- Segment 下载:Historical 服务从深度存储下载段
- 查询准备:Historical 服务缓存段数据以供查询
4.2 查询处理流程
- 查询接收:Broker 接收外部客户端查询
- 查询路由:Broker 将查询转发至相关 Data 服务器
- 结果合并:Broker 合并子查询结果并返回给调用者
五、架构优势与适用场景
5.1 Druid 架构的核心优势
- 实时与批量处理统一:同时支持流式和批处理数据摄取
- 亚秒级查询响应:优化的列式存储和内存管理实现快速查询
- 水平可扩展性:所有组件均可独立扩展
- 高可用性:无单点故障设计
5.2 典型应用场景
- 点击流分析
- 网络流量监控
- 数字营销分析
- 业务指标监控
- 时间序列数据分析
六、部署建议与最佳实践
6.1 硬件配置建议
- Master 服务器:中等CPU,高内存,SSD存储
- Query 服务器:高CPU,高内存,SSD存储
- Data 服务器:高磁盘容量,高IOPS,适量内存
6.2 性能优化技巧
- 段管理:合理设置段大小(通常500MB-1GB)
- 缓存策略:优化JVM堆大小和缓存配置
- 并行度调整:根据数据量和集群规模调整并行处理参数
- 查询优化:使用合适的时间范围和过滤条件
6.3 监控与维护
- 监控关键指标:摄取速率、查询延迟、段数量等
- 定期维护:段压缩、数据清理
- 备份策略:确保深度存储和元数据存储的可靠性
七、总结与展望
Apache Druid 的架构设计使其成为实时分析领域的强大工具。通过理解其组件交互和服务部署策略,您可以构建高效、可扩展的数据分析平台,满足各种业务场景的需求。
随着数据量和分析需求的不断增长,Druid 的分布式架构和优化特性将帮助您应对未来的挑战。建议持续关注 Druid 社区的更新,特别是 Indexer 服务等实验性功能的成熟进展。
下一步行动建议:
- 在测试环境部署 Druid 集群,熟悉其架构和操作
- 根据业务需求调整服务配置和硬件资源
- 探索 Druid 与其他数据系统的集成可能性
通过合理利用 Druid 的架构优势,您可以构建高性能、可靠的数据分析解决方案,为业务决策提供有力支持。