数据库是什么?为什么需要数据库?
数据存储在内存中,断电后数据会丢失,此时可以将数据存储在磁盘等非易失性存储介质上。但是并不能将数据单纯的拷贝到磁盘,如指针,此时需要一些特殊的操作。先进行序列化,移除指针等结构,将数据扁平化,接着将扁平化流的数据反序列化写入磁盘。虽然可以通过一些操作将内存数据存储入磁盘,但是耗时并且麻烦,需要一定的代价,此外堆业务程序员不太友好,不仅需要考虑内存数据结构本身,还需要考虑内存与磁盘的交互。此时可以子啊内存与磁盘之间加一个中间层:数据库
数据库是内存和磁盘的中间层次,负责将复杂的数据结构持久化:
- 管理复杂的数据结构,性能好
- 数据冗余问题、数据修改不一致和安全
数据库的分类
按组织结构分类
- 关系(表)型数据库:所有的数据项的结构都是一样的,SQL。
Oracle:(甲骨文)目前性能最好的关系型数据库,收费贵
MySQL为互联网公司应用广泛
postgreSQL代码比MySQL更加优秀
关系型数据库适合于大部分场景,占据80%市场,但是在游戏领域等不适用
- 非关系型数据库:不同的数据项的结构是不一样的,NoSQL
MongoDB:游戏领域用的多
Redis:将重心放在内存,(键值对)提升性能,在互联网领域使用较多。
走进人工智能时代出现了其他数据库:图数据库、时序数据库(嵌入式用的多)
关系
数学上的关系是二维表格,由行和列组成。表格和矩阵的区别在于行和列各有各自的区别。
关系的行和列有着不同的作用。
- 一列代表了所有数据对象在某一属性上的取值(结构->DDL 数据定义语言)
- 一行代表了一个数据对象(内容 -> 数据操作语言)
SQL语言的使用
structured Query Language
SQL设计的时候,不只是面向程序员,还要面向很多非技术人员,是声明式语言,体现是想要什么。
c、c++、Java等等是过程是语言,体现是应该怎么做。
声明式 --- 解析 ---> 过程式指令 --- 优化 ---> 存储引擎
MySQL架构
采用 :C/S 架构
MySQL端口号:3306
d: 是ddaemon,是守护进程。mysqld是Mysql的服务端进程。
- 客户端与服务端通信时通过客户端与服务器端,通过tcp连接,使用端口号:3306。
- 可以使用代码直接向MySQL发送数据。
- 可以借助图形化客户端连接MySQL。
Mysql的进入退出
在命令行输入
mysql -u root -p
输入root用户密码,即可进入mysql
退出使用 quit 或者 crt + D
Mysql当中数据是一种二级结构
数据在Mysql中存储在表格当中。
database当中只能存储table。
SQL语句
- SQL语句以分号为结尾
- 换行和空格等价
- SQL语句的关键字时大小写不敏感的
show databases;
展示所有数据库
select databases();
select :读取
databases() 这是一个函数调用
NULL是一个特殊的空值,NULL不是0(区别于C语言)
create database 数据库名;
创建数据库
drop database 数据库名;
删除数据库
注:这里的数据库名是我们自己创建的标识符,是大小写敏感的
use 数据库名
切换database,use不是一个SQL语句,是mysql管理命令。
查看database里面的table
show tables;
注:要先使用use进入到想要查看的database里面,在使用show tables; 查看当前数据库里面有什么表。
DML之增删改查
- insert into
- delete from
- updata ...... set
- select ...... from
创建表格
在创建表之前需要知道:
- 表的结构 DDL
- 列的信息(名字、数据类型、额外属性)
数据类型:
- 数值类型
- 日期和时间类型
- 字符串类型
数值类型
整数:精确值
小数:定点数也是精确值
浮点数:近似值
日期时间类型
- DATE 年 月 日
- TIME 时 分 秒
- TIMESTAMP 时间戳 本质是一个整数 1970年1月1日到现在多少秒(2038年会出现千年虫问题)
字符串类型
- CHAR(N): 定长字符串
- VARCHAR(N):变长字符串(最大长度为N),N限制在255
- TEXT: 长的文本数据
- BLOB:长的二进制数据(图片、音乐)不超过10MB
字符串适合中等文件大小的数据存储。海量小文件存储的处理相当麻烦。tips:不同的业务特征要有不同的处理方案。
创建表格
create table 表名 (列1,列2,......,额外要求);

获取表格信息
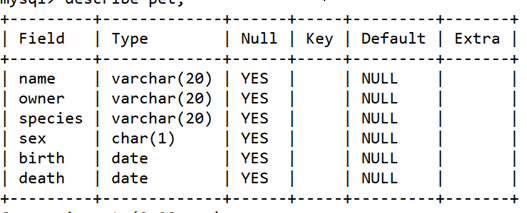
describe 表名
或者 desc 表名
- Field: 域,列名
- Type:类型
- NULL:是否为空
- key:索引
- Default: 默认值
- Extra:额外
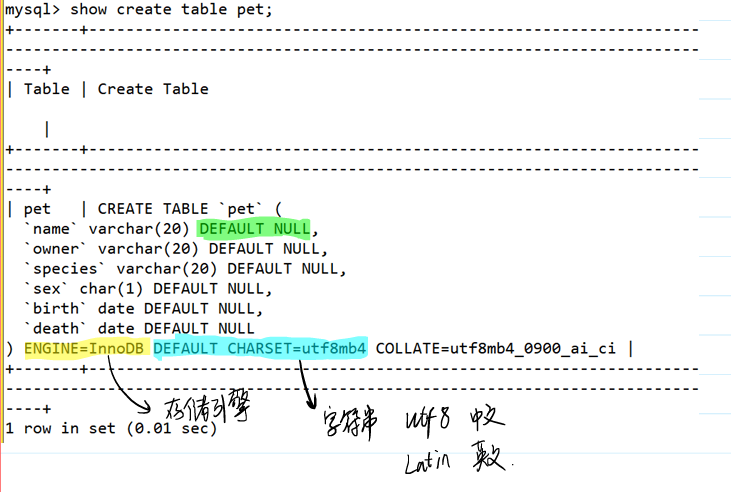
查看表格如何创建
show create table 表名;
ENGINE: 存储引擎
DEFAULT CHARSET: 默认编码格式
- utf8 中文
- Latin 英文
获取表格中的所有内容
DML里面的DQL(查询)
select * from 表名;
- select: 查询
- *: 所有列
- from 表名:从表中
插入一行
DML
insert into 表名(列1值,列2值,列3值......);
使用字符串时尽量使用单引号。
插入一行,只写部分列的值
insert into 表名 (列名1,列名2,......) values(列1值,列2值);
没有赋值的列值会取默认值。
select查询
select * from 表名;
查询表名中的所有内容
where从句
select * from 表名 where 筛选条件;
按行进行筛选
判断大小关系
=: 是相等,区别与C
<>: 不相等
使用 > 或 < 号
- 数值按大小
- 日期按先后
- 字符串按字典序
NULL要做特殊处理
NULL不支持 = 和 <>
支持 is NULL 和 is not NULL。
多个条件的组合
与: and
或: or
非: not
模糊匹配
wildcard 通配符
运算符 like
- % 任意长度的字符串
- _ 任意一个字符

按列进行筛选
select 表达式1,表达式2, ...... from 表名 where 条件;
顺序:先from再where最后select
order by
select 表达式 from 表名 order by 条件;
多种条件排序
select 表达式 from 表名 order by 条件1、条件2;
先按条件1排序,取值相同的再按照条件2排序,排序时左边的条件更重要。
select 表达式 from 表名 where 条件 order by 排序条件
会先执行【select 表达式 from 表名 where 条件】做出表格后,再按照order by进行排序。
limit 从句
select 表达式 from 表名 where 条件 order by 排序条件 limit 1;
执行顺序:from -> where -> select -> order by -> limit
聚集查询
之前的查询称为普通查询,其结果只能为原始表的子集
我们现在需要查询一些原始表中没有的数据(统计性的信息),将这种查询方式称为聚集查询
count
select count(*) from 表名;
count称为聚集函数,它能统计出在当前条件下的数量。执行顺序很靠后。
聚集函数的执行时机
from -> where -> * -> count
先算出表格,在执行聚集函数。
注意:聚集查询和普通查询不要随便混用。
分组聚集 group by
select 聚集函数(表达式),分组依据 from 表名 where 条件 group by 分组依据;
在计算聚集函数之前先分组,现在展示的是每个分组的信息
group by一定要在聚集查询下使用,配合count使用。现在可以在聚集表达式前,写分组条件。
having 从句
select 聚集函数(表达式),分组依据 from 表名 where 条件 group by 分组依据 having 条件;
对聚集之后的结果进一步进行筛选
如:

聚集的执行顺序
select 聚集函数(表达式) from 表 where 条件 group by 分组 ;
from -> where -> 表达式 -> group by -> 聚集函数
两张表做一些运算的到一张新表
表 t1 行的集合 {a1,a2,a3......}
表 t2 行的集合 {b1,b2,b3......}
笛卡尔积
将t1与t2连接形成一张新表: {a1b1,a1b2,a1b3......a2b1,a2b2,a2b3......}
先做笛卡尔积在筛选,可以将两张无关联的表整合起来
缺点:笛卡尔积生成的表非常大
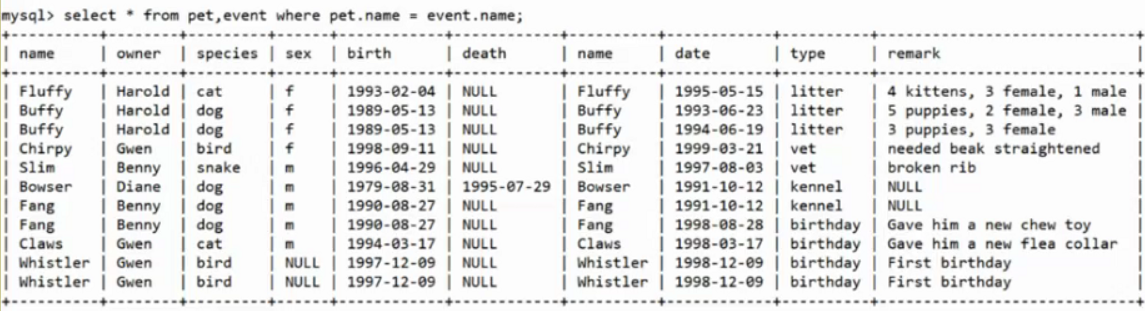
内连接
前提:有两张表,描述不同信息,但是两个表中各有一列描述的是相同的内容。
左表inner join 右表的时候,只有两表在on条件满足这些行才会加入到结果中。内连接需要连接条件(
ON),笛卡尔积不需要。内连接的结果是笛卡尔积的子集(仅保留符合条件的行组合)。内连接结果行数 ≤ 笛卡尔积结果行数(当连接条件为恒真时,两者结果相同)。
内连接是笛卡尔积的条件过滤版本,二者有逻辑上的包含关系。
select * from 左表 inner join 右表 on 条件;
左外连接
select * from 左表 left outer join 右表 on 条件;
在内连接的基础上,再额外加上左右表没有匹配的部分(右表没有,左表有)
左连接 = 内连接结果 + 左表未匹配的行 (右表补
NULL)
- 外连接会产生
NULL值,笛卡尔积不会主动产生NULL。
右外连接
select * from 左表 right outer join 右表 on 条件;
在内连接的基础上,再额外加上左表有,而右表没有的内容
右连接 = 内连接结果 + 右表未匹配的行 (左表补
NULL)
全外连接
MySQL不支持全外连接
select * from 左表 left outer join 右表 on 条件 union select * from 左表 right outer join 右表 on 条件;
只要取左外连接并集即可。
连接的好处
笛卡尔积会产生一张大表,而连接不会产生,。
避免数据的重复存储,产生冗余
修改行
uodata 表名 set 列名 = 新值 where 筛选条件;
不写where会将所有行全更改
假如表中存在完全相同的两行
没有任何办法之更改其中一行而不影响另外一行。
因此再设计表的时候,一定让表中不存再完全相同的两行。否则这两行等价于一行,关系中不存在插入的先后顺序。
删除行
delete * from 表名 where 筛选条件
删除数据不是一件好事
表的底层事一颗B+树,删除一行数据可能会导致节点合并,可能严重影响性能。
可以不做物理上的删除,做逻辑上的删除。多加一个字段is_delete,0代表没有删除,1代表删除。代价是浪费一部分物理空间,换取时间。且做数据恢复时可以直接更改is_delete = 0。在业务中,我们可以在一次大维护中,同一对数据库进行维护,将逻辑删除的内容真正删除。
调整表的结构
改列:这些指令一般在停服维护时执行或永远不执行(时间开销很大)
- 新增一列或多列
alter table add( 名字 数据类型 )
- 删除一列
alter table drop 名字 数据类型
- 修改一列的属性
alter table change 名字 更改后名字 更改后数据类型
其他SQL指令
更改表名
rename table 表名 to 新表名
删除表drop table 表名;
约束
某一个数据对象在某个字段取值的限制
- 域约束,只看这一列的性质就可以确定的约束
int 型不能填入 字符型
- 实体约束,还需要查看另外的行在本列的取值
主键约束:所有的行在本列的值必须互不相同,一张表只能有一个
唯一键约束:所有行在本列的值必须互不相同,唯一键可以有任意个
- 参照约束,还要检查另一张表
主键
有了主键以后,表中不存在完全相同的两行
主键是一列或多列的组合,表中所有行在主键上的取值必须互不相同
一张表最多有一个主键,推荐有一个。表的底层是B+树,主键的大小是B+树排序的依据。
创建表时添加主键,使用primary key(主键名)
creat table 表名( id int , 属性名 属性类型,......,primary key(id));

多列主键
creat table 表名(属性名 属性类型,......,primary key(属性名1,属性名2));
选择主键的原则
- 尽量选择与业务无关的主键
- 优先选择自动增长的整数
自动增长
auto_increment
creat table 表名( id int auto_increment, 属性名 属性类型,......,primary key(id));
业务上有唯一性的要求
唯一键:添加unique key(属性名)
creat table 表名( id int auto_increment, 属性名 属性类型,......,unique key(id));
此时选择使用唯一键实现。不选择使用主键,因为主键影响数据排列。
安装mysql库函数 客户端
sudo apt install libmysqlclient-dev