Some of the events that can trigger a rebalance
- A consumer instance fails to send a heartbeat to the coordinator before the timeout and is removed from the group
- A consumer instance has been added to the group
- New partitions have been added to a topic in the group's subscription
- A group has a wildcard subscription and a new matching topic is created
- And, of course, initial group startup
What happens when a rebalance occurs
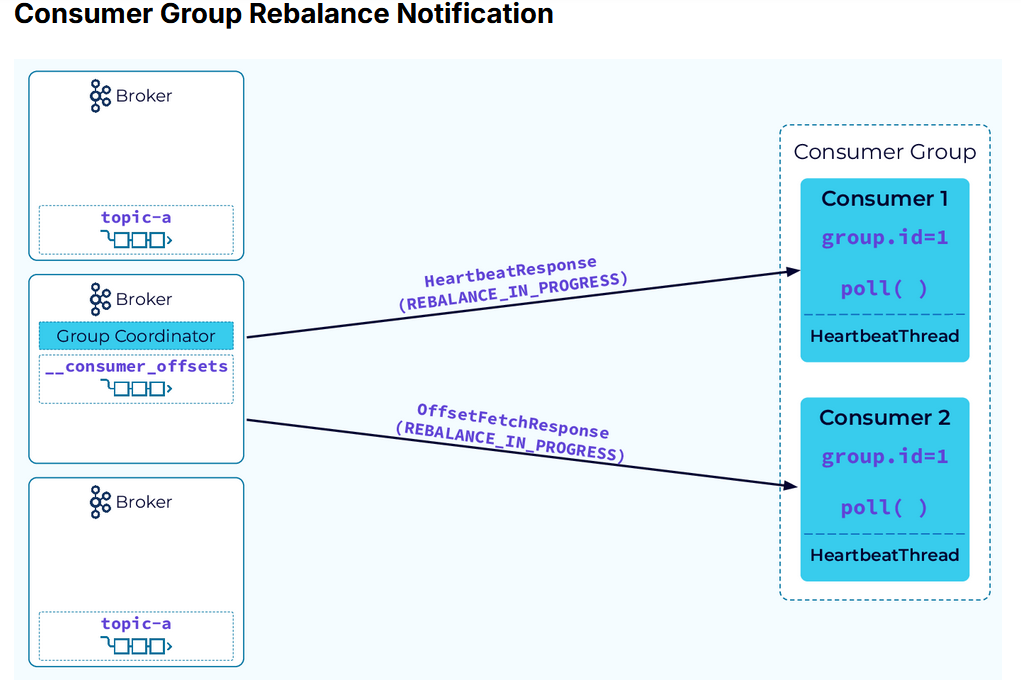
The rebalance process begins with the coordinator notifying the consumer instances that a rebalance has begun. It does this by piggybacking on the HeartbeatResponse or the OffsetFetchResponse.
Stop-the-World Rebalance
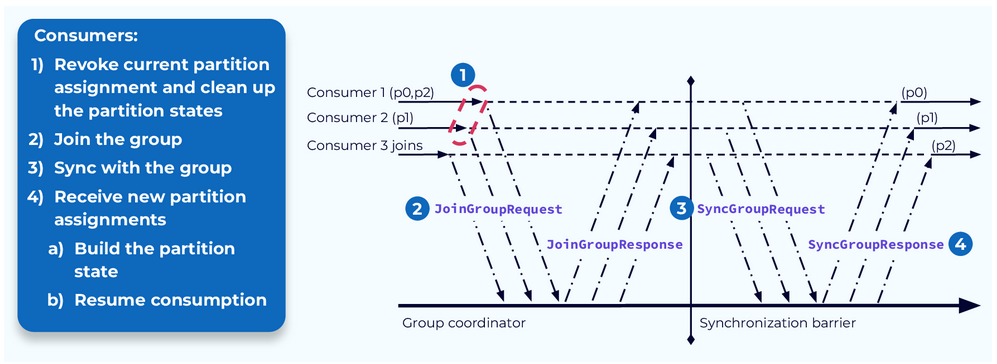
Once the consumers receive the rebalance notification from the coordinator, they will revoke their current partition assignments. If they have been maintaining any state associated with the data in their previously assigned partitions, they will also have to clean that up. Now they are basically like new consumers and will go through the same steps as a new consumer joining the group.
They will send a JoinGroupRequest to the coordinator, followed by a SyncGroupRequest. The coordinator will respond accordingly, and the consumers will each have their new assignments.
Any state that is required by the consumer would now have to be rebuilt from the data in the newly assigned partitions.
这个过程很有效率,但是也有一些缺陷,如下
Stop-the-World Problem #1 -- Rebuilding State
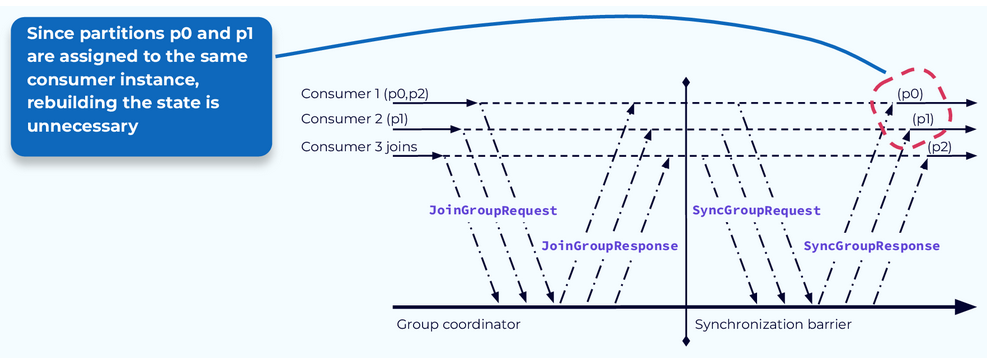
The first problem is the need to rebuild state. If a consumer application was maintaining state based on the events in the partition it had been assigned to, it may need to read all of the events in the partition to rebuild that state after the rebalance is complete. As you can see from our example, sometimes this work is being done even when it is not needed. If a consumer revokes its assignment to a particular partition and then is assigned that same partition during the rebalance, a significant amount of wasted processing may occur.
Stop-the-World Problem #2 -- Paused Processing
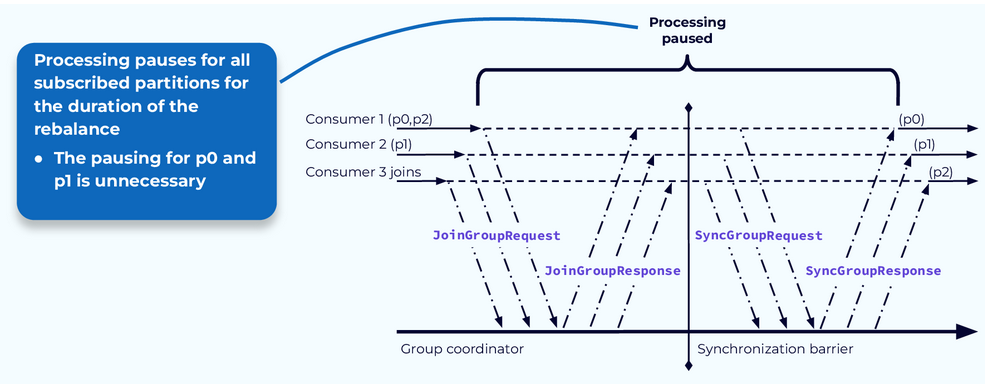
The second problem is that we're required to pause all processing while the rebalance is occurring, hence the name "Stop-the-world." Since the partition assignments for all consumers are revoked at the beginning of the process, nothing can happen until the process completes and the partitions have been reassigned. In many cases, as in our example here, some consumers will keep some of the same partitions and could have, in theory, continued working with them while the rebalance was underway.
Avoid Needless State Rebuild with StickyAssignor
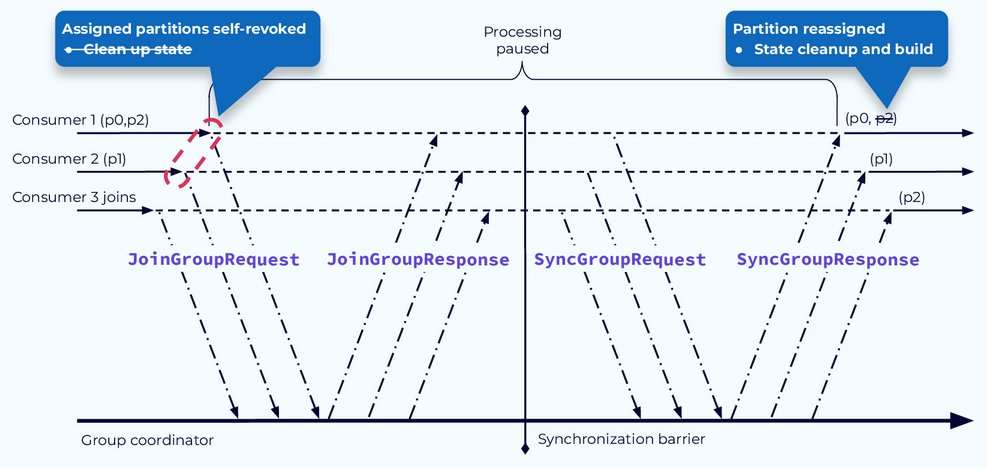
First, using the new StickyAssignor we can avoid unnecessary state rebuilding. The main difference with the StickyAssignor, is that the state cleanup is moved to a later step, after the reassignments are complete. That way if a consumer is reassigned the same partition it can just continue with its work and not clear or rebuild state. In our example, state would only need to be rebuilt for partition p2, which is assigned to the new consumer.
Avoid Pause with CooperativeStickyAssignor Step 1
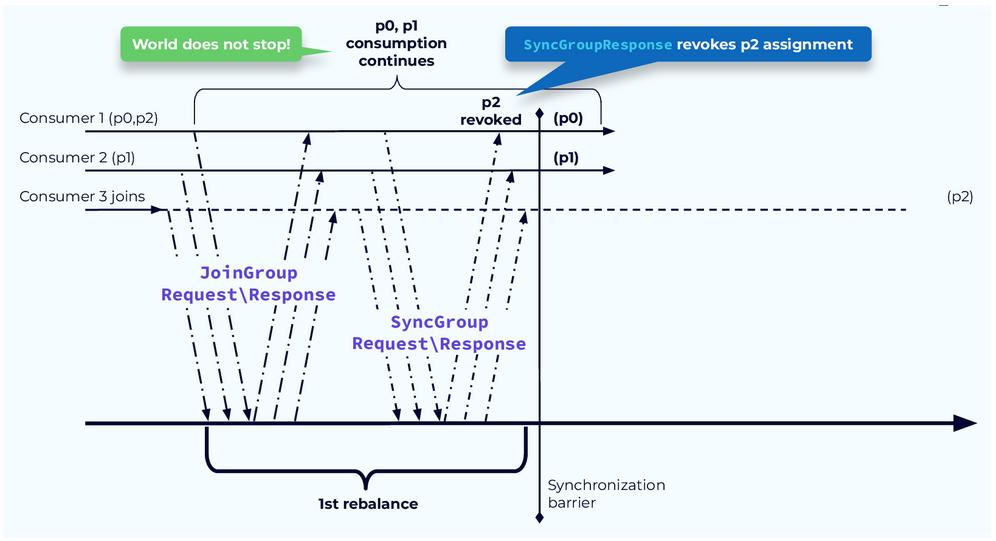
To solve the problem of paused processing, we introduced the CooperativeStickyAssignor. This assignor works in a two-step process. In the first step the determination is made as to which partition assignments need to be revoked. Those assignments are revoked at the end of the first rebalance step. The partitions that are not revoked can continue to be processed.
Avoid Pause with CooperativeStickyAssignor Step 2
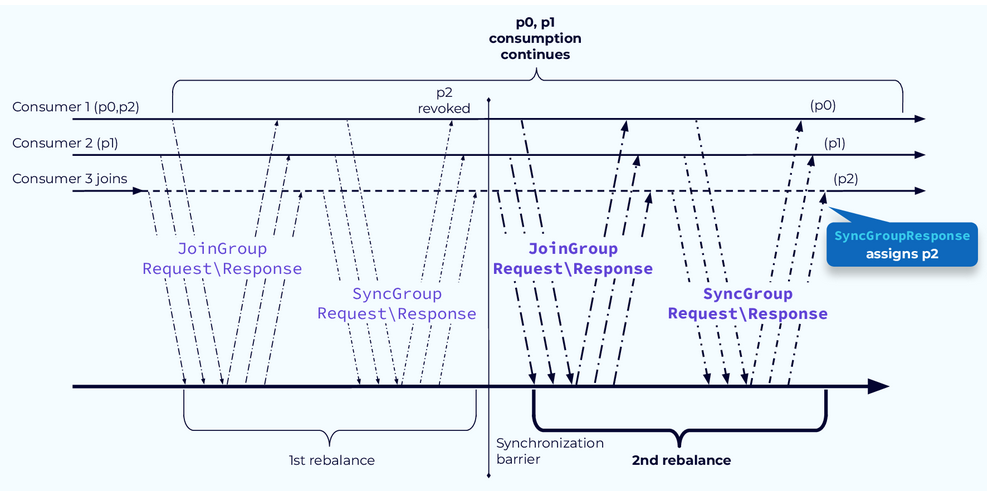
In the second rebalance step, the revoked partitions will be assigned. In our example, partition 2 was the only one revoked and it is assigned to the new consumer 3. In a more involved system, all of the consumers might have new partition assignments, but the fact remains that any partitions that did not need to move can continue to be processed without the world grinding to a halt.
问题解决总结
之所以会产生 stop-the-world 是因为所有的consumer 都需要重新assign partition, 所以traffic 需要停掉。
避免这种情况可以配置 CooperativeStickyAssignor 这种 assignment strategy. 这中strategy is an extension of StickyAssignor.
另外一种增强就是减少rebalance 的发生
Avoid Rebalance with Static Group Membership
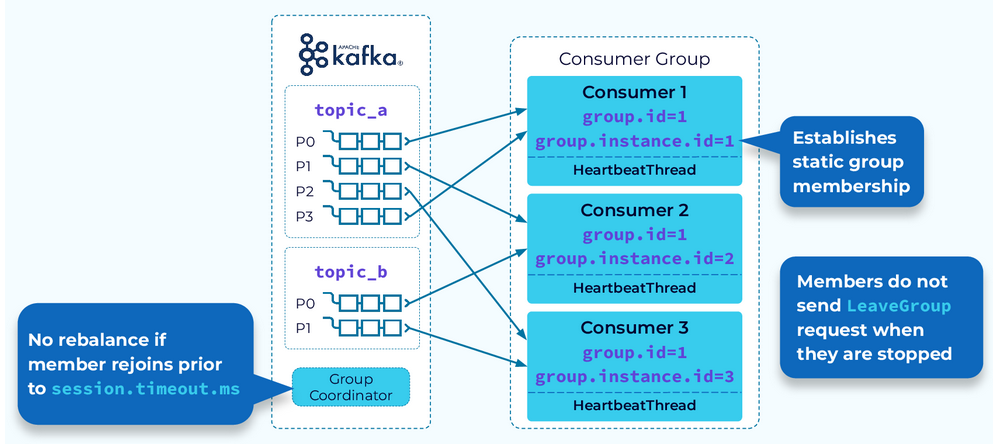
As the saying goes, the fastest rebalance is the one that doesn't happen. That's the goal of static group membership.
With static group membership each consumer instance is assigned a group.instance.id. Also, when a consumer instance leaves gracefully it will not send a LeaveGroup request to the coordinator, so no rebalance is started.
When the same instance rejoins the group, the coordinator will recognize it and allow it to continue with its existing partition assignments. Again, no rebalance needed.
当然这个的前提是consumer 断开的时间没有超过 session.timeout.ms.
Likewise, if a consumer instance fails but is restarted before its heartbeat interval has timed out, it will be able to continue with its existing assignments.
就是给consumer group 中的每个consumer 设置 group.instance.id, 让consumer 成为static member.
Static member 断开之后会重新连到同一个partition. No rebalance 会发生。
总结之如何减少rebalance 发生
- 设置
CooperativeStickyAssignor这种assignment strategy - 设置
group.instance.id - 调整
session.timeout.ms
session.timeout.ms vs heartbeat.interval.ms
| Config | Purpose | Default (Kafka 2.0+) | Relationship |
|---|---|---|---|
session.timeout.ms |
How long the broker waits before declaring a consumer dead if no heartbeats are received | 10,000 ms (10 sec) | Must be > heartbeat.interval.ms |
heartbeat.interval.ms |
How often the consumer sends heartbeat messages to the broker (group coordinator) | 3,000 ms (3 sec) | Sent periodically within the session window |
So:
heartbeat.interval.ms controls frequency of liveness check-ins.
session.timeout.ms controls how long the broker will wait for those check-ins before giving up.
Example
If you set:
bash
session.timeout.ms = 15000
heartbeat.interval.ms = 5000Consumer sends heartbeat every 5 seconds.
If 3 heartbeats are missed in a row, Kafka assumes the consumer is dead and starts a rebalance.