Data Studio支持在您的数据分析代码中引用自定义的资源和函数(支持MaxCompute、EMR、CDH、Flink),您需要先创建或上传资源、函数至目标工作空间,上传后才可在该工作空间的任务中使用。您可参考本文了解如何使用DataWorks可视化方式创建资源和函数并在节点中使用。
参考官方文档:
资源管理_大数据开发治理平台 DataWorks(DataWorks)-阿里云帮助中心 (aliyun.com)
目录
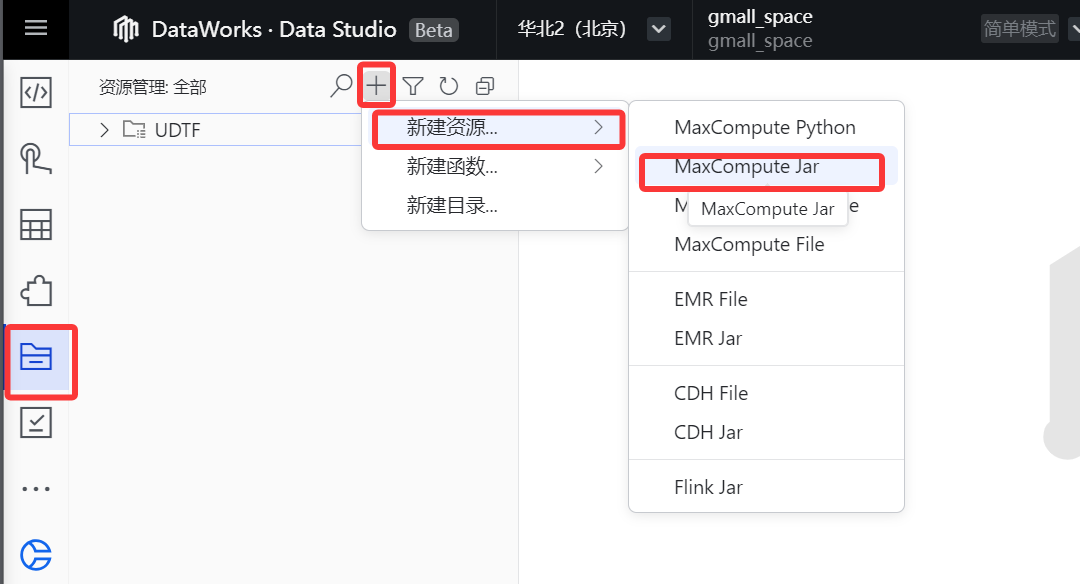
[1.如下图,依次点击,然后点击"MaxCompute Jar"](#1.如下图,依次点击,然后点击“MaxCompute Jar”)
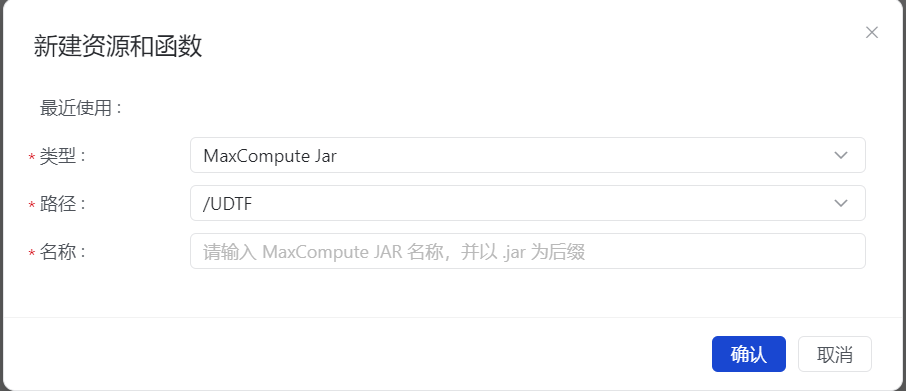
[2.名称:请输入MaxCompute Jar名称,并以.jar为后缀](#2.名称:请输入MaxCompute Jar名称,并以.jar为后缀)
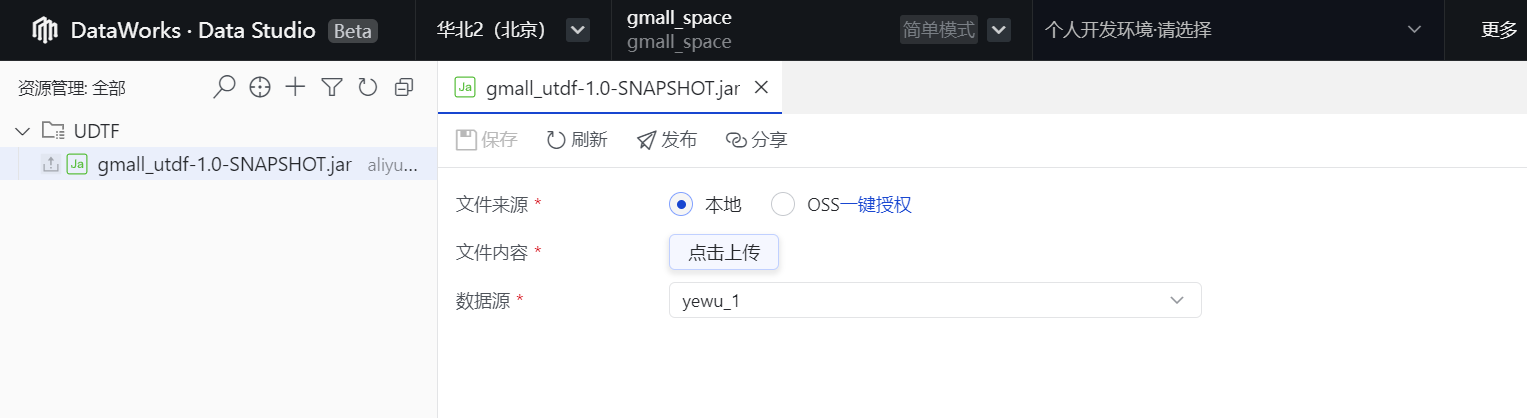
[编辑 3.然后进入到如下界面,文件来源选择"本地",文件内容进行点击上传,选择合适的"数据源"](#编辑 3.然后进入到如下界面,文件来源选择“本地”,文件内容进行点击上传,选择合适的“数据源”)
[编辑 5.点击"开始发布生产"](#编辑 5.点击“开始发布生产”)
[2.输入名称,点击 "确认"](#2.输入名称,点击 “确认”)
[3. 进行如下设置,然后点击"发布"](#3. 进行如下设置,然后点击“发布”)
一、创建资源(如上传jar包)
1.如下图,依次点击,然后点击"MaxCompute Jar"
2.名称:请输入MaxCompute Jar名称,并以.jar为后缀
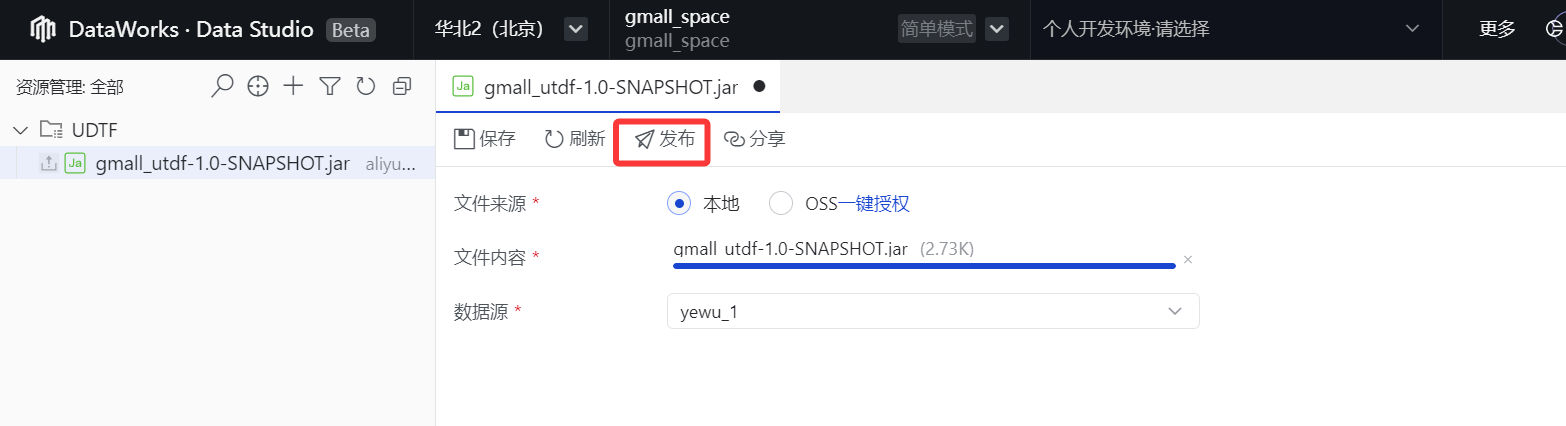
 3.然后进入到如下界面,文件来源选择"本地",文件内容进行点击上传,选择合适的"数据源"
3.然后进入到如下界面,文件来源选择"本地",文件内容进行点击上传,选择合适的"数据源"
4.点击"发布"
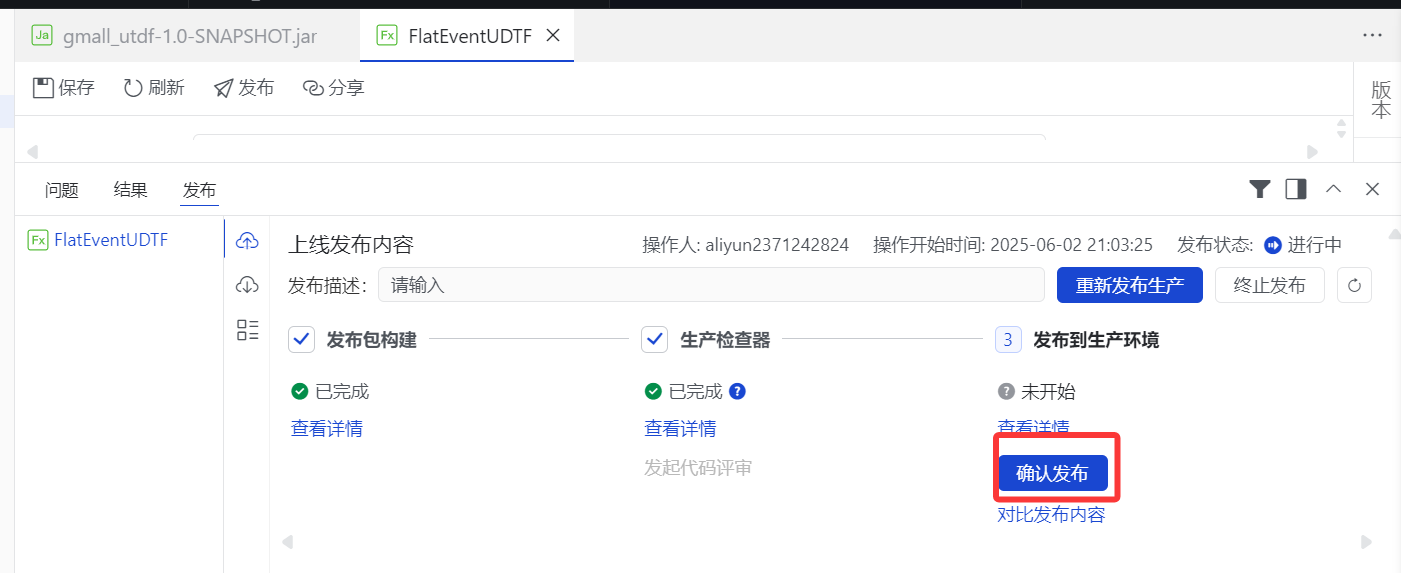
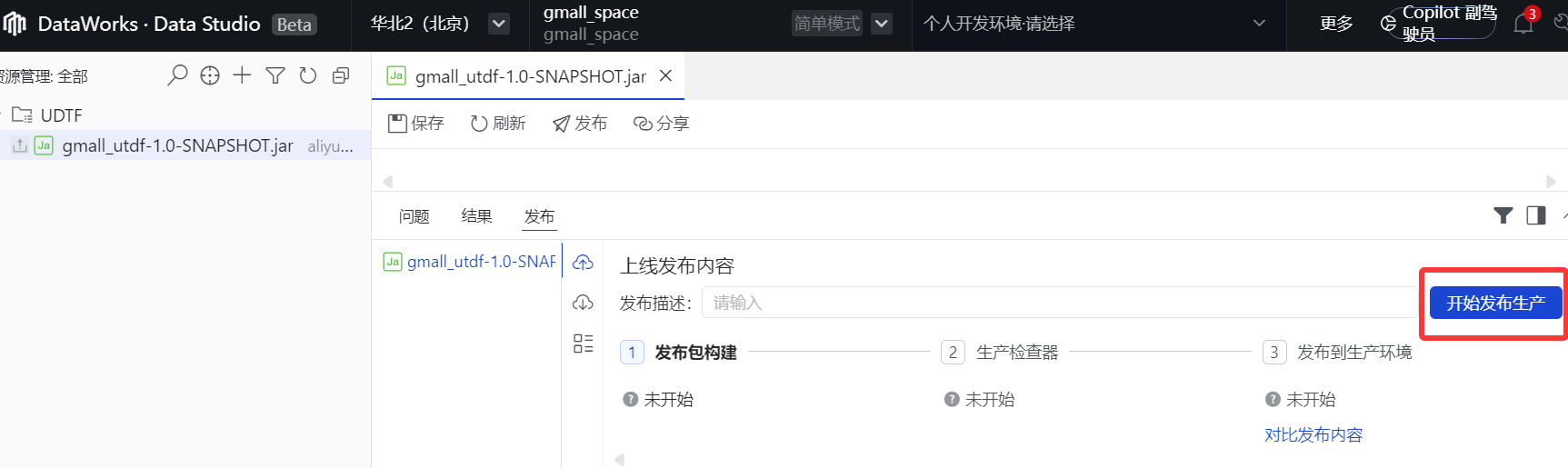
 5.点击"开始发布生产"
5.点击"开始发布生产"
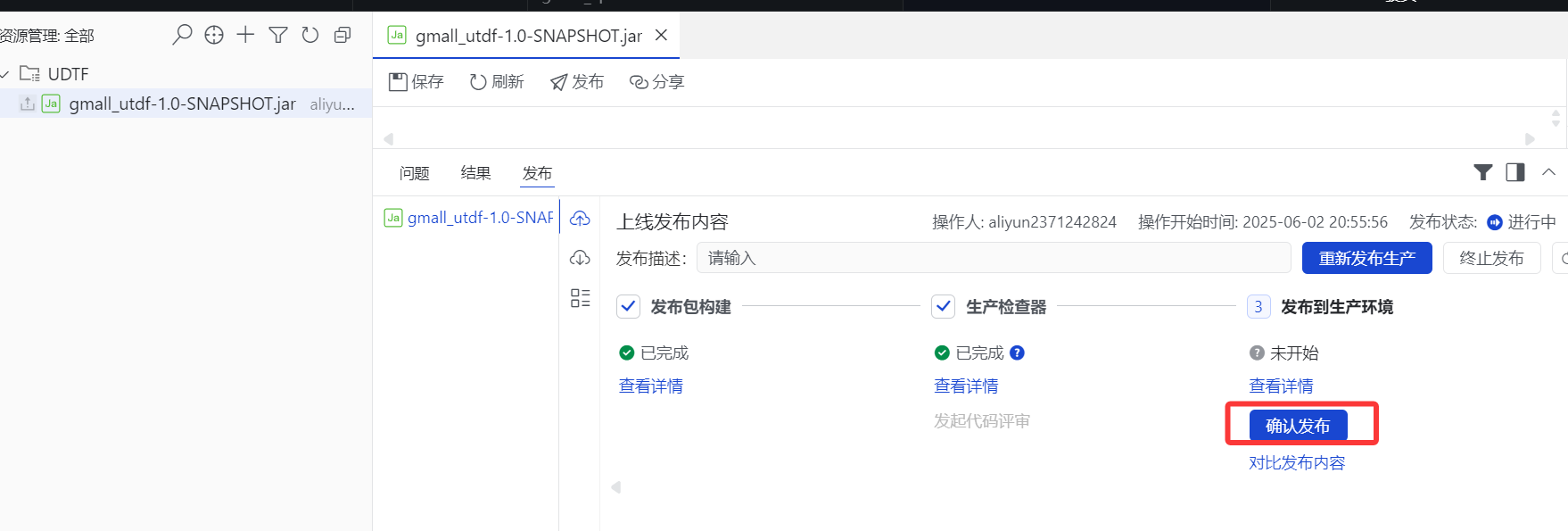
6.点击"确认发布"
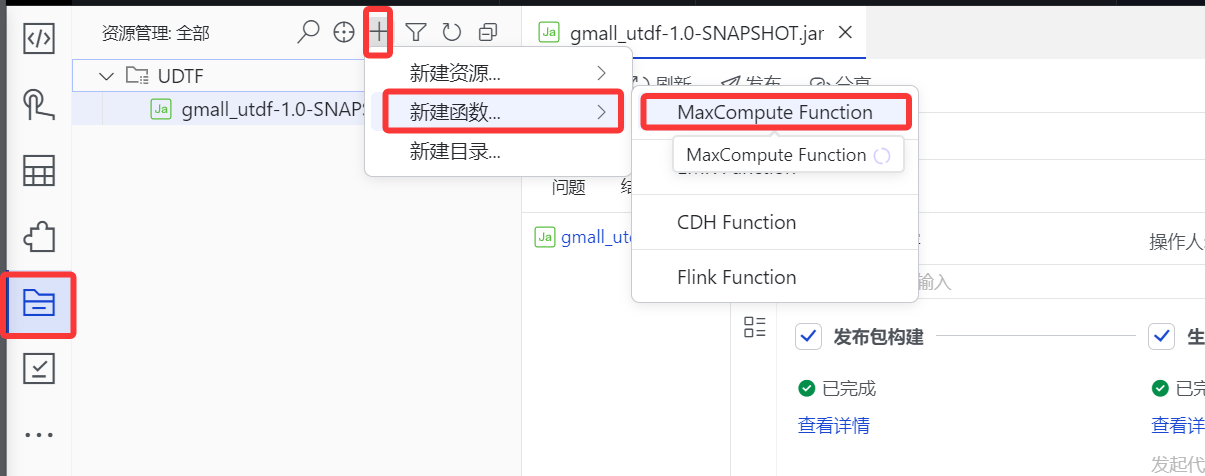
二、创建函数
1.如下图所示,依次点击
2.输入名称,点击 "确认"
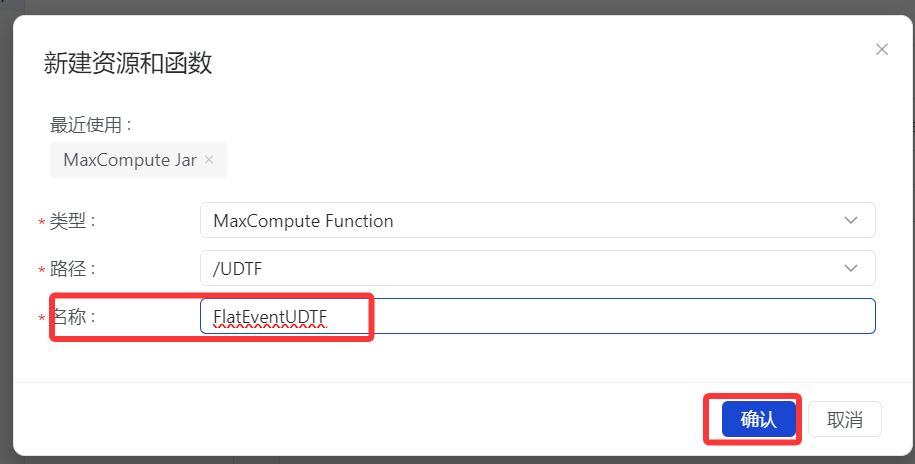
3. 进行如下设置,然后点击"发布"
具体参数含义,参考如下链接:资源管理_大数据开发治理平台 DataWorks(DataWorks)-阿里云帮助中心 (aliyun.com)
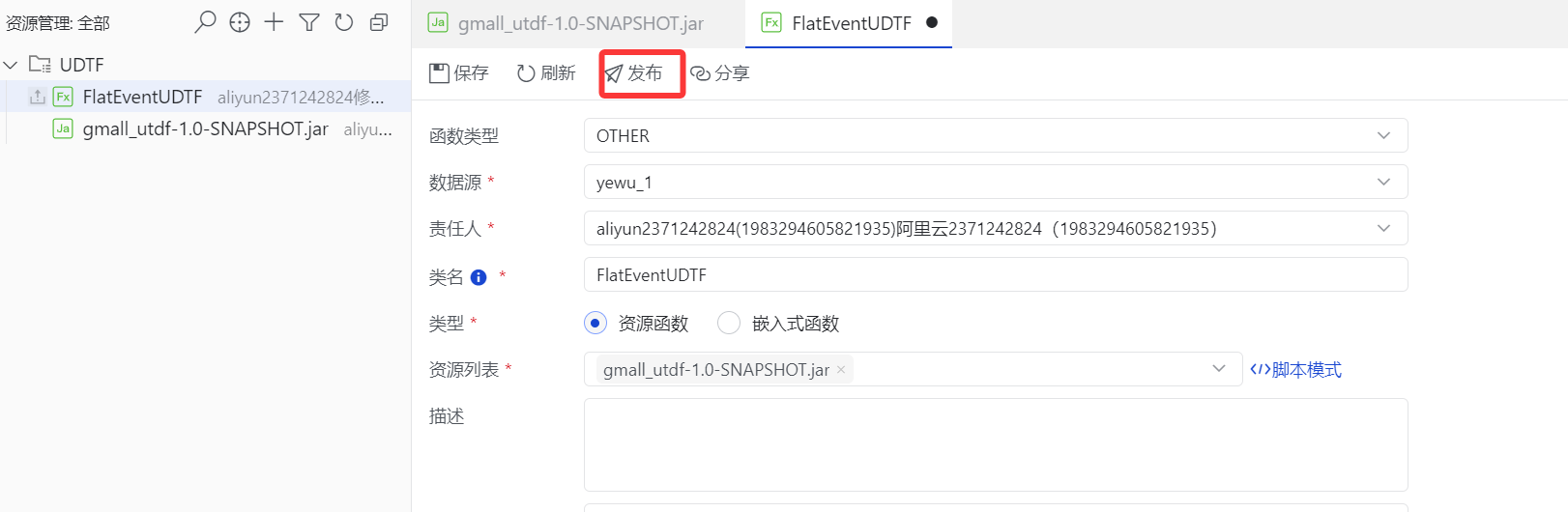
4.点击"开始发布生产"
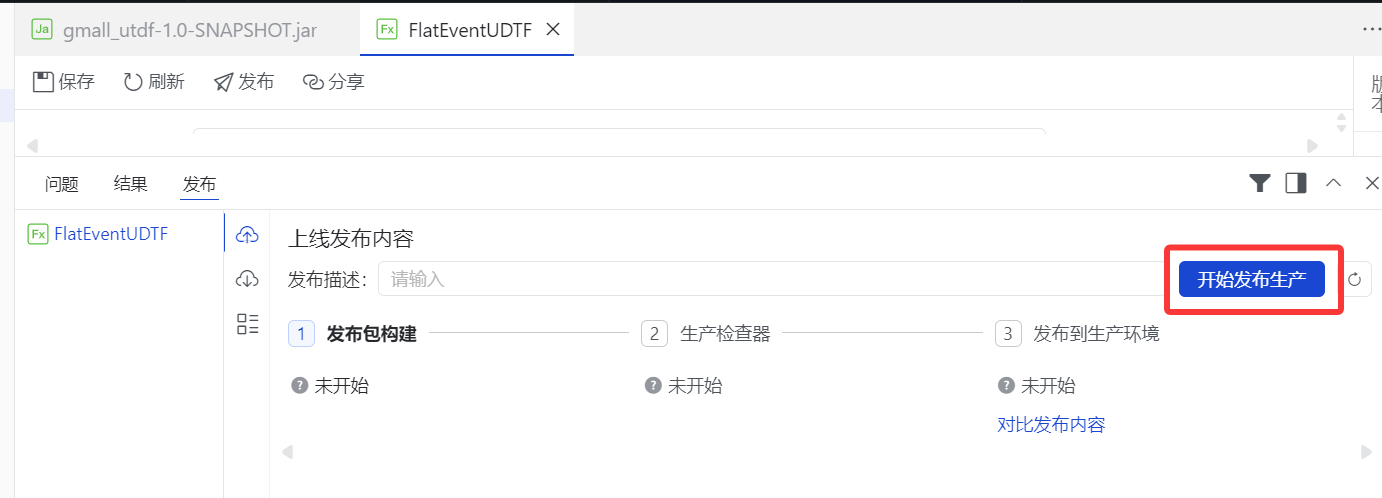
5.点击"确认发布"