本地可部署的模型
Marker
Marker 快速准确地将文档转换为 markdown、JSON 和 HTML。
- 转换所有语言的 PDF、图像、PPTX、DOCX、XLSX、HTML、EPUB 文件
- 在给定 JSON 架构 (beta) 的情况下进行结构化提取
- 设置表格、表单、方程式、内联数学、链接、引用和代码块的格式
- 提取和保存图像
- 删除页眉/页脚/其他工件
- 可使用您自己的格式和逻辑进行扩展
- (可选)使用 LLM 提高准确性
- 适用于 GPU、CPU 或 MPS
https://github.com/VikParuchuri/marker
Surya
Surya 是一个文档 OCR 工具包,它做到了:
- 90+ 种语言的 OCR,与云服务相比具有优势
- 任何语言的行级文本检测
- 布局分析(表格、图像、标题等检测)
- 读取顺序检测
- 表识别(检测行/列)
- LaTeX OCR
https://github.com/VikParuchuri/surya
MinerU

MinerU 是一种将 PDF 转换为机器可读格式(例如 markdown、JSON)的工具,可以轻松提取为任何格式。 MinerU 诞生于 InternLM 的预训练过程中。我们专注于解决科学文献中的符号转换问题,希望为大模型时代的技术发展做出贡献。
https://github.com/opendatalab/MinerU
需API调用的模型工具
llamaPaser
使用样例:
pip install dotenv
pip install llama_parse
pip install llama-index-llms-openai
在 modelDownload.py 文件所在的目录创建一个名为 .env 的文件,并在其中添加以下内容:
python
LLAMA_CLOUD_API_KEY='llamapaser API密钥'
OPENAI_API_KEY = 'openai APkey'配置好环境后运行代码:
python
# 需要LLAMA_CLOUD_API_KEY
from dotenv import load_dotenv
load_dotenv()
# LlamaParse PDF reader for PDF Parsing
from llama_parse import LlamaParse
documents = LlamaParse(result_type="markdown").load_data(
"90-文档-Data/黑悟空/黑神话悟空.pdf"
)
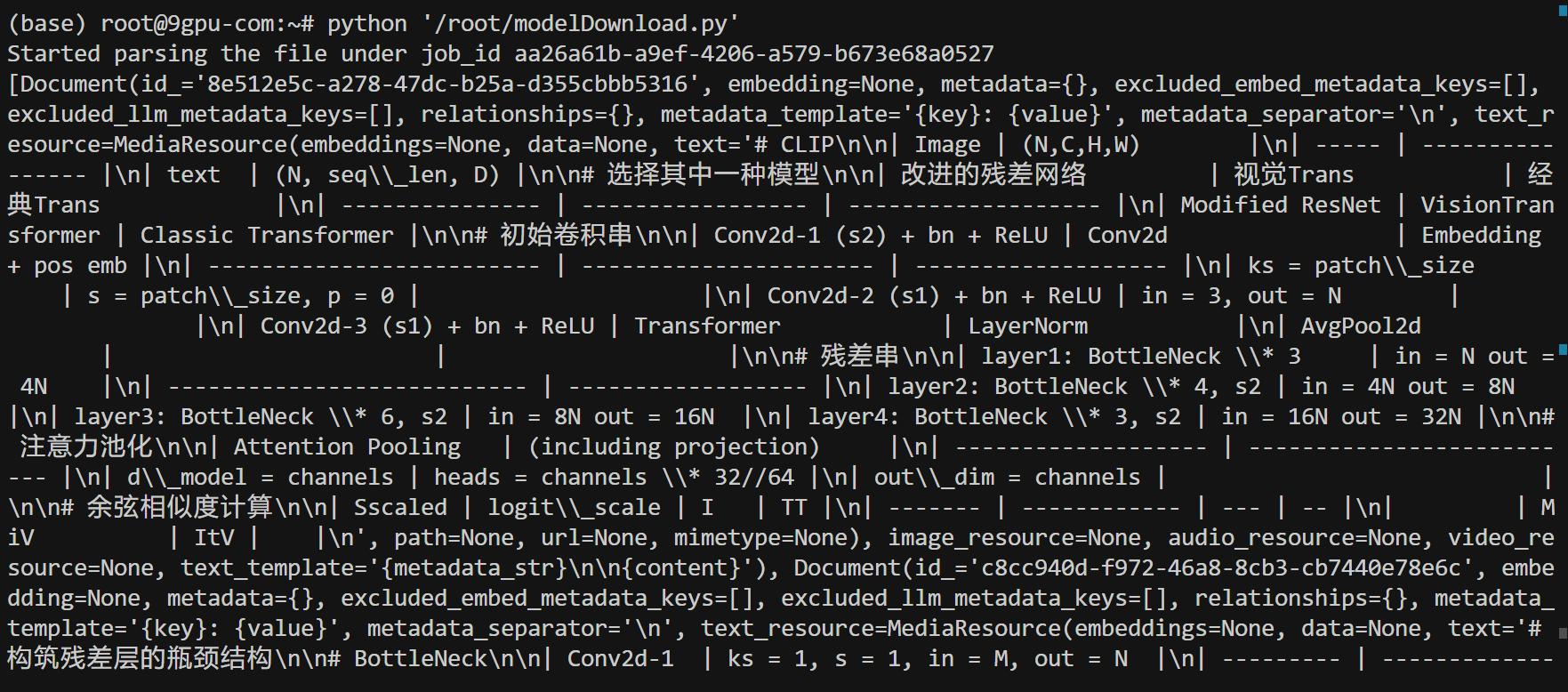
print(documents)
from llama_index.core.node_parser import MarkdownElementNodeParser
node_parser = MarkdownElementNodeParser()
nodes = node_parser.get_nodes_from_documents(documents)
print(nodes)效果如下: