背景:
接上一篇的数据库三范式设计数据库三范式设计---小白初学+案例引入-CSDN博客
为了从我们设计的三张表中联合获取完整的计算历史记录,我们来写下对应的SQL查询语句!
首先确认整体的查询语句结构:
(select a from b join c)
sql
SELECT [要选择的字段]
FROM [主表]
JOIN [关联表1] ON [关联条件]
JOIN [关联表2] ON [关联条件]
JOIN [关联表3] ON [关联条件]
ORDER BY [排序字段]
LIMIT [返回条数]先写select的部分:
sql
SELECT
c.id, -- 计算记录ID
o1.param AS num1, -- 第一个操作数的值,命名为num1
op.operator, -- 运算符
o2.param AS num2, -- 第二个操作数的值,命名为num2
c.result, -- 计算结果
c.spend_time, -- 计算耗时
c.created_at -- 创建时间from部分:
sql
FROM cal c -- 从calculations表查询,简称为cjoin部分 :
1.关联第一个操作数:
sql
JOIN operands o1 -- 关联operands表,简称为o1
ON c.id = o1.cal_id -- 通过cal_id关联
AND o1.position = 1 -- 只取position=1的记录(第一个操作数)2.关联运算符:
sql
JOIN operators op -- 关联operators表,简称为op
ON c.id = op.cal_id -- 通过cal_id关联3.关联第二个操作数:
sql
JOIN operands o2 -- 再次关联operands表,简称为o2
ON c.id = o2.cal_id -- 通过cal_id关联
AND o2.position = 2 -- 只取position=2的记录(第二个操作数)4.最后的排序和限制部分:
sql
ORDER BY c.created_at DESC -- 按创建时间降序排列(最新记录在前)
LIMIT ? -- 限制返回条数(参数化查询)为什么需要这样设计?
-
数据关联:通过calculation_id将三张表的记录关联起来
-
操作数定位:使用position=1/2区分第一个和第二个操作数
-
结果整合:将分散存储的数据重新组合成完整的计算记录
实际效果:
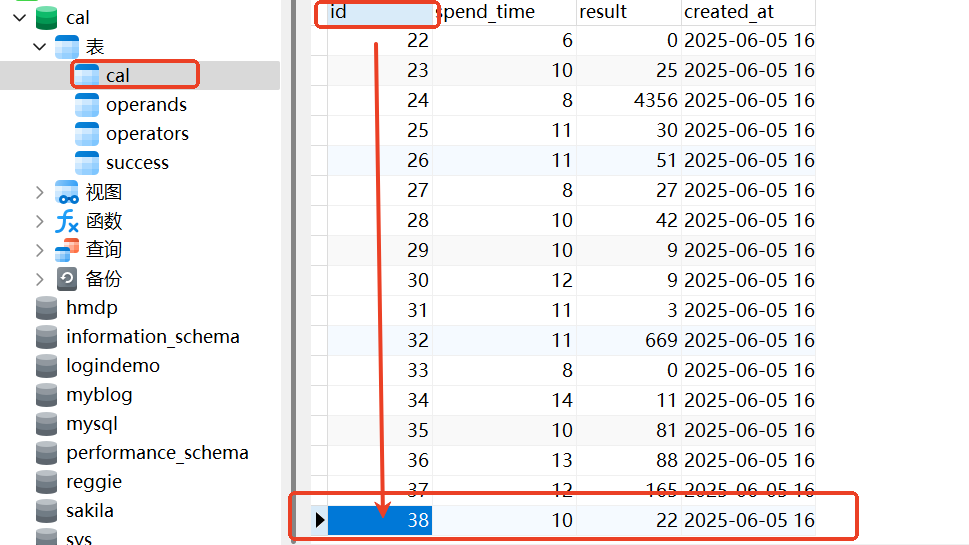
第一步:cal表:比如我们就看这个id=38的,可以知道其耗时10ms,结果是22
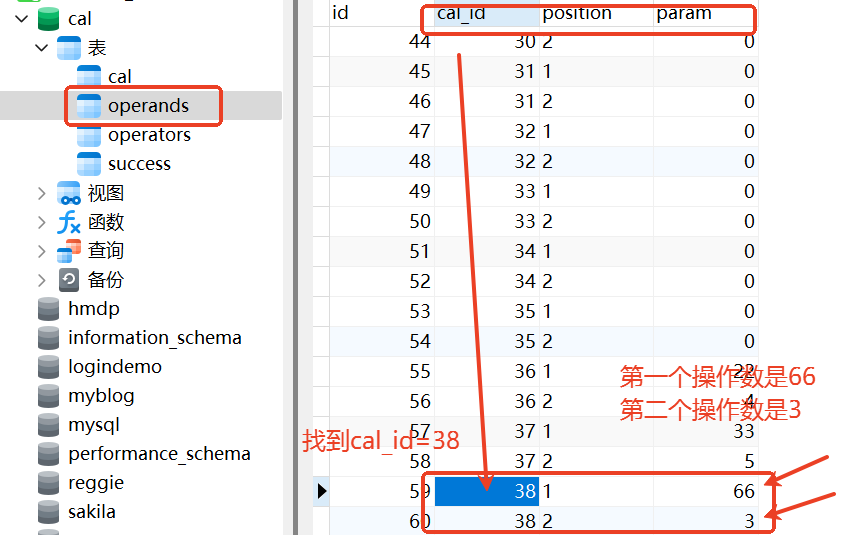
第二步:operands表:找到前面说的38,对应的两个操作数是66和3
第三步:operators表:也是找到38,运算符号是除号
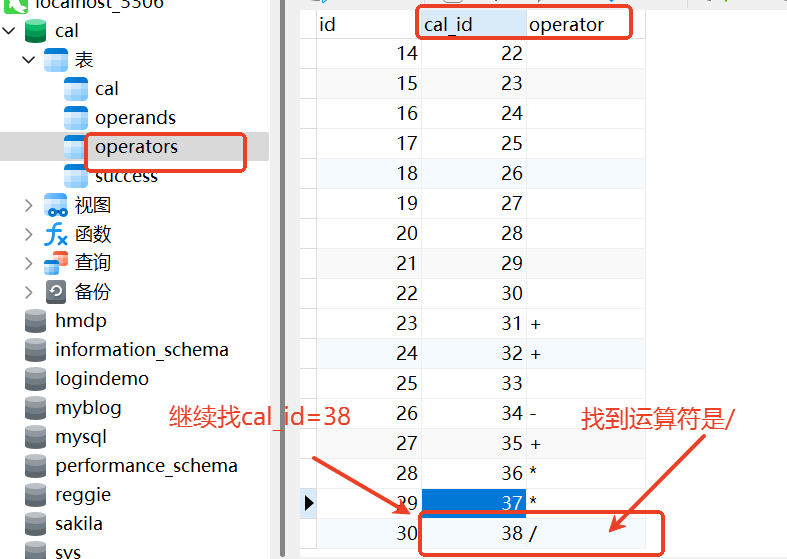
最后:总结可以知道 ,66/3=22没毛病!!