在数据工程领域,软件工程实践 (如版本控制、测试、CI/CD)的引入已成为趋势。尽管像 dbt 这样的工具已经推动了数据建模的标准化,但在测试自动化、工作流管理等方面仍存在不足。
SQLMesh 应运而生,旨在填补这些空白,提供更高效、可靠的数据工程解决方案。本文将深入探讨 SQLMesh 的核心功能、架构设计及其对数据工程实践的影响,并通过一个实战示例展示其优势。

1. 为什么需要SQLMesh?------数据工程的痛点
传统数据工程工作流面临以下挑战:
- 缺乏版本控制:数据模型变更难以追踪,回滚困难。
- 测试效率低:依赖手动验证或复杂的外部测试框架。
- 环境管理复杂:开发、测试、生产环境的数据一致性难以保证。
- 依赖管理薄弱:模型变更可能意外影响下游数据管道。
SQLMesh 通过引入软件工程最佳实践 ,如增量计算、自动化测试、虚拟环境隔离,解决了这些问题。
2. SQLMesh 核心功能解析
2.1 项目结构与配置
SQLMesh 的项目结构与 dbt 类似,但更现代化:
sqlmesh_example/
├── config.yml # 项目配置(数据库连接、SQL方言等)
├── audits/ # 数据质量检查(类似dbt的"data tests")
├── macros/ # 自定义SQL宏(支持Jinja,但更强大)
├── models/ # 数据模型定义(SQL文件内嵌元数据)
├── seeds/ # CSV/JSON数据导入
└── tests/ # 单元测试(输入vs输出验证)关键改进:
- 元数据直接嵌入SQL:无需额外YAML文件,提升可读性。
- 更强大的宏系统:支持SQL语义解析,而不仅是字符串替换。
2.2 测试与数据质量
SQLMesh 的测试框架强调轻量级、自动化:
- 单元测试 :通过
tests/目录定义输入输出对,快速验证模型逻辑。 - 数据审计(Audits):类似dbt的"data tests",但更灵活。
示例:
-- models/example_model.sql
SELECT
user_id,
COUNT(*) AS event_count
FROM events
GROUP BY user_id
# tests/example_model_test.yml
tests:
- name: "event_count_positive"
sql: "SELECT * FROM {{ ref('example_model') }} WHERE event_count < 0"
expect: "EMPTY" # 确保无负值2.3 虚拟数据环境(Virtual Data Environments)
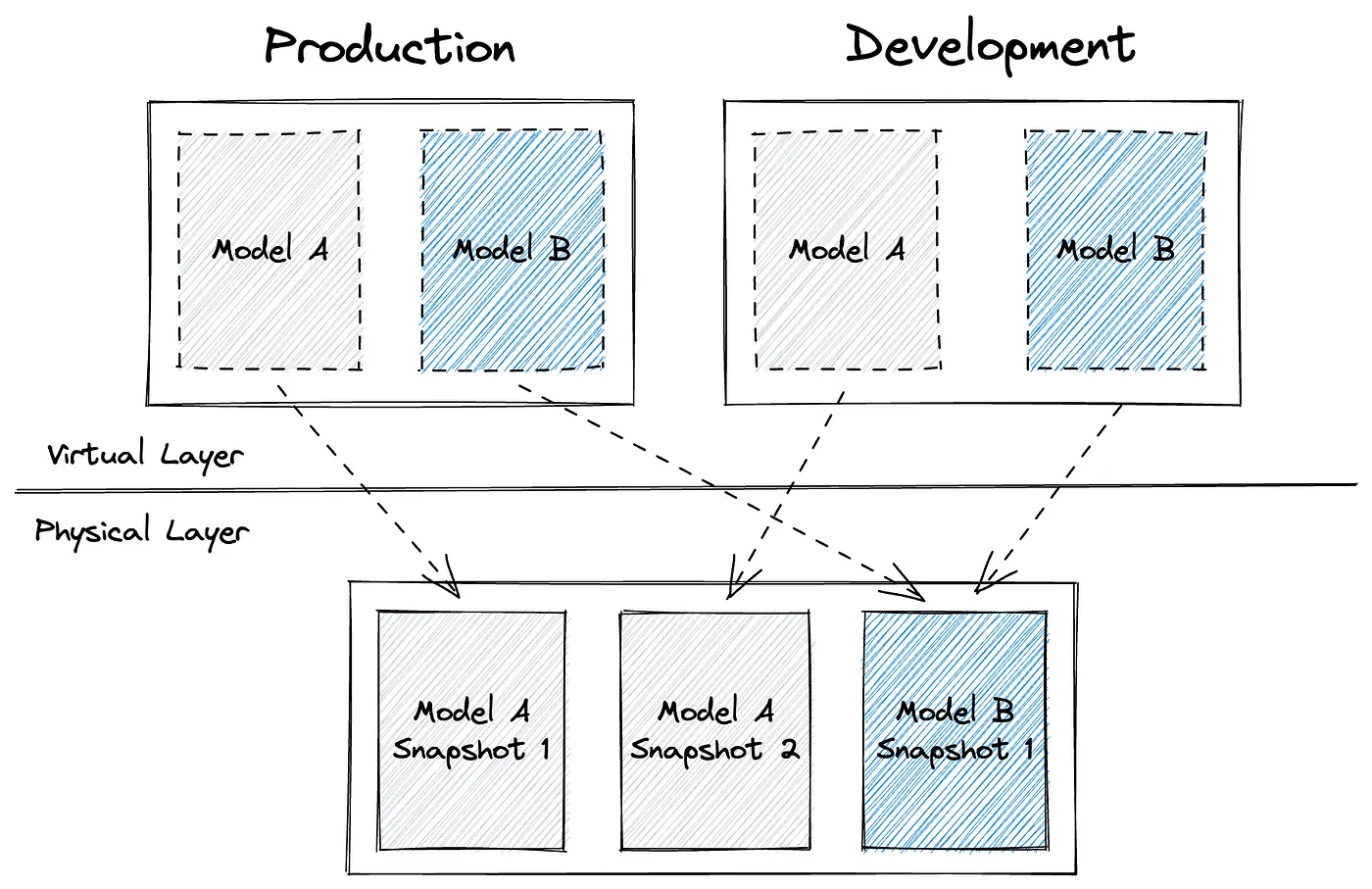
SQLMesh 的核心创新 是Virtual Data Environments,它通过以下机制实现高效版本管理:
- 物理快照(Snapshots) :每次
sqlmesh plan生成新版本快照。 - 虚拟视图(Virtual Views) :环境(如
dev/prod)指向最新快照,实现无缝切换。 - 依赖感知变更:指纹系统自动检测影响范围,避免意外破坏下游数据。
工作流示例:
# 初始化开发环境
sqlmesh plan dev # 创建dev虚拟视图,指向最新快照
# 修改模型后重新计划
sqlmesh plan dev # 生成新快照,更新dev视图
# 回滚到旧版本
sqlmesh rollback # 无需重跑数据,直接切换视图优势:
- 零数据重处理:回滚仅需切换视图指针。
- 自动化依赖管理:避免手动追踪模型依赖。
3. SQLMesh vs dbt:关键差异
| 功能 | SQLMesh | dbt |
|---|---|---|
| 版本控制 | 虚拟环境 + 快照,支持回滚 | 依赖Git,无内置版本回滚机制 |
| 测试框架 | 轻量级单元测试(输入/输出验证) | 支持"data tests",但需手动编写SQL |
| 宏系统 | 支持SQL语义解析,更强大 | 基于Jinja,功能有限 |
| 环境管理 | 物理快照 + 虚拟视图隔离 | 依赖profiles.yml多环境配置 |
| 增量计算 | 原生支持 | 需手动配置is_incremental() |
SQLMesh 的独特价值:
- 更快的反馈循环:单元测试直接嵌入工作流。
- 更安全的变更管理:虚拟环境避免"破坏性更新"。
- 更少的运维负担:Janitor自动清理旧快照。
4. 实战示例:从零搭建SQLMesh项目
4.1 环境准备
git clone https://github.com/data-max-hq/sqlmesh_example
cd sqlmesh_example
python3 -m venv .venv
source .venv/bin/activate
pip install "sqlmesh[postgres,web]"4.2 定义模型与测试
-
编辑
models/example_model.sql,编写SQL逻辑。 -
在
tests/目录添加测试用例(YAML格式)。 -
运行测试:
sqlmesh test
4.3 部署到生产
# 计划生产环境变更
sqlmesh plan prod
# 应用变更(生成新快照)
sqlmesh apply prod5. 总结与展望
SQLMesh 通过Virtual Data Environments 和自动化测试,正在重新定义数据工程的最佳实践。它的优势包括:
- 更可靠的版本控制:告别"数据回滚噩梦"。
- 更高效的协作:Git友好 + 环境隔离。
- 更快的迭代速度:轻量级测试框架。
尽管 dbt 仍是市场领导者,但 SQLMesh 在测试自动化、变更管理 方面的创新值得关注。对于追求工程化数据管道的团队,SQLMesh 提供了一个值得尝试的替代方案。