对于Hadoop配置本地存储路径:
<property><name>dfs.datanode.data.dir</name><value>file:///dfs/data</value></property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///mnt/datadir1/data,/mnt/datadir2/data,/mnt/datadir3/data</value>
</property>
- 可以严格按照XML换行和缩进格式配置,也可以配置到一行中;
- 可以带file://前缀也可以不带;
注: 在 Hadoop 的配置中,dfs.datanode.data.dir 是用来指定本地文件系统上的目录路径。默认情况下,Hadoop 会将这些路径解释为本地文件系统上的路径,因此不需要显式地添加 file:/// 前缀。
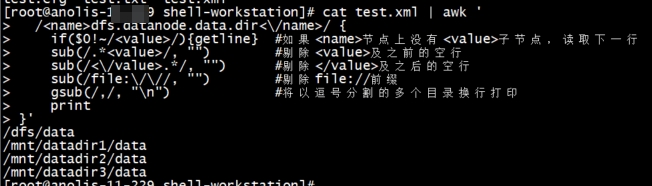
awk是行处理工具,那么如何处理这种结构化的数据块呢?并且要兼顾单行和多行配置。
其实也不难。。
bash
sudo cat "$hadoop_conf/hdfs-site.xml" | awk '
/<name>dfs.datanode.data.dir<\/name>/ {
if($0!~/<value>/){getline} #如果<name>节点上没有<value>子节点,读取下一行
sub(/.*<value>/, "") #剔除<value>及之前的空行
sub(/<\/value>.*/, "") #剔除</value>及之后的空行
sub(/file:\/\//, "") #剔除file://前缀
gsub(/,/, "\n") #将以逗号分割的多个目录换行打印
print
}'效果如下:
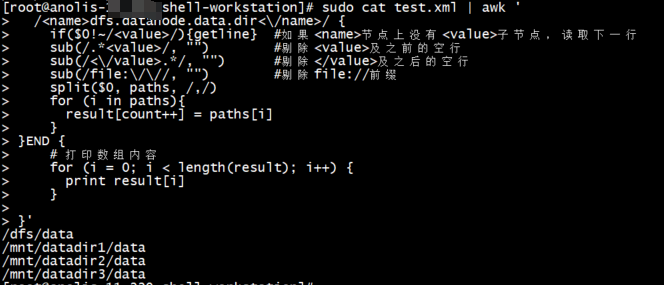
如果集合不直接打印,而是要封装成集合,以待后续处理呢?
bash
sudo cat "$hadoop_conf/hdfs-site.xml" | awk '
/<name>dfs.datanode.data.dir<\/name>/ {
if($0!~/<value>/){getline}
sub(/.*<value>/, "")
sub(/<\/value>.*/, "")
sub(/file:\/\//, "")
split($0, paths, /,/)
for (i in paths){
result[count++] = paths[i]
}
}END {
# 打印数组内容
for (i = 0; i < length(result); i++) {
print result[i]
}
}'这里为啥要将paths集合中的数据倒腾到result数组中,知道为啥吗?
效果如下: