作者:SkyXZ
CSDN:SkyXZ~-CSDN博客
博客园:SkyXZ - 博客园
在机器人或智能车的自主导航任务中,视觉巡线是一项最为基础且关键的能力之一。通过摄像头实时获取道路图像,并基于图像信息判断行驶路径,是实现智能车自动行驶的前提。其中,"滑动窗口 + 直方图"法作为一种经典的视觉巡线策略,因其实现简单、效果稳定、对环境适应性强,广泛应用于竞赛与实际项目中。接下来我将趁着学弟参加比赛的机会,手把手带着大家理解并实现这一经典纯视觉的巡线策略
一、滑动窗口 + 直方图算法原理解析
(1)什么是图像直方图
图像直方图是用来表现图像中亮度分布的一种数据图表,其给出的是图像中某个亮度或者某个范围亮度下像素的多少,即能统计一幅图在某个坐标下有效像素数量。其计算代价较小,且具有图像平移、旋转、缩放不变性等众多优点,因此广泛地应用于图像处理的各个领域,特别是灰度图像的阈值分割、基于颜色的图像检索以及图像分类,因此在纯视觉巡线的任务中,直方图可以比较清除的显示车道线(或引导线)在图像中的位置。特别是在处理已经经过二值化处理的图像时(如黑白图像中,白色为车道线,黑色为背景),可以通过统计图像某一区域(如下半部分)的垂直方向像素分布,快速定位车道线的起始位置。
如下图所示,我们通常对图像的底部进行水平方向(X轴)的直方图统计,找到像素值为1(或255)的像素在每一列的数量,从而绘制出一个表示白色像素数量随水平位置变化的图像直方图,在这幅直方图中出现峰值的位置,往往就是左右车道线起始位置所在的区域

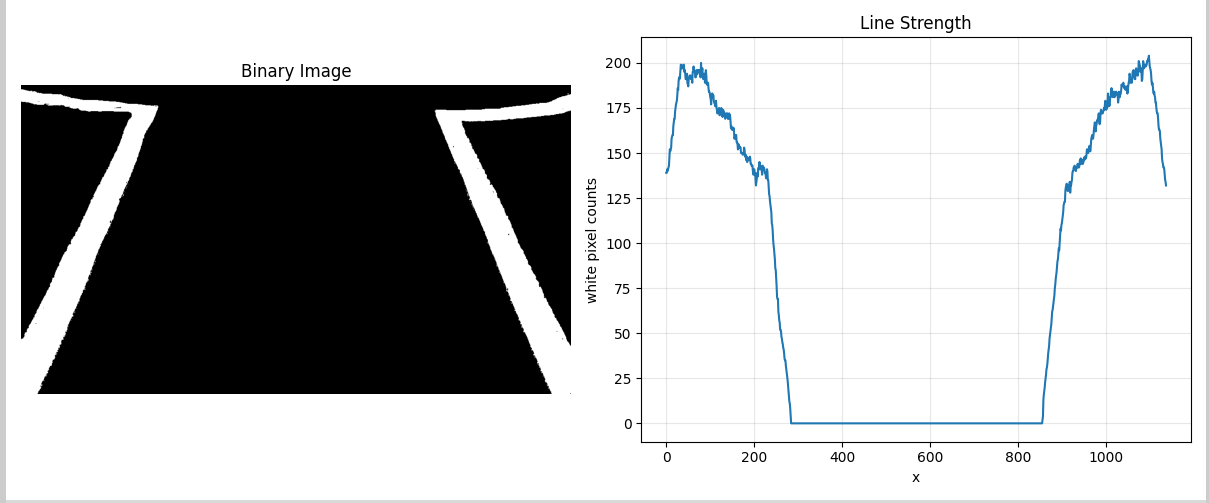
相比于其他的巡线算法,这一寻找直方图的过程不仅计算量小,而且对图像噪声有一定的鲁棒性,因此非常适合作为滑动窗口法的初始定位步骤。有了直方图的辅助,我们可以快速粗略判断左右车道线的大致位置,为后续的滑窗跟踪打下基础。
示例用到的代码如下,仅供参考:
python
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
yellow_low = [20, 100, 100]
yellow_up = [30, 255, 255]
img = cv.imread('road.png')
hsv = cv.cvtColor(img, cv.COLOR_BGR2HSV)
mask = cv.inRange(hsv, np.array(yellow_low), np.array(yellow_up))
# 计算沿x轴方向每列的白色像素数量
height, width = mask.shape
x_positions = np.arange(width)
white_pixel_counts = np.sum(mask == 255, axis=0)
# 显示结果
plt.figure(figsize=(12, 5))
plt.subplot(121)
plt.imshow(mask, cmap='gray')
plt.title('Binary Image')
plt.axis('off')
plt.subplot(122)
plt.plot(x_positions, white_pixel_counts)
plt.title('Line Strength')
plt.xlabel('x')
plt.ylabel('white pixel counts')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()(2)什么是滑动窗口法
滑动窗口法(Sliding Window Method)是一种经典的图像区域搜索方法,广泛应用于目标检测、路径提取等视觉任务中。在视觉巡线中,它的核心思想是:固定一个长宽一定的窗口,从整幅图像下方开始,沿垂直方向逐步上移,通过滑动"窗口"在每一个窗口内部的图像中寻找我们期望目标的位置,并不断调整窗口的中心位置以跟随寻找我们的目标对象。
而在我们纯视觉巡线的具体任务中我们通过直方图法确定了左右车道线在图像底部的大致位置,那么底部的位置便可以作为我们第一个滑动窗口的中心点,接着我们便可将图像沿垂直方向划分为若干水平层,每层设置一个固定大小的窗口(通常为矩形)。从底部向上依次遍历每一层并在每一个滑动窗口区域中,统计白色像素(即二值化后的车道线像素)的位置,如果超过一定数量,则认为找到了车道线位置。而我们可以根据窗口内的像素分布计算质心(如平均X坐标),并以此更新下一层滑动窗口的中心位置,从而实现"跟踪"车道线的效果。
其有几个主要的参数,分别是:
- 窗口数量(
nwindows):即图像在垂直方向被划分为多少层。该值越大,滑动窗口越密集,精度越高,但计算量也随之增加。一般取 8~15 层较为合理。 - 窗口高度(
window_height):由图像高度除以窗口数量确定,每个滑窗在垂直方向的尺寸。窗口高度越小,每层的"扫描"范围越细,有助于追踪曲线,但对图像噪声也更敏感。 - 窗口宽度(
margin):窗口在水平方向的搜索半径,即从当前中心向左右扩展多少像素作为当前层的检测区域。该参数直接影响车道线捕获的"包容性",通常设置为 50~100 像素。 - 最小像素阈值(
minpix):当某一层窗口中白色像素数量超过该值时,认为当前窗口中存在车道线,并据此更新窗口中心。若像素数小于该值,则保持上一层的中心点。这一参数有助于抑制噪声干扰,常设置为 50~100。
如下图展现所示:
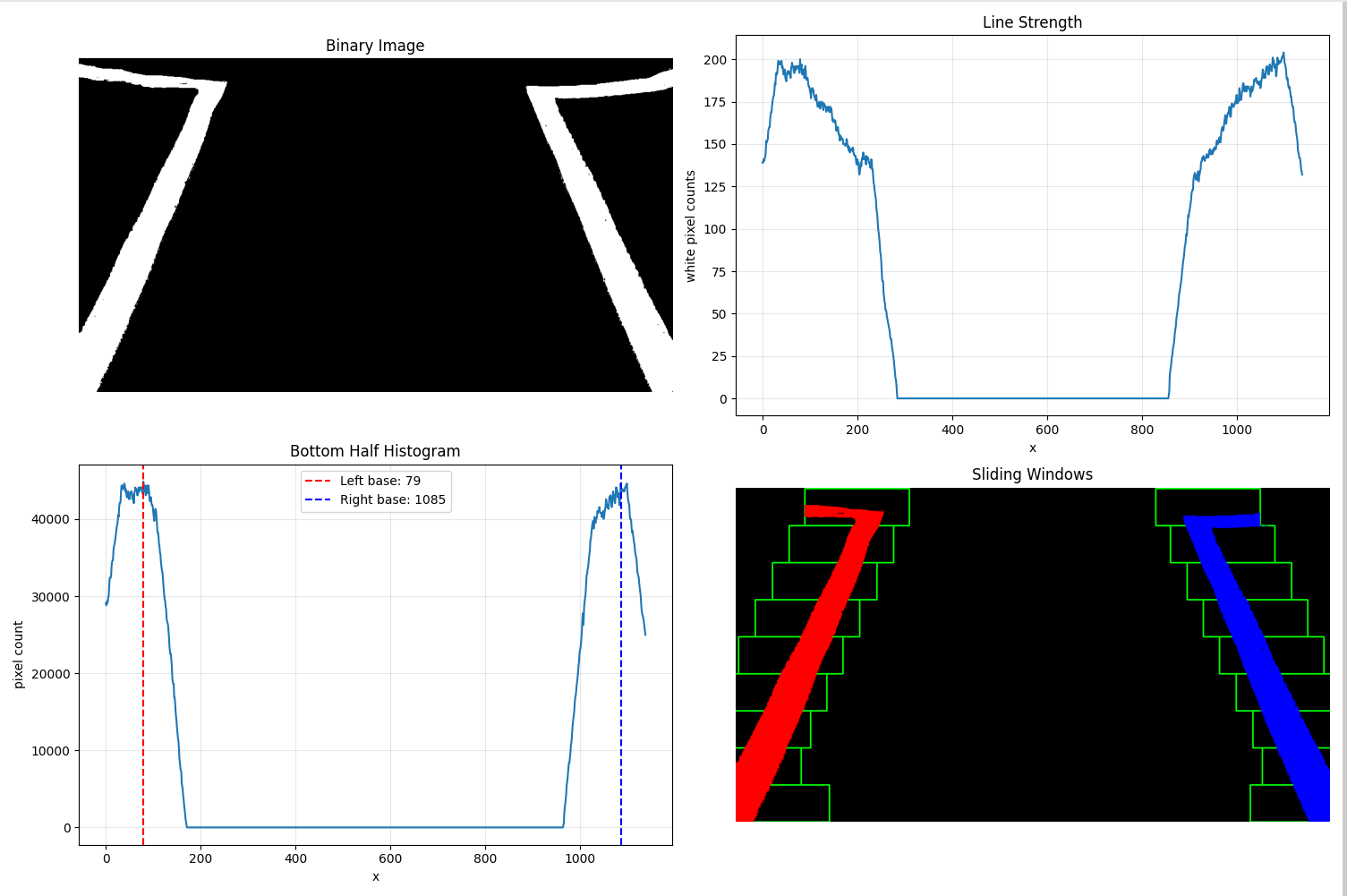
使用这个方法获取的车道线鲁棒性强,即使车道线弯曲、有轻微遮挡,滑窗也能较好地进行跟踪;具体实现见第二章实战部分
(3)路径拟合的基本原理
在滑动窗口法中,我们从图像中提取到了若干条白色像素点的坐标,这些点大致分布在车道线或引导线的轨迹上。为了将这些离散点转化为一条连续、光滑的曲线以用于导航控制,我们通常会采用曲线拟合的方法。其中,最常用的是二阶多项式拟合, y = Ax\^2 + Bx + C\\(,或者换个角度(在巡线任务中更常见):\\)x = Ay\^2 + By + C 这里的 x和y 是图像中的像素坐标,A,B,C是拟合出的多项式系数。由于图像中车道线是沿垂直方向延伸的,因此我们更倾向于以 纵轴 y 为自变量,以便更稳定地拟合整条线。我们可以使用NumPy包中的np.polyfit来实现多项式拟合
python
fit = np.polyfit(y_vals, x_vals, 2) # 得到 A, B, C 系数根据拟合结果,可以计算车道线中点、偏离中心的距离、曲率半径等信息,为后续的舵机转向或PID控制提供输入
二、实战步骤详解:构建你的视觉巡线系统
接下来我来带着大家手把手实现一个属于你自己的视觉巡线系统,整个流程涵盖从图像获取、预处理,到车道线提取、拟合与偏差计算,适用于各类巡线场景。我们使用 Python 作为实现语言,使用 OpenCV + NumPy 作为实现工具,思路清晰,代码简洁,便于复现与调试,出于对大家学习效果的考量,本Blog将不提供完整直接可用的代码,仅根据下方各章节的内容提供分模块的代码教学,在认真学习完后可以快速构建属于自己的巡线系统
(1)摄像头标定与透视变换
在计算机视觉领域,我们是将三维物体转换到二维平面,这就需要确定空间物体表面某点的三维几何位置与其在二维图像中对应点之间的相互关系,这又需要建立摄像头成像的几何模型,而这些几何模型的参数就是摄像头参数,包括内参、外参、畸变参数等。而我们进行标定的目的便是求出摄像头的内、外参数,以及畸变参数,进而可以建立摄像头成像的几何模型。在我们的视觉巡线任务中,图像的几何畸变会影响后续处理效果。尤其是视角变形 (Perspective distortion),会导致车道线在图像中呈现非线性弯曲,影响定位准确性。因此我们便需要对摄像头进行畸变矫正,标定我们主要使用的是张正友标定法,ROS中可以直接使用camera_calibration来实现,而如果想自己进行标定的话,推荐大家一篇文章:自动驾驶感知------摄像头标定(相机标定)及张正友标定法(张氏标定法) - 知乎来学习实现,这里我们便不展开叙述了
而透视变换是做什么用处的呢?前面我们说了,我们的这套巡线的核心是使用直方图来确定车道线的起始点,我们的车道线原先是一个平行的结构 ,而在我们正常的摄像头视角里,车道线却是一个有透视畸变的梯形结构 ------ 离摄像头近的部分看起来宽,远处看起来窄,这种"收缩感"会导致车道线在图像中的形状发生变化,这便带来两个问题:一是直方图波峰位置不稳定 ,由于车道线宽度不一致,底部像素密集而顶部稀疏,直方图往往只在底部区域有效,无法获得整个车道的分布信息;二是滑动窗口漂移严重,车道线的非平行投影会让滑窗误判车道边界,尤其在弯道或转角处更明显。
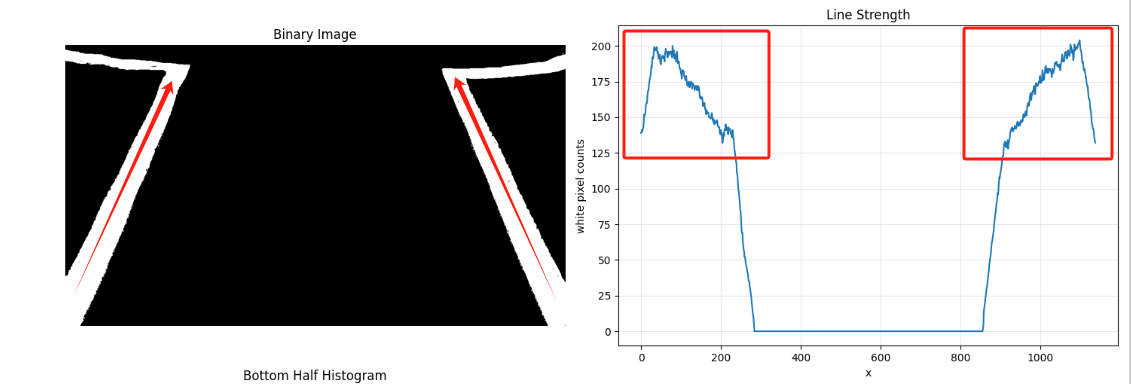
因此,我们可以通过透视变换将原图中呈梯形的车道区域"拉伸"成一个标准的矩形视图,也就是常说的"俯视图"(Bird's-eye View),让车道线在图像中看起来像是在平地上的两条平行直线 。这样不仅能使车道线宽度保持一致 ,从而提升直方图提取的稳定性,还能提高滑动窗口的定位精度,使拟合曲线更加平滑。同时,这种视角变换也便于进行几何测量 ,例如计算车辆的横向偏移和航向角,并在处理弯道等复杂场景时表现出更强的鲁棒性。具体的效果如下:
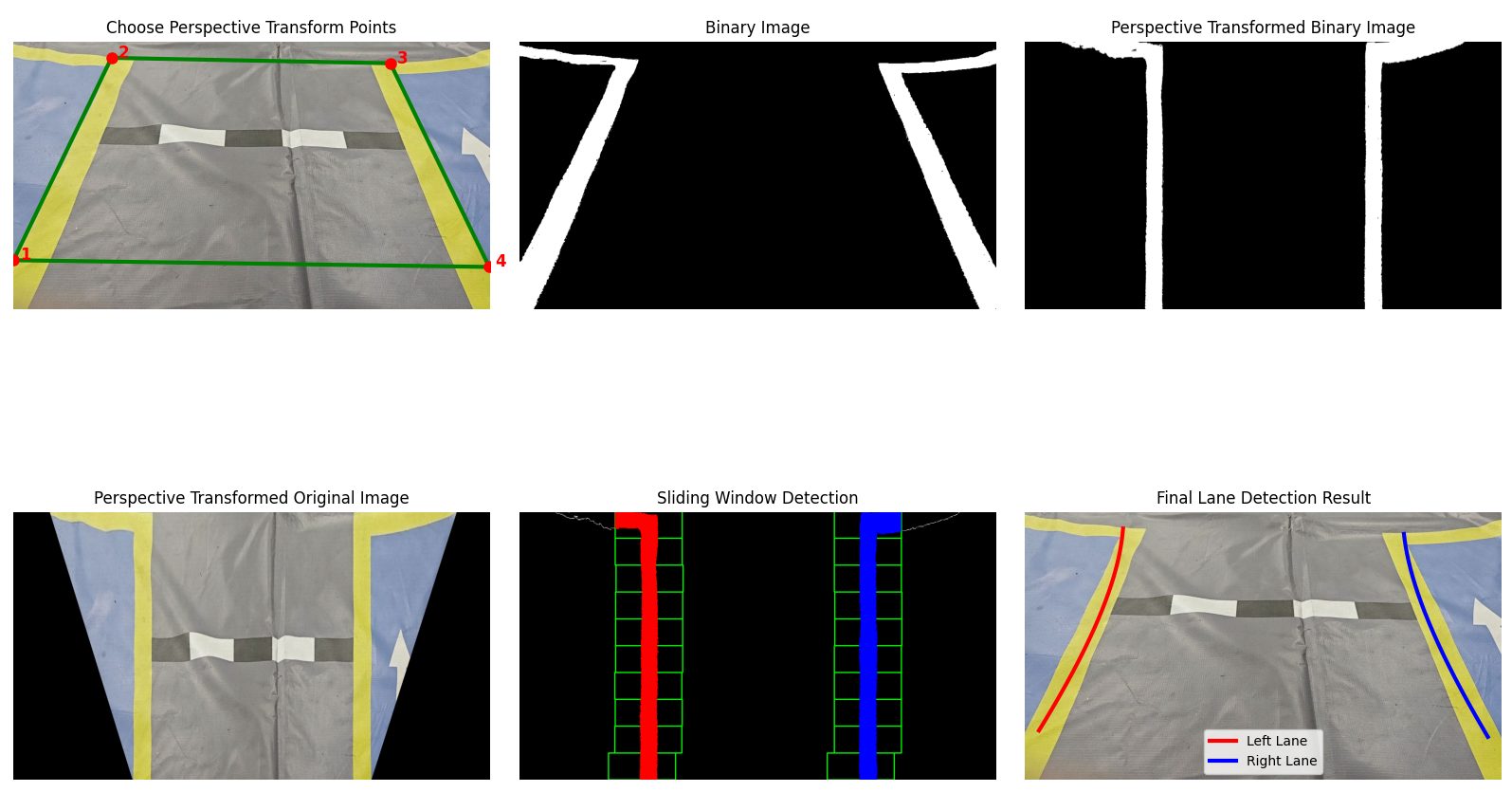
接下来我们首先完成一个小工具,用来选择图像车道线的矩形区域获取四个点来实现对车道线的透视变换,这里没有什么难度,主要就是使用OpenCV打开摄像头显示图像然后利用鼠标回调事件来点击图像选择目标点,因此不做过多解释,自行浏览代码中的注释进行理解
python
import cv2 as cv
import numpy as np
points = [] # 存储选择的四个点
img_original = None # 原始图像
img_display = None # 用于显示的图像副本
def mouse_callback(event, x, y, flags, param):
"""鼠标回调函数 - 当鼠标点击时被调用"""
global points, img_display
# 检查是否是左键点击
if event == cv.EVENT_LBUTTONDOWN:
# 如果还没有选择4个点
if len(points) < 4:
# 添加点击的坐标到列表
points.append([x, y])
print(f"选择了第 {len(points)} 个点: ({x}, {y})")
# 在图像上绘制圆点标记选择的位置
cv.circle(img_display, (x, y), 5, (0, 255, 0), -1)
# 在点旁边显示点的编号
cv.putText(img_display, str(len(points)), (x+10, y-10),
cv.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
# 如果已经选择了4个点,连接成多边形
if len(points) == 4:
# 将点转换为numpy数组
pts = np.array(points, np.int32)
# 绘制多边形边框
cv.polylines(img_display, [pts], True, (255, 0, 0), 2)
print("已选择4个点!")
print("选择的坐标:", points)
# 更新显示
cv.imshow('选择四个点', img_display)
def reset_points():
"""重置选择的点"""
global points, img_display
points = []
img_display = img_original.copy()
cv.imshow('选择四个点', img_display)
print("重新选择点...")
def main():
"""主函数"""
global img_original, img_display
# 读取图像
img_original = cv.imread('road.png')
if img_original is None:
print("无法读取图像 'road.png',请确保文件存在")
return
# 创建显示用的图像副本
img_display = img_original.copy()
# 创建窗口并设置大小
cv.namedWindow('选择四个点', cv.WINDOW_NORMAL)
cv.resizeWindow('选择四个点', 800, 600)
# 设置鼠标回调函数
cv.setMouseCallback('选择四个点', mouse_callback)
# 显示图像
cv.imshow('选择四个点', img_display)
print("=== 透视变换点选择工具 ===")
print("请用鼠标左键点击选择4个点")
print("建议按顺序选择:左下 -> 左上 -> 右上 -> 右下")
print("操作说明:")
print(" - 鼠标左键:选择点")
print(" - r键:重新选择点")
print(" - ESC键:退出程序")
# 主循环
while True:
key = cv.waitKey(1) & 0xFF
if key == 27: # ESC键 - 退出
break
elif key == ord('r'): # r键 - 重新选择
reset_points()
cv.destroyAllWindows()
return points
if __name__ == "__main__":
selected_points = main()
print(f"最终选择的四个点: {selected_points}")在我们获取了我们的四个目标点src_points后我们便可以将这四个目标点拉伸透视变换到我们的目标点dst_points,也就是把原本的梯形车道区域"拉"成规则矩形。通常,dst_points 会被设为输出图像的四个角,例如 [[0,0], [w,0], [0,h], [w,h]],这样就能得到一个尺寸为 (w, h) 的俯视图,们一般不会直接使用图像的四个角作为目标点,这是因为这样做虽然能完成变换,但未必能保证变换后的车道线位于图像中心或比例合适,可能导致变换结果失真或信息丢失。为了更合理地展示车道线,我们通常会自定义一个"矩形区域" 作为目标区域 dst_points,例如将目标区域的位置稍微向中间偏移,或者缩放到更适合视觉分析的大小,使变换后的俯视图既包含完整的车道信息,又便于后续的滑动窗口操作、拟合和可视化叠加。在这里我们使用如下作为我们的dst_points,同时实现透视变换只需调用如下三个函数即可实现:
python
dst_points = np.float32([
[img_width * 0.25, img_height], # 左下
[img_width * 0.25, 0], # 左上
[img_width * 0.75, 0], # 右上
[img_width * 0.75, img_height] # 右下
])# 需与前面的src_point保持点顺序一致
M = cv2.getPerspectiveTransform(src_points, dst_points) # 透视变换矩阵
Minv = cv2.getPerspectiveTransform(dst_points, src_points) # 逆变换矩阵(后续把结果投回原图时用)
warped = cv2.warpPerspective(frame, M, (img_width, img_height)) # 得到俯视图其中 M 是 3 × 3 的透视变换矩阵,warped 就是拉直后的车道图像。通过这一步,我们把原先在图像中呈梯形收缩的车道线拉伸为平行直线,不仅让直方图峰值位置更稳定、滑动窗口跟踪更准确,也方便后续用 Minv 将拟合好的车道线重新绘制回原始视角,实现可视化叠加与偏差计算,实现代码如下:
python
import cv2 as cv
import numpy as np
img = cv.imread("road.png")
img_height, img_width = img.shape[:2]
src_points = np.float32([
[0,522],
[234,39],
[900,52],
[1136,538]
])
dst_points = np.float32([
[img_width * 0.25, img_height], # 左下
[img_width * 0.25, 0], # 左上
[img_width * 0.75, 0], # 右上
[img_width * 0.75, img_height] # 右下
])
M = cv.getPerspectiveTransform(src_points, dst_points)
warped = cv.warpPerspective(img, M, (img_width, img_height))
cv.imshow("img",img)
cv.imshow("warped",warped)
cv.waitKey(0)
cv.destroyAllWindows()特别注意的是,如果我们在后续通过图像中心点以及车道中心点来计算偏差的话,我们在这里可以获取一下透视变换后的车道线宽度,如果我们不对选取的车道线进行外延处理的话,那么车道线宽度就是变换后的图像宽度,如果我们进行了延拓的话,那么车道线宽度就是图像宽度减去两边外延宽度之和,在这里即:
python
line_width = int(img_width * 0.75 - img_width * 0.25) # 透视变换后车道线宽度(2)获取并预处理图像
在完成摄像头的标定和透视变换点的选取之后,我们就可以正式开始视觉巡线系统的代码编写了。第一步是图像的获取,这一部分相对简单,我们可以通过读取摄像头帧(如 OpenCV 的 cv2.VideoCapture)或读取本地视频/图像文件来完成。为了提高处理效率并实现帧的连续处理,我们可以使用一个队列(Queue) 来缓存摄像头获取的图像帧,从而避免因处理速度波动而丢帧。我们只需要每次取上一帧即可:
python
import cv2 as cv
from collections import deque
cap = cv.VideoCapture("road.mp4")
frame_queue = deque(maxlen=2)
while True:
ret, frame = cap.read()
if not ret:
break
# 将当前帧加入队列
frame_queue.append(frame.copy())
# 显示上一帧(如果存在)
if len(frame_queue) > 1:
last_frame = frame_queue[0]
cv.imshow("frame", last_frame)
if cv.waitKey(1) & 0xFF == ord('q'):
break
cap.release()接着我们对图像进行预处理,在这里我们可以先对图像进行透视变换然后通过阈值或是其他方法将车道线提取出来实现对图像的二值化处理,同时为提升直方图的提取效果我们可以开闭运算来消除图像中的部分噪点,具体如下:
python
def process_frame(frame):
src_points = np.float32([
[0, 522],
[234, 39],
[900, 52],
[1136, 538]
])
dst_points = np.float32([
[frame.shape[1] * 0.25, frame.shape[0]], # 左下
[frame.shape[1] * 0.25, 0], # 左上
[frame.shape[1] * 0.75, 0], # 右上
[frame.shape[1] * 0.75, frame.shape[0]] # 右下
])
# 完成透视变换
M = cv.getPerspectiveTransform(src_points, dst_points)
warped = cv.warpPerspective(frame, M, (frame.shape[1], frame.shape[0]))
# 转换为HSV并提取黄色车道线
hsv_warped = cv.cvtColor(warped, cv.COLOR_BGR2HSV)
yellow_low = [20, 100, 100]
yellow_up = [30, 255, 255]
mask = cv.inRange(hsv_warped, np.array(yellow_low), np.array(yellow_up))
# 形态学操作处理噪点
kernel = np.ones((5, 5), np.uint8)
eroded = cv.erode(mask, kernel, iterations=1)
dilated = cv.dilate(eroded, kernel, iterations=1)
cv.imshow("dsad",dilated)
return dilated
(3)使用直方图定位初始车道位置
在我们得到了透视变换后的二值车道线图像后,接下来就可以利用图像直方图来确定车道线的初始位置。这里我们主要关注图像下半部分的像素分布,因为车辆当前所处的车道线大多集中在图像底部区域,这一部分的信息更为清晰、可靠。
python3
def get_linebase(frame):
height, width = frame.shape[:2]
# 找到直方图底部一半的峰值作为起始点
histogram = np.sum(frame[height//2:,:], axis=0)
midpoint = len(histogram) // 2
leftx_base = np.argmax(histogram[:midpoint])
rightx_base = np.argmax(histogram[midpoint:]) + midpoint
return leftx_base, rightx_base我们通过 np.sum(frameheight//2:, :, axis=0) 计算了图像下半部分每一列的像素和,形成了一个横向的一维直方图,这个直方图的波峰往往对应着车道线的左右边缘。接着我们将直方图一分为二,通过np.argmax(histogram[:midpoint]) 找到左半边的最大值索引,即左车道线的起始 x 坐标 ;np.argmax(histogram[midpoint:]) + midpoint 找到右半边的最大值索引,加上偏移量后得到右车道线的起始 x 坐标 。最终函数 get_linebase 返回的 leftx_base 和 rightx_base,就是我们滑动窗口搜索的起点,后续滑窗的中心位置将以这两个点为基础进行逐层向上搜索。

(4)应用滑动窗口逐步寻找车道线
在通过直方图获取了左右车道线的起始位置 leftx_base 和 rightx_base 后,我们就可以使用滑动窗口(Sliding Window)方法,其核心思想是:从图像底部开始,依据起始点设置左右两个滑动窗口,然后逐层向上滑动,根据每一层窗口内的有效像素分布不断更新窗口中心,从而实现对车道线的"跟踪"。我们首先先定义我们滑动窗口的基本参数:
python
# 滑动窗口参数
nwindows = 9 # 窗口数量
window_height = height // nwindows # 每个窗口的高度
margin = 100 # 窗口宽度的一半
minpix = 50 # 重新定位窗口中心所需的最小像素数然后我们初始化窗口的起点和所需的变量:
python
leftx_base, rightx_base = get_linebase(frame)
# 创建输出图像来绘制滑动窗口
out_img = np.dstack((mask, mask, mask)) * 255
# 初始化当前位置
leftx_current = leftx_base
rightx_current = rightx_base
# 存储车道线像素的索引
left_lane_inds = []
right_lane_inds = []
# 获取所有非零像素的位置
nonzero = mask.nonzero()
nonzeroy = np.array(nonzero[0])
nonzerox = np.array(nonzero[1])然后开始遍历每一层滑动窗口,查找对应的车道线像素,这一部分代码就是滑动窗口"自适应搜索"的核心。每一层窗口都是基于上一层的结果动态更新中心点位置的,这种做法可以很好地应对弯道和部分缺失的车道线情况。如果某一层像素数量较少,则窗口位置不会改变,保持当前趋势,保证搜索的连贯性和鲁棒性。
python
# 遍历所有窗口
for window in range(nwindows):
# 计算窗口边界
win_y_low = height - (window + 1) * window_height
win_y_high = height - window * window_height
# 左车道线窗口边界
win_xleft_low = leftx_current - margin
win_xleft_high = leftx_current + margin
# 右车道线窗口边界
win_xright_low = rightx_current - margin
win_xright_high = rightx_current + margin
# 在输出图像上绘制窗口
cv.rectangle(out_img, (win_xleft_low, win_y_low), (win_xleft_high, win_y_high), (0, 255, 0), 2)
cv.rectangle(out_img, (win_xright_low, win_y_low), (win_xright_high, win_y_high), (0, 255, 0), 2)
# 找到窗口内的非零像素
good_left_inds = ((nonzeroy >= win_y_low) & (nonzeroy < win_y_high) &
(nonzerox >= win_xleft_low) & (nonzerox < win_xleft_high)).nonzero()[0]
good_right_inds = ((nonzeroy >= win_y_low) & (nonzeroy < win_y_high) &
(nonzerox >= win_xright_low) & (nonzerox < win_xright_high)).nonzero()[0]
# 添加这些索引到列表中
left_lane_inds.append(good_left_inds)
right_lane_inds.append(good_right_inds)
# 如果找到足够的像素,重新计算窗口中心
if len(good_left_inds) > minpix:
leftx_current = int(np.mean(nonzerox[good_left_inds]))
if len(good_right_inds) > minpix:
rightx_current = int(np.mean(nonzerox[good_right_inds]))在滑动窗口完成逐层搜索之后,我们已经得到了每一层中可能属于左右车道线的像素点索引,保存在 left_lane_inds 和 right_lane_inds 中。但此时它们是一个按层存储的二维列表(列表嵌套),为了便于后续处理,我们需要将它们合并为一个一维数组:
python
# 将所有窗口中找到的像素索引连接成一个一维数组
left_lane_inds = np.concatenate(left_lane_inds)
right_lane_inds = np.concatenate(right_lane_inds)接着,利用这些索引,我们就可以从原始的非零像素集合中提取出左右车道线各自的所有像素点坐标了:
python
# 提取左右车道线的所有像素点的x和y坐标
leftx = nonzerox[left_lane_inds]
lefty = nonzeroy[left_lane_inds]
rightx = nonzerox[right_lane_inds]
righty = nonzeroy[right_lane_inds]这样一来,leftx, lefty 表示左车道线上的所有像素点,rightx, righty 表示右车道线的所有像素点。我们可以使用这些坐标进行多项式拟合(例如二次曲线拟合),进而重建车道线的几何模型,实现车道线的平滑重建与可视化。
完整的函数处理如下:
python
def sliding_window_search(mask, leftx_base, rightx_base):
height, width = mask.shape
# 滑动窗口参数
nwindows = 9
window_height = height // nwindows
margin = 100
minpix = 50
# 创建输出图像来绘制滑动窗口
out_img = np.dstack((mask, mask, mask)) * 255
# 初始化当前位置
leftx_current = leftx_base
rightx_current = rightx_base
# 存储车道线像素的索引
left_lane_inds = []
right_lane_inds = []
# 获取所有非零像素的位置
nonzero = mask.nonzero()
nonzeroy = np.array(nonzero[0])
nonzerox = np.array(nonzero[1])
# 遍历所有窗口
for window in range(nwindows):
# 计算窗口边界
win_y_low = height - (window + 1) * window_height
win_y_high = height - window * window_height
# 左车道线窗口边界
win_xleft_low = leftx_current - margin
win_xleft_high = leftx_current + margin
# 右车道线窗口边界
win_xright_low = rightx_current - margin
win_xright_high = rightx_current + margin
# 在输出图像上绘制窗口(修复类型错误)
cv.rectangle(out_img, (int(win_xleft_low), int(win_y_low)),
(int(win_xleft_high), int(win_y_high)), (0, 255, 0), 2)
cv.rectangle(out_img, (int(win_xright_low), int(win_y_low)),
(int(win_xright_high), int(win_y_high)), (0, 255, 0), 2
# 找到窗口内的非零像素
good_left_inds = ((nonzeroy >= win_y_low) & (nonzeroy < win_y_high) &
(nonzerox >= win_xleft_low) & (nonzerox < win_xleft_high)).nonzero()[0]
good_right_inds = ((nonzeroy >= win_y_low) & (nonzeroy < win_y_high) &
(nonzerox >= win_xright_low) & (nonzerox < win_xright_high)).nonzero()[0]
# 添加这些索引到列表中
left_lane_inds.append(good_left_inds)
right_lane_inds.append(good_right_inds)
# 如果找到足够的像素,重新计算窗口中心
if len(good_left_inds) > minpix:
leftx_current = int(np.mean(nonzerox[good_left_inds]))
if len(good_right_inds) > minpix:
rightx_current = int(np.mean(nonzerox[good_right_inds]))
# 连接数组
left_lane_inds = np.concatenate(left_lane_inds)
right_lane_inds = np.concatenate(right_lane_inds)
# 提取左右车道线像素位置
leftx = nonzerox[left_lane_inds]
lefty = nonzeroy[left_lane_inds]
rightx = nonzerox[right_lane_inds]
righty = nonzeroy[right_lane_inds]
# 给车道线像素着色
out_img[lefty, leftx] = [255, 0, 0] # 红色表示左车道线
out_img[righty, rightx] = [0, 0, 255] # 蓝色表示右车道线
return leftx, lefty, rightx, righty, out_img(5)多项式拟合输出拟合曲线
在通过滑动窗口法提取到了左右车道线的像素坐标后,我们可以利用多项式拟合来构建出连续、平滑的车道线模型。由于实际道路中的车道线往往呈现一定的弯曲程度,因此我们通常选择使用二次多项式(即二次曲线) 对提取到的车道线像素点进行拟合,具体函数如下:\(x = Ay^2 + By + C\) ,通过拟合后的多项式函数,我们可以在每一行(y 方向)计算出左右车道线的 x 坐标,从而生成连续的车道曲线。这不仅能让车道线显示得更加平滑,还能够显著提升在曲线路段的鲁棒性。最终,我们可以将这些拟合出的曲线绘制在原图或透视图上,辅助路径规划或偏移计算,这部分仅需使用np.polyfit() 拟合即可
python
def fit_polynomial(leftx, lefty, rightx, righty, img_shape):
height, width = img_shape
# 多项式拟合
left_fit = np.polyfit(lefty, leftx, 2)
right_fit = np.polyfit(righty, rightx, 2)
# 生成拟合曲线上的 y 值
ploty = np.linspace(0, height - 1, height)
# 根据拟合参数计算对应的 x 值
left_fitx = left_fit[0]*ploty**2 + left_fit[1]*ploty + left_fit[2]
right_fitx = right_fit[0]*ploty**2 + right_fit[1]*ploty + right_fit[2]
return left_fit, right_fit, left_fitx, right_fitx, ploty(6)实际应用------计算偏差
完成车道线的拟合后,我们就可以基于拟合结果来估算车辆当前相对于车道中心的横向偏差(Lateral Offset) ,这是视觉巡线中最核心的控制依据之一。首先,我们在图像的最底部(即车辆所在位置对应的图像底边)获取左右车道线的横坐标值,分别记为 left_fitx[-1] 和 right_fitx[-1],二者的平均值即为当前帧所估计的车道中心 lane_center。再获取图像的实际中心点位置 image_center = width // 2,即代表车辆相机的当前中心视角。车辆相对于车道中心的偏差即为这两者之差:
python
offset = image_center - lane_center此时的 offset 单位为像素,如果我们知道图像每个像素代表的实际距离(例如通过标定得到 1 pixel ≈ 3.7 / 700 m),我们就可以将其换算为实际偏移距离,从而反馈给控制器,进行方向调整或打角补偿。更进一步,由于我们拟合出了整条车道线的曲线信息(left_fit 和 right_fit),我们不仅可以计算横向偏差,还可以获得当前车道曲率、车辆偏航角等几何信息。
-
车道曲率(Curvature):通过拟合的二次多项式可计算道路的弯曲程度;
-
车身航向角(Yaw angle):通过底部点处的导数估算当前车辆与车道方向的夹角;
-
预测前方路径:可将拟合曲线延展,进行路径规划和控制前馈。
三、优化技巧与调参建议
(1)滑动窗口参数(数量、宽度、高度)的调试建议
在使用滑动窗口算法进行车道线提取时,不同场景、图像分辨率以及车道线形态的不同都会影响最终的检测效果,因此合理设置滑动窗口的核心参数对于精度与效率的平衡至关重要。以下是主要参数的详细说明及推荐的初始值:
| 参数名 | 作用说明 | 推荐初始值(以720p图像为例) |
|---|---|---|
n_windows |
滑动窗口数量(从图像底部到顶部) | 9 或 10 |
margin |
每个窗口的宽度(左右偏移范围) | 100 ~ 150 px |
minpix |
若窗口内像素数大于该值,则重新定位窗口中心 | 50 ~ 100 |
window_height |
每个窗口的高度(由图像高度 / n_windows 得到) | 自动计算 |
总的来说,我们先固定图像尺寸和透视变换区域,接着从中间参数开始(如 n=9,margin=100,minpix=50)测试几张图,观察窗口是否对准线条,然后据识别结果调整参数:识别不稳?减小 margin,丢失线条?降低 minpix,拟合不光滑?增大 n_windows
(2)多帧融合与卡尔曼滤波
为了提升车道线检测的稳定性和连续性 ,尤其是在帧率不高或图像存在噪声时,我们可以使用**多帧融合或状态估计方法(如卡尔曼滤波)**对拟合结果进行优化。
- 多帧融合:我们可以保存上一帧的拟合参数(如二次曲线系数),然后将当前帧的检测结果与上一帧进行加权平均,用以缓解某一帧检测异常或缺失的问题
python
smooth_fit = alpha * current_fit + (1 - alpha) * previous_fit #其中 alpha 为平滑因子(如 0.7 ~ 0.9)- 卡尔曼滤波应用:我们可以定义状态量为拟合曲线的参数(如
[a, b, c]),然后使用拟合结果作为观测值,由于建模车道线变化为平滑变化过程所以可以用 KF 进行预测 + 更新
| 优势 | 效果说明 |
|---|---|
| 抗噪性提升 | 某一帧检测异常不致影响整体输出 |
| 时序连续 | 曲线变化连续平滑,避免跳动 |
| 可扩展到路径预测 | 滤波器预测的车道线可用于未来路径规划 |
当然,除了这几个优化方法。我们还可以使用动态窗口宽度 (根据车道线曲率动态调整 margin)、带权拟合(给靠近底部的点更高权重,提高近距离识别精度)等多种方法来提高我们拟合巡线的精准度