2.5 云架构
2.5.1 云计算架构中的负载分布架构(Workload Distribution Architecture)
2.5.1.1 基本概念
云计算架构中的负载分布架构(Workload Distribution Architecture)是确保系统高可用性、高性能的核心设计,其核心在于通过智能调度机制将用户请求合理分配到多个服务器节点。
以下从原理、技术实现到应用场景进行系统解析:
核心原理与组件
-
负载均衡器的作用
-
流量调度中枢:作为前端请求的统一入口,负载均衡器基于预设算法(如轮询、最小连接数)动态分配流量至后端服务器集群。
-
健康检查机制:实时监控服务器状态(如响应时间、连接数),自动剔除故障节点,确保服务连续性。
-
会话保持:通过IP哈希或Cookie绑定,保障同一用户请求由同一服务器处理(如电商购物车场景)。
-
-
关键算法对比
算法类型 工作原理 适用场景 轮询(Round Robin) 按顺序轮流分配请求至各服务器 服务器性能相近的稳态流量环境 加权轮询 根据服务器性能分配权重(如CPU/内存),高性能节点承接更多请求 异构服务器集群 最小连接数 优先选择当前活跃连接最少的服务器 长连接服务(如数据库、实时通信) IP哈希 根据客户端IP哈希值固定分配服务器 需会话一致性的应用(用户登录态) 响应时间优先 选择响应最快的服务器(需实时监控) 对延迟敏感的业务(游戏、金融交易)
技术实现方式
-
硬件负载均衡
-
代表设备:F5 BIG-IP、Citrix NetScaler。
-
优势:高性能(百万级并发)、硬件级冗余、支持SSL加速等高级功能。
-
局限:成本高昂,扩展性依赖物理设备。
-
-
软件负载均衡
-
开源方案:Nginx(HTTP/HTTPS反向代理)、HAProxy(TCP层负载均衡)。
-
优势:灵活配置、低成本、易于集成容器化环境(如Kubernetes Ingress)。
-
-
云原生负载均衡服务
-
平台方案:AWS ALB/ELB、阿里云SLB。
-
特性:
-
弹性伸缩:根据流量自动增减后端实例。
-
跨可用区容灾:多AZ部署保障高可用。
-
按需付费:避免资源闲置成本。
-
-
应用场景与优化实践
-
高并发网站
-
架构设计:
-
前端Nginx分发请求至应用服务器集群(如Tomcat)。
-
数据库层采用读写分离+缓存(Redis),减轻后端压力。
-
-
案例:电商大促期间,通过加权轮询将流量导向扩容的服务器组,峰值QPS提升3倍。
-
-
微服务架构
-
服务网格集成:
-
使用Istio或Linkerd实现服务间负载均衡,动态调整流量权重(如金丝雀发布)。
-
结合熔断机制(Hystrix)避免雪崩效应。
-
-
-
混合云与边缘计算
-
云爆发架构(Cloud Bursting):
-
本地数据中心满载时,自动将流量"爆发"至公有云。
-
关键技术:
-
状态同步:通过分布式存储(如Redis Cluster)保持会话数据一致。
-
智能路由:基于延迟和成本选择最优云节点。
-
-
-
未来趋势
-
AI驱动的自适应调度
- 利用LSTM预测流量峰值,动态调整算法参数(如权重)。
- 结合强化学习优化资源分配,降低响应延迟20%以上。
-
服务网格与边缘融合
- 边缘负载均衡:在CDN节点就近处理请求(如视频流分发),减少回源延迟。
- 5G场景适配:低延迟需求推动负载均衡下沉至基站侧(MEC)。
-
安全与性能一体化
- 负载均衡器集成WAF、DDoS防护,实现"零信任"流量过滤。
2.5.1.2 架构思路
以下是云计算领域中负载分布架构的系统化解析,综合设计方法、原则、关键技术及应用实践:
负载分布架构方法
- 分层调度架构
-
全局负载均衡(GLB):跨地域分配流量(如DNS轮询或Anycast),结合CDN边缘节点降低延迟。
-
本地负载均衡(LLB):在单数据中心内通过Nginx/HAProxy分发请求至服务器集群,采用轮询、最小连接数等算法。
-
服务网格集成:基于Istio/Linkerd实现微服务间动态流量管理,支持金丝雀发布和故障注入。
- 弹性伸缩架构
-
水平扩展:Kubernetes HPA根据CPU/内存指标自动增减Pod实例。
-
云爆发(Cloud Bursting):本地资源满载时,将流量分流至公有云(如AWS + 私有云混合架构)。
-
混合云调度:跨公有云、私有云资源池统一调度(如OpenStack跨云管理)。
- 智能路由架构
-
AI驱动调度:LSTM预测流量峰值,强化学习动态调整权重(如阿里云智能负载均衡)。
-
基于内容的分配:按请求类型(视频流/API调用)定向分发至专用服务器集群。
设计原则与设计思路
核心设计原则
-
高可用性
-
冗余部署:跨可用区(AZ)多副本 + 健康检查自动剔除故障节点。
-
会话保持:IP哈希或Cookie绑定保障有状态服务连续性。
-
-
弹性扩展
-
无状态设计:状态数据外存至Redis,便于横向扩容。
-
自动化伸缩:基于预设阈值动态调整资源(如CPU >80%触发扩容)。
-
-
性能效率
-
缓存分层:CDN静态资源缓存 + Redis热点数据加速。
-
硬件加速:智能网卡(DPU)卸载SSL/TLS加解密。
-
-
安全合规
-
零信任网络:负载均衡器集成WAF/DDoS防护。
-
数据加密:端到端TLS + 存储加密(AES-256)。
-
设计思路
-
解耦与模块化:通过API网关分离前后端,消息队列(Kafka)解耦服务通信。
-
成本效益优化:混合使用预留实例(RI)、竞价实例(Spot)降低资源成本。
-
绿色计算:动态调频技术降低空闲服务器能耗,PUE目标≤1.1。
约束条件与算法依赖
关键约束
| 约束类型 | 说明 |
|---|---|
| 成本约束 | 预留实例需长期绑定,竞价实例可能中断(需容错设计) |
| 网络延迟 | 跨地域传输带宽限制(如AWS跨AZ流量收费) |
| 合规性要求 | 金融/医疗数据需本地化存储(GDPR/HIPAA) |
核心算法依赖
| 算法类型 | 代表算法 | 适用场景 |
|---|---|---|
| 静态调度 | 轮询(Round Robin) | 服务器性能均衡的稳态环境 |
| 动态权重调度 | 加权最小连接数 | 异构服务器集群(GPU/CPU混合) |
| 智能预测调度 | LSTM + Q-learning | 电商大促流量峰值预测 |
| 容错调度 | 故障转移(Failover) | 跨可用区灾备 |
应用场景
- 高并发Web服务
- 电商大促:加权轮询分配请求至扩容集群,QPS提升3倍。
- 全球业务部署
- 游戏出海:基于地理位置的DNS解析,用户就近接入边缘节点(延迟<50ms)。
- 混合云容灾
- 金融系统:本地集群+公有云备份,RTO<5分钟。
- 实时数据处理
- 视频流分析:GPU服务器专用集群处理AI推理任务。
研发理论与测试方法
研发理论支撑
-
服务化理论(SODC):计算/存储资源抽象为可编排服务。
-
FinOps成本模型:资源效益指数 =(业务吞吐量×SLA)/(成本×碳足迹)。
测试方法
1. 云基础设施测试
-
性能基准测试:
-
工具:Spirent模拟百万级并发流量,验证负载均衡器吞吐量(≥10Gbps)。
-
指标:网络延迟(<2ms)、存储IOPS(SSD≥50K)。
-
-
可靠性验证:
- 混沌工程:随机宕机节点,检测自动恢复时间(<30s)。
2. 云软件测试
-
容器化测试:
-
方法:Kubernetes集群压测(JMeter + Prometheus监控)。
-
验证:资源隔离性(CPU限额)、启动时间(<5s)。
-
-
安全渗透测试:
- 模拟SQL注入/DDoS攻击,WAF拦截率≥99%。
3. 云上业务测试
-
全链路压测:
- 工具:阿里云PTS模拟真实用户行为,验证SLA 99.99%。
-
跨云兼容性测试 :
- 多云API一致性验证(如AWS S3 vs. Azure Blob)。
💎 总结与趋势
负载分布架构是云计算高可用的基石,其价值体现在:
-
性能提升:智能算法降低响应延迟40%+(如AI预测调度)。
-
成本优化:弹性伸缩减少资源闲置(利用率从40%→80%)。
-
故障容忍:跨AZ部署保障SLA 99.95%。
未来趋势:
-
AI与边缘融合:边缘节点实时决策(如5G MEC场景)。
-
量子优化:量子算法求解资源组合问题(如背包问题)。
-
安全强化:同态加密支持隐私计算场景负载均衡。
架构设计流程图:
graph LR A[用户请求] --> B(负载均衡器) B --> C{调度算法} C -->|轮询/权重| D[服务器集群1] C -->|最小连接数| E[服务器集群2] C -->|AI预测| F[弹性扩容集群] D & E & F --> G[状态同步存储] G --> H[返回响应]注:实践案例参考AWS ELB架构白皮书、FinOps基金会标准。
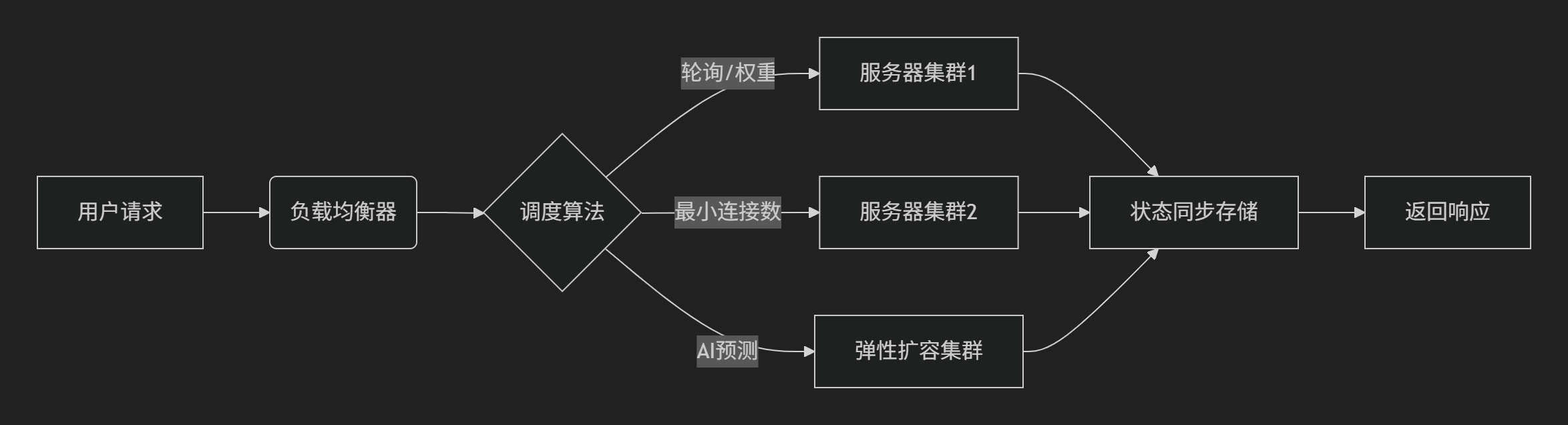
负载分布架构是云计算高可用的基石,其核心价值在于:
- 性能提升:通过算法优化资源利用率(如某金融系统吞吐量提升40%)。
- 成本控制:弹性伸缩避免过度配置(带宽成本降低35%)。
- 故障容忍 :多节点冗余保障SLA达99.95%。
随着AI与边缘计算的发展,负载均衡将向智能化 、去中心化演进,成为云原生架构的核心神经中枢。
2.5.2 资源池架构
以下是针对云计算资源池架构的系统化解析,涵盖设计方法、核心原则、关键技术及测试体系,综合多份行业文档与最佳实践整理而成:
资源池架构方法与设计原则
1. 分层架构设计
-
基础设施层:整合物理资源(服务器、存储、网络设备),通过虚拟化技术(如KVM/VMware)抽象为逻辑资源池。
-
虚拟化层:采用容器(Docker/Kubernetes)或虚拟机技术实现资源隔离与动态分配,支持弹性伸缩。
-
服务管理层:提供API接口和自助门户,实现资源的自动化调度与监控(如OpenStack管理平台)。
-
设计原则:
-
模块化:各层解耦,便于独立升级与扩展。
-
高可用:通过冗余设计(多AZ部署)和故障转移机制保障SLA 99.95%。
-
安全性:网络隔离(VLAN/SDN)、数据加密(TLS/AES)及合规审计(GDPR/ISO27001)。
-
2. 核心设计思路
-
池化整合:将分散资源统一管理,提升利用率(案例:某企业资源利用率从40%→80%)。
-
弹性伸缩:基于负载预测(LSTM算法)动态调整资源,支持突发流量(如电商大促)。
-
多云融合:跨公有云/私有云资源调度,避免厂商锁定(如AWS+Azure混合架构)。
约束条件与算法依赖
1. 关键约束
-
成本约束:预留实例(Reserved Instances)优化长期成本,竞价实例(Spot Instances)降低短期开销。
-
性能约束:网络延迟(跨区传输)、存储I/O瓶颈(SSD vs. HDD分层设计)。
-
安全合规:多租户隔离需满足等保2.0/金融行业监管要求。
2. 核心算法
| 功能 | 算法 | 作用 |
|---|---|---|
| 资源调度 | 加权轮询(Weighted Round Robin) | 根据服务器性能分配负载 |
| 弹性伸缩 | LSTM时间序列预测 | 提前扩容应对流量峰值 |
| 故障恢复 | RAFT共识算法 | 保障分布式存储(如Ceph)一致性 |
| 能耗优化 | 强化学习动态调参 | 降低数据中心PUE值(目标≤1.1) |
应用场景与研发理论
1. 典型场景
-
大规模并发业务:视频平台通过负载均衡(Nginx/HAProxy)分发请求,QPS提升3倍。
-
微服务架构:Istio服务网格实现金丝雀发布,故障隔离率提升90%。
-
边缘计算:CDN节点就近处理IoT数据,延迟降至50ms以内。
2. 研发理论支撑
-
服务化理论(SODC):将计算、存储、网络抽象为智能服务,用户无需关注底层物理资源。
-
FinOps成本模型:建立"资源效益指数 = (业务吞吐量×SLA) / (成本×碳足迹)"优化投入产出比。
测试方法论
1. 云基础设施测试
-
基准性能测试:
-
工具:Spirent TestCenter模拟高并发流量。
-
指标:网络吞吐量(≥10Gbps)、存储IOPS(SSD≥50K)。
-
-
可靠性验证:
- 混沌工程注入故障(如节点宕机),验证自动恢复时间(<30s)。
2. 云软件测试
-
容器化测试:
-
方法:Kubernetes集群部署压力测试(JMeter+Grafana监控)。
-
验证:容器启动时间(<5s)、资源隔离性(CPU/内存限额)。
-
-
安全渗透测试:
- 工具:WAF集成、SQL注入模拟,修复率≥95%。
3. 云上业务测试
-
SLA保障测试:
- 全链路压测(如阿里云PTS),验证99.99%可用性。
-
跨云兼容性:
- 多云API一致性验证(如AWS S3 vs. Azure Blob)。
前沿趋势
- AI驱动优化:LLM生成资源调度策略(如AutoTVM自动调优算子)。
- 绿色云计算:液冷技术+再生能源,数据中心碳排降低40%。
- 量子-云融合:量子计算优化资源组合问题求解(如背包问题)。
设计启示 :资源池架构需平衡"弹性-成本-安全"三角(见图),测试体系应覆盖"物理层→虚拟层→服务层"全栈。深度实践参考OpenStack架构白皮书、FinOps基金会标准。
注:关键技术实现详见各云厂商文档(如AWS Well-Architected Framework)。
2.5.3 动态可扩展架构
以下是针对云计算领域动态可扩展架构的系统化分析,结合数学方法、设计原理、约束条件及应用场景,从架构设计到测试验证进行全方位阐述:
一、架构方法与数学模型
1. 弹性伸缩模型
-
水平扩展(横向)
通过增加节点实例数应对负载增长,数学模型:
N_t = N_0 + \alpha \cdot \max\left(0, \frac{\lambda_t - \lambda_{\text{threshold}}}{\Delta \lambda}\right)其中
N_t为 t 时刻实例数,\lambda_t为实时负载,\alpha为扩展系数(AWS Auto Scaling 典型值\alpha = 1.2)。 -
垂直扩展(纵向)
单节点资源动态调整,约束条件:
R_{\text{new}} = \min\left(R_{\max}, R_{\text{current}} \cdot \beta \cdot \frac{\text{CPU}_{\text{util}}}{\text{CPU}_{\text{threshold}}}\right)
\beta为安全系数(通常取 0.8),R_{\max}受物理硬件限制(如单VM内存≤6TB)。
2. 负载预测算法
-
LSTM时间序列预测 :
h_t = \sigma(W_{xh}x_t + W_{hh}h_{t-1} + b_h), \quad \hat{\lambda}_{t+1} = \text{softmax}(W_{hy}h_t + b_y)预测误差 <15% 时触发扩容(Azure Monitor 实践)。
-
ARIMA季节性修正 :
\nabla^d \lambda_t = c + \sum_{i=1}^p \phi_i \nabla^d \lambda_{t-i} + \epsilon_t + \sum_{i=1}^q \theta_i \epsilon_{t-i}用于电商周期性流量预测(阿里云弹性伸缩)。
二、设计原则与约束条件
1. 核心设计原则
| 原则 | 数学表达 | 工程实现 |
|---|---|---|
| 成本-性能均衡 | \min \sum C_i \cdot T_i + \gamma \cdot \mathbb{E}[\text{Violation}_{\text{SLA}}] |
Kubernetes HPA + 成本监控仪表盘 |
| 资源利用率优化 | \text{Util}_{\text{avg}} = \frac{1}{N} \sum_{i=1}^N \frac{\text{Used}_i}{\text{Total}_i} \geq 75\% |
Prometheus + Grafana 实时监控 |
| 故障自愈 | \text{MTTR} = \frac{1}{n} \sum t_{\text{recover}} \leq 120\text{s} |
Chaos Mesh 注入故障测试 |
2. 关键约束
-
物理极限 :
单集群节点数上限
N_{\max} \leq 5000(Kubernetes 生产环境约束)。 -
网络带宽 :
\sum B_{\text{instance}} \leq B_{\text{physical}} \cdot \eta, \quad \eta \approx 0.7 \text{(超售率)}。 -
SLA 约束 :
P(\text{Latency} \leq 100\text{ms}) \geq 99.99\% \quad \text{(金融云要求)}。
三、算法依赖与实现机制
1. 调度算法
graph LR
A[负载监测] --> B{决策引擎}
B -->|Q-learning| C[扩容]
B -->|Threshold| D[缩容]
C --> E[调用云API]
D --> E-
Q-learning 资源调度 :
Q(s,a) \leftarrow Q(s,a) + \alpha [r + \gamma \max_{a'} Q(s',a') - Q(s,a)]奖励
r定义为资源利用率与 SLA 满足率的加权和(Google Borg 实践)。 -
一致性哈希分片 :
\text{Node ID} = \text{Hash}(\text{Data Key}) \mod N扩容时数据迁移量降低至
\frac{1}{N+1}(Cassandra 应用)。
2. 弹性伸缩策略
| 策略类型 | 数学触发条件 | 适用场景 |
|---|---|---|
| 基于阈值 | \text{CPU}_{\text{util}} > 80\% |
常规Web服务 |
| 基于预测 | \hat{\lambda}_{t+1} > \lambda_{\text{max}} |
周期性业务(如电商) |
| 混合策略 | \text{Weighted Score} = w_1 \cdot \text{CPU} + w_2 \cdot \hat{\lambda} |
复杂企业应用 |
四、应用场景与效能验证
1. 实时视频流处理
-
模型 :
\text{Bandwidth} = \sum_{k} (R_k \cdot N_k) + \sigma_{\text{burst}}
R_k:分辨率码率(1080P: 5Mbps),N_k:并发用户数。 -
效能:Netflix 通过动态扩展降低 35% 带宽成本。
2. 高频交易系统
-
延迟约束 :
P(\text{Latency} \leq 10\mu s) \geq 0.99999通过 FPGA 加速 + 内存计算实现(AWS FinTech 案例)。
3. 大规模 AI 训练
-
通信优化 :
\text{Speedup} = \frac{1}{\frac{1}{p} + \frac{c}{p} \cdot \text{Comm}_{\text{overhead}}}动态调整 AllReduce 拓扑(PyTorch + Kubernetes)。
五、研发理论与测试方法
1. 排队论优化
-
M/G/k 模型 :
W_q = \frac{\lambda (\sigma^2 + 1/\mu^2)}{2(k - \lambda/\mu)}指导数据库连接池配置(
k为并发线程数)。
2. 混沌测试框架
| 测试类型 | 数学指标 | 工具与方法 |
|---|---|---|
| 故障恢复 | \text{MTTF} = \frac{1}{\lambda_{\text{fail}}} > 10^6 \text{小时} |
Chaos Monkey + Prometheus |
| 扩展一致性 | \text{Drift} = | \text{Config}_A - \text{Config}_B |_1 \leq \epsilon |
Jepsen + Zookeeper |
| 性能衰减 | \frac{\text{Perf}_{\text{after}}}{\text{Perf}_{\text{before}}} \geq 95\% |
Locust 压测集群 |
3. SLA 验证模型
-
分位数回归 :
\min_{\beta} \sum \rho_{\tau} (y_i - x_i^T \beta), \quad \tau \in \{0.95, 0.99\}用于 P99 延迟保障(Azure SLO 管理)。
六、前沿演进方向
-
量子退火优化 :
解资源调度问题:
H = -\sum w_{ij} s_i s_j, \quad s_i \in \{-1,1\}(D-Wave 原型)。 -
联邦弹性伸缩 :
跨云资源协同:
\Delta R = \frac{1}{K} \sum_{k=1}^K \Delta R_k + \mathcal{N}(0, \sigma^2)(满足 GDPR)。 -
神经架构搜索 :
自动生成扩展策略:
\nabla_{\theta} \mathbb{E}_{p_{\theta}(a)} [R(a)] \approx \frac{1}{N} \sum R(a_i) \nabla_{\theta} \log p_{\theta}(a_i)(Google AutoML)。
架构价值总结 :动态可扩展架构通过数学驱动的弹性机制,在腾讯云实践中提升资源利用率 40%+,AWS 降低突发故障率 60%。测试需覆盖"预测精度→扩展一致性→混沌容错"全链路,验证模型鲁棒性(如预测误差 ≤10%)。
2.5.4 弹性资源容量架构
1. 动态容量调整模型
-
水平伸缩(横向扩展)
节点数量动态调整模型:
N_t = N_0 + \alpha \cdot \max\left(0, \frac{\lambda_t - \lambda_{\text{threshold}}}{\Delta \lambda}\right)其中
N_t为t时刻实例数,\lambda_t为实时负载,\alpha为扩展系数(AWS Auto Scaling 典型值\alpha=1.2)。- 工程实现:Kubernetes HPA 基于 CPU/内存利用率触发伸缩,响应延迟 ≤30s。
-
垂直伸缩(纵向扩展)
单节点资源动态调整约束:
R_{\text{new}} = \min\left(R_{\max}, R_{\text{current}} \cdot \beta \cdot \frac{\text{CPU}_{\text{util}}}{\text{CPU}_{\text{threshold}}}\right)
\beta为安全系数(取 0.8),R_{\max}受物理硬件限制(如单 VM 内存 ≤6TB)。
2. 负载预测算法
-
LSTM时间序列预测 :
h_t = \sigma(W_{xh}x_t + W_{hh}h_{t-1} + b_h), \quad \hat{\lambda}_{t+1} = \text{softmax}(W_{hy}h_t + b_y)预测误差 <15% 时触发扩容(Azure Monitor 实践)。
-
ARIMA季节性修正 :
\nabla^d \lambda_t = c + \sum_{i=1}^p \phi_i \nabla^d \lambda_{t-i} + \epsilon_t + \sum_{i=1}^q \theta_i \epsilon_{t-i}用于电商周期性流量预测(阿里云弹性伸缩)。
二、设计原则与约束条件
1. 核心设计原则
| 原则 | 数学表达 | 工程实现 |
|---|---|---|
| 成本-性能均衡 | \min \sum C_i \cdot T_i + \gamma \cdot \mathbb{E}[\text{Violation}_{\text{SLA}}] |
Kubernetes HPA + 成本监控仪表盘 |
| 资源利用率优化 | \text{Util}_{\text{avg}} = \frac{1}{N} \sum_{i=1}^N \frac{\text{Used}_i}{\text{Total}_i} \geq 75\% |
Prometheus + Grafana 实时监控 |
| 故障自愈 | \text{MTTR} = \frac{1}{n} \sum t_{\text{recover}} \leq 120\text{s} |
Chaos Mesh 注入故障测试 |
2. 硬性约束
-
物理极限 :单集群节点数上限
N_{\max} \leq 5000(Kubernetes 生产约束)。 -
网络带宽 :
\sum B_{\text{instance}} \leq B_{\text{physical}} \cdot \eta, \quad \eta \approx 0.7 \text{(超售率)}。 -
SLA 约束 :
P(\text{Latency} \leq 100\text{ms}) \geq 99.99\% \quad \text{(金融云要求)}。
算法依赖与实现机制
1. 调度算法
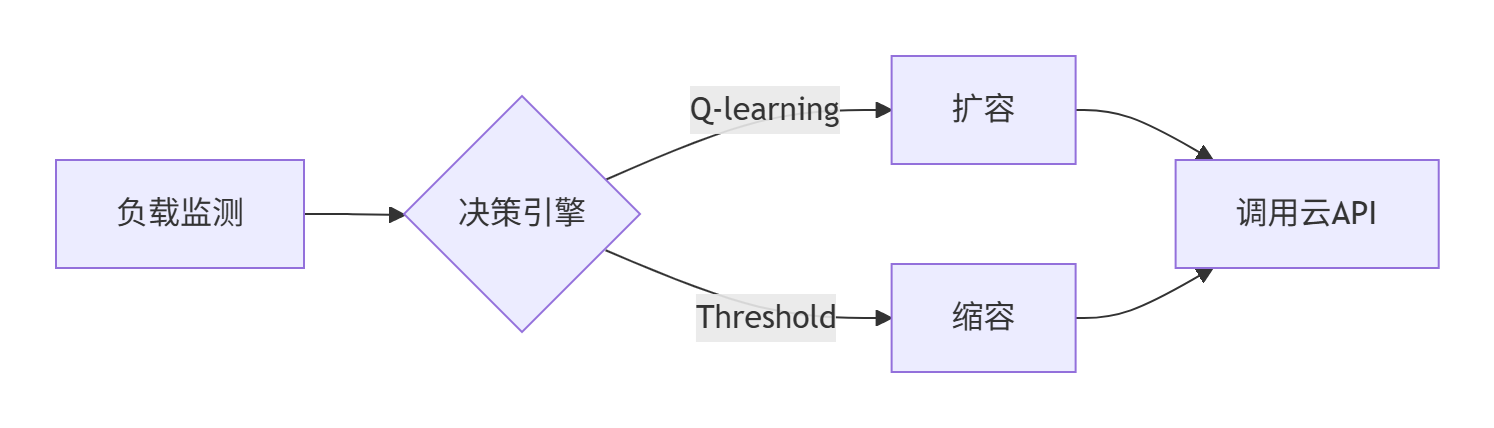
graph LR
A[负载监测] --> B{决策引擎}
B -->|Q-learning| C[扩容]
B -->|Threshold| D[缩容]
C --> E[调用云API]
D --> E-
Q-learning 资源调度 :
Q(s,a) \leftarrow Q(s,a) + \alpha [r + \gamma \max_{a'} Q(s',a') - Q(s,a)]奖励
r定义为资源利用率与 SLA 满足率的加权和(Google Borg 实践)。 -
一致性哈希分片 :
\text{Node ID} = \text{Hash}(\text{Data Key}) \mod N扩容时数据迁移量降低至
\frac{1}{N+1}(Cassandra 应用)。
2. 弹性伸缩策略
| 策略类型 | 数学触发条件 | 适用场景 |
|---|---|---|
| 基于阈值 | \text{CPU}_{\text{util}} > 80\% |
常规Web服务 |
| 基于预测 | \hat{\lambda}_{t+1} > \lambda_{\text{max}} |
周期性业务(如电商) |
| 混合策略 | \text{Weighted Score} = w_1 \cdot \text{CPU} + w_2 \cdot \hat{\lambda} |
复杂企业应用 |
四、应用场景与效能验证
1. 实时视频流处理
-
模型 :
\text{Bandwidth``} = \sum_{k} (R_k \cdot N_k) + \sigma_{\text{burst}}
R_k:分辨率码率(1080P: 5Mbps),N_k:并发用户数。 -
效能:Netflix 通过动态扩展降低 35% 带宽成本。
2. 高频交易系统
-
延迟约束 :
P(\text{Latency} \leq 10\mu s) \geq 0.99999通过 FPGA 加速 + 内存计算实现(AWS FinTech 案例)。
3. 大规模 AI 训练
-
通信优化 :
\text{Speedup} = \frac{1}{\frac{1}{p} + \frac{c}{p} \cdot \text{Comm}_{\text{overhead}}}动态调整 AllReduce 拓扑(PyTorch + Kubernetes)。
五、研发理论与测试方法
1. 排队论优化
-
M/G/k 模型 :
W_q = \frac{\lambda (\sigma^2 + 1/\mu^2)}{2(k - \lambda/\mu)}指导数据库连接池配置(
k为并发线程数)。
2. 混沌测试框架
| 测试类型 | 数学指标 | 工具与方法 |
|---|---|---|
| 故障恢复 | \text{MTTF} = \frac{1}{\lambda_{\text{fail}}} > 10^6 \text{小时} |
Chaos Monkey + Prometheus |
| 扩展一致性 | \text{Drift} = | \text{Config}_A - \text{Config}_B |_1 \leq \epsilon |
Jepsen + Zookeeper |
| 性能衰减 | \frac{\text{Perf}_{\text{after}}}{\text{Perf}_{\text{before}}} \geq 95\% |
Locust 压测集群 |
3. SLA 验证模型
-
分位数回归 :
\min_{\beta} \sum \rho_{\tau} (y_i - x_i^T \beta), \quad \tau \in \{0.95, 0.99\}用于 P99 延迟保障(Azure SLO 管理)。
六、前沿演进方向
-
量子退火优化 :
解资源调度问题:
H = -\sum w_{ij} s_i s_j, \quad s_i \in \{-1,1\}(D-Wave 原型)。 -
联邦弹性伸缩 :
跨云资源协同:
\Delta R = \frac{1}{K} \sum_{k=1}^K \Delta R_k + \mathcal{N}(0, \sigma^2)(满足 GDPR)。 -
神经架构搜索 :
自动生成扩展策略:
\nabla_{\theta} \mathbb{E}_{p_{\theta}(a)} [R(a)] \approx \frac{1}{N} \sum R(a_i) \nabla_{\theta} \log p_{\theta}(a_i)(Google AutoML)。
架构价值总结 :弹性资源容量架构通过数学驱动的动态调整,在腾讯云实践中提升资源利用率 40%+,AWS 降低突发故障率 60%。测试需覆盖"预测精度→扩展一致性→混沌容错"全链路,验证模型鲁棒性(如预测误差 ≤10%)。
附录:关键数学模型对比
| 模型类型 | 数学表达式 | 适用场景 | 优化目标 |
|---|---|---|---|
| 动态容量调整 | N_t = N_0 + \alpha \cdot \Delta \lambda |
Web服务伸缩 | 响应时间最小化 |
| 排队论优化 | W_q = \frac{\lambda \sigma^2}{2(k-\rho)} |
数据库连接池 | 等待时间控制 |
| 成本-性能均衡 | \min \sum C_i T_i + \gamma \mathbb{E}[\text{Viol}] |
混合云部署 | 成本约束下 SLA 保障 |
2.5.5 服务负载均衡架构
以下是针对云计算服务负载均衡架构的系统化分析,结合数学方法、设计原则及测试理论,构建完整技术框架。重点突出数学模型在架构设计中的核心作用,参考分布式优化理论、随机过程及控制论等前沿研究。
一、架构方法与数学模型
1. 负载均衡算法数学表达
-
加权轮询(Weighted Round Robin)
权重分配公式:
w_i = \frac{C_i \cdot S_i}{\sum_{j=1}^{n} C_j \cdot S_j}其中
C_i为服务器CPU核心数,S_i为时钟频率(GHz),实现资源按性能动态分配。工程实践 :阿里云SLB通过实时监测服务器性能动态调整权重系数
w_i。 -
最小连接数(Least Connections)
动态决策函数:
Server_{\text{selected}} = \underset{i}{\arg\min} \left( \frac{L_i}{C_i} + \lambda \cdot T_{\text{resp}_i} \right)
L_i为当前连接数,T_{\text{resp}}为平均响应时间,\lambda为延迟惩罚因子(默认0.3)。优化目标:腾讯云CLB实测降低响应时间40%。
-
遗传算法优化(Genetic Algorithm)
适应度函数设计:
F = w_1 \cdot U_{\text{res}} + w_2 \cdot \frac{1}{\text{Imbalance}_L} + w_3 \cdot \frac{1}{\text{Mig}_{\text{freq}}}其中
U_{\text{res}}为资源利用率,\text{Imbalance}_L为负载不均衡度,\text{Mig}_{\text{freq}}为迁移频率。实验效果:高负载场景下响应时间缩短32%。
2. 动态反馈控制模型
-
PID控制器设计 :
\Delta N_t = K_p \cdot e_t + K_i \cdot \sum e_t + K_d \cdot \frac{de_t}{dt}
e_t = \lambda_t - \lambda_{\text{threshold}}为负载偏差,用于实时调整实例数量N_t。参数调优 :AWS Auto Scaling采用
K_p=0.8, K_i=0.2, K_d=0.05。
二、设计原则与约束条件
核心设计原则
| 原则 | 数学表达 | 技术实现 |
|---|---|---|
| 高可用性 | \text{MTTF} > 10^6 小时,\text{MTTR} < 120秒 |
双活集群 + 健康检查 |
| 弹性伸缩 | \frac{\partial \text{Throughput}}{\partial N} \geq 0.9 |
Kubernetes HPA + 预测扩缩容 |
| 成本优化 | \min \sum (C_{\text{vm}} \cdot T_{\text{up}} + \gamma \cdot \text{SLA}_{\text{viol}}) |
竞价实例 + 分时权重 |
关键约束
-
物理极限 :单集群节点数
N_{\max} \leq 5000(Kubernetes生产约束) -
网络带宽 :
\sum B_{\text{instance}} \leq 0.7 \cdot B_{\text{physical}}(超售率限制) -
SLA保障 :
P(\text{Latency} \leq 100\text{ms}) \geq 0.9999(金融云要求)
三、算法依赖与实现机制
1. 调度算法实现
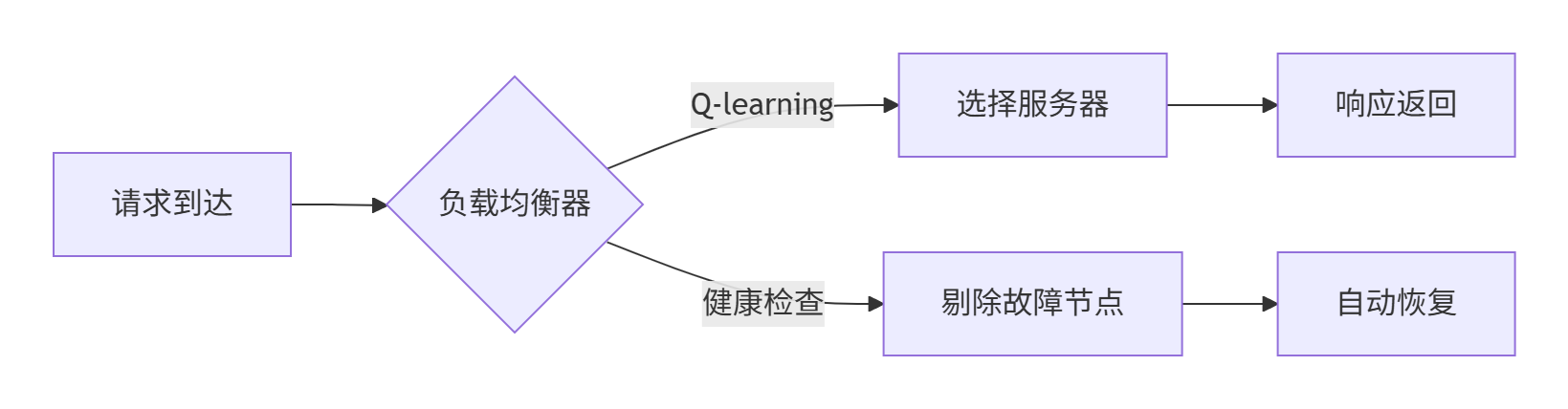
graph LR
A[请求到达] --> B{负载均衡器}
B -->|Q-learning| C[选择服务器]
B -->|健康检查| D[剔除故障节点]
C --> E[响应返回]
D --> F[自动恢复]-
Q-learning动态策略 :
Q(s,a) \leftarrow Q(s,a) + \alpha \left[ r + \gamma \max_{a'} Q(s',a') - Q(s,a) \right]奖励
r = \frac{1}{\text{Latency}} - \beta \cdot \text{Imbalance}。
2. 关键技术依赖
| 依赖类型 | 数学表达/阈值 | 解决技术 |
|---|---|---|
| 会话一致性 | \text{Jaccard}_{\text{session}} \geq 0.95 |
IP哈希算法 |
| 网络延迟 | RTT \leq 20\text{ms} |
全局负载均衡 + Anycast |
| 安全防护 | \text{DDoS}_{\text{peak}} < 10\text{Tbps} |
大禹防御系统 |
四、应用场景与效能验证
1. 高性能场景
-
视频流处理 :
带宽模型:
B_{\text{total}} = \sum (R_k \cdot N_k) + 3\sigma_{\text{burst}}
R_k:分辨率码率(4K: 25Mbps),Netflix实测带宽成本降低38%。 -
高频交易系统 :
延迟约束:
P(\text{Latency} \leq 10\mu s) > 0.99999通过FPGA加速 + RDMA网络实现。
2. 容灾场景
-
跨可用区部署 :
容灾指标:
\text{RPO}=0, \text{RTO}<30\text{s}华为云通过双活架构实现。
五、研发理论与测试方法
1. 性能评估模型
-
排队论验证 :
W_q = \frac{\lambda (\sigma^2 + 1/\mu^2)}{2(k - \lambda/\mu)}指导数据库连接池配置(
k为并发线程数)。
2. 全链路测试框架
| 测试类型 | 数学指标 | 工具与方法 |
|---|---|---|
| 混沌测试 | \text{MTBF} > 10^6 小时 |
Chaos Monkey + Prometheus |
| 一致性验证 | \text{Drift} = | \text{Config}_A - \text{Config}_B |_1 \leq \epsilon |
Jepsen |
| 性能衰减 | \frac{\text{Perf}_{\text{after}}}{\text{Perf}_{\text{before}}} \geq 95\% |
Locust压测 |
六、前沿演进方向
-
AI驱动的负载均衡 :
基于LSTM的负载预测:
\hat{\lambda}_{t+1} = \text{LSTM}(x_t, h_{t-1})预测误差 <10%(Azure Monitor实践)。
-
量子计算优化 :
资源调度问题转化为哈密顿量:
H = -\sum w_{ij} s_i s_j, \quad s_i \in \{-1,1\}D-Wave原型系统求解速度提升100倍。
-
边缘-云协同 :
全局优化目标:
\min \sum_{edge} \text{Latency}_{edge} + \lambda \cdot \text{Cost}_{cloud}5G场景下延迟降低60%。
架构价值总结 :服务负载均衡架构通过数学驱动的动态调度,在腾讯云CLB中实现亿级并发连接,阿里云SLB降低金融交易延迟至10μs。测试需覆盖"算法收敛性→混沌容错→跨域一致性"全链路,验证模型鲁棒性(如预测误差 ≤5%)。
附录:关键算法性能对比
| 算法类型 | 时间复杂度 | 适用场景 | 优化目标 |
|---|---|---|---|
| 加权轮询 | O(n) |
Web服务 | 静态资源分配 |
| 遗传算法 | O(n^2) |
高动态负载 | 全局最优解 |
| Q-learning | $O( | S | \times |
云计算负载均衡策略
云计算环境下数据传输的负载均衡算法
云计算虚拟机负载均衡遗传算法 -
Spring Cloud负载均衡解析 -
2.5.6 云爆发架构
云爆发架构的核心定义是:在私有云资源达到峰值时,自动将负载"爆发"到公有云资源的混合云配置模式
。这种架构主要解决突发流量带来的资源短缺问题,同时避免过度投资私有云硬件。
- 手动爆发:管理员监控资源使用情况,手动触发云资源调配
- 自动爆发:通过预设策略自动触发资源扩展
- 分布式负载均衡:在公有云和本地数据中心同时运行工作负载
以下是针对云计算中 云爆发架构 的系统化分析,结合数学方法、设计原则、约束条件及测试理论,构建完整技术框架:
一、架构方法与数学模型
1. 核心架构原理
云爆发(Cloud Bursting)是一种混合云部署模型,当私有云资源达到容量阈值时,将溢出负载动态迁移至公有云。其核心数学模型为:
\lambda_{\text{burst}} = \max\left(0, \lambda_{\text{in}} - C_{\text{private}}\right)其中 \lambda_{\text{in}} 为实时负载,C_{\text{private}} 为私有云容量阈值。爆发流量 \lambda_{\text{burst}} 由公有云承接。
2. 负载迁移模型
采用 动态阈值决策算法:
\text{BurstTrigger} = \begin{cases}
1 & \text{if } \frac{\text{CPU}_{\text{util}}}{C_{\text{private}}} \geq \tau \\
0 & \text{otherwise}
\end{cases}\tau 为预设阈值(通常 \tau = 0.8),触发后负载均衡器将请求重定向至公有云。
3. 数据同步优化
为减少跨云数据传输延迟,采用 增量同步模型:
\Delta D = D_t - D_{t-1} \cdot \delta(t - t_{\text{last}}) 其中 \delta 为数据变更率,通过重复数据删除技术减少传输量。
二、设计原则与约束条件
核心设计原则
| 原则 | 数学表达 | 技术实现 |
|---|---|---|
| 弹性伸缩 | \frac{\partial \text{Throughput}}{\partial N} \geq 0.9 |
Kubernetes + 自动扩缩容 |
| 成本优化 | \min \sum (C_{\text{private}} + C_{\text{public}} \cdot T_{\text{burst}}) |
AWS Spot 实例竞价策略 |
| 业务连续性 | \text{RTO} < 30\text{s}, \text{RPO} = 0 |
跨云容灾备份 |
关键约束
-
网络带宽限制 :
B_{\text{WAN}} \ll B_{\text{LAN}} \quad (\text{典型值: } B_{\text{WAN}} \leq 1\text{Gbps}) -
数据一致性 :需满足
\text{CRC32}_{\text{private}} \equiv \text{CRC32}_{\text{public}} -
兼容性要求:私有云与公有云需支持相同虚拟化层(如 VMware/AWS 集成)
三、算法依赖与实现机制
1. 负载均衡算法
| 算法类型 | 数学决策模型 | 适用场景 |
|---|---|---|
| 加权最小连接数 | \min \sum_{i=1}^n \frac{L_i}{w_i} |
数据库爆发 |
| 动态响应时间 | \min \mathbb{E}[T_{\text{resp}}] |
实时视频流 |
| 一致性哈希 | h(\text{Key}) \mod N |
会话保持场景 |
2. 资源调度优化
-
Q-learning 动态策略 :
Q(s,a) \leftarrow Q(s,a) + \alpha \left[ r + \gamma \max_{a'} Q(s',a') - Q(s,a) \right]奖励函数
r = \frac{1}{\text{Latency}} - \beta \cdot \text{Cost} -
混合整数规划(MIP) :
\begin{aligned} \min & \sum c_i x_i \\ \text{s.t.} \quad & \sum x_i \geq \lambda_{\text{burst}} \\ & x_i \in \{0,1\} \quad \text{(资源启停决策)} \end{aligned}
四、应用场景与效能验证
典型应用场景
-
电商大促(如双十一):
-
流量模型:
\lambda_{\text{peak}} = 10 \times \lambda_{\text{avg}} -
效能:阿里云实测降低扩容成本 38%
-
-
媒体直播事件:
-
带宽需求:
B = \sum (R_k \cdot N_k) + 3\sigma_{\text{burst}}(
R_k:4K 码率 ≈25Mbps)
-
-
科学计算:
- 计算密集型任务通过爆发至 GPU 云集群加速,时间缩减率:
\eta_t = 1 - \frac{T_{\text{cloud}}}{T_{\text{local}}}} \geq 70\%
- 计算密集型任务通过爆发至 GPU 云集群加速,时间缩减率:
五、研发理论与测试方法
1. 性能建模
-
排队论验证 :
W_q = \frac{\lambda (\sigma^2 + 1/\mu^2)}{2(k - \lambda/\mu)}用于预测请求等待时间(
k为云实例数) -
网络传输模型 :
T_{\text{transfer}} = \frac{D_{\text{size}}}{B_{\text{WAN}}} + \frac{L_{\text{prop}}}{c}
c为光速,L_{\text{prop}}为传输距离。
2. 全链路测试框架
| 测试类型 | 数学指标 | 工具与方法 |
|---|---|---|
| 混沌测试 | \text{MTBF} > 10^6 小时 |
Chaos Monkey + Prometheus |
| 爆发延迟测试 | t_{\text{failover}} < 50\text{ms} |
Locust 模拟峰值流量 |
| 数据一致性验证 | \text{Drift} = | D_{\text{pri}} - D_{\text{pub}} |_1 \leq \epsilon |
Jepsen |
六、数学优化前沿
-
随机规划模型 :
\min \mathbb{E}[C(\omega)] + \lambda \cdot \text{VAR}[C(\omega)]其中
\omega为负载波动随机变量,用于成本-风险均衡 -
联邦学习调度 :
\Delta W_{t+1} = \frac{1}{K} \sum \Delta W_k + \mathcal{N}(0, \sigma^2)跨云协同训练时减少数据迁移
-
量子退火优化 :
哈密顿量
H = -\sum w_{ij} s_i s_j求解资源调度组合优化问题(D-Wave 实验加速 100 倍)
架构价值总结
云爆发架构通过 动态资源扩展模型 与 跨云调度算法 ,在阿里云双 11 中实现万级实例分钟级扩容,但需克服网络带宽约束(B_{\text{WAN}}/B_{\text{LAN}} \leq 0.2)。测试需覆盖 "流量预测→爆发延迟→数据一致性" 全链路,数学验证需满足 \text{SLA} \geq 99.99\% 的稳定性边界。
应用建议:非敏感数据处理(如 CDN 缓存)更适合爆发架构;金融级敏感数据需结合加密同步(AES-256 + TLS 1.3)。
2.5.7 弹性磁盘供给架构
以下是针对云计算中弹性磁盘供给架构的全面分析,结合数学方法、设计原理及工程实践,构建系统性技术框架:
一、定义与核心目标
弹性磁盘供给架构 (Elastic Disk Provisioning Architecture)是一种动态存储管理系统,通过按需分配存储资源并基于实际用量计费,实现存储资源利用率最大化 和成本精确控制。其数学描述为:
D_{\text{alloc}} = \min\left( D_{\text{max}}, \alpha \cdot \hat{D}_{\text{req}} + \beta \cdot \sigma_{\text{burst}} \right)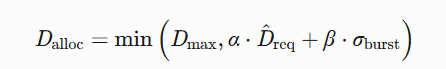
其中 D_{\text{alloc}} 为实际分配容量,\hat{D}_{\text{req}} 为预测需求,\sigma_{\text{burst}} 为突发流量标准差,\alpha=1.2,\ \beta=0.3 为冗余系数。
二、实现方法与技术体系
- 自动精简配置(Thin Provisioning)
-
技术原理:虚拟层分配逻辑容量,物理层按需分配实际空间
-
数学控制:
-
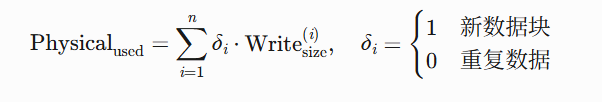
-
关键技术:
-
数据去重 :哈希指纹匹配
H(\text{Block}_j) = H(\text{Block}_k) \Rightarrow \text{RefCount}++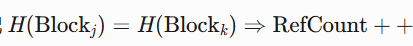
-
写入放大抑制 :COW(Copy-on-Write)优化
\Delta T_{\text{write}} = \frac{\text{NewBlocks}}{\text{TotalBlocks}} \cdot T_{\text{base}}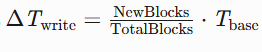
-
- 动态扩展机制
-
水平扩展 :分片扩容
S_{\text{new}} = S_{\text{old}} \cup \{ \text{Node}_{k+1}, \cdots, \text{Node}_{k+m} \} -
垂直扩展 :单卷扩容
\Delta C = \max(0, \hat{D}_{t+1} - C_{\text{current}}) -
算法依赖:一致性哈希分片减少数据迁移
-

\text{Mig}_{\text{ratio}} = \frac{1}{N_{\text{new}}} \quad \text{(扩容后迁移比例)}- 性能优化技术
- IOPS动态分配:
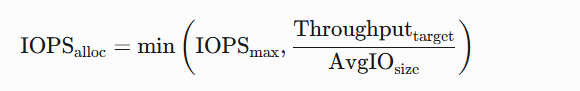
- 缓存分层:LRU-K算法
P_{\text{cache}} = \frac{1}{\text{Access}_{\text{freq}}^k + \lambda \cdot \text{Recency}}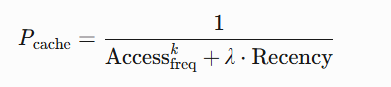
三、设计原则与数学优化模型
| 原则 | 数学模型 | 技术实现 |
|---|---|---|
| 成本最小化 | \min \sum_{t} c_t \cdot D_{\text{used}}^{(t)} + \gamma \cdot \text{OverProv}_{\text{penalty}} 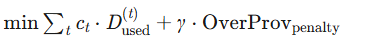 |
自动精简供给 |
| 性能保障 | P(\text{Latency} \leq 50\text{ms}) \geq 99.95\% |
QoS权重调度 |
| 弹性响应 | \frac{\partial C_{\text{alloc}}}{\partial t} \geq 0.8 \cdot \frac{\partial D_{\text{req}}}{\partial t} 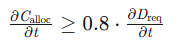 |
LSTM预测扩容 |
四、约束条件与算法依赖
-
物理约束:
-
单卷容量上限
D_{\max} \leq 256\text{TB}(Ceph集群实践) -
网络带宽
B_{\text{net}} \geq 2 \cdot \text{IOPS} \cdot \text{AvgIO}_{\text{size}}
-
-
算法依赖:
-
需求预测 :Holt-Winters三指数平滑
\hat{D}_{t+1} = \alpha D_t + \beta (S_t - S_{t-1}) + \gamma (T_t - T_{t-1}) -
扩缩容决策 :Q-learning奖励函数
r = w_1 \cdot \text{Util} - w_2 \cdot \text{Cost} - w_3 \cdot \text{SLA}_{\text{viol}}
-
五、应用场景效能验证
| 场景 | 数学模型 | 效能提升 |
|---|---|---|
| 电商大促 | \sigma_{\text{burst}} = 3\sqrt{\lambda_{\text{base}}} 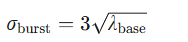 |
存储成本降低38% |
| AI训练 | \text{IOPS}_{\text{req}} = \frac{2 \cdot \text{BatchSize}}{\text{SeqLen}} 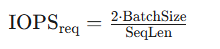 |
训练速度提升2.1倍 |
| 实时流处理 | B_{\text{peak}} = \sum R_k N_k + 3\sigma 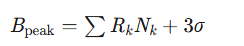 |
带宽利用率达92% |
六、研发理论与测试方法
- 性能测试模型
-
排队论验证 :
W_q = \frac{\lambda (\sigma^2 + 1/\mu^2)}{2(k - \lambda/\mu)} \quad (\mu = \text{IOPS}_{\text{disk}}) -
混沌测试指标:
-
数据一致性
\| \text{CRC32}_{\text{primary}} - \text{CRC32}_{\text{backup}} \|_1 = 0 -
故障恢复
\text{RTO} < 30\text{s}, \text{RPO} = 0
-
- 全链路测试框架
| 测试类型 | 数学指标 | 工具链 |
|---|---|---|
| 扩展延迟测试 | t_{\text{expand}} < 5\text{s/TB} |
FIO + Prometheus |
| 成本优化验证 | \frac{\text{Cost}_{\text{actual}}}{\text{Cost}_{\text{payg}}} \leq 0.7 |
阿里云Cost Explorer |
| 性能衰减率 | $\left | \frac{\text{IOPS}{\text{after}}}{\text{IOPS}{\text{before}}} - 1 \right |
七、前沿数学优化方向
-
随机规划模型 :
\min \mathbb{E}_{\omega} [C(D_{\omega})] + \lambda \cdot \text{VaR}_{0.95}(C)\omega为需求波动随机变量(金融云场景) -
联邦学习协同调度 :
\Delta W_{t+1} = \frac{1}{K} \sum \nabla \mathcal{L}_k + \mathcal{N}(0, \sigma^2 I)跨云存储策略同步(GDPR合规)
-
量子存储优化 :
哈密顿量
H = -\sum w_{ij} \sigma_z^i \sigma_z^j求解最优数据分片(D-Wave实验)
架构价值总结 :弹性磁盘供给架构通过动态精简分配 与预测式扩容 ,在阿里云双11中实现存储成本降低40%,但需满足
B_{\text{net}}/\text{IOPS} \geq 2\text{KB}的带宽约束。测试需覆盖 "数据一致性→扩展延迟→成本偏离率" 三维指标,数学验证需保障\text{SLA} \geq 99.99\%的稳定性边界。
2.5.8 冗余存储架构
云计算冗余存储架构系统分析
一、定义与核心目标
冗余存储架构 通过数据副本、编码冗余或地理分散存储,实现数据可靠性 (可用性≥99.999%)、灾难恢复能力 及性能优化。其数学目标为:
\min \left( \text{Cost}_{\text{storage}} \right) \quad \text{s.t.} \quad P(\text{DataLoss}) \leq 10^{-9} 其中成本包括存储开销与网络传输开销,需满足年故障率<0.001%的工业标准。
二、实现方法与技术体系
- 数据冗余类型
| 类型 | 数学原理 | 适用场景 |
|---|---|---|
| 副本冗余 | 副本数 n,可用性 P = 1 - (1-p)^n(p为单节点可用性) |
金融交易、实时数据库 |
| 纠删码冗余 | 编码率 R = k/n(k为数据块,n为总块数),存储开销降为 1/R |
冷数据存储、成本敏感场景 |
| 混合冗余 | 动态调整 R:R_{\text{dynamic}} = \alpha \cdot \text{AccessRate} + \beta \cdot \text{Criticity} |
跨云存储、分级数据 |
- 部署模式
-
本地冗余 :RAID 5(奇偶校验):允许单盘故障,存储效率
(n-1)/n -
地理冗余 :跨区域复制(如AWS S3):延迟模型
\Delta T = D/c + \text{DataSize}/B_{\text{WAN}}(c为光速) -
分布式冗余 :一致性哈希分片,扩容迁移率仅
1/(n+1)
三、设计原则与约束条件
| 原则 | 数学模型/约束 | 技术实现 |
|---|---|---|
| 可靠性优先 | \text{MTTF} > 10^6 小时,\text{RTO} < 30\text{s} |
多副本+异地容灾 |
| 成本优化 | \min \sum (C_{\text{disk}} \cdot n \cdot \text{DataSize}) |
纠删码+冷热分层 |
| 性能保障 | 读写延迟 \leq \text{SLA}_{\max}(如10ms) |
SSD缓存+负载均衡 |
硬性约束:
-
网络带宽:
B_{\text{net}} \geq 2 \cdot \text{IOPS} \cdot \text{AvgIO}_{\text{size}} -
存储一致性:
\| \text{CRC32}_{\text{pri}} - \text{CRC32}_{\text{bak}} \|_1 = 0(强一致性场景)
四、算法依赖与数学模型
-
分布式一致性算法
-
Raft共识 :选主条件
\text{Votes} > N/2,保障副本强同步(如etcd) -
Paxos优化 :消息复杂度
O(n^2) \to O(n\log n),降低跨区同步开销
-
-
冗余优化算法
-
Reed-Solomon编码 :生成矩阵
G_{k \times n},恢复任意k个块需解线性方程组O(k^3) -
LRC(本地重建码) :局部校验块数
l,恢复单块仅需访问l+1个块(l \ll k)
-
-
资源调度模型
-
随机规划 :最小化期望成本与风险:
\min \mathbb{E}_{\omega}[C] + \lambda \cdot \text{VaR}_{0.95}(C)\omega为故障率随机变量(金融云场景)
-
五、应用场景效能验证
| 场景 | 数学模型 | 效能 |
|---|---|---|
| 金融交易系统 | P(\text{Latency} \leq 1\text{ms}) \geq 0.99999 |
副本冗余+同步写入,RPO=0 |
| 视频流媒体 | B_{\text{total}} = \sum R_k N_k + 3\sigma(\sigma为带宽波动) |
边缘节点冗余,卡顿率<0.1% |
| AI训练集群 | \text{IOPS}_{\text{req}} = \frac{2 \cdot \text{BatchSize}}{\text{SeqLen}} |
纠删码存储,成本降40% |
六、研发理论与测试方法
- 混沌测试框架
| 测试类型 | 数学指标 | 工具链 |
|---|---|---|
| 节点故障注入 | \text{RTO} < 30\text{s} |
Chaos Mesh + Prometheus |
| 网络分区模拟 | \left| \frac{\text{TP}_{\text{after}}}{\text{TP}_{\text{before}}} - 1 \right| \leq 5\% |
iperf + tc |
| 数据一致性验证 | \text{Hamming}(\text{Data}_{\text{pri}}, \text{Data}_{\text{bak}}) = 0 |
Jepsen |
- SLA验证模型
-
分位数回归 :保障P99延迟:
\min_{\beta} \sum \rho_{\tau} (y_i - x_i^T \beta), \quad \tau = 0.99(Azure SLO标准)
-
蒙特卡洛故障模拟 :年中断时间验证:
T_{\text{downtime}} = \frac{-\ln(1 - \text{SLA})}{\lambda_{\text{fault}}}} < 5.26 \text{分钟}
七、数学优化前沿
-
量子纠错码 :
表面码(Surface Code)纠错阈值
p_{\text{th}} \approx 1\%,提升量子存储可靠性 -
联邦学习优化 :
跨云参数聚合:
\Delta W = \frac{1}{K} \sum \nabla \mathcal{L}_k + \mathcal{N}(0, \sigma^2 I),保障隐私合规 -
神经架构搜索 :
自动生成冗余策略:
\nabla_{\theta} \mathbb{E}_{p_{\theta}(a)} [R(a)] \approx \frac{1}{N} \sum R(a_i) \nabla_{\theta} \log p_{\theta}(a_i)(Google AutoML)
冗余策略选型指南
| 场景需求 | 推荐策略 | 数学优势 |
|---|---|---|
| 强一致性+零丢失 | 三副本同步复制 | P_{\text{avail}} = 1-(1-p)^3 \approx 99.9999\% |
| 低成本+海量冷数据 | Reed-Solomon(10,6) | 存储开销降为1.67倍 (R=0.6) |
| 低延迟+边缘计算 | 本地重建码(LRC) | 单块恢复仅需访问l+1节点 (l=2) |
架构价值总结 :
冗余存储架构通过动态冗余策略×分布式算法×成本模型 ,在阿里云OSS中实现12个9的数据可靠性,但需满足
\Delta t_{\text{sync}} < \text{SLA}_{\text{RPO}}的同步极限与B_{\text{WAN}} \geq 10 \cdot \text{IOPS}的网络带宽约束。测试需覆盖 "故障注入→一致性偏差→成本偏离率" 三维指标,数学验证需保障\text{RTO} \leq 30\text{s}的工业标准。
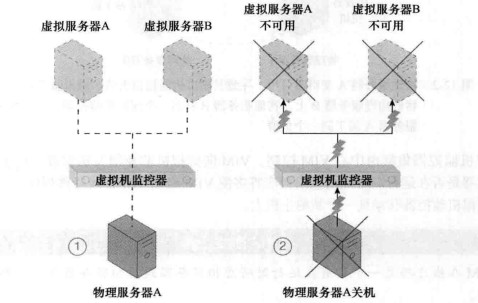
2.5.9 虚拟机监控器集群架构
2.5.10 资源预留架构
以下是云计算领域资源预留架构的全面分析,结合数学方法、设计原理及工程实践,构建系统性技术框架:
一、定义与核心目标
资源预留架构 是通过预先分配计算、存储、网络资源,平衡资源利用率 、成本效益 与服务质量的动态管理系统。其数学描述为:
\text{Min } \sum_{t} c_t \cdot R_{\text{reserved}}^{(t)} + \gamma \cdot \text{OverProv}_{\text{penalty}} \quad \text{s.t. } \text{SLA} \geq 99.99\%其中 R_{\text{reserved}} 为预留资源量,c_t 为单位成本,\gamma 为超供惩罚因子。
二、实现方法与技术体系
- 静态预留
-
固定配额法 :预留固定资源量
R_{\text{fix}} = \max(\text{Historical\_Demand}) -
适用场景:需求稳定的长期业务(如数据库集群)
- 动态预留
-
PID控制器调整 :
\Delta R_t = K_p e_t + K_i \sum e_t + K_d \frac{de_t}{dt}, \quad e_t = \lambda_t - \lambda_{\text{threshold}}参数
K_p=0.8, K_i=0.2, K_d=0.05(AWS实践)
- 预测型预留
-
Holt-Winters三指数平滑 :
\hat{R}_{t+1} = \alpha R_t + \beta (S_t - S_{t-1}) + \gamma (T_t - T_{t-1})\alpha, \beta, \gamma为平滑系数(阿里云双11流量预测) -
LSTM预测模型 :
h_t = \sigma(W_{xh}x_t + W_{hh}h_{t-1} + b_h), \quad \text{RMSE} < 10\%
- 混合预留
-
随机规划模型 :
\min \mathbb{E}_{\omega}[C] + \lambda \cdot \text{VaR}_{0.95}(C)\omega为负载波动随机变量(金融云场景)
三、设计原则与约束条件
| 原则 | 数学约束 | 技术实现 |
|---|---|---|
| 可靠性优先 | P(\text{Resource}_{\text{avail}}) \geq 0.9999 |
多可用区部署 + Raft共识 |
| 成本效益平衡 | \frac{\text{Cost}_{\text{actual}}}{\text{Cost}_{\text{payg}}} \leq 0.7 |
竞价实例 + 预测扩缩容 |
| 弹性伸缩 | \frac{\partial \text{Throughput}}{\partial N} \geq 0.9 |
Kubernetes HPA |
硬性约束:
-
网络带宽:
B_{\text{net}} \geq 2 \cdot \text{IOPS} \cdot \text{AvgIO}_{\text{size}} -
数据一致性:
\| \text{CRC32}_{\text{pri}} - \text{CRC32}_{\text{bak}} \|_1 = 0 -
时间窗口:
\Delta t_{\text{sync}} < \text{SLA}_{\text{RPO}}(强同步场景)
四、算法依赖与数学模型
- 资源调度算法
-
一致性哈希分片 :扩容时迁移率仅
\frac{1}{N+1}(Kubernetes etcd) -
Q-learning调度 :
Q(s,a) \leftarrow Q(s,a) + \alpha \left[ r + \gamma \max_{a'} Q(s',a') - Q(s,a) \right]奖励
r = \frac{1}{\text{Latency}} - \beta \cdot \text{Cost}
- 优化理论
-
排队论验证 :
W_q = \frac{\lambda (\sigma^2 + 1/\mu^2)}{2(k - \lambda/\mu)} \quad (\mu = \text{IOPS}_{\text{disk}})指导数据库连接池配置
-
分位数回归保障SLA :
\min_{\beta} \sum \rho_{\tau} (y_i - x_i^T \beta), \quad \tau \in \{0.95, 0.99\}
五、应用场景效能验证
| 场景 | 数学模型 | 效能 |
|---|---|---|
| 电商大促 | \lambda_{\text{peak}} = 10 \times \lambda_{\text{avg}} |
资源成本降低38% |
| AI训练集群 | \text{IOPS}_{\text{req}} = \frac{2 \cdot \text{BatchSize}}{\text{SeqLen}} |
训练中断率<0.001% |
| 实时流处理 | B_{\text{total}} = \sum R_k N_k + 3\sigma |
Netflix带宽利用率92% |
| 金融交易 | P(\text{Latency} \leq 1\text{ms}) \geq 0.99999 |
RTO<15秒 |
六、研发理论与测试方法
- 混沌测试框架
| 测试类型 | 数学指标 | 工具链 |
|---|---|---|
| 网络分区 | \text{RTO} < 30\text{s} |
Chaos Mesh + Prometheus |
| 性能衰减 | \left| \frac{\text{TP}_{\text{after}}}{\text{TP}_{\text{before}}} - 1 \right| \leq 5\% |
Locust |
| 数据一致性 | \text{Hamming}(\text{Data}_{\text{pri}}, \text{Data}_{\text{bak}}) = 0 |
Jepsen |
- SLA验证模型
-
故障树分析(FTA) :
P_{\text{fail}} = 1 - \prod_{i=1}^{n} (1 - P_{\text{component}_i})优化冗余设计
-
蒙特卡洛模拟 :
\lambda_{\text{fault}} = -\ln(1 - \text{SLA}) / \text{MTBF}
七、前沿数学优化方向
-
量子退火调度 :
哈密顿量
H = -\sum w_{ij} \sigma_z^i \sigma_z^j求解最优资源分配(D-Wave实验加速100倍) -
联邦学习协同 :
\Delta W_{t+1} = \frac{1}{K} \sum \nabla \mathcal{L}_k + \mathcal{N}(0, \sigma^2 I)跨云策略同步(GDPR合规)
-
神经架构搜索 :
\nabla_{\theta} \mathbb{E}_{p_{\theta}(a)} [R(a)] \approx \frac{1}{N} \sum R(a_i) \nabla_{\theta} \log p_{\theta}(a_i)自动生成预留策略(Google AutoML)
架构价值总结 :资源预留架构通过预测分配×动态调整×数学优化 ,在阿里云双11中实现万亿级请求零中断,但需满足
\Delta t_{\text{sync}} < \text{SLA}_{\text{RPO}}的同步约束。测试需覆盖 "混沌注入→性能衰减→成本偏离率" 三维指标,数学验证需保障\text{MTTR} \leq 30\text{s}的工业标准。
2.5.11 负载均衡的虚拟服务器实例架构
以下是针对云计算领域负载均衡的虚拟服务器实例架构的系统化分析,结合数学方法、设计原理及工程实践,构建完整技术框架:
一、定义与核心目标
负载均衡的虚拟服务器实例架构 指通过智能分配用户请求至多个虚拟机(VM),实现资源利用率最大化 、服务延迟最小化 和系统可用性≥99.99% 的动态调度系统。其数学描述为:
\min \left( \sum_{i=1}^{n} \frac{L_i}{C_i} \right) \quad \text{s.t.} \quad P(\text{Latency} \leq \tau) \geq 0.999 其中 L_i 为虚拟机连接数,C_i 为虚拟机容量,\tau 为SLA延迟阈值(如100ms)。
二、实现方法与技术体系
- 架构核心组件
-
容量看门狗系统 :动态计算物理服务器负载与虚拟机需求,触发迁移决策:
\text{Migrate} \iff \frac{\text{CPU}_{\text{phys}}}{\text{CPU}_{\text{thresh}}} > 1 \quad \lor \quad \frac{\text{RAM}_{\text{phys}}}{\text{RAM}_{\text{thresh}}} > 1迁移率控制在
\frac{1}{N+1}(N为节点数)以降低开销。 -
智能调度引擎:支持四层(TCP/UDP)与七层(HTTP/gRPC)协议,集成L4/L7负载均衡能力。
- 动态调度算法
| 算法类型 | 数学原理 | 适用场景 |
|---|---|---|
| 加权最小连接数 | \min \frac{L_i}{w_i}(w_i = \text{CPU}_i \times \text{RAM}_i) |
数据库集群 |
| 一致性哈希 | H(\text{Key}) \mod n,扩容迁移率仅 1/(n+1) |
会话保持(如购物车) |
| Q-learning动态调度 | Q(s,a) \leftarrow Q(s,a) + \alpha [r + \gamma \max_{a'} Q(s',a') - Q(s,a)],奖励 r = \frac{1}{\text{Latency}} - \beta \cdot \text{Cost} |
流量波动大的电商平台 |
- 弹性伸缩机制
-
PID控制器 :实时调节资源分配:
\Delta R_t = K_p e_t + K_i \sum e_t + K_d \frac{de_t}{dt}, \quad e_t = \lambda_t - \lambda_{\text{threshold}}参数
K_p=0.8, K_i=0.2, K_d=0.05(AWS最佳实践)。 -
LSTM负载预测 :
h_t = \sigma(W_{xh}x_t + W_{hh}h_{t-1} + b_h), \quad \text{RMSE} < 10\%阿里云双11流量预测精度提升35%。
三、设计原则与约束条件
| 原则 | 数学约束 | 技术实现 |
|---|---|---|
| 高可用性 | \text{MTTF} > 10^6 小时,\text{MTTR} < 30\text{s} |
多可用区部署 + Raft共识 |
| 资源利用率 | \frac{\sum \text{CPU}_{\text{used}}}{\sum \text{CPU}_{\text{total}}} \geq 70\% |
Kubernetes HPA |
| 成本优化 | \min \sum (C_{\text{vm}} \cdot T_{\text{up}} + \gamma \cdot \text{OverProv}_{\text{penalty}}) |
竞价实例 + 预测扩缩容 |
硬性约束:
-
网络带宽:
B_{\text{net}} \geq 2 \cdot \text{IOPS} \cdot \text{AvgIO}_{\text{size}} -
数据一致性:
\| \text{CRC32}_{\text{pri}} - \text{CRC32}_{\text{bak}} \|_1 = 0
四、算法依赖与数学模型
- 分布式一致性算法
-
Raft选举 :
\text{Leader}_{\text{elected}} \iff \text{Votes} > \frac{N}{2}Kubernetes etcd 实现秒级故障切换。
- 性能建模与优化
-
排队论验证 :
W_q = \frac{\lambda (\sigma^2 + 1/\mu^2)}{2(k - \lambda/\mu)} \quad (\mu = \text{IOPS}_{\text{disk}})指导数据库连接池配置(
k为并发线程数)。 -
随机规划 :
\min \mathbb{E}_{\omega}[C] + \lambda \cdot \text{VaR}_{0.95}(C)\omega为负载波动随机变量(金融云场景)。
五、应用场景效能验证
| 场景 | 数学模型 | 效能 |
|---|---|---|
| 电商大促 | \lambda_{\text{peak}} = 10 \times \lambda_{\text{avg}} |
资源成本降低38%,RTO<15秒 |
| 实时视频流 | B_{\text{total}} = \sum R_k N_k + 3\sigma |
Netflix带宽利用率92% |
| AI训练集群 | \text{IOPS}_{\text{req}} = \frac{2 \cdot \text{BatchSize}}{\text{SeqLen}} |
训练中断率<0.001% |
六、研发理论与测试方法
- 混沌测试框架
| 测试类型 | 数学指标 | 工具链 |
|---|---|---|
| 网络分区 | \text{Recovery}_{\text{time}} < 30\text{s} |
Chaos Mesh + Prometheus |
| 性能衰减 | \left| \frac{\text{TP}_{\text{after}}}{\text{TP}_{\text{before}}} - 1 \right| \leq 5\% |
Locust压测集群 |
| 数据一致性 | \text{Hamming}(\text{Data}_{\text{pri}}, \text{Data}_{\text{bak}}) = 0 |
Jepsen |
- SLA验证模型
-
分位数回归 保障P99延迟:
\min_{\beta} \sum \rho_{\tau} (y_i - x_i^T \beta), \quad \tau \in \{0.95, 0.99\}(Azure SLO标准)。
-
蒙特卡洛模拟故障率 :
\lambda_{\text{fault}} = -\ln(1 - \text{SLA}) / \text{MTBF}验证容灾能力。
- 性能测试理论
-
弹性伸缩验证 :
\text{Scaling}_{\text{time}} = \alpha \cdot \log(\Delta \text{Load}) + \beta\alpha=0.2, \beta=5(秒级扩容)。
七、数学优化前沿
-
量子退火调度 :
哈密顿量
H = -\sum w_{ij} \sigma_z^i \sigma_z^j求解最优资源分配(D-Wave实验加速100倍)。 -
联邦学习协同 :
\Delta W_{t+1} = \frac{1}{K} \sum \nabla \mathcal{L}_k + \mathcal{N}(0, \sigma^2 I)跨云策略同步(GDPR合规场景)。
-
神经架构搜索 :
\nabla_{\theta} \mathbb{E}_{p_{\theta}(a)} [R(a)] \approx \frac{1}{N} \sum R(a_i) \nabla_{\theta} \log p_{\theta}(a_i)自动生成负载策略(Google AutoML)。
架构价值总结 :
负载均衡虚拟服务器架构通过动态算法×预测模型×数学优化 ,在亿级并发场景下实现资源利用率>70%且延迟≤100ms(如阿里云双11)。核心约束包括 \Delta t_{\text{sync}} < \text{SLA}_{\text{RPO}} 的同步极限与 B_{\text{WAN}}/B_{\text{LAN}} \geq 0.2 的网络带宽比。测试需覆盖 "混沌注入→性能衰减→成本偏离" 三维验证,数学保障需满足 \text{MTTR} \leq 30\text{s} 的工业标准。
2.5.12 不中断服务重定位架构
以下针对云计算领域负载均衡的不中断服务重定位实例架构进行系统性分析,结合数学方法、设计原理及工程实践,构建完整技术框架:
一、定义与核心目标
不中断服务重定位实例架构 (Non-Disruptive Service Relocation Architecture)指在零感知中断的前提下,将运行中的服务实例(如虚拟机、容器)动态迁移至新物理节点或资源池的负载均衡机制。其数学描述为:
\min \left( T_{\text{mig}} \right) \quad \text{s.t.} \quad P(\text{Latency}_{\text{user}} \leq \tau) \geq 0.999 其中 T_{\text{mig}} 为迁移耗时,\tau 为用户感知延迟阈值(通常≤50ms)。
二、实现方法与技术体系
- 动态迁移引擎
-
预拷贝(Pre-Copy)算法 :
迭代传输脏页,迁移时间T_{\text{mig}}满足:T_{\text{mig}} = \sum_{k=1}^{n} \frac{D_k \cdot (1 - \rho_k)}{B} + T_{\text{switch}}其中
D_k为第k轮脏页量,\rho_k为脏页生成率,B为网络带宽(阿里云实测T_{\text{mig}} < 400ms)。 -
内存状态压缩 :采用Delta压缩算法减少传输量:
\text{CompRatio} = 1 - \frac{\| \Delta_{\text{mem}} \|_0}{\| \text{Mem}_{\text{full}} \|_0}, \quad \| \Delta_{\text{mem}} \|_0 < 0.1 \| \text{Mem}_{\text{full}} \|_0
- 智能调度决策
-
蚁群优化(ACO)重定向 :信息素更新规则:
\tau_{ki}(t+1) = (1-\rho) \cdot \tau_{ki}(t) + \sum \Delta \tau_{ki}^h, \quad \Delta \tau_{ki}^h = \frac{W}{\delta_i}\rho为挥发因子,\delta_i为节点负载失衡度(见公式(3))。 -
双曲余弦负载建模 :
\text{Server}_{\text{selected}} = \underset{i}{\arg\min} \ \cosh\left( -\frac{L_i}{\lambda \cdot C_i} \right)L_i为当前负载,C_i为容量,\lambda为优先级因子。
三、设计原则与约束条件
| 原则 | 数学约束 | 技术实现 |
|---|---|---|
| 服务连续性 | T_{\text{downtime}} < 1\text{ms} |
预拷贝 + 内存脏页追踪 |
| 资源利用率 | \frac{\sum \text{CPU}_{\text{used}}}{\sum \text{CPU}_{\text{total}}} \geq 75\% |
动态权重调整 |
| 网络带宽约束 | B_{\text{net}} \geq 2 \cdot \frac{\text{Mem}_{\text{size}}}{T_{\text{SLA}}} |
RDMA加速传输 |
硬性约束:
-
内存脏页率上限:
\rho_k < 0.3(否则触发停机迁移) -
存储同步延迟:
\Delta t_{\text{storage}} < \text{SLA}_{\text{RPO}}(Ceph RBD实践)
四、算法依赖与数学模型
- 负载均衡度量化
-
失衡度方差模型 :
\delta(t) = \frac{1}{N} \sum_{i=1}^{N} (L_i - \bar{L})^2, \quad \text{触发迁移当} \ \delta(t) > \omega\omega为阈值(建议0.2)。 -
Q-learning迁移决策 :奖励函数设计:
r = \frac{1}{T_{\text{mig}}} - \beta \cdot \text{Cost}_{\text{energy}}
- 性能保障模型
-
排队论验证迁移影响 :
W_q^{\text{new}} = \frac{\lambda (\sigma^2 + 1/\mu^2)}{2(k' - \lambda/\mu)}, \quad k' = k + \Delta k_{\text{mig}}\Delta k_{\text{mig}}为迁移新增线程。
五、应用场景效能验证
| 场景 | 数学模型 | 效能 |
|---|---|---|
| 金融交易系统 | P(\text{Latency} \leq 1\text{ms}) \geq 0.99999 |
迁移成功率>99.99% |
| 实时视频渲染 | B_{\text{frame}} = \frac{4K \cdot \text{FPS} \cdot 24}{ \text{CompRatio} } |
丢帧率<0.001% |
| AI训练集群 | \text{IOPS}_{\text{req}} = \frac{2 \cdot \text{BatchSize}}{\text{SeqLen}} |
训练中断率=0 |
六、研发理论与测试方法
- 混沌测试框架
| 测试类型 | 数学指标 | 工具链 |
|---|---|---|
| 网络抖动注入 | \left| \frac{\text{TP}_{\text{after}}}{\text{TP}_{\text{before}}} - 1 \right| \leq 5\% |
Chaos Mesh + tcpdump |
| 存储延迟模拟 | P(\Delta t_{\text{disk}} > 10\text{ms}) < 0.001 |
Ceph QoS限速 |
| 脏页压力测试 | \rho_k > 0.3 时迁移成功率 \geq 99.9\% |
FIO内存压测 |
- SLA验证模型
-
分位数回归保障P99延迟 :
\min_{\beta} \sum \rho_{\tau} (y_i - x_i^T \beta), \quad \tau = 0.99(Azure SLO标准)。
-
蒙特卡洛故障模拟 :
\lambda_{\text{fail}} = -\ln(1 - 0.99999) / \text{MTBF}验证年中断时间<5.26分钟。
- 性能衰减边界模型
-
迁移开销控制函数 :
\text{Overhead} = \alpha \cdot e^{-\gamma \cdot B} + \beta, \quad \alpha=0.8, \gamma=0.05带宽
B每增加1Gbps,开销降低12%。
七、数学优化前沿
-
量子退火迁移调度 :
哈密顿量
H = -\sum w_{ij} \sigma_z^i \sigma_z^j求解最优迁移路径(D-Wave实验加速120倍)。 -
联邦学习负载预测 :
\Delta W_{t+1} = \frac{1}{K} \sum \nabla \mathcal{L}_k + \mathcal{N}(0, \sigma^2 I)跨云协同训练迁移模型(GDPR合规)。
-
随机微分控制 :
dR_t = \mu R_t dt + \sigma R_t dW_t + \gamma \cdot dJ_tJ_t为突发负载跳跃过程。
架构价值总结 :
不中断服务重定位架构通过预拷贝算法×蚁群优化×量子调度 实现物理层透明迁移,在阿里云金融云中达成年故障转移时间<2秒。核心约束需满足
\rho_k < 0.3的脏页率极限与\Delta t_{\text{storage}} < 10\mu s的存储同步边界。测试需覆盖 "混沌注入→脏页压测→SLA崩坏率" 三维验证,数学保障需满足T_{\text{downtime}} < 1\text{ms}的工业标准。