目录
介绍
Kafka是一个分布式流媒体平台,类似于消息队列或企业信息传递系统。
下载
Kafka对于Zookeeper是强依赖,所以安装Kafka之前必须先安装zookeeper
官网:Apache Kafka
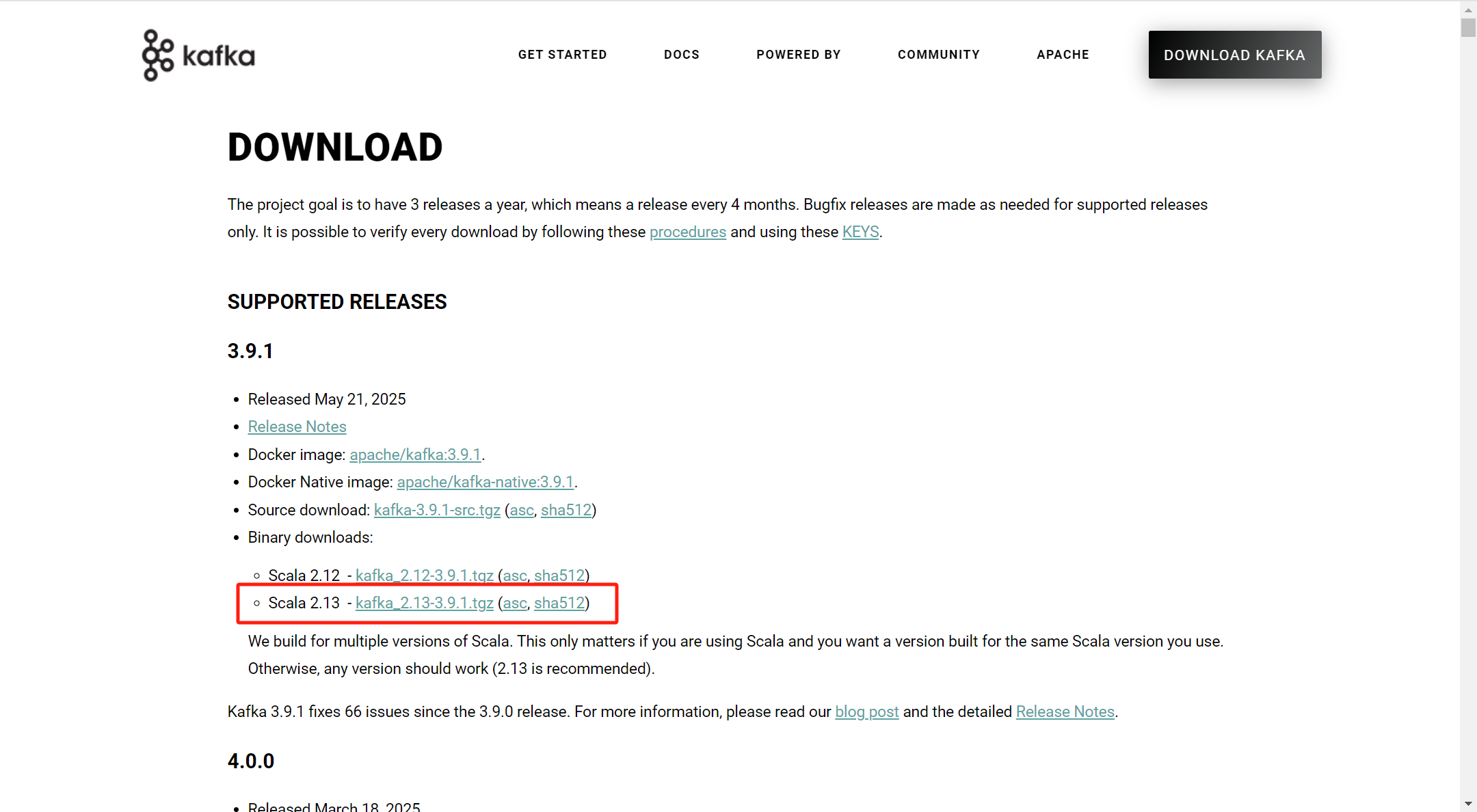
下载此安装包并解压

配置
新建logs文件夹存放日志文件
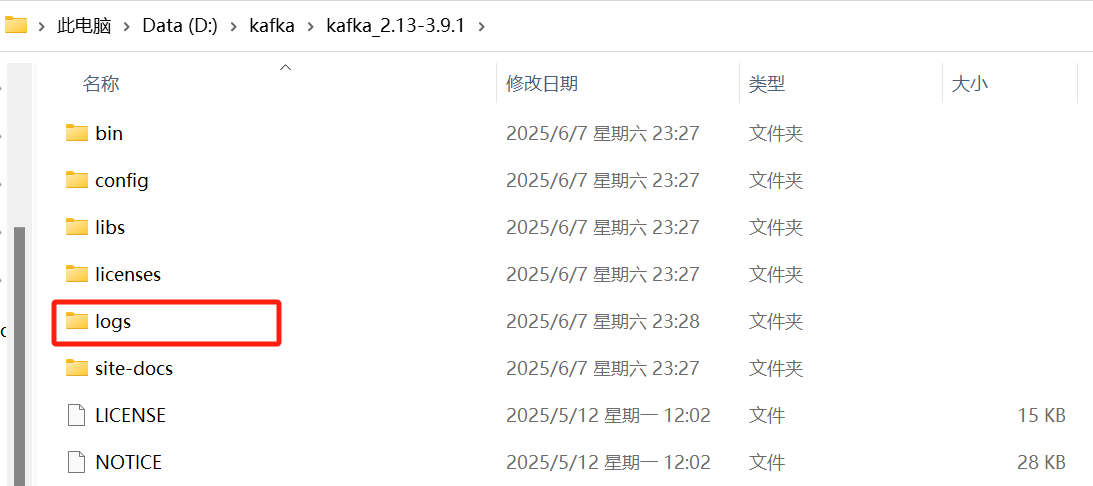
打开config文件夹,找到 zookeeper.properties文件。将dataDir改为上面logs文件夹路径再加上/zookeeper,表示zookeeper的日志文件
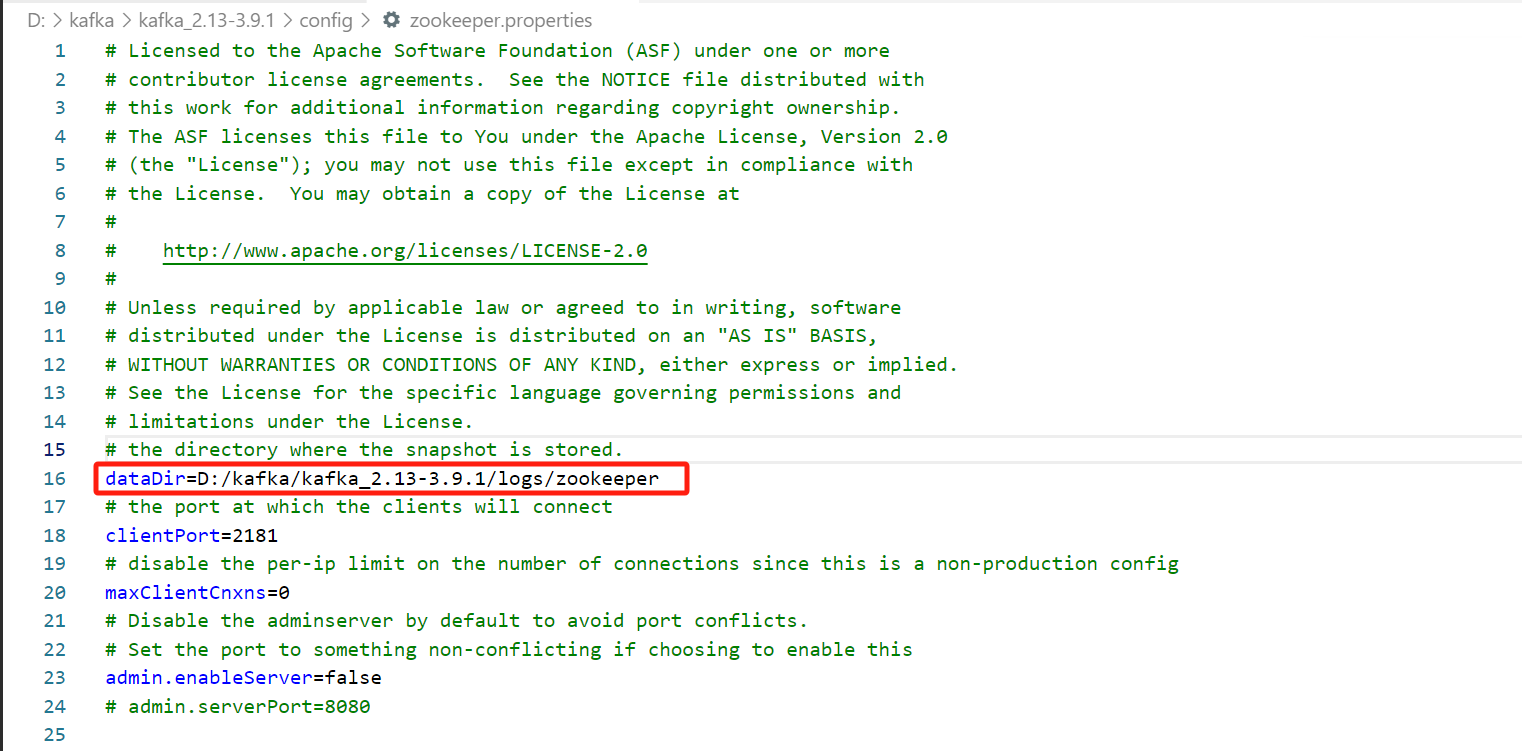
打开config文件夹,找到 server.properties文件。将log.dirs改为上面logs文件夹路径再加上/kafka,表示kafka的日志文件
新建zk.cmd文件,里面放zookeeper启动脚本
call bin/windows/zookeeper-server-start.bat config/zookeeper.properties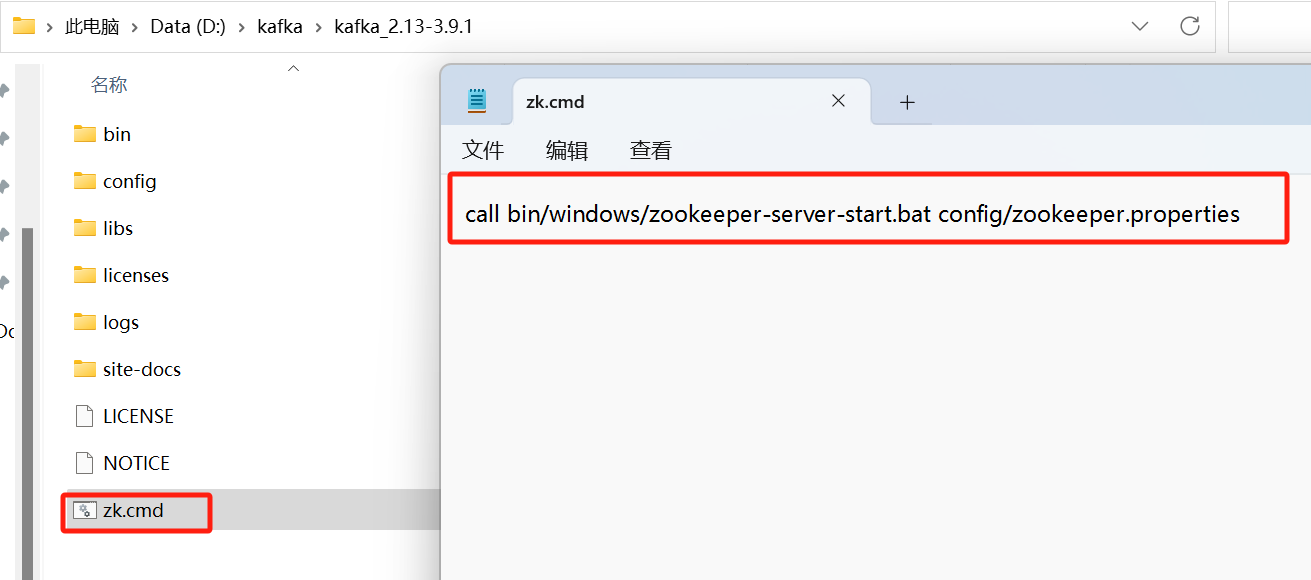
新建kfk.cmd文件,里面放kafka启动脚本
call bin/windows/kafka-server-start.bat config/server.properties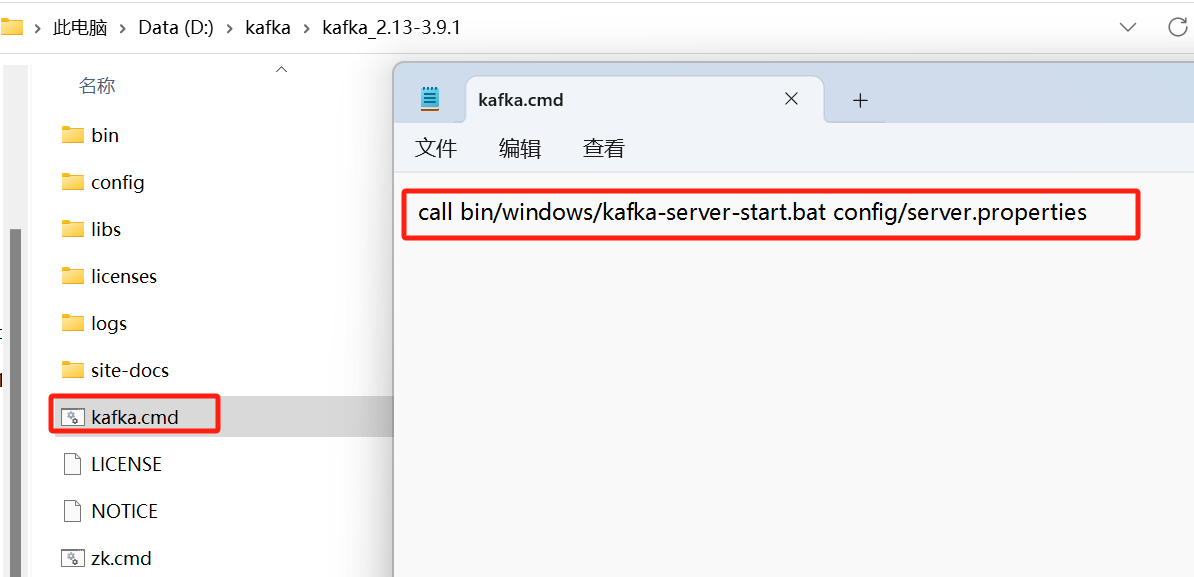
先双击zk.cmd
再双击kafka.cmd(关闭的话相反)
测试
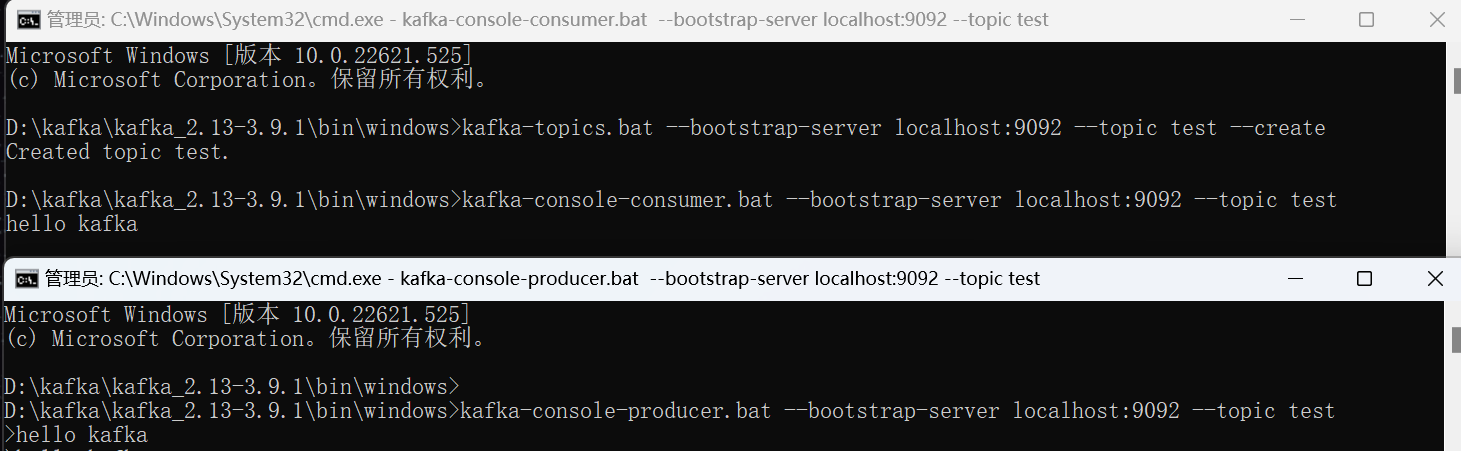
打开两个cmd窗口(bin下的windows),在第一个cmd窗口创建topic
kafka-topics.bat --bootstrap-server localhost:9092 --topic test --create
在第二个cmd窗口 创建生产者
kafka-console-producer.bat --bootstrap-server localhost:9092 --topic test
在第一个cmd窗口 创建消费者
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test回到第二个cmd窗口输入hello kafka 观察第一个cmd窗口是否有输出hello kafka
在idea中创建一个项目kafka-demo
添加kafka依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</dependency>ProducerQuickStart
java
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* 生产者
*/
public class ProducerQuickStart {
public static void main(String[] args) {
//1.kafka的配置信息
Properties properties = new Properties();
//kafka的连接地址
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
//发送失败,失败的重试次数
properties.put(ProducerConfig.RETRIES_CONFIG,5);
//消息key的序列化器
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//消息value的序列化器
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//2.生产者对象
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
/**
* 封装发送的消息
* 参数一:topic
* 参数二:消息的key
* 参数三:消息的value
*/
ProducerRecord<String,String> record = new ProducerRecord<String, String>("topic-first","100001","hello kafka");
//3.发送消息
producer.send(record);
//4.关闭消息通道,必须关闭,否则消息发送不成功
producer.close();
}
}ConsumerQuickStart
java
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* 消费者
*/
public class ConsumerQuickStart {
public static void main(String[] args) {
//1.添加kafka的配置信息
Properties properties = new Properties();
//kafka的连接地址
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
//消费者组(必须设置)
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "group1");
//消息的反序列化器
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
//2.消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
//3.订阅主题
consumer.subscribe(Collections.singletonList("topic-first"));
//当前线程一直处于监听状态
while (true) {
//4.获取消息
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord.key());
System.out.println(consumerRecord.value());
}
}
}
}先运行ConsumerQuickStart 再运行ProducerQuickStart
回到ConsumerQuickStart的控制台
