
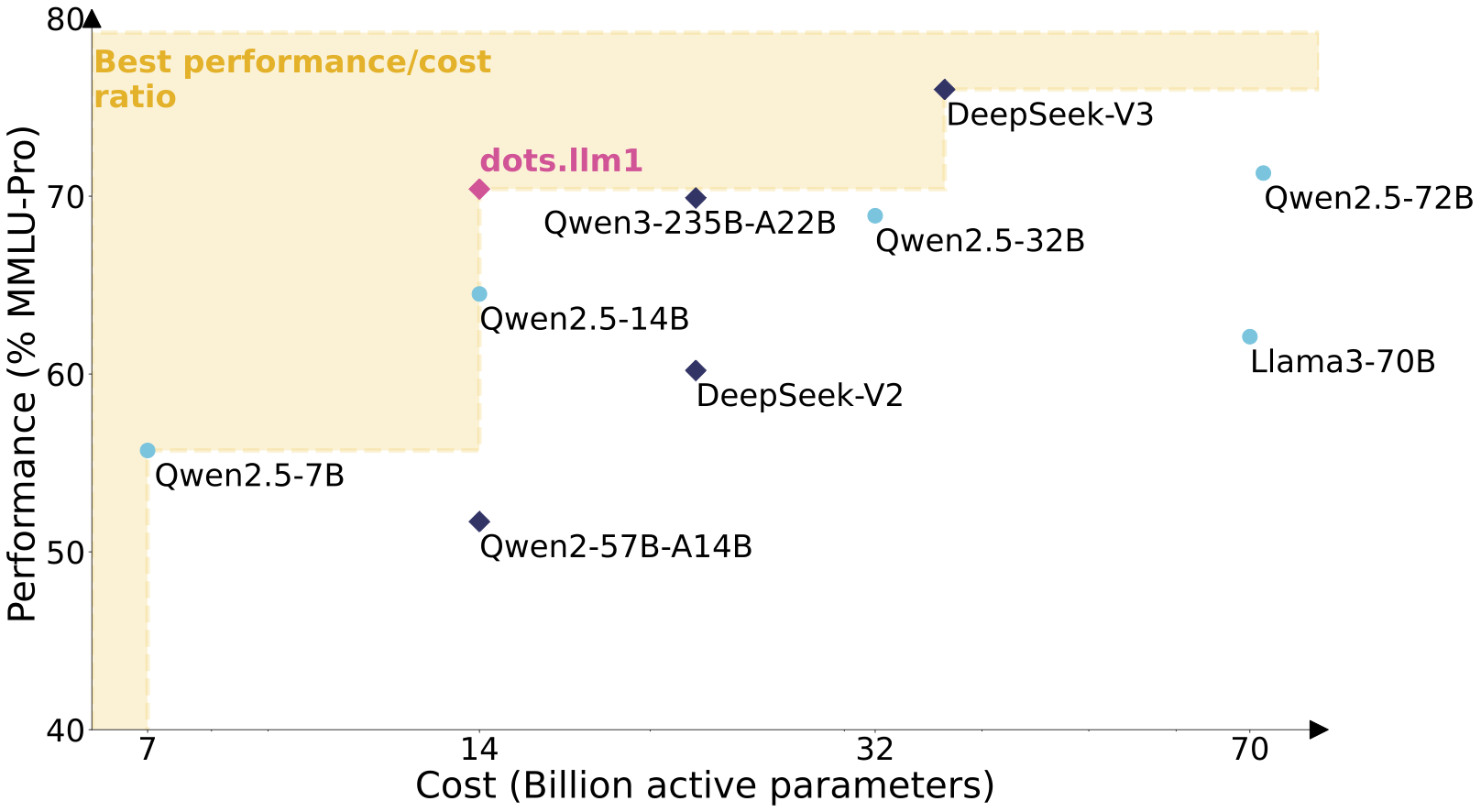
dots.llm1模型是一个大规模混合专家模型(MoE),在总计1420亿参数中激活140亿参数,其性能与最先进模型相当。通过我们精心设计的高效数据处理流程,dots.llm1在预训练11.2万亿高质量token(未使用合成数据)后,性能已可比拟Qwen2.5-72B。为促进进一步研究,我们每训练1万亿token就会开源中间检查点,为大型语言模型的学习动态研究提供宝贵洞见。
模型概要
该仓库包含基础版和指令微调版的dots.llm1模型,具有以下特性:
- 类型:采用混合专家(MoE)架构的模型,激活参数140亿,总参数量1420亿,训练数据量11.2万亿token
- 训练阶段:预训练与监督微调(SFT)
- 架构:注意力层采用多头注意力机制与QK标准化,细粒度MoE结构从128个路由专家中动态选择前6个,另含2个共享专家
- 层数:62
- 注意力头数:32
- 支持语言:英语、中文
- 上下文长度:32,768个token
- 许可协议:MIT
dots.llm1的核心亮点包括:
- 增强的数据处理框架:我们提出可扩展且细粒度的三阶段数据处理框架,专门用于生成大规模、高质量且多样化的预训练数据。
- 预训练阶段零合成数据:基础模型预训练使用了11.2万亿个真实场景产生的高质量文本标记(token)。
- 性能与成本效率:该开源模型推理时仅激活140亿参数,兼具全面能力与高效计算特性。
- 基础设施创新:基于交错式1F1B流水线调度技术,我们研发了创新的混合专家全互联通信与计算重叠方案,配合高效分组GEMM实现显著提升计算效率。
- 模型动态开放研究:每训练1万亿标记即发布中间模型检查点,为大型语言模型学习机制研究提供宝贵资源。
Example Usage
模型下载
| 模型 | 参数总量 | 激活参数量 | 上下文长度 | 下载链接 |
|---|---|---|---|---|
| dots.llm1.base | 142B | 14B | 32K | 🤗 Hugging Face |
| dots.llm1.inst | 142B | 14B | 32K | 🤗 Hugging Face |
Docker (推荐)
Docker镜像基于官方镜像构建,可在Docker Hub获取。
您可以通过vllm启动服务器。
shell
docker run --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p 8000:8000 \
--ipc=host \
rednotehilab/dots1:vllm-openai-v0.9.0.1 \
--model rednote-hilab/dots.llm1.inst \
--tensor-parallel-size 8 \
--trust-remote-code \
--served-model-name dots1那么您可以通过以下方式来验证模型是否成功运行。
shell
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "dots1",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"}
],
"max_tokens": 32,
"temperature": 0
}'使用HuggingFace进行推理
我们正在努力将其合并到Transformers库中(PR #38143)。
文本补全
python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "rednote-hilab/dots.llm1.base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype=torch.bfloat16)
text = "An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)聊天
python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "rednote-hilab/dots.llm1.inst"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype=torch.bfloat16)
messages = [
{"role": "user", "content": "Write a piece of quicksort code in C++"}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=200)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)使用vLLM进行推理
vLLM 是一个面向大语言模型的高吞吐量且内存高效的推理与服务引擎。PR #18254 中提供了对该功能的官方支持。
shell
vllm serve dots.llm1.inst --port 8000 --tensor-parallel-size 8OpenAI兼容API将提供在http://localhost:8000/v1.
使用sglang进行推理
SGLang 是一个用于大型语言模型和视觉语言模型的快速服务框架。SGLang可用于启动具有OpenAI兼容API服务的服务器。该功能的官方支持包含在PR #6471中。
只需运行以下命令即可开始使用:
shell
python -m sglang.launch_server --model-path dots.llm1.inst --tp 8 --host 0.0.0.0 --port 8000A一个OpenAI兼容的API将在 http://localhost:8000/v1.