摘要
检测器将图像中的物体表示为轴对齐的边界框。大多数成功的目标检测方法都会枚举几乎完整的潜在目标位置列表,并对每一个位置进行分类。这种做法既浪费又低效,并且需要额外的后处理。在本文中,我们采取了不同的方法。我们将物体建模为单个点------其边界框的中心点。我们的检测器使用关键点估计来寻找中心点,并回归预测所有其他物体属性,例如大小、三维位置、朝向,甚至姿态。基于中心点的方法 CenterNet 是端到端可微的,更简单、更快速,也比相应的基于边界框的检测器更准确。CenterNet 在 MS COCO 数据集上实现了最佳的速度---精度权衡,在 142 FPS 时达到 28.1% AP,在 52 FPS 时达到 37.4% AP,在多尺度测试(1.4 FPS)时达到 45.1% AP。我们使用相同的方法在 KITTI 基准上估计 3D 边界框,并在人体关键点数据集上进行姿态估计。我们的方法在与复杂的多阶段方法竞争时表现优异,并可实时运行。
引言
目标检测推动了许多视觉任务的发展,如实例分割 7,21,32、姿态估计 3,15,39、跟踪 24,27 和动作识别 5。它在监控 57、自动驾驶 53 以及视觉问答 1 等领域具有下游应用。当前的目标检测器通过一个紧密包围物体的轴对齐边界框来表示每个物体 18,19,33,43,46。然后,它们将目标检测问题简化为对大量潜在边界框的图像分类。对于每个边界框,分类器判断其中的图像内容是某个特定物体还是背景。单阶段检测器 33,43 在图像上滑动一组复杂的、可能的边界框(称为锚点),并直接对它们进行分类,而不指定框的具体内容。两阶段检测器 18,19,46 则为每个潜在框重新计算图像特征,然后对这些特征进行分类。随后通过非极大值抑制(NMS)后处理,依据边界框的 IoU(交并比)去除同一实例的重复检测。该后处理过程难以微分和训练 23,因此大多数当前检测器并非端到端可训练。然而,在过去五年中 19,这一思路已取得了良好的经验性成功 12,21,25,26,31,35,47,48,56,62,63。基于滑动窗口的目标检测虽然成功,但需要枚举所有可能的物体位置和尺寸,因而略显低效。
在本文中,我们提供了一种更简单、更高效的替代方案。我们将物体用其边界框中心的一个点来表示(见图 2)。然后,从该中心位置的图像特征中直接回归预测物体的大小、尺寸、三维范围、朝向和姿态等属性。目标检测便转化为标准的关键点估计问题 3,39,60。我们只需将输入图像送入一个全卷积网络 37,40,它会生成一个热图。热图中的峰值对应物体中心。在每个峰值处提取的图像特征用于预测物体边界框的宽度和高度 。该模型使用标准的密集监督学习进行训练 39,60。推理时仅需一次网络前向传播,无需非极大值抑制等后处理。

我们的方法具有通用性,仅需少量改动即可扩展到其他任务。我们在 3D 目标检测 17 和多人姿态估计 4 上进行了实验,通过在每个中心点预测额外的输出(见图 4)。对于 3D 边界框估计,我们回归预测物体的绝对深度、3D 边界框尺寸和物体朝向 38。对于人体姿态估计,我们将 2D 关节点位置视为相对于中心的偏移量,并在中心点位置直接回归预测这些偏移。
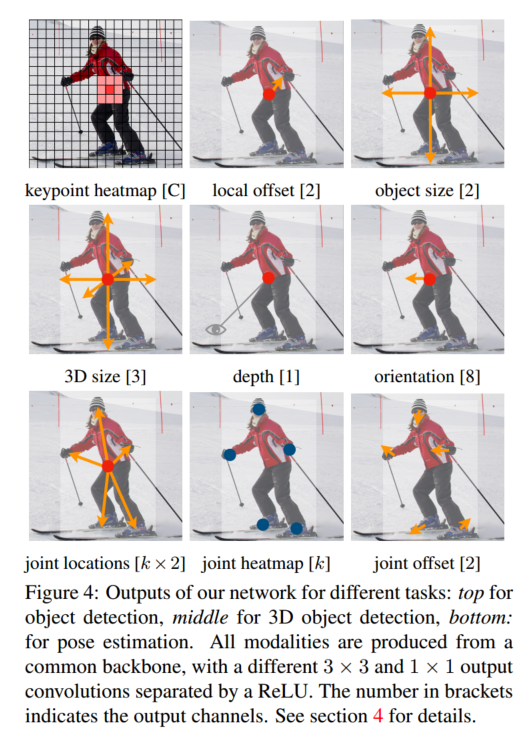
图 4:我们网络在不同任务上的输出:顶部为目标检测,中部为 3D 目标检测,底部为姿态估计。所有这些输出都来自一个通用的主干网络,之后分别通过一个 3×3 和一个 1×1 的输出卷积(中间以 ReLU 激活分隔)。括号中的数字表示输出通道数。详见第 4 节。
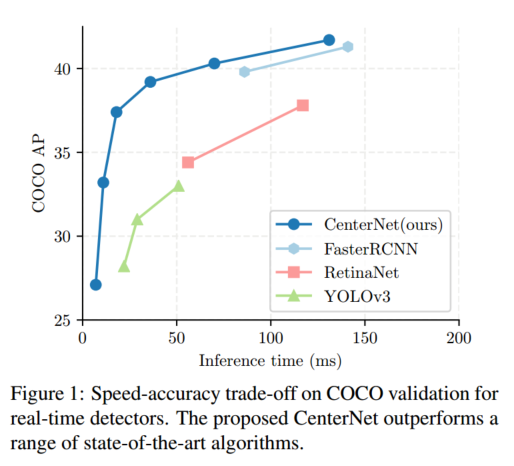
我们的方法 CenterNet 足够简单,能够以非常高的速度运行(见图 1)。使用简单的 ResNet-18 和上采样卷积层 55,我们的网络在 142 FPS 下实现了 28.1% 的 COCO 边界框 AP。使用精心设计的关键点检测网络 DLA-34 58,我们的网络在 52 FPS 下达到 37.4% 的 COCO AP。配备最先进的关键点估计网络 Hourglass-104 30,40 并使用多尺度测试后,我们的网络在 1.4 FPS 下实现了 45.1% 的 COCO AP。在 3D 边界框估计和人体姿态估计任务中,我们以更高的推理速度与最先进的方法竞争。代码已发布于 https://github.com/xingyizhou/CenterNet。
相关工作
基于区域分类的目标检测。 RCNN 19 是最早成功的深度目标检测器之一,它从大量候选区域 52 中枚举目标位置,对每个区域进行裁剪,然后使用深度网络进行分类。Fast R-CNN 18 则对图像特征进行裁剪,以节省计算资源,但两者都依赖于缓慢的低层区域提议方法。
带隐式锚点的目标检测。 Faster R-CNN 46 在检测网络内部生成区域提议。它在低分辨率的图像网格上采样固定形状的边界框(锚点),并将每个锚点分类为"前景或背景"。当锚点与任一真实目标的重叠度(IoU)>0.7 时标记为前景,<0.3 时标记为背景,否则忽略。随后对每个生成的区域提议再次进行分类 18。将提议分类器改为多类分类器构成了单阶段检测器的基础。一阶段检测器的若干改进包括锚点形状先验 44,45、不同的特征分辨率 36 以及对不同样本重加权的损失 33。
我们的方法与基于锚点的一阶段方法 33,36,43 密切相关。中心点可看作是一个与形状无关的单一锚点(见图 3)。但我们的 CenterNet 有几点重要区别。首先,CenterNet 仅基于位置分配"锚点",而不是基于边界框重叠度 18,无需人为设定前景/背景阈值 18。其次,每个物体仅有一个正样本"锚点",因此无需非极大值抑制(NMS)2,只需在关键点热图中提取局部峰值 4,39。第三,CenterNet 使用更高的输出分辨率(输出步幅为 4),而传统检测器输出步幅为 16 21,22,从而无需使用多重锚点 47。

(a) 标准的基于锚框检测。对于任何目标,如果锚框与目标的 IoU > 0.7 则视为正样本,IoU < 0.3 则视为负样本,其它情况忽略。
(b) 基于中心点的检测。将中心像素分配给对应目标;距离中心较近的点会有较低的负样本损失;并回归目标的尺寸。
图 3:基于锚框的检测器 (a) 与我们提出的中心点检测器 (b) 之间的区别。建议在屏幕上观看以获得最佳效果。
通过关键点估计进行目标检测。 我们并不是首个将关键点估计用于目标检测的方法。CornerNet 30 将两个边界框角点检测为关键点,而 ExtremeNet 61 检测所有物体的顶部、左侧、底部、右侧和中心点。这两种方法都建立在与 CenterNet 相同的强大关键点估计网络之上,但它们在关键点检测后需要进行组合分组,这显著降低了速度。而我们的 CenterNet 则仅需为每个物体提取单个中心点,无需分组或后处理。
单目 3D 目标检测。 3D 边界框估计在自动驾驶中至关重要 17。Deep3Dbox 38 使用类似 RCNN 19 的框架,先检测 2D 目标 46,再将每个目标输入到 3D 估计网络。3D RCNN 29 在 Faster R-CNN 46 后添加了一个 3D 投影分支。Deep Manta 6 使用多任务训练的粗到精 Faster R-CNN 46。我们的方法类似于 Deep3Dbox 38 或 3DRCNN 29 的一阶段版本,因此比竞品方法更简单、更快速。
预备知识




4.1 3D检测

4.2人体姿态估计

5、实现细节
我们在四种网络结构上进行了实验:ResNet-18、ResNet-101 55、DLA-34 58 和 Hourglass-104 30。对 ResNet 和 DLA-34 加入了可变形卷积层 12,Hourglass 网络则保持原样。
Hourglass
堆叠砂漏网络(stacked Hourglass)30,40 首先将输入下采样 4×,然后依次通过两个砂漏模块。每个砂漏模块是一个对称的五层下采样---上采样卷积网络,带有跨层跳跃连接。该网络规模较大,但通常能带来最佳的关键点估计性能。
ResNet
Xiao 等 55 在标准残差网络 22 后接三个上采样卷积网络,以获得更高分辨率的输出(输出步幅为 4)。我们首先将这三层上采样的通道数改为 256、128、64,以节省计算量;然后在每个上采样卷积前分别加入一个通道数同为 256、128、64 的 3×3 可变形卷积层。上采样卷积核采用双线性插值初始化。详见补充材料中的结构图。
DLA
深度层聚合网络(DLA)58 是一种带层次化跳跃连接的图像分类网络。我们采用其全卷积上采样版本用于密集预测,通过迭代深度聚合对称地提高特征图分辨率。我们在每个上采样层将原卷积替换为 3×3 可变形卷积 63,在跳跃连接中引入更灵活的采样。详见补充材料中的结构图。
对于所有模型,在每个输出头之前,我们都加入一个 3×3、256 通道的卷积层,随后再接一个 1×1 卷积以产生所需输出。更多细节见补充材料。
训练
输入分辨率为 512×512,产生的输出分辨率为 128×128。数据增强包括随机翻转、随机缩放(0.6--1.3)、裁剪和颜色抖动;使用 Adam 28 优化总体目标。由于裁剪或缩放会改变 3D 测量,我们对 3D 分支不做增强。ResNet 和 DLA-34 以批量大小 128(8 GPUs)训练 140 个 epoch,初始学习率 5e-4,在第 90 和 120 个 epoch 时各将学习率降低 10×(同 55)。Hourglass-104 按 ExtremeNet 61 设置,批量大小 29(5 GPUs,其中主 GPU 批量大小为 4),学习率 2.5e-4,训练 50 个 epoch,第 40 个 epoch 时学习率降低 10×。检测任务中,为节省计算,Hourglass-104 从 ExtremeNet 61 微调。ResNet-101 和 DLA-34 的下采样层使用 ImageNet 预训练权重,上采样层随机初始化。ResNet-101 和 DLA-34 在 8 枚 TITAN-V GPU 上训练 2.5 天,Hourglass-104 则需 5 天。
推理
我们使用三种测试增强策略:无增强、翻转增强、翻转+多尺度(0.5、0.75、1、1.25、1.5)。对于翻转增强,先对网络输出取平均,再解码边界框;对于多尺度,则使用 NMS 合并结果。这些增强在速度---精度上提供了不同的权衡,见下节分析。
实验
我们在 MS COCO 数据集 34 上评估目标检测性能。该数据集包含 118k 训练图像(train2017)、5k 验证图像(val2017)和 20k 测试图像(test-dev)。我们报告所有 IoU 阈值上的平均精度(AP),以及 IoU=0.5(AP50)和 IoU=0.75(AP75)下的 AP。补充材料中包含 PascalVOC 14 上的额外实验。
6.1 目标检测
表 1 列出了在 COCO 验证集上,不同主干网络和测试选项下的结果;图 1 将 CenterNet 与其它实时检测器进行速度---精度对比。运行环境:Intel Core i7-8086K CPU、Titan Xp GPU、PyTorch 0.4.1、CUDA 9.0、cuDNN 7.1。我们下载各模型官方代码和预训练权重¹²,在同一机器上测运行时间。
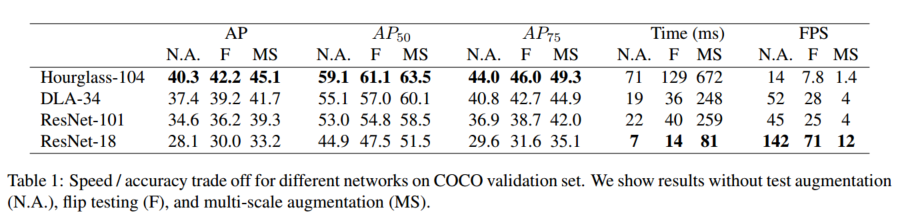
Hourglass-104 在较高精度和较好速度间取得平衡:7.8 FPS 下 42.2% AP。该主干上,CenterNet 在速度和精度上均优于 CornerNet 30(4.1 FPS,40.6% AP)和 ExtremeNet 61(3.1 FPS,40.3% AP)------得益于更少的输出头和更简单的解码方式;更高精度表明中心点比角点或极值点更易检测。
ResNet-101 主干下,我们也超越了同样主干的 RetinaNet 33:在相同精度下速度提升超 2 倍(CenterNet 34.8% AP @ 45 FPS (512×512) vs. RetinaNet 34.4% AP @ 18 FPS (500×800))。我们最快的 ResNet-18 模型在 142 FPS 下也能取得 28.1% AP。
DLA-34 实现了最佳的速度---精度折衷:52 FPS 下 37.4% AP,比 YOLOv3 45 快超 2 倍、精度高 4.4% AP。加入翻转测试后,CenterNet 39.2% AP @ 28 FPS 仍快于 YOLOv3,且达到 Faster-R-CNN-FPN 46 水平(39.8% AP @ 11 FPS)。
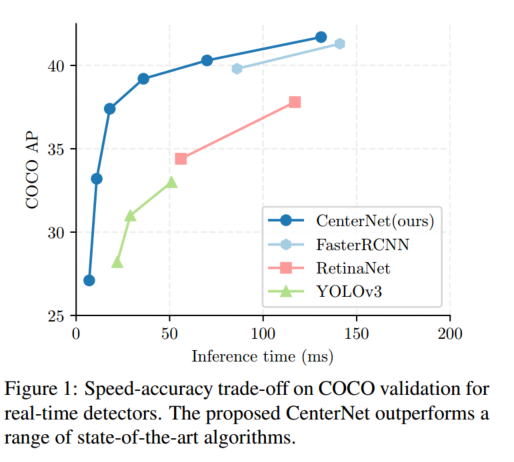
与最先进方法对比
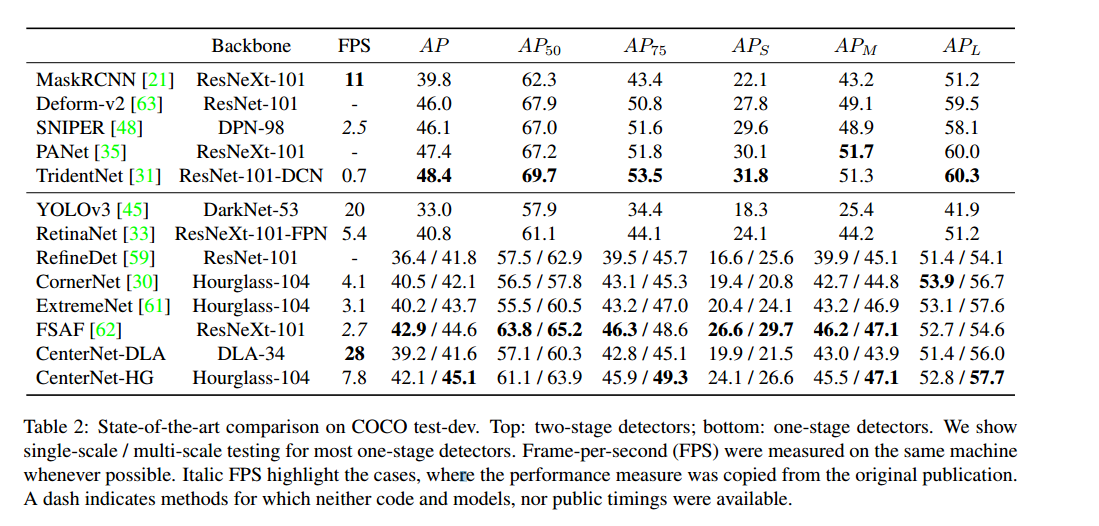
表 2 给出了 COCO test-dev 上的对比。多尺度测试下,Hourglass-104 主干的 CenterNet 达到 45.1% AP,超越所有现有一阶段检测器。复杂的两阶段方法 31,35,48,63 精度更高但速度更慢。CenterNet 在不同目标尺寸和 IoU 阈值下表现与常规模型无异,只是更快。
6.1.1 额外实验
中心点冲突
在 COCO 训练集中,步幅 4 下有 614 对物体中心重合。总对象数 860 001,因此因中心冲突丢失的检测 <0.1%,远低于 RCNN 因提议不足丢失的 ∼2% 52,以及 Faster-RCNN 因锚点不足丢失的 20.0% 46(15 锚点、IoU 0.5)。且其中 715 对重合的框 IoU>0.7,本应分配两个锚点,中心点方法冲突更少。

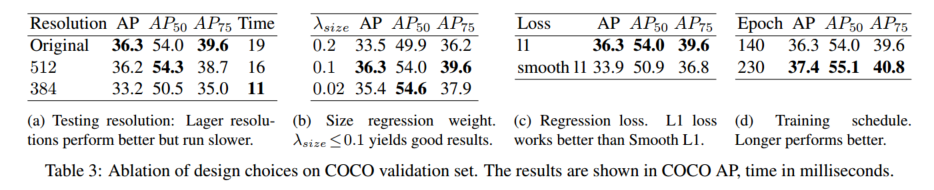
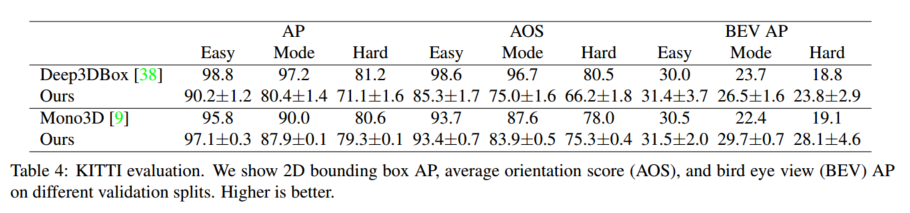
6.2 3D 检测
在 KITTI 数据集 17 上做 3D 边界框估计,包含 7841 张带车辆 3D 标注的训练图。按文献 10,54 划分训练/验证,评测使用 11 个召回率(0.0--1.0,步长 0.1)下的 AP@IoU 0.5,包括 2D AP、朝向精度 AOS 及鸟瞰图 BEV AP。训练/测试均保持原分辨率并填充至 1280×384;70 epoch 收敛,45、60 epoch 处各降 LR。主干用 DLA-34,深度/朝向/尺寸损失权重均设 1,其它超参同检测任务。
由于阈点少,验证 AP 波动达 10%,我们训练 5 个模型并报告均值±标准差。与 Deep3DBox 38(slow-RCNN)和 Mono3D 9(Faster-RCNN)对比(各自验证集划分),表 4 显示 CenterNet 在 AP、AOS 上持平,BEV 上略优,速度快两个量级。
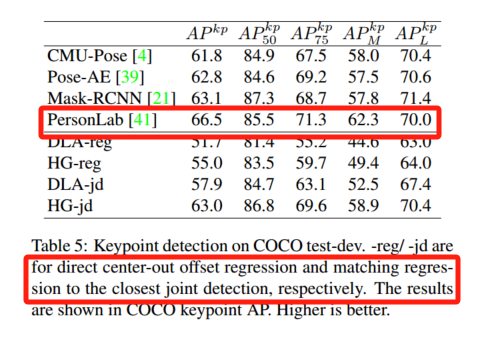
6.3 姿态估计
在 MS COCO 上评估多人姿态,使用关键点 AP(用关键点相似度替代 IoU)。在 COCO test-dev 上与其它方法对比。
我们用 DLA-34(320 epoch,≈3 天/8 GPU 收敛)和 Hourglass-104(150 epoch,≈8 天/5 GPU 收敛),所有额外损失权重设 1,其它超参同检测。表 5 显示:直接回归关节点表现尚可但难进高 IoU;将回归值映射到最近热图检测点后,AP 大幅提升,与最先进的多人体姿态方法 4,21,39,41 相当,验证了 CenterNet 的通用性和易适应性。图 5 给出各任务的定性示例。

结论
综上所述,我们提出了一种新的物体表示方式:将物体视为点(points)。我们的 CenterNet 目标检测器基于已有的关键点估计网络,定位物体中心点,并回归其尺寸。该算法简单、快速、准确,并且端到端可微分,无需任何 NMS 后处理。这个思想具有通用性,可广泛应用于二维检测之外的场景。CenterNet 能在一次前向传递中估计多种额外的物体属性,例如姿态、三维朝向、深度和范围。我们的初步实验结果令人鼓舞,并为实时物体识别及相关任务开启了新的研究方向。