一、字符集和字符编码概念
1、字符集 (Character Set)
- 定义:一个预定义的字符集合,为每个字符分配一个
唯一的编号(称为"码点"或"代码点") - 作用:定义能够
表示哪些字符(如字母、数字、符号、汉字等) - 例子:
ASCII:最基本的字符集!包含128个字符(英文字母、数字、常用标点、控制字符)ISO-8859 系列:扩展了ASCII,用于西欧、东欧等不同语言区域GB2312 / GBK / GB18030:中国国家标准字符集,包含简体汉字、拉丁字母、数字等Big5:繁体中文常用字符集JIS X 0208:日本常用字符集(包含汉字和假名)Unicode:最重要的现代字符集!目标是包含世界上所有书写系统的所有字符,并为每个字符分配一个唯一的码点
2、字符编码 (Character Encoding)
- 定义:一种将
字符集中的码点转换成计算机能够存储和传输的二进制序列(字节序列)的规则。 - 作用:解决
如何存储和传输字符集中的字符的问题 - 例子:
ASCII 编码:最简单的编码,直接将 ASCII 码位(0-127)存储为一个字节(最高位为0)。例如A的码位是 65,编码后就是字节0x41(二进制01000001)ISO-8859-1 编码:直接将码位(0-255)存储为一个字节GBK 编码:对于 ASCII 范围内的字符(0-127),用一个字节表示(与 ASCII 兼容)。对于汉字和其他扩展字符,用两个字节表示。编码规则有特定的映射表UTF-8: 最流行、最重要的 Unicode 编码方式之一。它是一种变长编码,使用 1 到 4 个字节来表示一个 Unicode 码位UTF-16:使用 2 或 4 个字节来表示一个 Unicode 码位UTF-32:使用固定的 4 个字节来表示每一个Unicode 码位
3、关键区别与联系
- 一个字符集可以有多种编码方式。这是理解它们区别的关键!
- Unicode 字符集就有多种编码方式:UTF-8, UTF-16, UTF-32, 还有早期的 UCS-2 等
- 一种编码方式通常对应一个特定的字符集(或兼容其子集)
- UTF-8 编码只能表示 Unicode 字符集中的字符
- GBK 编码对应 GBK 字符集(它是 GB2312 的扩展)
- ASCII 编码只对应 ASCII 字符集(128个字符)
- 总结一句话:
字符集决定有哪些字符,字符编码决定怎么存/传字符(字符集码位到字节的映射规则)
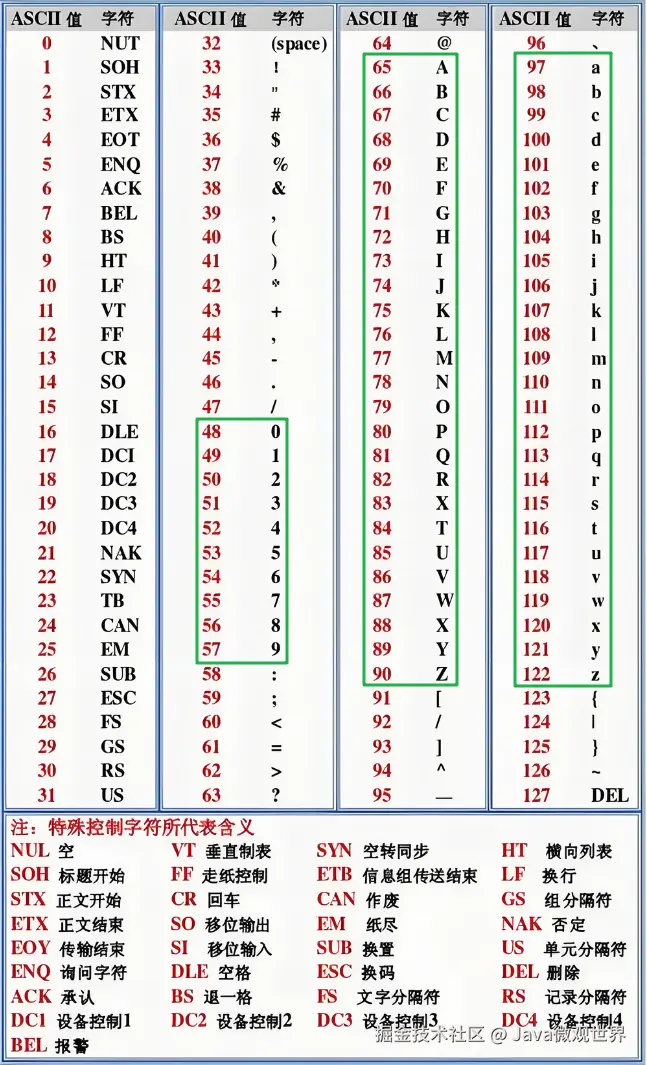
一、ASCII(字符集/字符编码)
ASCII既是一个字符集,也是一个编码方案,并且是一体的。它定义了字符集(包含哪些字符)同时也定义了这些字符如何用数字表示(编码)。
1、ASCII字符集
ASCII 是美国信息交换标准代码,是最早的一种字符集,由美国标准协会(ANSI)在 1963 年制定,用于解决字符标准化和跨平台通信需求,便于计算机统一处理英语文本。
ASCII字符集特点:
- ASCII定义了
128个字符,33个控制字符(0-31与127),95个可打印字符- 前32个字符和最后一个是
不可打印的,包括控制字符,回车键、换行键、空格、删除等 - 后95个字符是
可打印的,包括字母、数字、标点符号等
- 前32个字符和最后一个是
- 适合英文,不支持中文、日文、韩文等非拉丁文字
ASCII字符集标准码表:
2、ASCII字符编码
ASCII 编码是一种将字符转换为数字(并最终转为二进制)的规则,它是对ASCII字符集中字符的具体编码方式。每个 ASCII 字符用 7 位二进制数表示,对应一个十进制值(0~127)。
ASCII编码特点:
- 每个字符使用
7 位(bit)编码,通常在存储或传输时补成一个完整的8位字节(byte),最高位补0
ASCII编码示例表:
| 字符 | 十进制 | 二进制 |
|---|---|---|
| A | 65 | 01000001 |
| a | 97 | 01100001 |
| 0 | 48 | 00110000 |
| 空格 | 32 | 00100000 |
| ! | 33 | 00100001 |
| Z | 90 | 01011010 |
3、扩展ASCII
ASCII扩展于1981年由IBM在其PC中首次大规模实施,主要原因是原始ASCII的7位限制无法满足多语言需求和8位硬件潜力。扩展增加了128个字符(128-255),包括符号、图形和西欧语言字符。
扩展 ASCII 的方式:
- 标准 ASCII 是 7 位,扩展 ASCII 将字符扩展为 8 位(1 字节),总数变为 256(0--255)
标准 ASCII,范围0-127,包含英文字符、数字、符号、控制字符扩展 ASCII,范围128-255,包含特殊拉丁字母、图形符号等
常见扩展 ASCII 版本(扩展部分没有统一标准,不同厂商定义了不同的字符表):
| 字符集名 | 简称/编号 | 特点 | 典型用途 |
|---|---|---|---|
ISO 8859-1 |
Latin-1 | 欧洲最常用,支持英语、西班牙语、德语、法语等 | HTML 网页、Linux 系统 |
Windows-1252 |
ANSI/CP1252 | 微软对 Latin-1 的扩展,加入了 "©™" 等常见字符 | Windows 平台默认编码 |
Mac Roman |
Apple Macintosh 系统使用,支持法语、西语等 | 早期 Mac OS 系统 | |
ISO 8859-5 |
扩展 ASCII 用于西里尔字母(俄语) | 东欧国家 |
扩展ASCII 编码方式:
- 编码位数:8 位(二进制),即一个字节
- 编码范围:0--255
0--127:标准 ASCII 保持不变128--255:扩展字符区
- 可表示:
- 各种语言的特殊字母(é, ñ, ü 等)
- 图形符号(█, ░, ═)
- 特殊符号(©, ®, °, ±)等
总结一句话:
扩展 ASCII 是为了解决标准 ASCII 无法支持国际字符的问题,但由于缺乏统一标准(不同系统的扩展方式不同),最终被 Unicode(如 UTF-8) 所取代。
二、GB2312(字符集/字符编码)
GB2312是一个既包含字符集也定义了编码规则的国家标准。
1、GB2312字符集
随着计算机在中国的普及,中国需要一种适合处理简体汉字的编码方案,因为早期的英文ASCII编码(仅支持128个字符)无法满足中文使用需求。中国大陆在1980年代初期推出的一种汉字编码字符集,主要用于简体中文信息的处理和交换。
GB2312字符集组成:
- 1️⃣ 汉字字符(
6763个汉字)- 一级汉字:3755 个,常用汉字,按拼音顺序排列
- 二级汉字:3008 个,次常用汉字,按部首结构排列
- 2️⃣ 非汉字字符(共
682个)- 拉丁字母(A--Z, a--z)
- 希腊字母(α,β 等)
- 日文假名(片假名)
- 数字(0--9)
- 标点符号(中英文)
- 常用符号(如 ©,¥,℃)
- 3️⃣ ASCII 字符(
128个),属于兼容范围
GB2312 字符集使用分区管理:
- GB2312将字符集划分为
94个区,每区包含94个位,形成94×94的编码矩阵,总计8836个码位(也称为区位码)01-09区:收录除汉字外的682个全角字符10-15区:空白未使用(预留扩展)16-55区:一级汉字(3755个),按汉语拼音排序56-87区:二级汉字(3008个),按部首/笔画排序88-94区:空白未使用(预留扩展)
- GB2312 字符集中字符的
区位码 = 区号 + 行号 + 列号,也可以说是区位码 = 区号 + 位号(后续字符编码会用到)
01-09区:除汉字外的 682 个全角字符
- 每个区的
(0,0)处是没有定义字符的,每个区有定义字符的区域在(0,1) ~ (9,4),所以每个区刚好包含94个码点

16-55区:收录 3755 个一级汉字,即常用汉字
'饼'在第17区的第9行第3列,所以其对应的区位码:区号 + 行号 + 列号 =1793

56-87区:收录 3088 个二级汉字,即次常用汉字
'侃'在第57区的第0行第9列,所以其对应的区位码:区号 + 位号 =5709

2、GB2312字符编码
- GB2312 规定对收录的每个字符采用
两个字节表示(兼容的ascill依然单个字节)- 第一个字节为"高字节",对应 94 个区(01-94区)
- 第二个字节为"低字节",对应 94 个位(每个区对应的94个位置,也是01-94)
- 这就看出区位码的最大范围是:
0101-9494(01区的01位 到 94区的94位)
区号和位号分别加上0xA0(十进制为160)就是GB2312编码- 第一个字节和第二个字节就由
01-94变成了161-254(对应十六进制0xA1-0xFE) - 此时GB2312编码对应范围就是
0xA1A1 - 0xFEFE
- 第一个字节和第二个字节就由
举例:'侃'字的存储方式
- 区号为57,也就是第一个字节为57,加上160为
217(对应十六进制为0xD9) - 位号为行号+列号为09,也就是第二个字节为09,加上160为
169(对应十六进制为0xA9) - 最终
'侃'字存储方式十进制为217 169(对应十六进制为0xD9 0xA9)
java
public static void main(String[] args) throws UnsupportedEncodingException {
byte[] bytes = "侃".getBytes("GB2312");
System.out.print("字节(十进制): ");
for (byte b : bytes) {
// & 0xFF 把负数转为无符号正整数
System.out.print((b & 0xFF) + " ");
}
System.out.println();
System.out.print("字节(十六进制): ");
for (byte b : bytes) {
// 0xFF & b 用于转无符号整数
System.out.printf("%02X ", b & 0xFF);
}
}输出结果:
java
字节(十进制): 217 169
字节(十六进制): D9 A9 为什么区号和位号都需要加上 0xA0(十进制为160)?
- 因为区是一个字节,位是一个字节,这两个字节都是从
01开始的,只有都加上160,才能避开 ASCII 和其他编码冲突
| 十六进制范围 | 十进制 | 是否适合 GB2312 用作编码 | 原因 |
|---|---|---|---|
| 0x00--0x7F | 0--127 |
❌ | 保留给英文及控制字符 |
| 0x80--0x9F | 128--159 | ❌ | ISO 控制符、编码冲突 |
| 0xA1--0xFE | 161--254 |
✅ ✅ ✅ | 国际标准、终端兼容、无冲突 |
3、GB2312如何兼容ASCII
单字节部分- ASCII 码使用单字节表示,取值范围是
0x00 到 0x7F(十进制 0 到 127) - 在 GB2312 中,0x00--0x7F 的字节值与 ASCII 完全相同
- 因此,当你在一个以 GB2312 视作"编码"环境中读到一个字节,如果它落在
0x00--0x7F,就可以直接当成 ASCII 字符来解释
- ASCII 码使用单字节表示,取值范围是
双字节部分- 双字节编码的两个字节都落在
0xA1 到 0xFE(十进制 161 得 254)这个范围内(GB2312 标准定义的有效区域) - 程序将这个读到的"高位字节"(第一个字节)和紧随其后的"低位字节"(第二个字节)组合在一起,形成一个两字节的编码。然后,它去查询 GB2312 的码表,找到这个双字节编码对应的汉字或符号
- 双字节编码的两个字节都落在
三、GBK(字符集/字符编码)
1、GBK字符集
GBK于1995年推出,是为了解决GB2312无法覆盖所有汉字(如生僻字和繁体字),GBK扩展GB2312字符集,支持更多生僻字、繁体字及少数民族文字。
GBK字符集组成:
单字节部分(ASCII)- 范围:0x00--0x7F(0-127)
- 包括:英文字母、数字、标点、控制字符等
双字节部分(汉字和其他符号)- 第1字节:
0x81--0xFE(129-256),共126位 - 第2字节:
0x40--0xFE(64-256),除0x7F,共191位 - 理论编码空间:126 × 191 = 24066 个位置
- 实际使用:
21886个字符 - 包含字符
- 全部的 GB2312 汉字(6763 个)
- 扩展汉字(约 18000 个)
- 常用繁体字
- 日文假名
- 希腊字母、俄文、西欧字符等
- 图形符号、制表符等
- 第1字节:
2、GBK字符编码
GBK 和 GB2312 虽然有相似的结构(比如都使用区位码的概念),但它们在编码范围、字符数量、区位定义等方面存在明显区别。
| 特征 | GB2312 | GBK |
|---|---|---|
| 编码方式 | 双字节 | 双字节 |
| 区的数量 | 最多 94 个区 |
最多 126 个区(范围更广) |
| 每区字符数量 | 最多 94 个 |
最多 191 个(不再固定 94) |
| 兼容区位结构 | ✅ 是 | ✅ 基于并扩展 |
GBK编码表:
- 区号从
0x81-0xFE,一共126个分区 - 位号=行号+列号,从
0x40--0xFE,排除0x7F和0xFF(后面解释),实际就190个位置 - 编码方式:第一个字节(区号)+ 第二个字节(位号)

... 省略中间的

GBK编码表为什么区号从0x81开始,位号从0x40开始,而且要排除0x7F和0xFF?
首字节0x81对应十进制129,这样就避开了标准ASCII0-127的范围了。次字节从0x40开始也是为了避开控制字符(兼容ASCIl和扩展字符)
0x7F 在 ASCII 表中是 DEL(删除)控制字符,在很多系统(特别是 Unix、DOS)中,0x7F 被保留用作控制功能。为避免误解或触发系统控制行为,被明确排除在 GBK 编码双字节的第二字节之外。
0xFF 是字节中的最大值,在很多编码协议中具有特殊含义,比如表示结束、填充、掩码等。它在一些通信协议中会被当作控制字节,因此也被排除以确保兼容性和稳定性。
3、GBK如何兼容GB2312
GB2312编码表区号和位号都是十进制,而且需要同时+160,而GBK则规则简单一些,直接就是十六进制的区号加位号即可,下面我们从GBK的编码表中找下'侃'字,如下也是0xD9A9,这也就说明了GBK是兼容GB2312的

四、Unicode(字符集)
Unicode是1991年一种国际标准字符集,旨在为全球所有语言的每个字符分配一个唯一的编码(称为码点),解决不同字符集间的兼容性问题。
解决的根本问题
- 在Unicode出现之前,存在数百种不同的、互不兼容的字符编码(如ASCII、ISO-8859系列、GB2312/GBK、Big5、Shift-JIS等)
- 这导致了严重的混乱:同一个数字在不同编码中可能代表完全不同的字符;文本在不同系统间交换时经常出现乱码;多语言文本共存非常困难
核心设计原则
通用性: 包含所有现代及许多历史书写系统的字符,以及大量符号(数学、技术、货币、标点、表情符号等)唯一性: 每个字符(或可组合字符的一部分)都被分配一个唯一的码点。这个码点是一个数字(通常表示为U+XXXX,其中XXXX是4-6位的十六进制数)- U+0041 = 拉丁大写字母 'A'
- U+4E2D = 汉字 '中'
- U+1F600 = 笑脸表情符号 😀
无歧义: 一个码点永远只对应一个字符(语义上),反之亦然(理想情况下)
编码空间与平面
- Unicode的理论编码空间是21位(从
U+0000到U+10FFFF),总计超过100万个可能的码点 - 这个空间被划分为
17个平面,每个平面包含65,536(2^16)个码点 基本多语言平面BMP是最重要的,包含了世界上最常用的字符(U+0000到U+FFFF)- 其他平面用于辅助文字、历史文字、特殊符号、私人使用区等

Unicode的实现:编码形式
- Unicode字符集定义了
字符和码点的映射关系,但它本身不规定字符在计算机中的存储方式(即编码方案) - 常见编码包括:
UTF-8:最常用;可变长度(1--4 字节);兼容 ASCII;在互联网上使用最广泛UTF-16:可变长度(2 或 4 字节);Windows 系统常用UTF-32:固定长度(4 字节);适合需要快速随机访问的系统
五、UTF-32、UTF-16(字符编码)
1、UTF-32编码方式
- UTF-32是一种
固定长度的Unicode编码方案,每个字符始终使用32位(4字节)表示 - 编码方式:直接将Unicode字符的码点转换为
32位二进制整数存储- 字符"A"(U+0041)的UTF-32编码为0x00000041
- 汉字"啊"(U+554A)的UTF-32编码为0x0000554A
- 码点范围:覆盖Unicode全部码点(U+0000至U+10FFFF),实际仅需21位,高位补0
2、UTF-16编码方式
- UTF-16是一种
变长的Unicode字符编码方式,它使用2字节或4字节来表示一个字符 - 对于位于基本多语言平面BMP(U+0000-U+FFFF)的字符,UTF-16使用
一个16位的代码单元来表示- 字符"A"(U+0041)的UTF-16编码为0041
- 字符"你"(U+4F60)的UTF-16编码为4F60
- 对于位于辅助平面(U+10000-U+10FFFF)的字符,UTF-16需要使用
两个16位的代码单元(称为代理对)来表示- 假设计算Unicode码点U+1F60A(😊表情符号)对应的代理对
- 将Unicode码点
减去0x10000(0x1F60A - 0x10000 = 0xF60A) - 将计算结果0xF60A转为二进制20位,不够前面补0,分为两部分,
高10位0x3D和低10位0x20A - 将高10位与
0xD800相加,得到高位代理(0x3D + 0xD800 = 0xD83D) - 将低10位与
0xDC00相加,得到低位代理(0x20A + 0xDC00 = 0xDE0A) - 最终 😊 = U+1F60A = 0xD83D 0xDE0A
3、字节顺序标记(BOM)
UTF-16 和 UTF-32 都是多字节编码(每个代码单元占用 2 或 4 个字节),因此在存储或传输时,字节顺序(大小端)至关重要。这就是字节顺序标记(BOM)存在的原因。
字节顺序
大端(Big-Endian, BE):高位字节在前,低位字节在后(类似人类读书方式,先左后右)- 例如:字符 U+4E2D (中) 的 UTF-16BE 编码:4E 2D
小端(Little-Endian, LE):低位字节在前,高位字节在后(就是大端的倒序)- 例如:字符 U+4E2D (中) 的 UTF-16LE 编码:2D 4E
字节顺序标记BOM
- BOM(Byte Order Mark) 是一段特定的字节序列,出现在文本文件开头
- 用于指示文件的字节顺序(大端序或小端序)
- UTF-16大端BOM为
0xFE 0xFF - UTF-16小端BOM为
0xFF 0xFE - UTF-32大端BOM为
0x00 0x00 0xFE 0xFF - UTF-32大端BOM为
0x00 0x00 0xFE 0xFF
- UTF-16大端BOM为
总结对比表
| 编码方式 | 字节序 | 示例字符 U+1234 |
存储字节序列 | BOM(文本文件开头) |
|---|---|---|---|---|
| UTF-16LE | 小端 | U+1234 | 34 12 |
FF FE |
| UTF-16BE | 大端 | U+1234 | 12 34 |
FE FF |
| UTF-32LE | 小端 | U+00001234 | 34 12 00 00 |
FF FE 00 00 |
| UTF-32BE | 大端 | U+00001234 | 00 00 12 34 |
00 00 FE FF |
大小端作用对比
- 大端注重"人类可读性"和标准化(通信、协议)
- 小端注重"计算机效率"和实际处理便利(内存、CPU)
六、UTF-8(字符编码)
UTF-8(8-bit Unicode Transformation Format)是Unicode字符集的一种可变长度字符编码,能够表示Unicode标准中的任何字符(覆盖范围U+0000至U+10FFFF)。
UTF-8 针对不同的 Unicode 字符的编码规则如下:

不同字符通过 UTF-8 编码之后,存储在计算机中的内容用1~4字节来存储,计算机通过不同字节不同前缀区分(上图二进制红色固定前缀)
字节分配规则:ASCII字符用1字节(U+0000~U+007F),希腊字母等用2字节(U+0080~U+07FF),中文字符用3字节(U+0800~FFFF),生僻字符用4字节(U+10000以上)
UTF-8编码方式
- 以汉字
'中'为例,Unicode码点U+6C49转为10进制:20013 - 码点 20013 属于 2048 ~ 65535 范围,编码之后需要用
3字节存储 将码点转换为二进制,20013 ---> 01001110 00101101(空缺位置用0填充,凑到8bit的整数倍)- 最终存储在计算机中的内容用
3字节存储,其十六进制形式是0xE4 0xB8 0xAD
