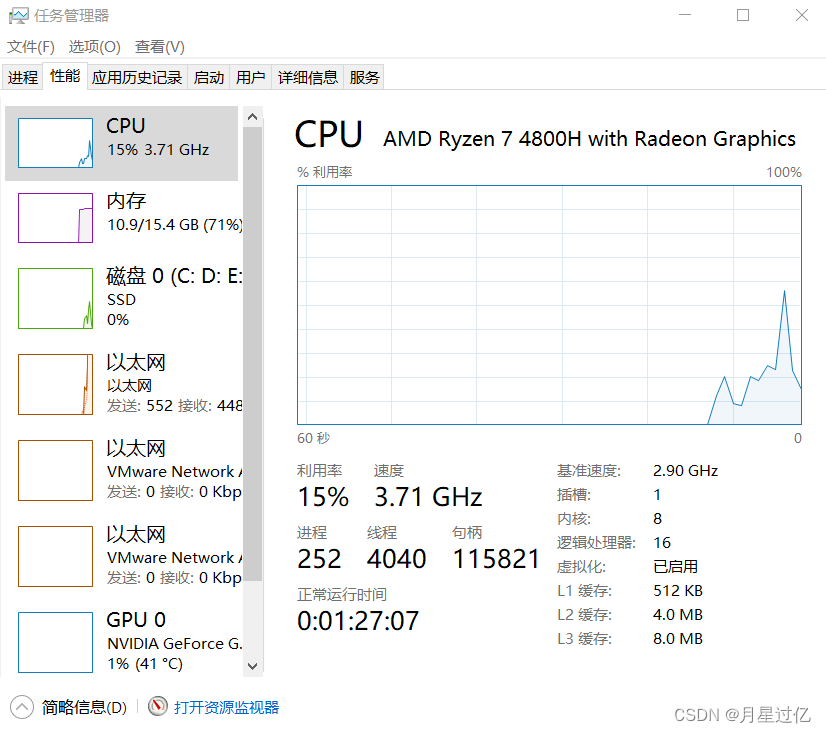
一、开启查看本地任务管理器是否开启虚拟化
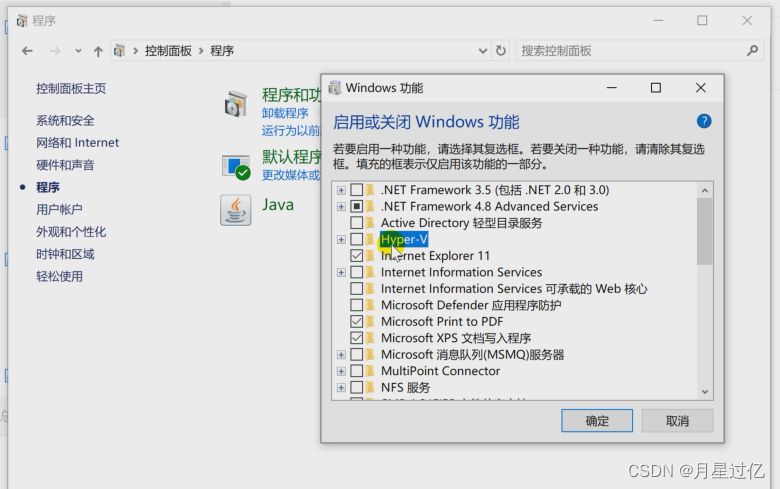
二、查看控制面板是否有Hyper-v 并关闭(会与vm虚拟化冲突)
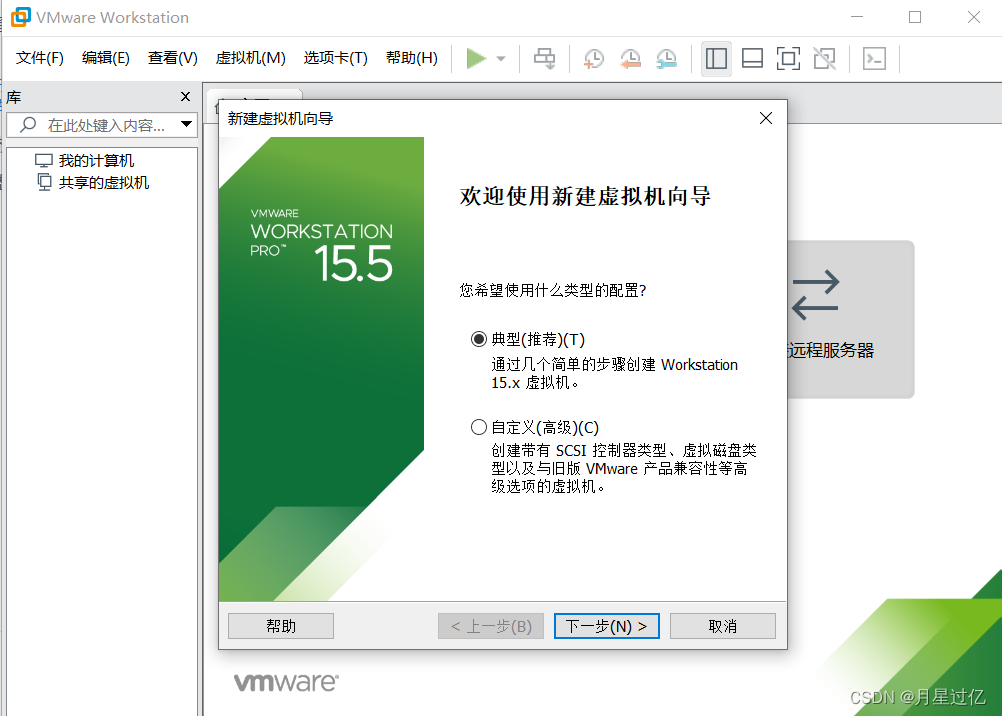
三、虚拟机安装
1.新建虚拟机
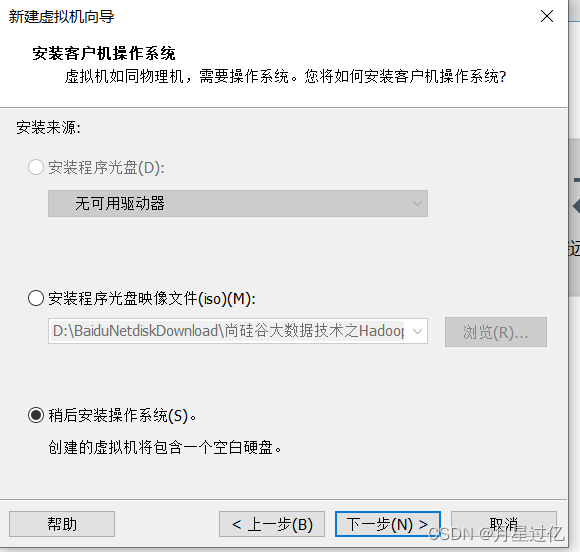

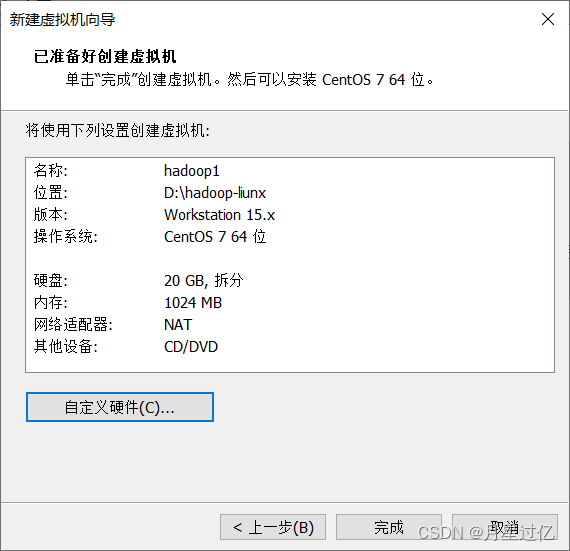
2、配置虚拟机
选择语言(chinese)
选择时区
3.命令行安装
设置root密码
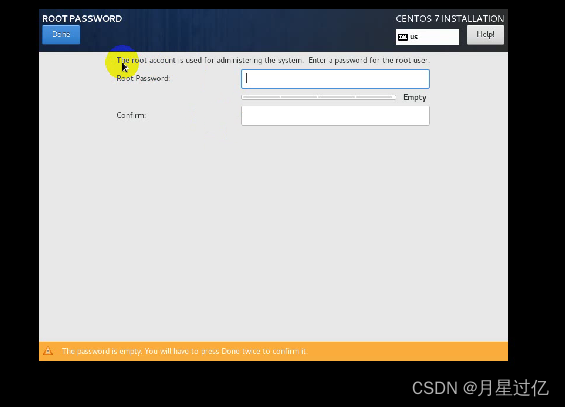
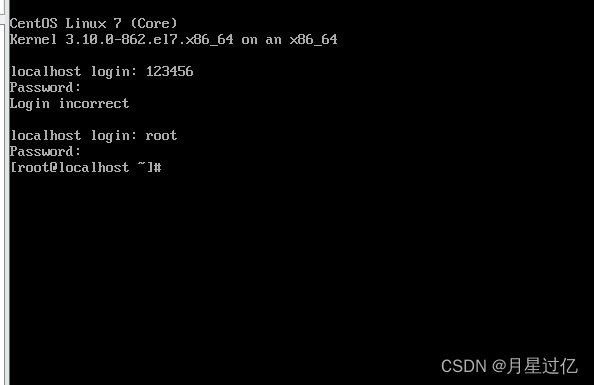
3、重启登录
四、常用虚拟机命令介绍
cd 路径 切换路径
ls:进行当前路径下,文件列表显示
ll:进行当前路径下,文件详细列表显示
ls -路径参数
-a 进行的是全部文件的查看
ll -路径参数
-a 进行的是全部文件的查看
etc 配置项 ,相关配置都在etc下
opt文件夹 用户文件夹存储位置
cd /路径 切换换到/下的某个路径中
cd 在当前的路劲下进行指定路径的切换
pwd 进行当前路径的查看
只能进行单层文件夹创建
mkdir 文件夹的名字 在当前路径下进行文件夹创建
mkdir /文件夹名 在指定目录下进行文件夹创建
多层级文件夹创建
mkdir -p 多层关系文件夹
mv 文件夹名字 要修改成什么名字
========>修改文件夹名字
移动文件夹 mv 文件夹名字 文件夹新的路径
移除文件夹 rm -r 文件夹名
文件创建:
touch 文件名 当前路径下进行文件创建
vi 文件名 :当前路进行进行文件创建
vi 文件名 :如果文件系统存在,
打开文件,进行文件内容查看
进行编辑模式,进行文件的书写 i a o进入到文件的编辑模式
进行文件内容书写
书写完毕,退出编辑模式 esc
:q不保存退出文件
:w保存文件
:wq 保存退出文件
vi 文件名:打开文件
如果文件在系统中不存在,提醒new file
========》当前文件不存在 esc :q 退出文件
查看文件内容: cat 文件名
文件复制 cp 文件名 路径下
文件夹复制 cp -r 原来文件夹名字 新文件夹位置
文件移除 rm 文件名 当前路径下文件的删除
五、虚拟机网络配置
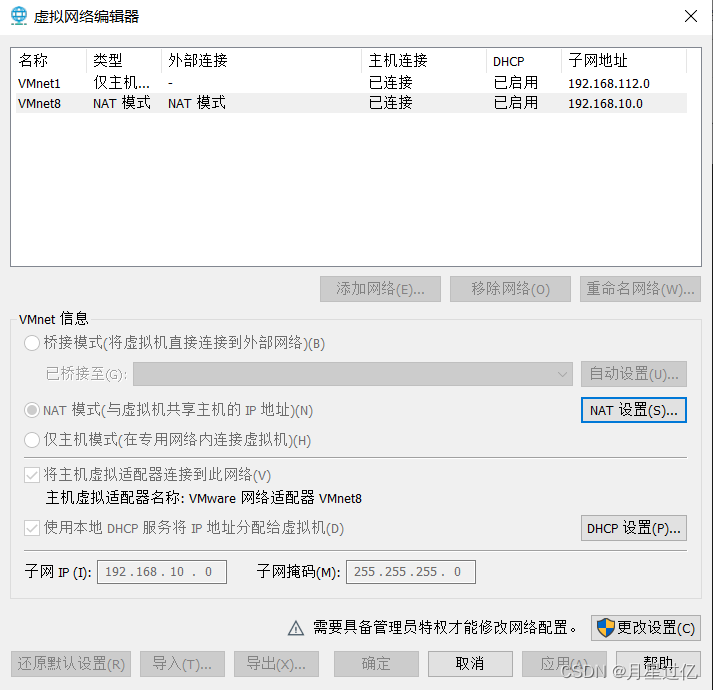
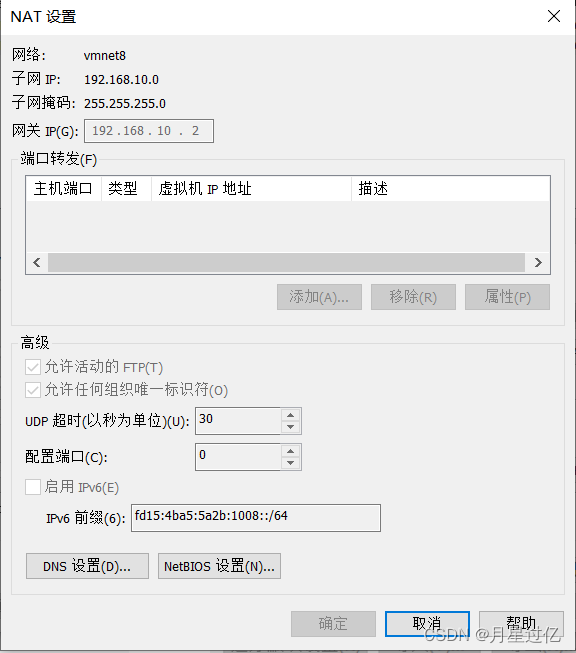
虚拟机配置
配置网络
所有配置etc下
/etc/sysconfig/network-scripts
有一个文件,ifcfg-ens32 进行网络配置
vi ifcfg-ens32
配置网络信息后,虚拟机上网
BOOTPROPO=static
ONBOOT=yes
IPADDR=192.168.10.150
NETMASK=255.255.255.0
GATEWAY=192.168.10.2
DNS1=114.114.114.114
配置网络,让网络服务生效
systemctl restart network
ping www.baidu.com 是否有回应,有回应网络已连接 +ctrl c 中断
六 hadoop环境安装
1.在虚拟机上进行java环境配置
1.获取到java-jdk文件
2.本机上传java-jdk到linux虚拟机
3进行安装
需要进行解压
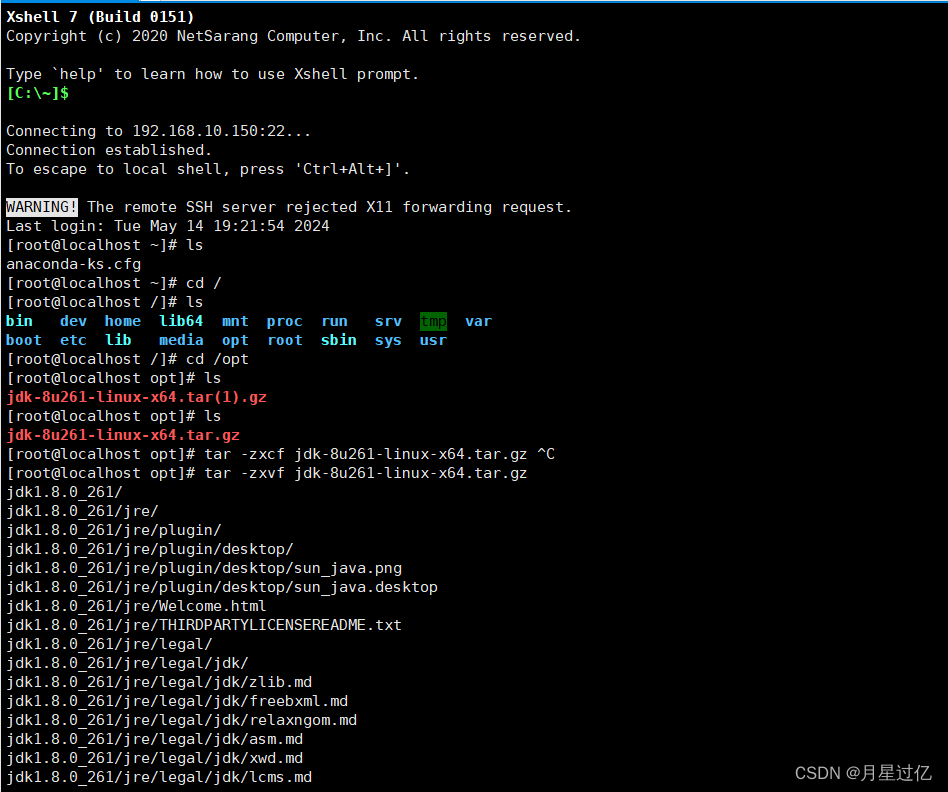
tar -zxvf 查看解压过程 压缩包
tar -xf 不查看解压过程 压缩包
tar -zxvf jdk-8u261-linux-x64.tar.gz //解压压缩包
mv jdk1.8.0_261/ jdk //给存放jdk的文件夹改名
- 配置环境变量
cd /etc
root@localhost etc# cd profile.d/
root@localhost profile.d# pwd
/etc/profile.d
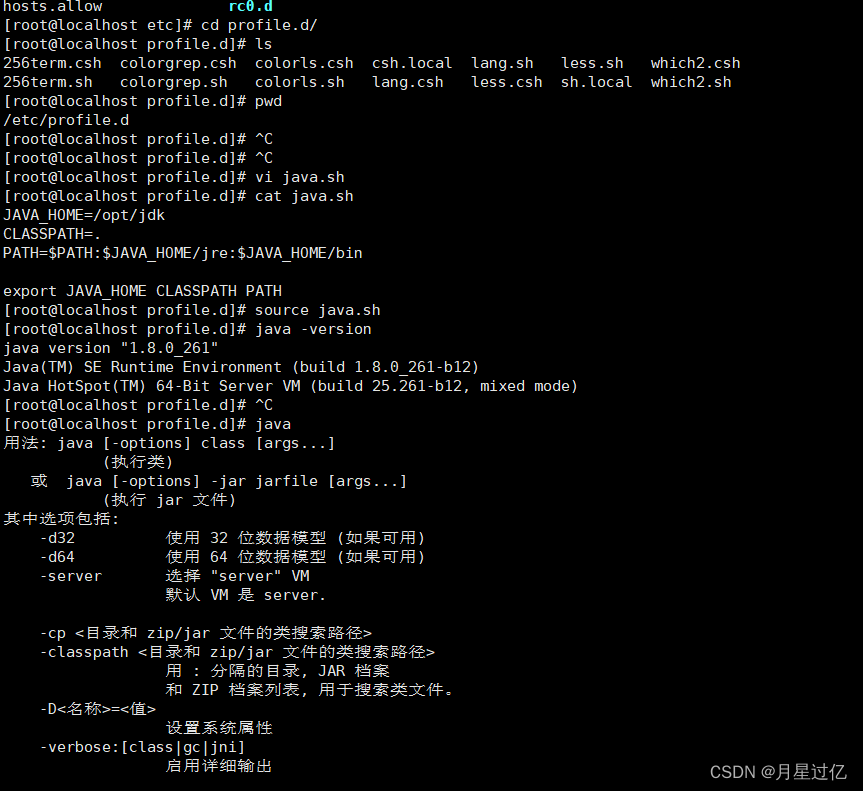
root@localhost profile.d# vi java.sh
JAVA_HOME=/opt/jdk
CLASSPATH=.
PATH=PATH:JAVA_HOME/jre:$JAVA_HOME/bin
export JAVA_HOME CLASSPATH PATH
root@localhost profile.d# source java.sh //使配置文件生效
root@localhost profile.d# java -version
2.安装hadoop
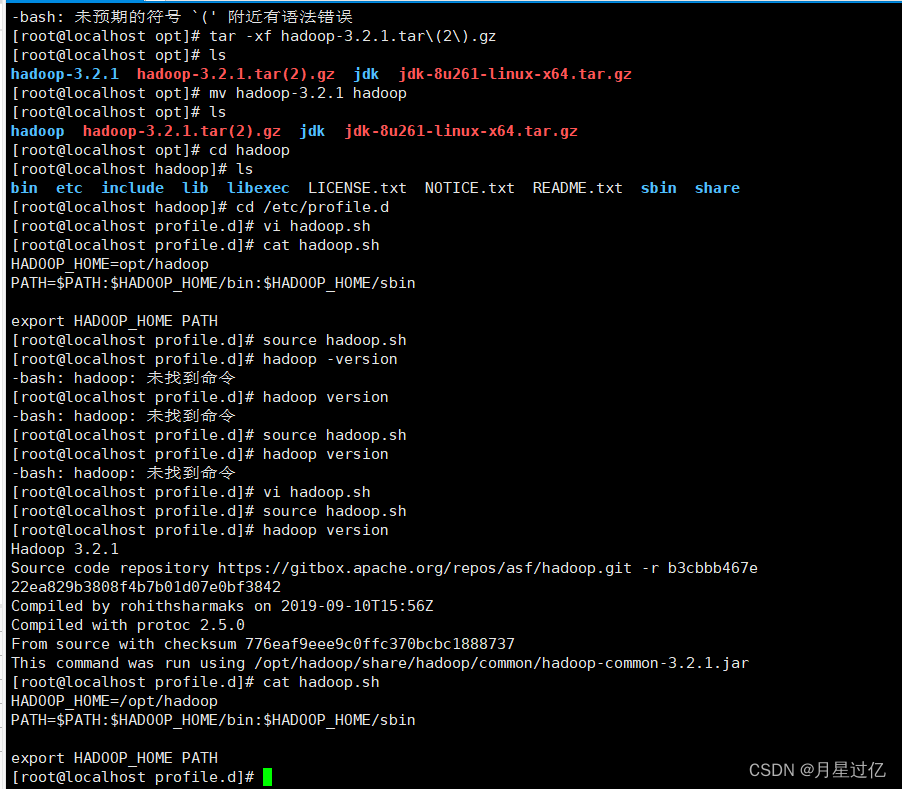
root@localhost opt# tar -xf hadoop-3.2.1.tar\(2\).gz
root@localhost opt# mv hadoop-3.2.1 hadoop
root@localhost hadoop# cd /etc/profile.d
root@localhost profile.d# vi hadoop.sh
HADOOP_HOME=/opt/hadoop
PATH=PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME PATH
root@localhost profile.d# source hadoop.sh
root@localhost profile.d# hadoop version
七、配置hdfs相关信息
hadoop:
核心内容
1.hdfs 进行分布式文件存储
通过hadoop进行大数据的操作
需要分析的数据,操作的数据,放到hdfs中进行存储
先把数据存储到hdfs中
2.mapreduce
进行数据的运算
3.yarn 资源调度 资源管理
mapreduce执行,进行资源分配
先存储数据到hdfs上,再进行mapreduce的运算(需要yarn进行资源分配)
1.core-site.xml配置
修改主机名 cd/etc
vi hosts
192.168.10.150 hadoop1
reboot //重启后生效

XML
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
</configuration>2.namenode格式化 hdfs namenode -format
2024-05-15 00:00:05,098 INFO common.Storage: Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted.
3. 进行hdfs存储文件时,相关文件的启动
hdfs相关的配置
启动namenode 和datanode
root@hadoop1 etc# cd /opt/hadoop
root@hadoop1 hadoop# ls
bin include libexec logs README.txt share
etc lib LICENSE.txt NOTICE.txt sbin
root@hadoop1 hadoop# cd sbin
root@hadoop1 sbin# ls
distribute-exclude.sh refresh-namenodes.sh start-yarn.cmd stop-secure-dns.sh
FederationStateStore start-all.cmd start-yarn.sh stop-yarn.cmd
hadoop-daemon.sh start-all.sh stop-all.cmd stop-yarn.sh
hadoop-daemons.sh start-balancer.sh stop-all.sh workers.sh
httpfs.sh start-dfs.cmd stop-balancer.sh yarn-daemon.sh
kms.sh start-dfs.sh stop-dfs.cmd yarn-daemons.sh
mr-jobhistory-daemon.sh start-secure-dns.sh stop-dfs.sh
root@hadoop1 sbin# ./hadoop-daemon.sh start namenode
WARNING: Use of this script to start HDFS daemons is deprecated.
WARNING: Attempting to execute replacement "hdfs --daemon start" instead.
root@hadoop1 sbin# jps
1476 NameNode
1495 Jps
root@hadoop1 sbin# ./hadoop-daemon.sh start datanode
WARNING: Use of this script to start HDFS daemons is deprecated.
WARNING: Attempting to execute replacement "hdfs --daemon start" instead.
root@hadoop1 sbin# jps
1476 NameNode
1637 Jps
1607 DataNode
root@hadoop1 sbin#
hdfs提供了一个接口,可以通过浏览器进行访问hdfs的访问
虚拟机,有自己的防火墙,进行保护
本机进行虚拟机上服务的访问,关闭防火墙,虚拟机上的服务才能访问
systemctl stop firewalld 关闭防火墙
概念:
namenode
名称节点,进行名字的存储
hdfs中存储的文件的名字的存储
datanode:
实际文件的存储
数据放到datanode中进行存储
修改hdfs-site.xml
XML
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/datas/dfs/names</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/datas/dfs/datas</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>生成密钥对
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys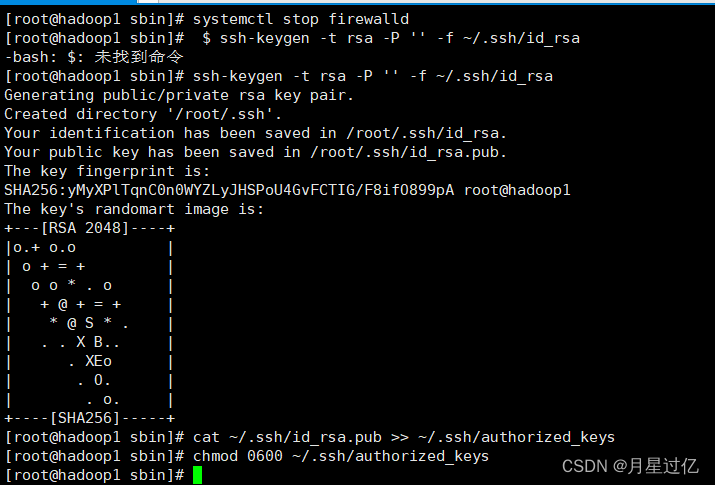
对以后进行分布式环境搭建,使用密钥对
vi start-dfs.sh
加入
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
八、hdfs常用命令
root@hadoop1 sbin# hdfs dfs -mkdir /a
root@hadoop1 sbin# hdfs dfs -mkdir -p /b/c/d
第二个路径不存在的改名
第二个路径存在的,进行移动
root@hadoop1 sbin# hdfs dfs -mv /a /test
root@hadoop1 sbin# hdfs dfs -mv /b/c/d /test