谁说强化学习只能是蛋糕上的樱桃,说不定,它也可以是整个蛋糕呢?

在 2016 年的一次演讲中,Yann LeCun 曾将强化学习比喻成蛋糕上的樱桃。他提到,「如果把智能比作一块蛋糕,那么无监督学习就是蛋糕的主体,监督学习就是蛋糕上的糖霜,而强化学习则是糖霜上的樱桃。我们已经知道如何制作糖霜和樱桃,但却不知道如何制作蛋糕本身。」

从 2016 年至今,LeCun 对强化学习一直不看好。然而,不可否认的是,强化学习在提升 AI 模型能力方面正变得越来越重要。而且,来自微软的一项新研究显示,它不仅在后训练阶段发挥着关键作用,甚至在预训练阶段也展现出巨大的潜力。

在这篇题为「Reinforcement Pre-Training」的论文中,作者提出了一种名为「强化预训练(RPT)」的新范式。在这种范式中,下一个 token 预测任务可以被重新定义为一个通过强化学习训练的推理任务。在这一任务中,模型会因正确预测给定上下文中的下一个 token 而获得可验证的奖励。

这就好比在制作蛋糕的过程中,直接将樱桃融入到蛋糕的主体结构中。


作者指出,RPT 范式的好处在于,它提供了一种可扩展的方法,能够利用海量文本数据进行通用强化学习,而无需依赖特定领域的标注答案。
通过激励模型进行下一个 token 的推理,RPT 显著提升了预测下一个 token 的语言建模准确性。此外,RPT 为后续的强化微调提供了一个强大的预训练基础。
scaling 曲线表明,随着训练计算量的增加,下一个 token 预测的准确性持续提升。这些结果表明,RPT 是一种有效且有前景的 scaling 范式,能够推动语言模型预训练的发展。
不过,由于论文提出的方法比较新,社区对该方法的有效性、效率、前景等还有所疑问。



接下来,我们看文章内容。
论文概览

-
论文标题:Reinforcement Pre-Training
大语言模型(LLMs)通过在海量文本语料库上采用可扩展的对下一个 token 的预测,展现出跨多种任务的卓越能力。这种自监督范式已被证明是一种高效的通用预训练方法。
与此同时,RL 已成为微调大语言模型的关键技术,既能让 LLM 符合人类偏好,又能提升诸如复杂推理等特定技能。
然而,目前 RL 在 LLM 训练中的应用面临着可扩展性和通用性方面的挑战。
一方面,基于人类反馈的强化学习虽然在对齐方面有效,但依赖于昂贵的人类偏好数据,而且其学习到的奖励模型容易受到 reward hacking 攻击,从而限制了其可扩展性。
另一方面,可验证奖励的强化学习 (RLVR) 利用客观的、基于规则的奖励,这些奖励通常来自问答对。虽然这可以缓解 reward hacking 攻击,但 RLVR 通常受限于数据的稀缺性,不能用于通用预训练。
本文提出了强化预训练(Reinforcement Pre-Training, RPT)这一新范式,旨在弥合可扩展的自监督预训练与强化学习能力之间的鸿沟。
RPT 将传统的对 next-token 的预测任务重构为对 next-token 的推理过程:对于预训练语料中的任意上下文,模型需在预测前对后续 Token 进行推理,并通过与语料真实的 next-token 比对获得可验证的内在奖励。
该方法无需外部标注或领域特定奖励函数,即可将传统用于 next-token 预测的海量无标注文本数据,转化为适用于通用强化学习的大规模训练资源。
这种方法提供了几个关键的优点。
首先,RPT 具有固有的可扩展性和通用性:该方法充分利用了传统 next-token 预测所使用的海量无标注文本数据,无需任何外部标注,即可将其转化为适用于通用强化学习的大规模训练数据集。
其次,使用直接的、基于规则的奖励信号本质上可以最大限度地降低 reward hacking 风险。
第三,通过明确奖励 next-token 推理范式,让模型能够进行更深入的理解和泛化,而不仅仅是记住下一个 Token。
最后,预训练期间的内部推理过程允许模型为每个预测步骤分配更多的思考(计算资源),这类似于将推理时间扩展能力提前应用到训练过程中,从而直接提升下一 Token 预测的准确性。
强化预训练(RPT)详解
Next-Token 预测与 Next-Token 推理对比如下。

在 Next-Token 推理范式下,长思维链可以包含各种推理模式,例如自我批评和自我修正。
Next-Token 推理将预训练语料库重构为一系列庞大的推理问题,使预训练不再局限于学习表面的 Token 级关联,而是理解其背后的隐藏知识。
RPT 通过 on-policy 强化学习的方式训练大语言模型执行 next-token 推理任务,如图 3 所示。

对于给定的上下文 ,提示语言模型
,提示语言模型 生成 G 个响应(思维轨迹)
生成 G 个响应(思维轨迹) 。每个响应
。每个响应 由一系列思维推理序列
由一系列思维推理序列 和最终预测序列
和最终预测序列  组成。
组成。
此外,为了验证的正确性,本文还引入了前缀匹配奖励(prefix matching reward)。
对于 的第 i 个输出的奖励
的第 i 个输出的奖励 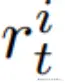 定义为:
定义为:

实验设置。本文使用 OmniMATH 数据集进行强化预训练,其包含 4,428 道竞赛级数学题目及答案。实验基础模型为 Deepseek-R1-Distill-Qwen-14B。
实验结果
语言建模能力
表 1 显示了 RPT 方法和基线方法在不同难度级别测试集上的下一个 token 预测准确性。结果显示,RPT 在与标准下一个 token 预测基线和基于推理的预测基线对比时均表现更优。
具体来说,与 R1-Distill-Qwen-14B 相比,RPT-14B 在所有难度级别上都具有更高的下一个 token 预测准确率。
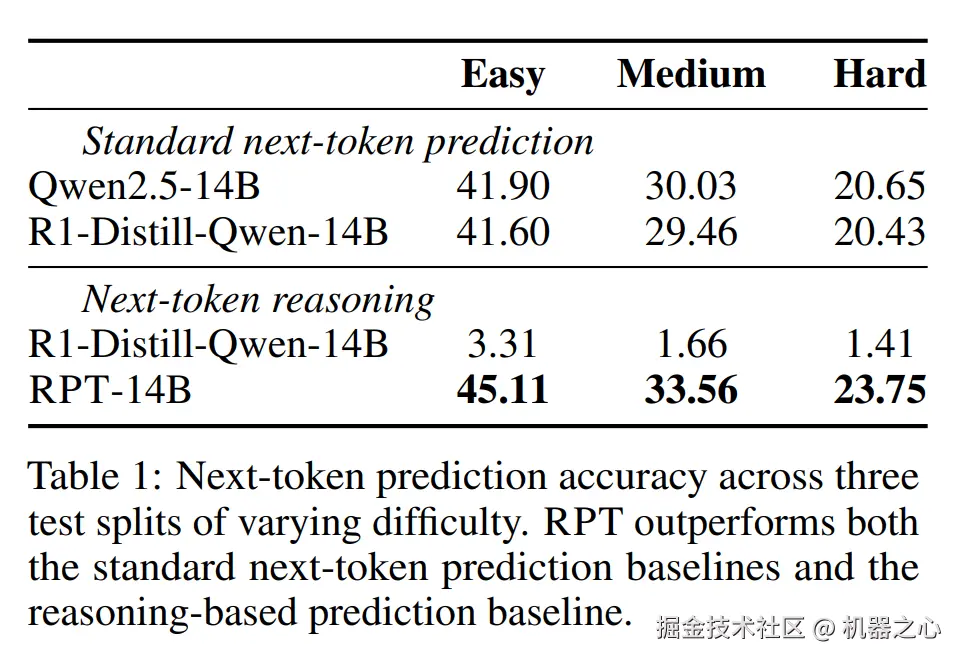
值得注意的是,它的性能与一个更大的模型的性能相媲美,即 R1-Distill-Qwen-32B(图 4)。这些结果表明,强化预训练在捕获 token 生成背后的复杂推理信号方面是有效的,并且在提高 LLM 的语言建模能力方面具有强大的潜力。

强化预训练的 scaling 特性
如图 5 所示,RPT 的下一个 token 预测准确率随着训练计算的扩大而可靠地提高。所有难度级别的高 R2 值表明拟合曲线准确地捕捉了性能趋势。

在 RPT 基础上进行强化微调
如表 2 所示,经过强化预训练的模型在进一步使用 RLVR 进行训练时能够达到更高的性能上限。当模型持续使用下一个 token 预测目标在相同数据上进行训练时,其推理能力显著下降。随后的 RLVR 训练仅能带来缓慢的性能提升。这些结果表明,在数据有限的情况下,强化预训练能够快速将从下一个 token 推理中学到的强化推理模式迁移到下游任务中。

零样本性能
如表 3 所示,RPT-14B 在所有基准测试中始终优于 R1-Distill-Qwen-14B。值得注意的是,RPT-14B 在 next-token 预测方面也超越了规模更大得多的 R1-Distill-Qwen-32B。

Next-Token 推理模式分析
如图 6 所示,RPT-14B 的 next-token 推理过程与 R1-Distill-Qwen-14B 的问题解决过程明显不同。表明 next-token 推理引发的推理过程与结构化问题解决存在质的差异。

最后,本文还在表 4 中提供了一个推理模式的示例。他们表明,RPT-14B 参与的是深思熟虑的过程,而非简单的模式匹配。
