0. 概述
上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分,导出模型分为 convert_checkpoint.py (quantize.py) 和 trtllm-build 两个过程。
tip
有些较新的模型不支持这个流程了,比如 DeepSeek-R1 等,需使用 pytorch backend 那套。1. convert_checkpoint.py
首先确定待转换模型的类型,然后在 examples/models 下面找到对应使用的脚本。本文使用 Qwen2.5-0.5B-Instruct,对应脚本文件是 examples/models/core/qwen/convert_checkpoint.py。
前文 提到,在 convert_checkpoint.py 这个过程主要是确定权重的拆分和计算方式,以及实际采用的量化方式,所以参数主要也是分为这两部分。
1.1 权重的拆分和计算
按照不同的切分方式,将模型权重以某种方式将其加载后放置到不同卡上,使得较大模型也能在多张较小显存的卡上运行。在实际运行时,某张卡仅负责部分权重的加载和运行,然后在需要整体数据时归约各卡的计算结果。
1.1.1 tp_size
将权重按照设置的 tp_size 值切分并加载到不同卡上,每张卡上保存全部激活值。当需要全局信息如计算自注意力的时候,首先将各卡结果归约。在实际设置时,tp_size 必须能整除 num_attention_heads 和 num_kv_heads 等这种维度划分的纬度值。
1.1.2 pp_size
将模型按照层切分到不同卡上,注意 tp_size*pp_size 的值不超过总卡数。
1.1.3 cp_size
暂时跳过,tp_size pp_size 和 cp_size 可以任意组合设置。
1.1.4 moe_tp_size
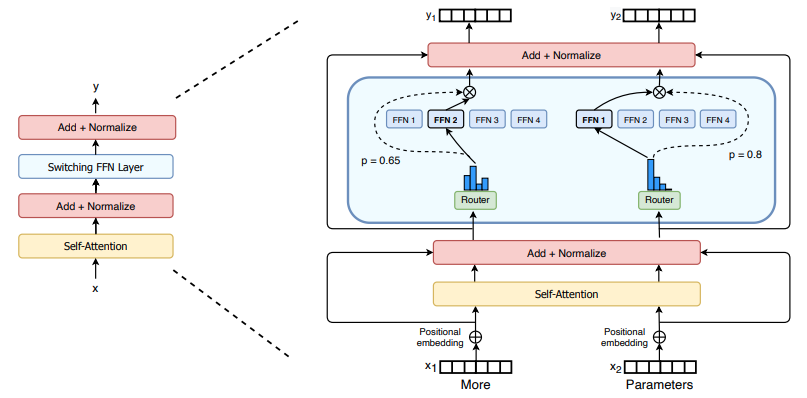
moe 和集成学习类似,通过多个模型来解决同一个问题,并且将它们的结果整合。如上图,论文 使用稀疏的 moe 块替换稠密的 FFN 层,图中每一个子 FFN 模块称为一个专家,整体还包含一个门控模块。在实际运行时,输入首先过一个门控网络,门控模块输出 softmax 的概率结果来确定输出应该路由到哪些专家并参与运算,同时通过 --moe_top_k 参数来控制参数运算的专家数。
--moe_tp_size 对 moe 模块使用 tp,默认值等于 tp_size 的值。
1.1.5 moe_ep_size
对于 moe 模块,将不同的专家放到不同的卡上,可以和 moe_tp_size 组合使用,默认值是 1,该值必须能够整除专家数。
1.1.6 示例
如设置 tp_size=4 pp_size=2:
shell
python examples/models/core/qwen/convert_checkpoint.py \
--model_dir Qwen2.5-0.5B-Instruct \
--tp_size 4 \
--pp_size 2 \
--output_dir Qwen2.5-0.5B-Instruct-pp2-tp4 1.2 量化
量化将权重或激活值从浮点类型转换为另一数值类型,一方面是最快降低模型推理显存占用的方案,另一方面在某些场景下也快于原浮点精度推理。比如,fp16 的 70b 模型需要大约 140G 的显存来存放权重。而如果将其权重量化为 int4 类型,则仅需要约 35G。对于量化,需要处理的是数值范围改变后带来的模型精度降低,从而可能导致模型产生不合理输出的情况。对于 TensorRT-LLM,量化主要针对权重、激活值和 kv cache 这三部分。
1.2.1 weight_only_quantization
权重量化,配合 --weight_only_precision 为 int8 int4 或者 int4_gptq 设置不同的权重量化方法。
int8 和 int4 是基础的量化方法,没有校准。在量化时,一般采用 per_channel 的方式。int4_gptq 是一种更细粒度的量化方法,将通道按照如默认的 128 划分 group,划分部分共用一个缩放系数,可通过 --group_size 设置 group 大小。
1.2.2 smoothquant
既量化权重也量化激活值,论文。大体思想是:由于权重量化相对于激活值量化,更能保证模型的精度(可以参考原论文的相关实验),因此引入一个平滑因子来将量化难度从激活转移到权重上。对于矩阵乘法:
Y = X ⋅ W Y=X\cdot W Y=X⋅W
可变换为:
Y = ( X ⋅ d i a g ( s ) − 1 ) ⋅ ( d i a g ( s ) ⋅ W ) Y=\left(X\cdot{\rm diag(s)}^{-1}\right)\cdot \left({\rm diag(s)}\cdot W\right) Y=(X⋅diag(s)−1)⋅(diag(s)⋅W)
其中,激活值右乘对角矩阵相当于对矩阵按列缩放,权重值左乘对角矩阵相当于对矩阵按行缩放(大学线代知识)。为实现量化难度从激活值转移到权重上,论文将上述变换的参数定义为:
s j = m a x ( ∣ X j ∣ ) α / m a x ( ∣ W j ∣ ) 1 − α {\rm s}_j={\rm max}\left(|X_j|\right)^{\alpha}/{\rm max}\left(|W_j|\right)^{1-\alpha} sj=max(∣Xj∣)α/max(∣Wj∣)1−α
其中 α \alpha α 是定义的超参数,范围是 0 到 1(推荐从 0.5 开始尝试),且论文有取值的消融实验。这样,我们可以先通过数据集离线计算 s {\rm s} s 的值,然后在推理时将该值作用到激活值和权重。在指定 --smoothquant 或 -sq 后会启用默认数据集 ccdv/cnn_dailymail,或使用 --calib_dataset 指定的数据集。
默认情况下,--smoothquant 会采用 per-tensor 的模式,即每个矩阵共用一个缩放系数。TensorRT-LLM 提供了 --per-token 和 --per-channel 的任意组合来分别确定激活值和权重的缩放方式。
1.2.3 int8_kv_cache
使用 int8 类型来存放 KV Cache 值,通过 --int8_kv_cache 指定。
1.2.4 示例
使用 int8 weight only 的量化:
shell
python examples/models/core/qwen/convert_checkpoint.py \
--model_dir Qwen2.5-0.5B-Instruct \
--use_weight_only \
--weight_only_precision int8 \
--output_dir Qwen2.5-0.5B-Instruct-int82. quantize.py
更多量化方法在 quantize.py 中指定,其中也有 tp_size 等选项。在 quantize.py 中提供了 --qformat 选项指定量化方式,包括:
| 量化方式 | 说明 |
|---|---|
| nvfp4 | Blackwell 架构,如 B 卡上的数据格式,没有设备没试过 |
| fp8 | Hopper 架构,如 H 卡上的数据格式 |
| int8_sq | int8 smoothquant |
| int4_awq | 和 gptq 类似,awq 保留部分权重的原始数据类型 |
| w4a8_awq | 和上一个参数一样,配合 --awq_block_size 设置 block 大小 |
| int8_wo | int8 weight only 量化 |
| int4_wo | int4 weight only 量化 |
| full_prec | 不量化 |
--kv_cache_dtype 可以设置 int8 或 fp8 来指定 kv cache 的数据类型。此外,为了实现混合精度,如 MLP 量化为 int4,其余部分为 int8。可通过 json 文件(命名为 quant_cfg.json)为模型不同部分设置不同精度:
json
{
"quant_algo": "MIXED_PRECISION",
"kv_cache_quant_algo": "FP8",
"quantized_layers": {
"transformer.layers.0.attention.qkv": {
"quant_algo": "FP8"
},
"transformer.layers.0.attention.dense": {
"quant_algo": "FP8"
},
"transformer.layers.0.mlp.fc": {
"quant_algo": "W4A16_AWQ",
"group_size": 128,
"has_zero_point": false,
"pre_quant_scale": true
},
"transformer.layers.0.mlp.proj": {
"quant_algo": "W8A8_SQ_PER_CHANNEL"
},
...
"transformer.layers.31.mlp.proj": {
"quant_algo": "FP8"
}
}
}3. trtllm-build
trtllm-build 输入是上面 convert_checkpoint.py 的输出目录,这里只列出常见的选项,没用过的暂时不列举了。
3.1 基本选项
3.1.1 长度相关
max_batch_size max_input_len max_seq_len 和 max_num_tokens 这几个配合使用,参考 说明。总的来说,由于 TensorRT 的静态特性,将 max_batch_size max_input_len 和 max_seq_len 设置得足够大以满足场景需求,然后控制 max_num_tokens 的值。如果 max_num_tokens 值太大,在 build 阶段的 warmup 等过程会提前暴露出如 oom 等错误。
3.1.2 max_beam_width
beam search 的返回结果数量,用于需产生多样化输出的场景。
3.1.3 kv_cache_type
kv cache 的存储和调度方式,默认为 paged kv cache。
3.2 logits 处理
如果需要收集 prefill 阶段(--gather_context_logits)和 decode (--gather_generation_logits) 阶段的 logits,或者都需要(--gather_all_token_logits),则需开启对应选项。
3.3 lora 相关
没用过,暂时跳过。
3.4 speculative decoding
没用过,暂时跳过。
3.5 plugin 相关
当 --remove_input_padding 开启时,不同输入组成一个一维向量,连同各输入长度送入模型。否则,对于不同输入,较短的输入会被填充到最大长度,这会带来额外的空间和计算浪费。
选项 --tokens_per_block 用在 paged kv cache 中,用于设置每个 block 的大小,默认为 32。
选项 --use_paged_context_fmha 可开启 kv cache 复用,以及 context chunking 功能(将长上下文分段 prefill)。
其他一些默认开启的设置,没有怎么设置用过。
4. run.py
导出模型后,可使用 run.py 快速验证和运行,如 tp_size*pp_size 等于 4:
shell
mpirun -n 4 run.py --max_output_len 128 --input_text "What is AI?"5. 总结
本文主要记录了原 tensorrt backend 的模型导出部分,后续可能用得也不多了,做个备份,还有其他内容可以想起来的时候补充。