分布式ID实现方案概述
在复杂的分布式项目中,往往需要对大量的数据或消息进行唯一标识,分布式ID能快速唯一的定位一条消息或数据。分布式ID实现方案有很多,下面简要介绍和比较几种实现方式:
1、依赖数据库自增生成:利用MySQL的自增列或Oracle的序列等功能。缺点:在分布式分库分表场景下无法保证ID全局唯一。
2、时间戳:ID采用时间戳生成。缺点:在高并发多实例服务场景下(相同的毫秒数生成的ID一样)无法保证ID全局唯一。
3、UUID:能保证在高并发多实例服务场景下ID全局唯一。缺点:空间占用多、生成的是无序的字符串,数据库索引效率低。
4、雪花算法:由Twitter设计的分布式ID生成算法,用于生成全局唯一且趋势递增的64位整数ID。它的64位ID由以下部分构成:
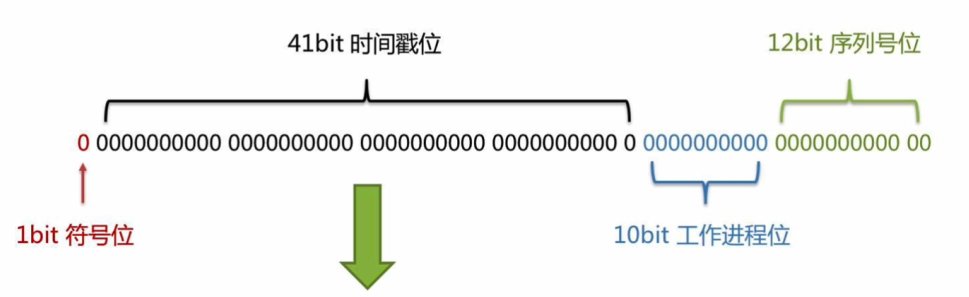
1)、符号位(1位):固定为0,保证ID为正数;
2)、时间戳(41位):记录当前时间与起始时间的毫秒差,支持约69年(从2010年计算);
3)、机器ID(10位):包含5位数据中心ID和5位机器ID,最多支持1024个节点;
4)、序列号(12位):同一毫秒内自增,每节点每毫秒最多生成4096个ID。
美团Leaf实现雪花算法
实现雪花算法的方案有很多,国内的滴滴Tinyid、百度UidGenerator、美团Leaf都有实现,本文重点阐述美团Leaf实现雪花算法方案及用法。
Leaf算法优势如下:
全局唯一性:Leaf算法通过合理的时间戳、数据中心ID、机器ID和序列号组合,确保每个生成的ID都是全局唯一的。
有序性:由于Leaf算法使用时间戳作为ID的一部分,因此生成的ID具有全局有序性,这对于一些需要按照时间顺序处理数据的场景非常有用。
可读性强:Leaf算法生成的ID采用十进制或十六进制表示,易于阅读和理解。
灵活性高:Leaf算法允许用户根据实际需求自定义数据中心ID和机器ID的位数和范围,具有很高的灵活性。
Leaf-snowflake沿用了Twitter的snowflake的设计,ID组成结构:正数位(占1比特)+ 时间戳(占41比特)+ 机器ID(占5比特)+ 机房ID(占5比特)+ 自增值(占12比特),总共64比特组成的一个Long类型。
Leaf-snowflake不同于原始snowflake算法地方,主要是在workId的生成上,Leaf-snowflake依靠Zookeeper生成workId,也就是上边的机器ID(占5比特)+ 机房ID(占5比特)。Leaf中workId是基于ZooKeeper的顺序Id来生成的,每个应用在使用Leaf-snowflake时,启动时都会都在Zookeeper中生成一个顺序Id,相当于一台机器对应一个顺序节点,也就是一个workId。
Leaf-snowflake使用步骤如下:
1、下载leaf源码 git clone git@github.com:Meituan-Dianping/Leaf.git
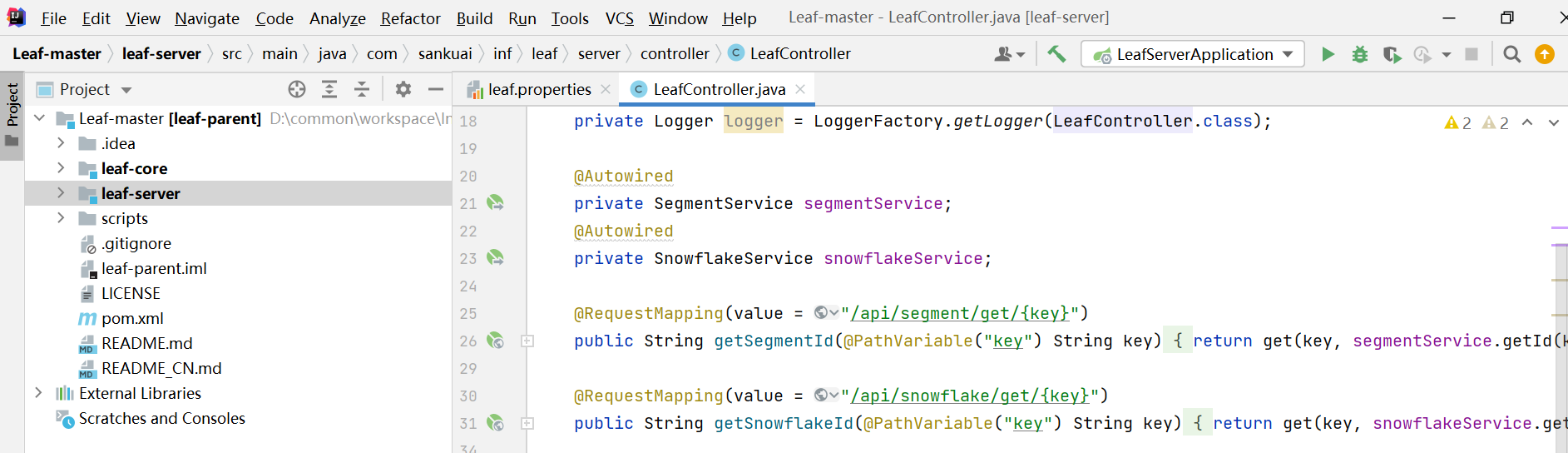
2、启动zookeeper

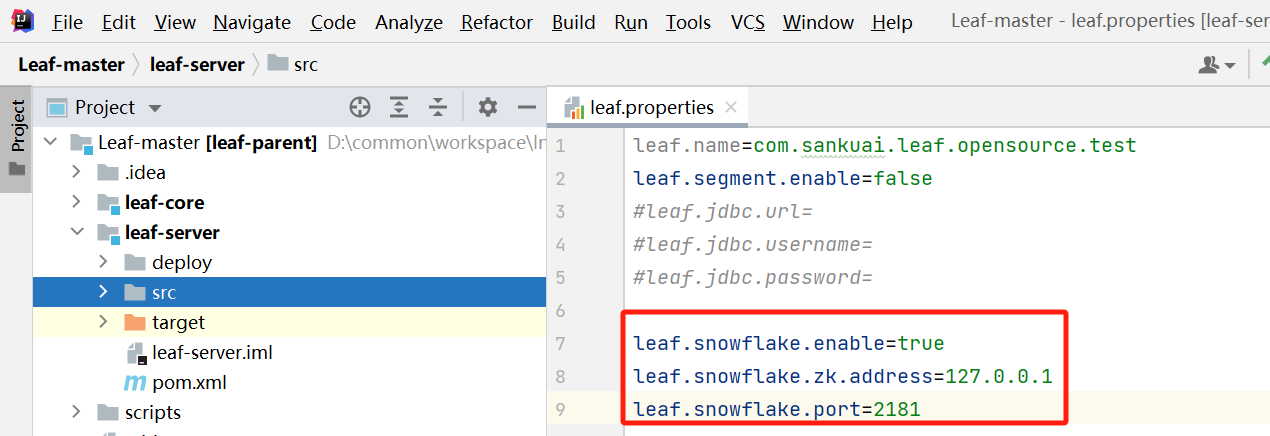
3、修改leaf.properties,添加zookeeper配置(leaf号段模式生成ID本文不介绍)
4、启动项目LeafServerApplication测试生成的ID
leaf-server启动实例,端口9999,观察zookeeper节点
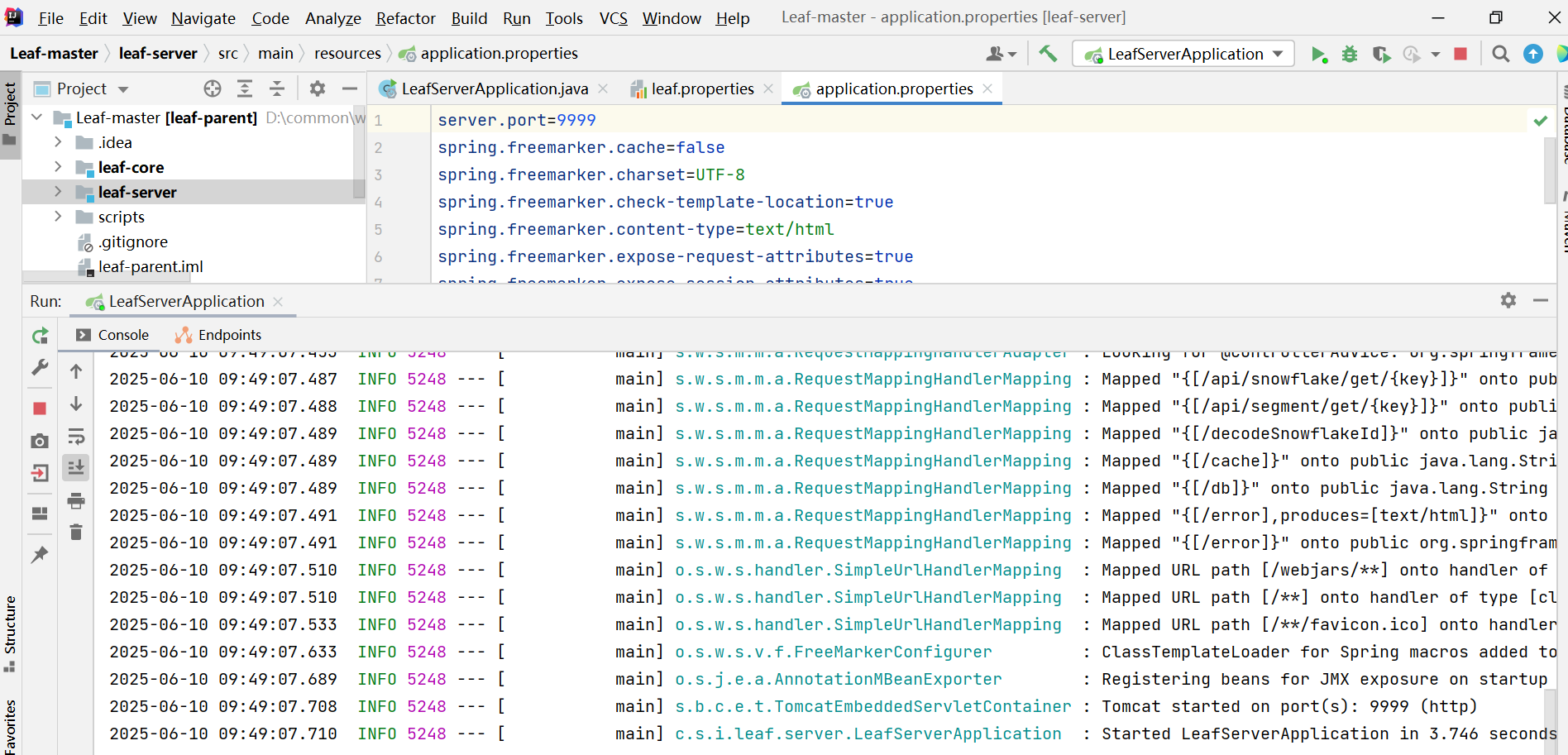

请求接口:http://localhost:9999//api/snowflake/get/gingko
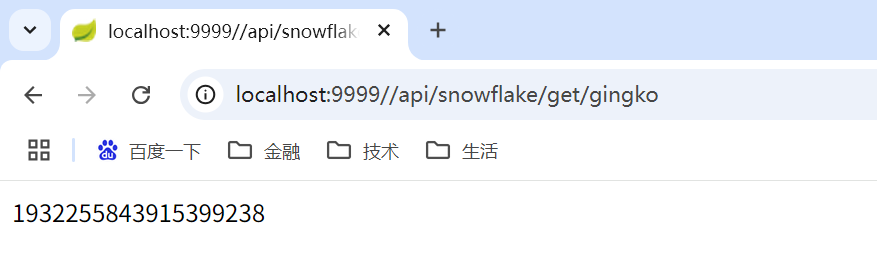
观察发现生成的ID有序且唯一,符合预期。
实际项目中,部署架构图如下:
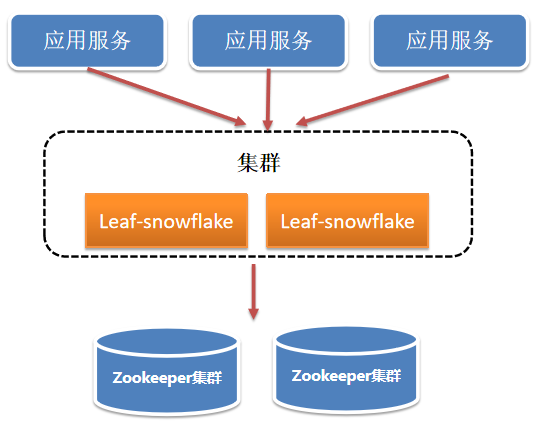
每个应用从leaf-snowflake集群中获取分布式ID,每个leaf-snowflake 服务在zookeeper中/snowflake/com.sankuai.leaf.opensource.test/forever 是顺序节点,类似192.168.110.68:2181-0000000000 、192.168.110.68:2181-0000000001、192.168.110.68:2181-0000000002...