编译原理
将高级编程语言编写的源代码转换成机器可执行的代码(二进制或汇编代码)
核心任务:
词法分析(正则表达式和有限自动机):
示例Token分类:
关键字:if, while
运算符:+, =
标识符:变量名分解源代码为单词 识别 其中关键字 变量名 运算符 等
语法分析(上下文无关文法CFG):
示例CFG规则:
E → E + T | T
T → T * F | F
F → (E) | id根据语法规则 构建抽象语法树(AST) 检查程序结构 是否正确
语义分析(语法制导翻译):
验证类型匹配,变量声明等语义规则
代码优化(数据流分析):
删除冗余代码、循环优化等技术提升程序性能。
目标代码生成:
优化过后转换成二进制或者汇编
应用场景:
编译器开发(GCC.LLVM等工具链实现)
静态分析工具(检测代码风格和漏洞 如:ESLint)
领域特定语言(DSL快速构建小型语言的处理工具)
使用现有的工具和库(如:Lex/Yacc/Bison/Flex)实践编译器开发
Windows环境安装工具flex bison
CMD管理员输入以下代码
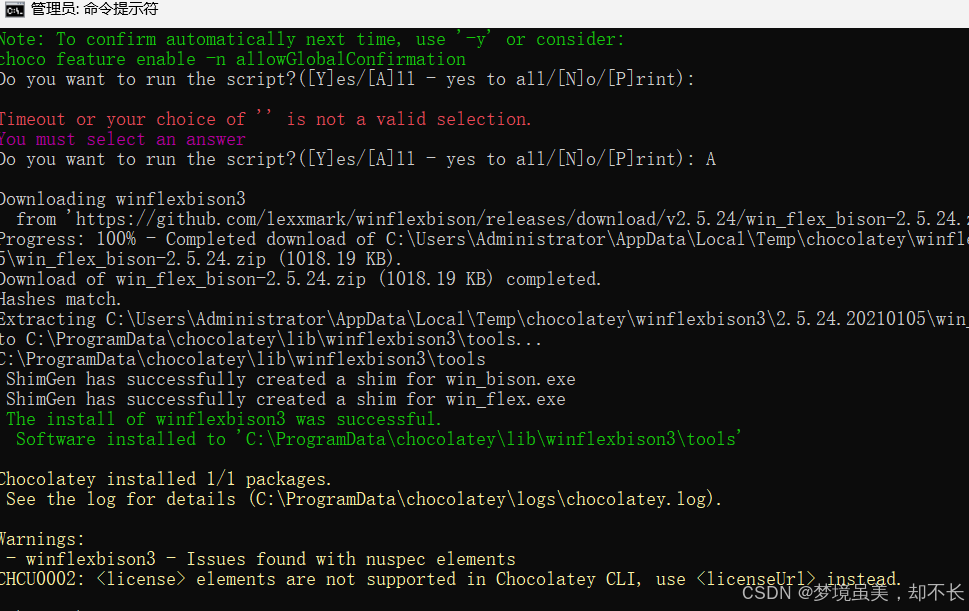
choco install winflexbison3当出现
Do you want to run the script?([Y]es/[A]ll - yes to all/[N]o/[P]rint):回复A 运行所有脚本
如果遇到运行问题可把以下地址添加到PATH(环境变量)) 默认路径为 C:\Program Files (x86)\WinFlexBison ``主要下图信息输出 比如说我的电脑 安装位置就为
C:\ProgramData\chocolatey\lib\winflexbison3\tools
检测是否安装成功
win_flex --version
win_bison --version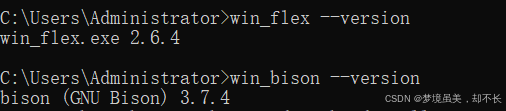
实战项目AI:实现一个简单的计算器(支持加减乘除)
编写 calc.l(Flex 文件)
%{
#include "y.tab.h" // 包含 Yacc/Bison 生成的头文件,用于 token 类型定义
// 文件名可能是 y.tab.h 或 calc.tab.h,取决于 Yacc/Bison 文件配置
%}
%option noyywrap // 禁用 yywrap 函数,简化 Lex 程序
%%
// 模式匹配规则部分
[0-9]+ { yylval = atoi(yytext); return NUMBER; } // 匹配数字并转换为整数
"+" { return ADD; } // 匹配加号运算符
"-" { return SUB; } // 匹配减号运算符
"*" { return MUL; } // 匹配乘号运算符
"/" { return DIV; } // 匹配除号运算符
"(" { return LPAREN; } // 匹配左括号
")" { return RPAREN; } // 匹配右括号
[ \t\n] ; // 忽略空格、制表符和换行符
. { printf("未知字符: %s\n", yytext); } // 处理其他未定义字符
%%
// 用户代码部分(此处为空)编写 calc.y(Bison 文件)
%{
#include <stdio.h>
#include <stdlib.h>
extern int yylex(); // 声明词法分析器函数
extern FILE *yyin; // 输入文件指针
void yyerror(const char *msg) { // 错误处理函数
fprintf(stderr, "Error: %s\n", msg);
}
%}
%token ADD SUB MUL DIV LPAREN RPAREN NUMBER // 定义token类型
%left '+' '-' // 定义运算符优先级和结合性
%left '*' '/' // 乘法除法优先级高于加减法
%%
input: // 输入规则
/* 空输入 */
| input line // 多行输入处理
;
line: // 行处理规则
'\n' // 空行
| expr '\n' { printf("= %d\n", $1); } // 表达式行,输出计算结果
;
expr: // 表达式规则
NUMBER { $$ = $1; } // 数字直接返回
| expr '+' expr { $$ = $1 + $3; } // 加法运算
| expr '-' expr { $$ = $1 - $3; } // 减法运算
| expr '*' expr { $$ = $1 * $3; } // 乘法运算
| expr '/' expr { if ($3 == 0) yyerror("Division by zero"); else $$ = $1 / $3; } // 除法运算,检查除零错误
| '(' expr ')' { $$ = $2; } // 括号表达式
;
%%
主程序部分
int main(int argc, char **argv) {
if (argc > 1) { // 如果有命令行参数
yyin = fopen(argv[1], "r"); // 打开文件作为输入
} else {
yyin = stdin; // 否则使用标准输入
}
// 启用 Bison 调试模式
yydebug = 1;
yyparse(); // 调用语法分析器
return 0;
}
Windows安装的工具需要在原代码调用的前提上添加 win_ 这样才会识别
下图是因为编译时被安全软件拦截生成的提示

1.生成 .c 文件
//修改前 以下代码 Windows 环境不会识别
flex calc.l # 生成 calc.yy.c
bison -dy calc.y # 生成 calc.tab.c 和 calc.tab.h
//修改后 正常生成,如果出现还是不识别 返回文章前面寻找路径添加到 环境变量
win_flex calc.l
win_bison -dy calc.y
- yylex():由词法分析器提供,负责返回词法单元。
- yyerror():用户需实现的错误处理函数
- yylval/yylloc:用于传递词法单元的属性和位置信息。
yyparse()是由语法分析器生成工具(如 Bison 或 Yacc)自动生成的函数,用于执行语法分析过程。它通常与词法分析器(如 Lex 或 Flex 生成的yylex())配合使用,构成编译器或解释器的核心部分。
可以看到生成了三个文件
lex.yy.c(由 Flex 生成)y.tab.c(由 Bison 生成)y.tab.h(定义 token)

2.编译链接
gcc lex.yy.c y.tab.c -o calc //正常链接
gcc lex.yy.c y.tab.c -DYYDEBUG=1 -o calc //打开调试开关的链接
//lex.yy.c:由Lex(或Flex)生成的词法分析器源代码,负责将输入字符流分解为标记(tokens)。
//y.tab.c:由Yacc(或Bison)生成的语法分析器源代码,包含语法规则和语义动作,通常依赖词法分析器的输出。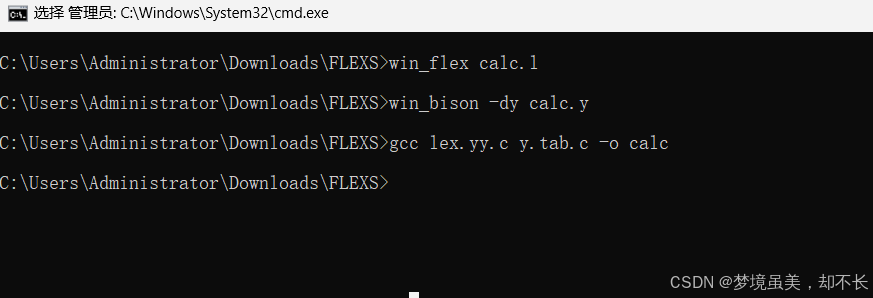
可以看到生成了一个exe程序

点击运行并输入算式:
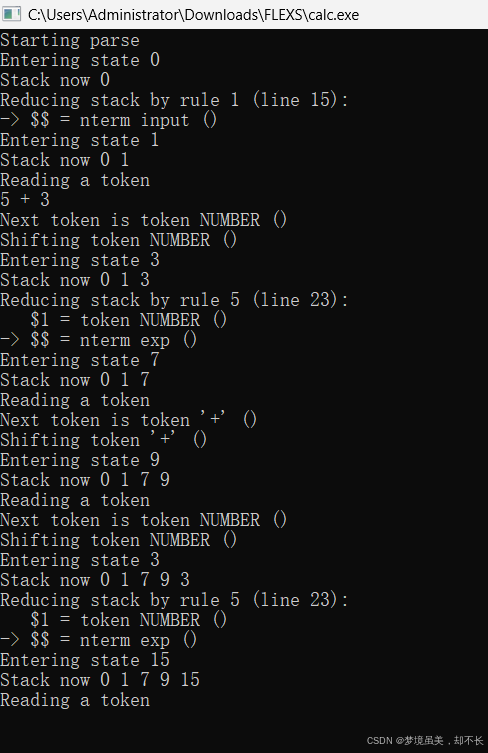
Starting parse // 开始语法分析(调用 yyparse())
Entering state 0 // 进入状态 0(初始状态)
Stack now 0 // 当前状态栈:[0]
Reducing stack by rule 1 (line 15): // 根据规则 1 归约(对应 input 规则)
-> $$ = nterm input () // 将 input 规约为一个非终结符(空输入)
Entering state 1 // 状态变为 1
Stack now 0 1 // 状态栈更新为 [0, 1]
Reading a token // 开始读取第一个 token
5 + 3 // 用户输入内容(注意这行是你手动或从文件输入的内容)
Next token is token NUMBER () // 下一个 token 是 NUMBER(数字 5)
Shifting token NUMBER () // 将该 token 移入栈中
Entering state 3 // 进入状态 3
Stack now 0 1 3 // 状态栈变为 [0, 1, 3]
Reducing stack by rule 5 (line 23): // 根据规则 5 归约(exp: NUMBER)
$1 = token NUMBER () // 使用 NUMBER 值(即 5)构造 exp
-> $$ = nterm exp () // 将 NUMBER 归约为 exp(表达式)
Entering state 7 // 进入状态 7
Stack now 0 1 7 // 状态栈变为 [0, 1, 7]
Reading a token // 继续读取下一个 token
Next token is token '+' () // 下一个 token 是 '+'(加号)
Shifting token '+' () // 将 '+' 移入栈中
Entering state 9 // 进入状态 9
Stack now 0 1 7 9 // 状态栈变为 [0, 1, 7, 9]
Reading a token // 继续读取下一个 token
Next token is token NUMBER ()
// 下一个读取到的 token 是 NUMBER(即数字 "3")
Shifting token NUMBER ()
// 将这个 token(数字 3)移入解析栈中
Entering state 3
// 当前状态变为 3(通常是处理 NUMBER 的状态)
Stack now 0 1 7 9 3
// 当前解析栈的状态序列:[0, 1, 7, 9, 3]
// 表示当前处于状态 3,前面是状态 0 → 1 → 7 → 9 → 3
Reducing stack by rule 5 (line 23):
// 根据语法规则第 5 条进行归约(对应 exp: NUMBER)
$1 = token NUMBER ()
// 使用当前 token 的值(即 3)作为规则中的第一个操作数
-> $$ = nterm exp ()
// 将 NUMBER 归约为非终结符 exp(表达式)
// 即:把数字 3 看作是一个"表达式"exp
Entering state 15
// 归约完成后进入新状态 15(通常是由 exp '+' exp 后匹配到新的 exp)
Stack now 0 1 7 9 15
// 当前状态栈更新为 [0, 1, 7, 9, 15]
Reading a token
// 准备读取下一个 token(输入结束或换行)