本教程适用于零基础 、一台刚装好 Windows 的全新电脑 开始,搭建能运行 Spark + Scala + IntelliJ 项目的开发环境。以下是超详细、小白级别逐步教程,从"下载什么"到"点击哪里"都帮你列清楚。
🎯 目标
- 操作系统:Windows10/11
- 工具:openJDK、Scala、Spark、sbt、IntelliJ IDEA、winutils
- 最终效果:在 IntelliJ 中运行你上传的 Spark 程序(Explore.scala)
🧰 一、安装开发工具(5 步)
✅ 1. 安装 openJDK(Java)
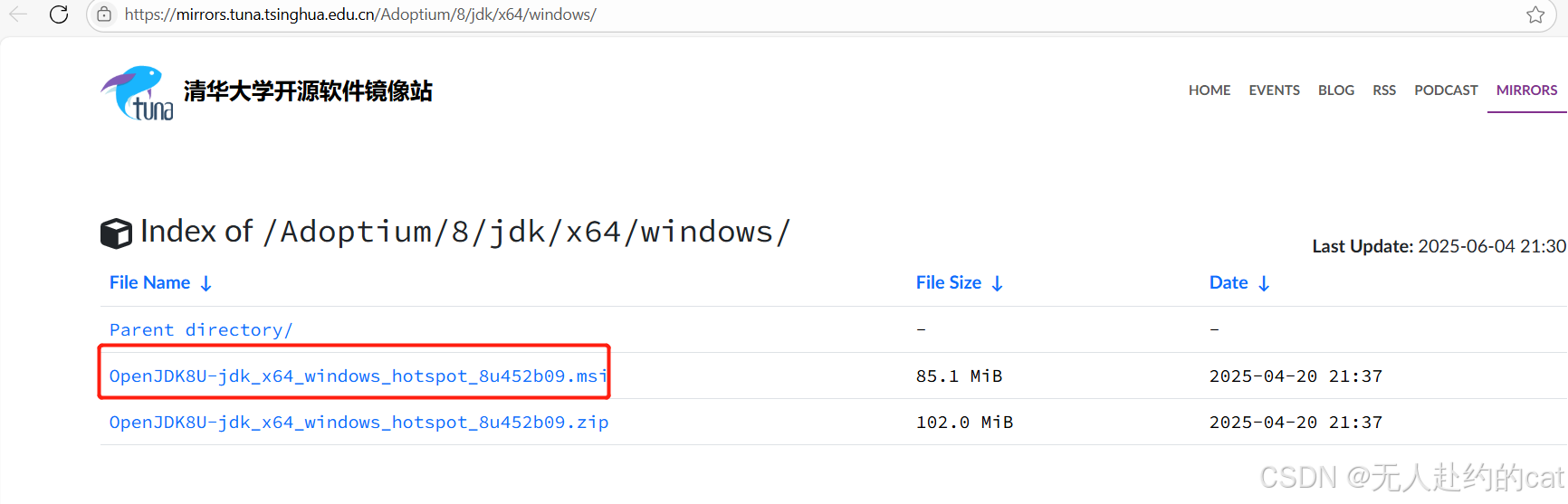
📥 下载地址(华为镜像):
👉 https://mirrors.tuna.tsinghua.edu.cn/Adoptium/8/jdk/x64/windows/
🚀 安装步骤:
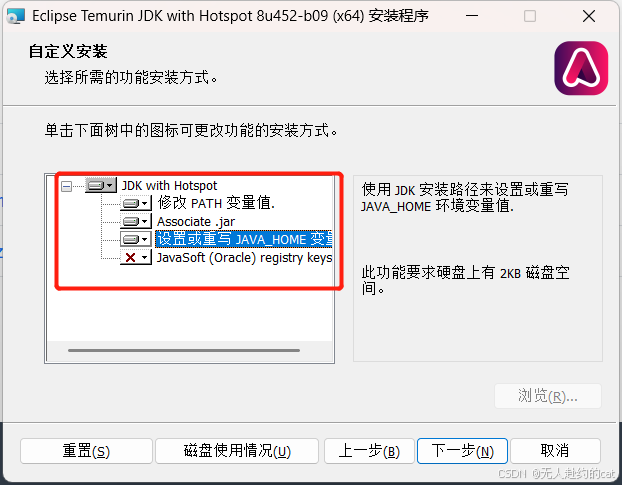
- 双击安装,点"下一步"即可。
- 修改设置或重写JAVA_HOME变量,点击下一步,完成安装。
✅ 测试:
打开命令提示符(Win + R 输入 cmd):
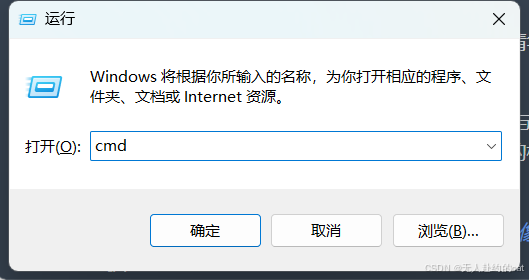
输入命令行:
bash
java -version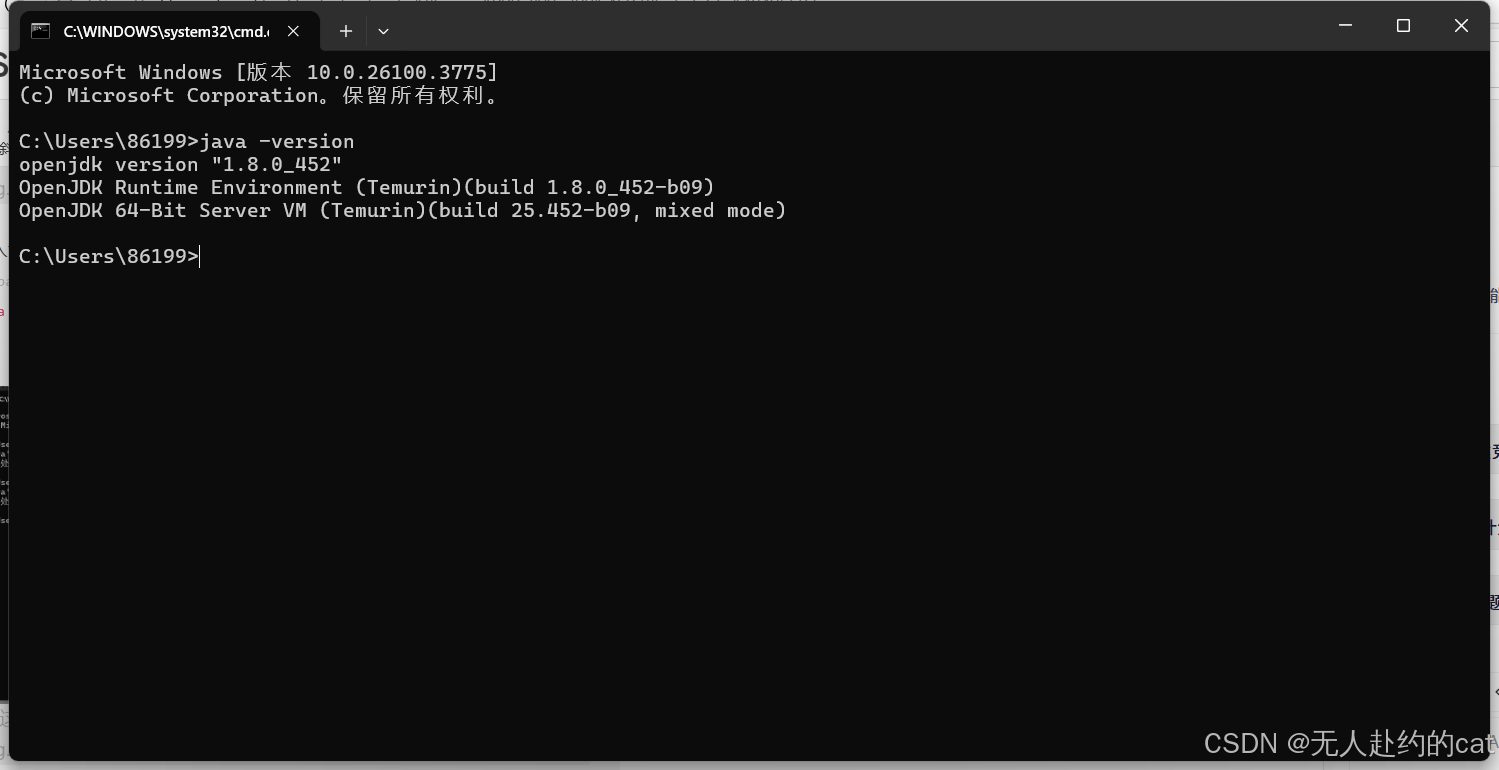
✅ 2. 安装 Scala
📥 下载地址(官网):
👉 https://www.scala-lang.org/download/2.12.20.html
🚀 安装步骤:
- 双击
.msi安装 - 一路next
✅ 测试:
打开命令提示符(Win + R 输入 cmd):
bash
scala -version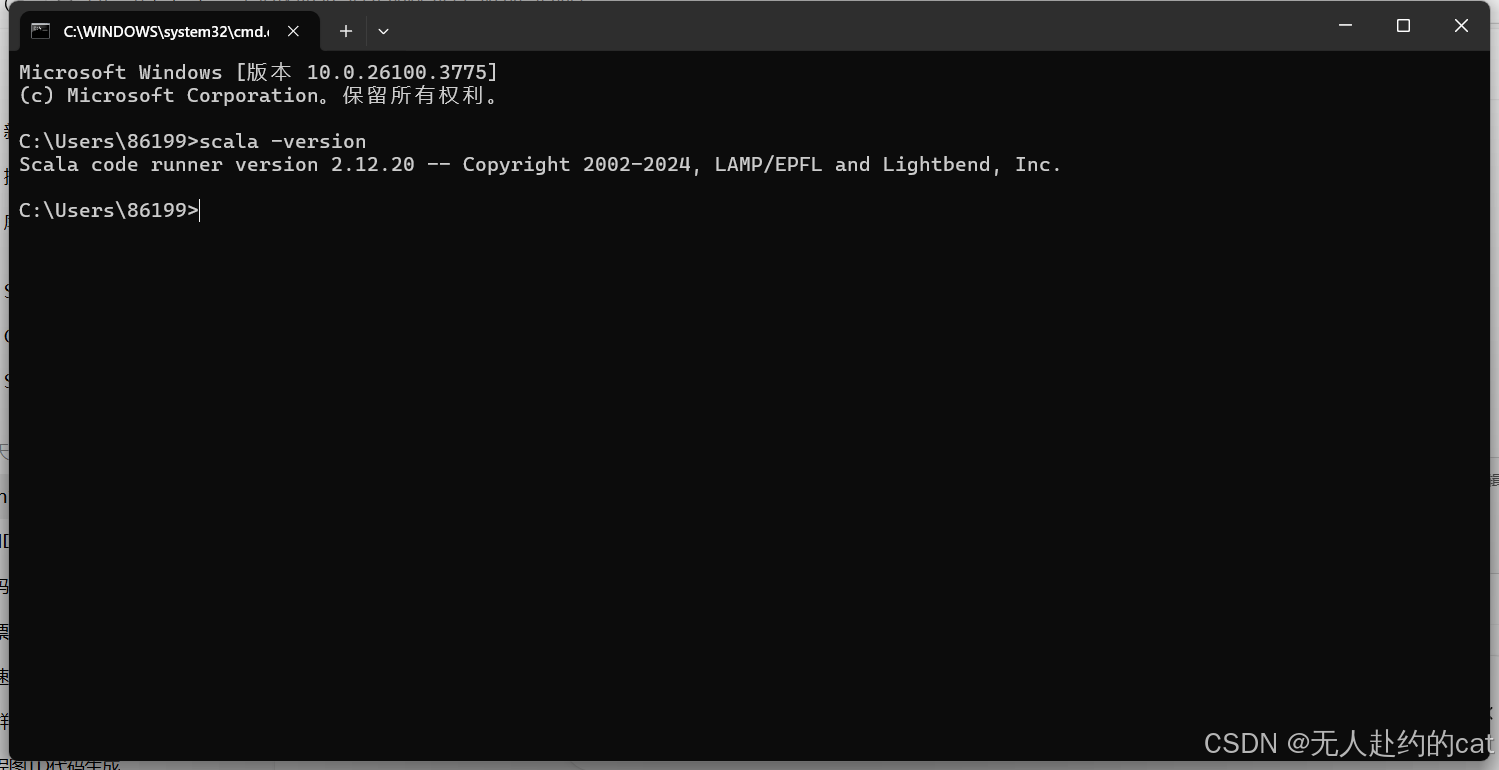
✅ 3. 安装 Spark
📥 下载地址(Spark 3.5.6,清华源):
👉 https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.5.6/
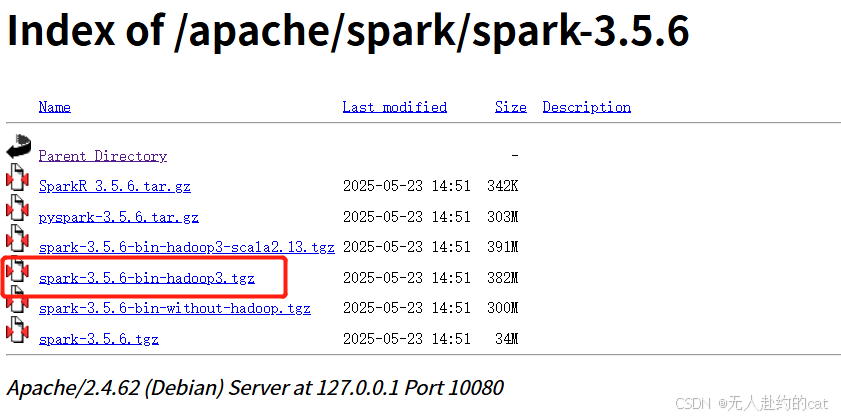
🚀 安装步骤:
- 解压缩
.tgz文件到任意目录(不要解压在包含中文或空格的路径下) - 得到目录:
spark-3.5.6-bin-hadoop3
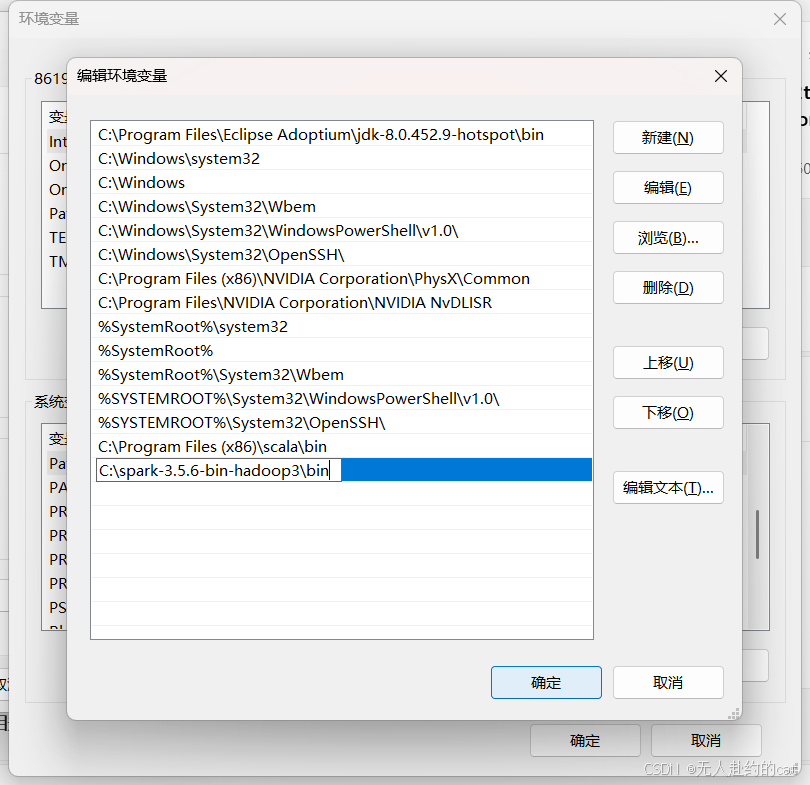
⚙️ 配置环境变量:
打开「控制面板」→「系统」→「高级系统设置」→「环境变量」
- 找到 系统变量下的Path
- 添加
spark安装目录\bin到Path
✅ 测试:
bash
spark-shell --version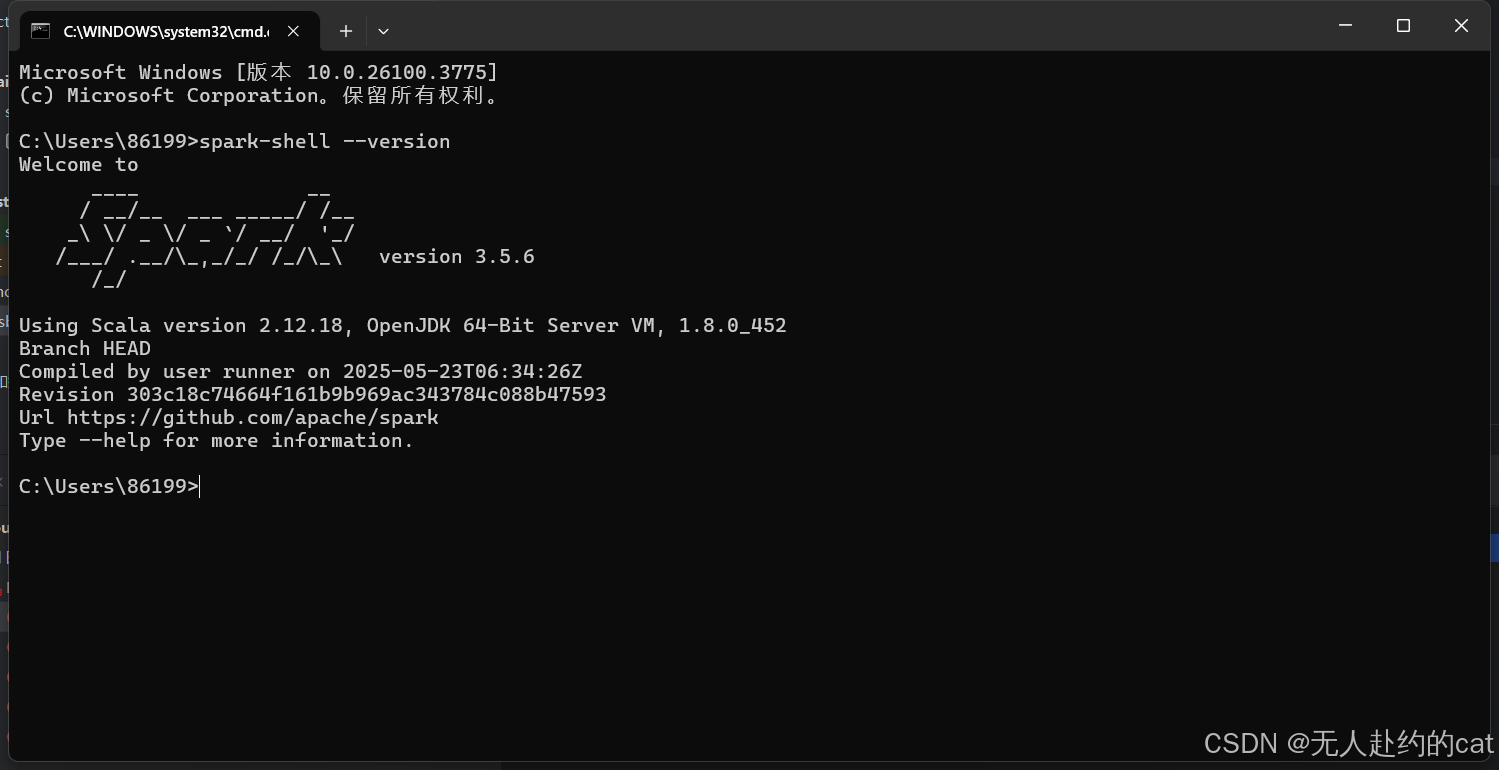
✅ 4. 安装 Hadoop Winutils(适配 Windows)
📥 下载地址(Gitee):
👉 https://github.com/cdarlint/winutils/tree/master/hadoop-3.3.5/bin
下载:
winutils.exe
将 winutils.exe复制到:(自己创建)
C:\hadoop\bin\⚙️ 配置环境变量:
- 添加
C:\hadoop\bin到Path
✅ 测试:
bash
winutils.exe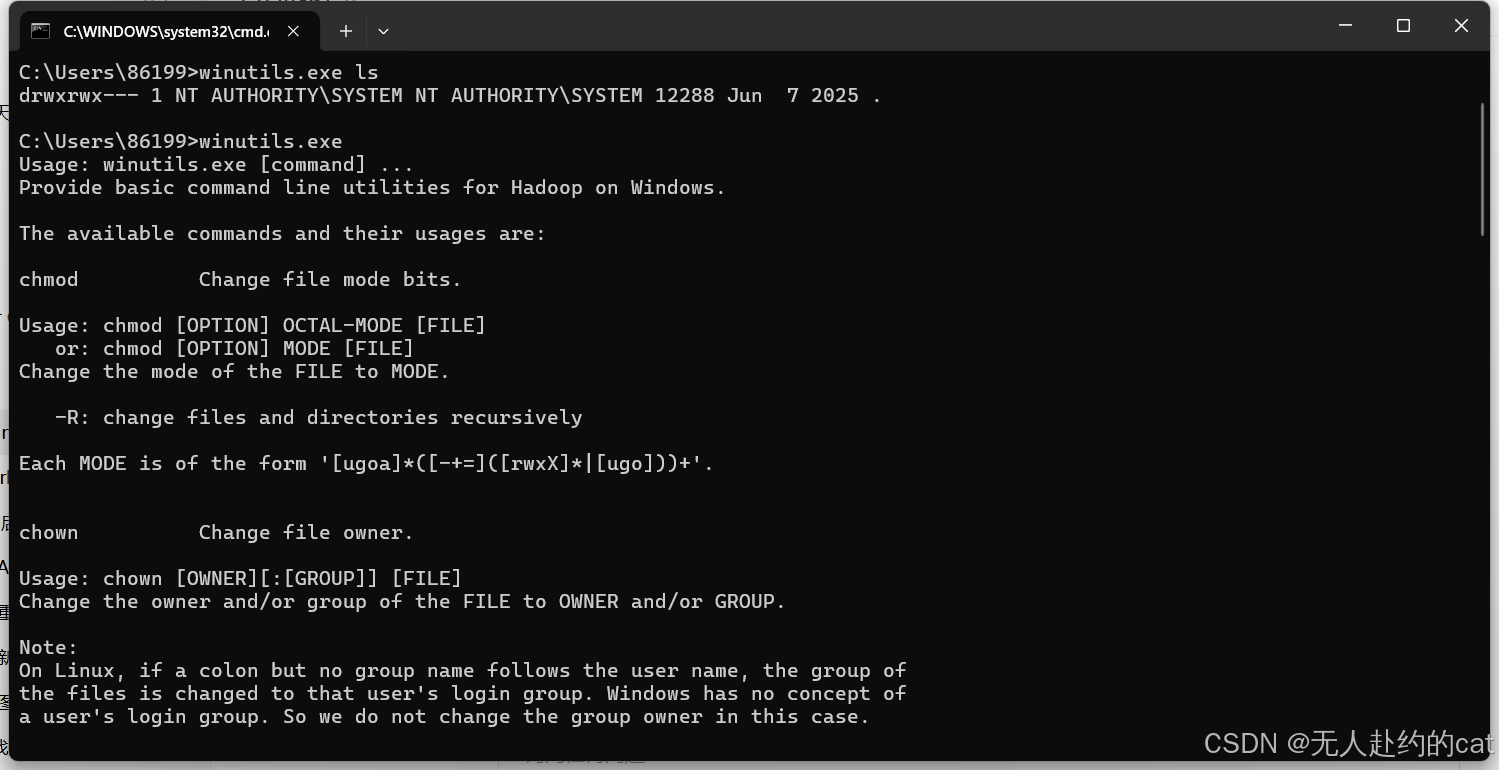
✅ 5. 安装 sbt(Scala 构建工具)
📥 下载地址(官网):
👉 https://www.scala-sbt.org/download/
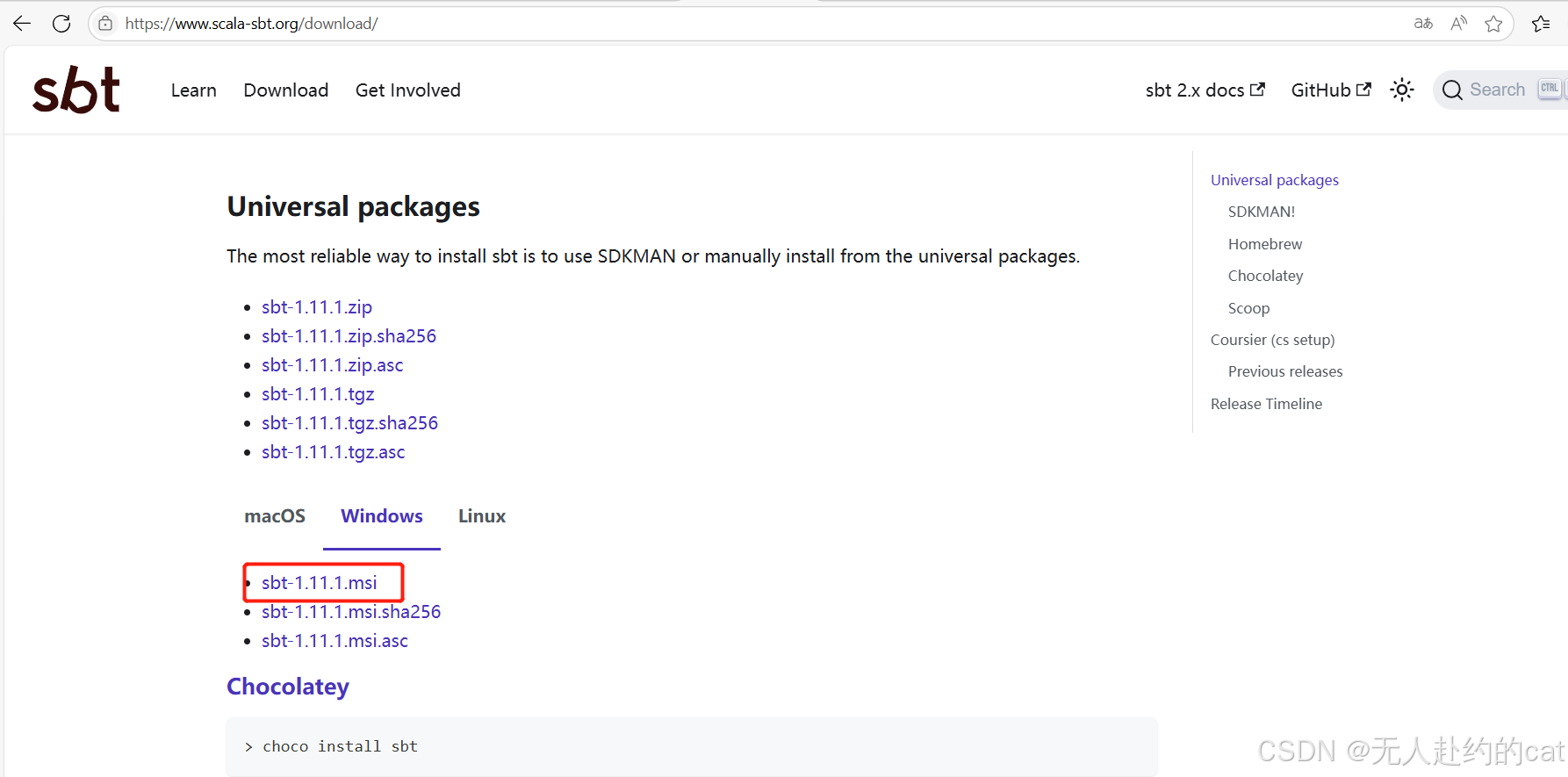
🚀 安装步骤:
- 双击安装,默认设置即可
✅ 测试:
bash
sbt sbtVersion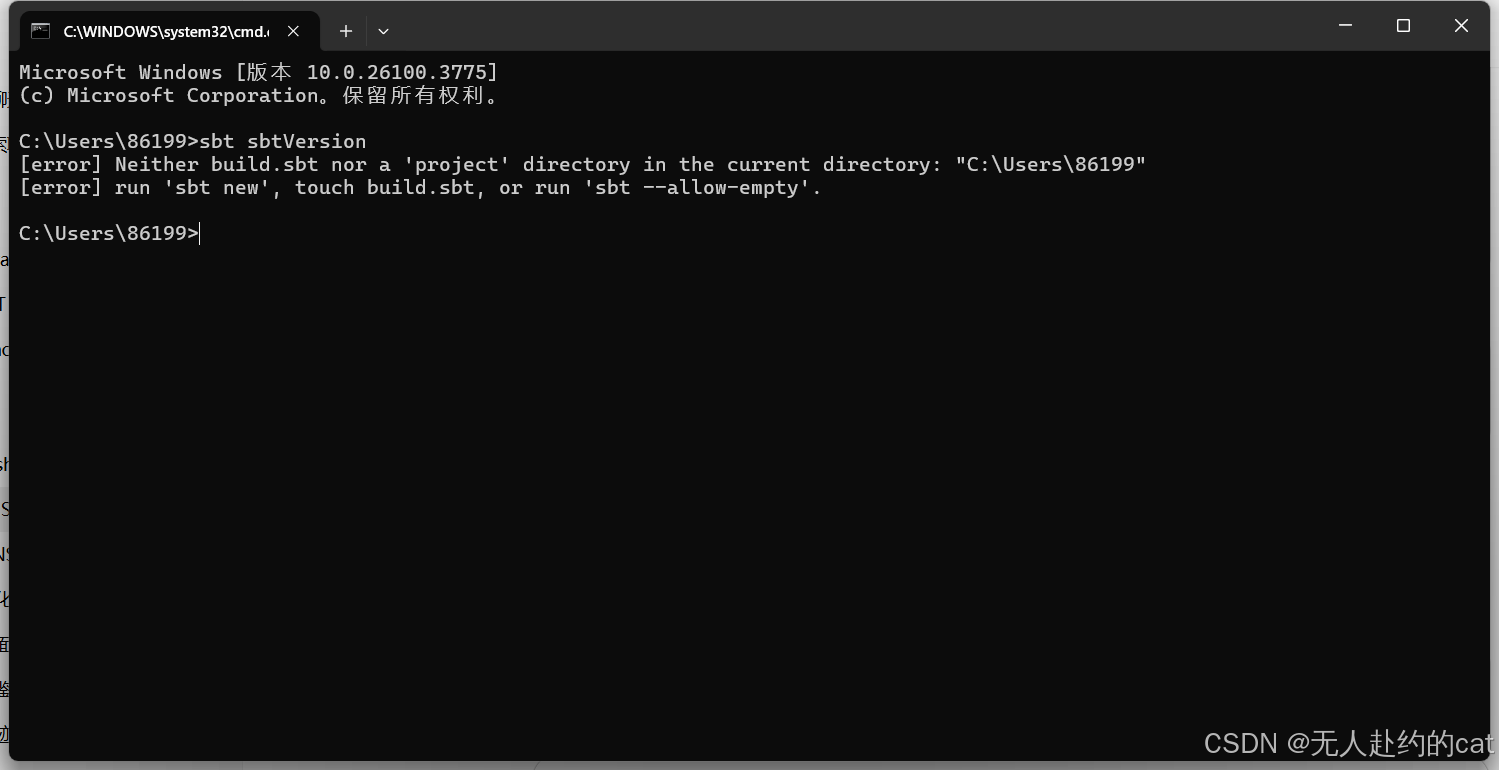
💻 二、安装 IntelliJ IDEA + 配置项目
✅ 1. 下载 IntelliJ IDEA 社区版(免费)
👉 官网:https://www.jetbrains.com/idea/download
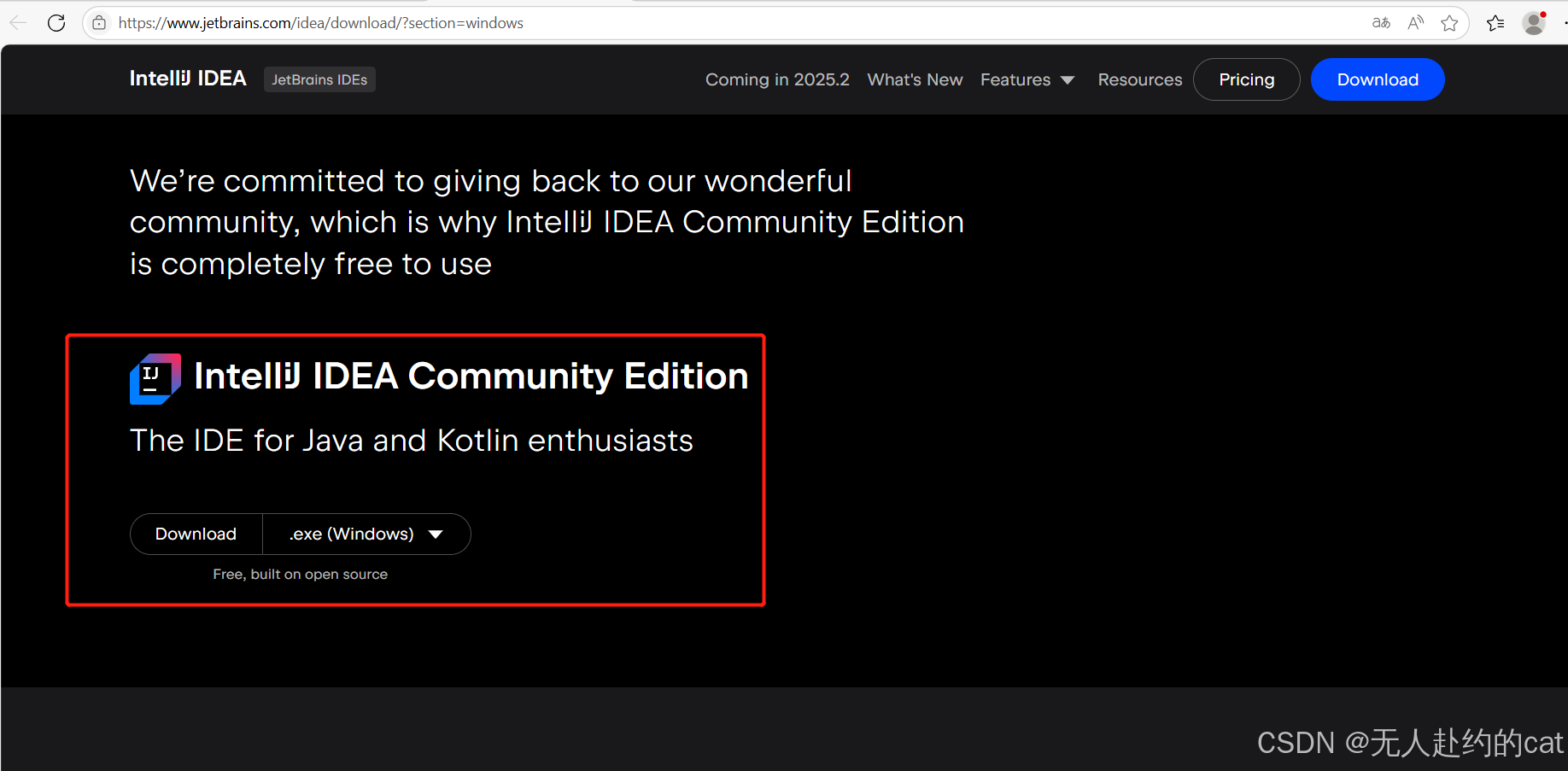
下载安装后,打开IDEA:
✔ 安装插件:
- ✅ Scala(必须)
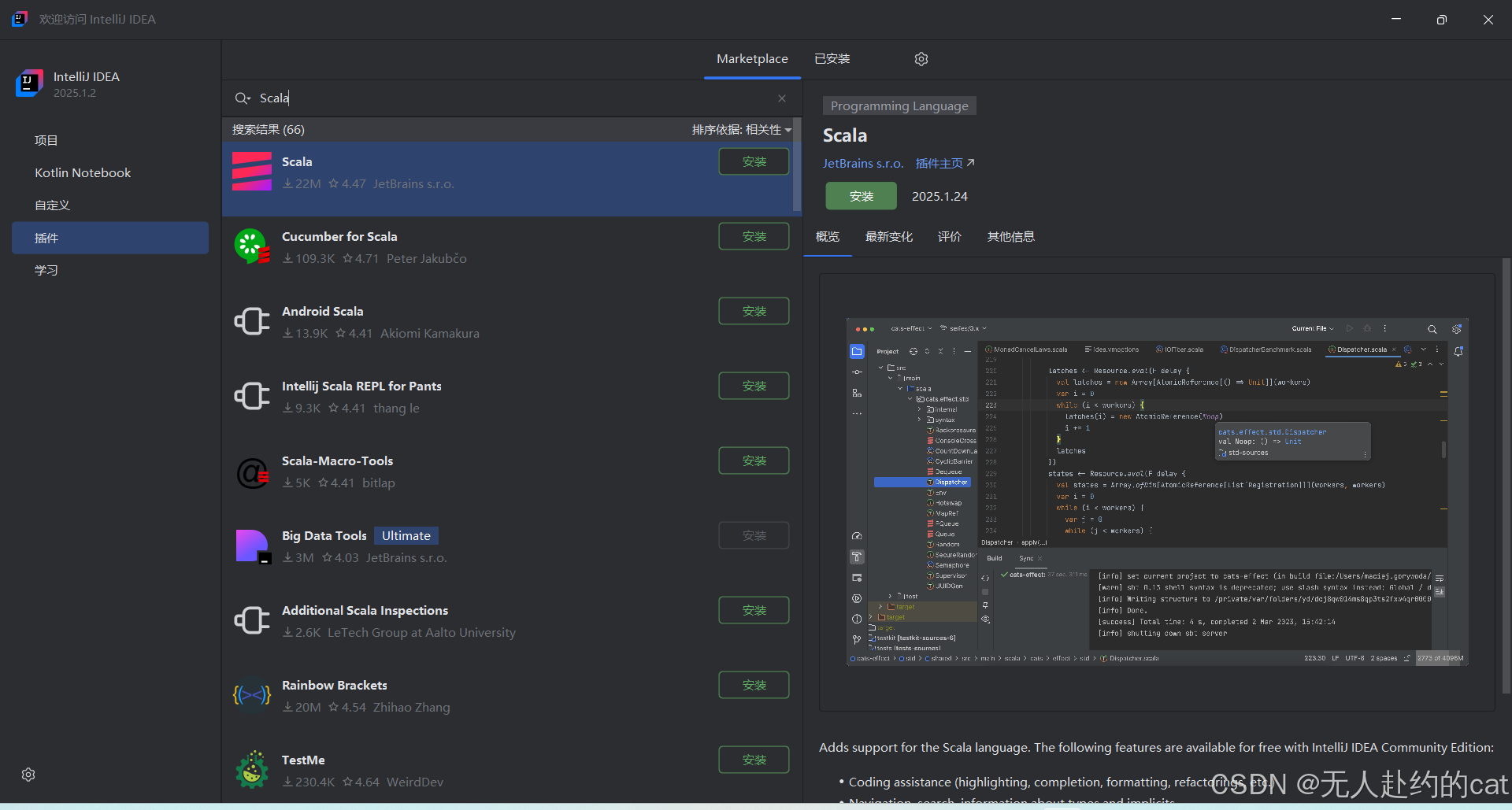
✅ 2. 创建新 Scala + sbt 项目
📁 项目结构(自动生成):
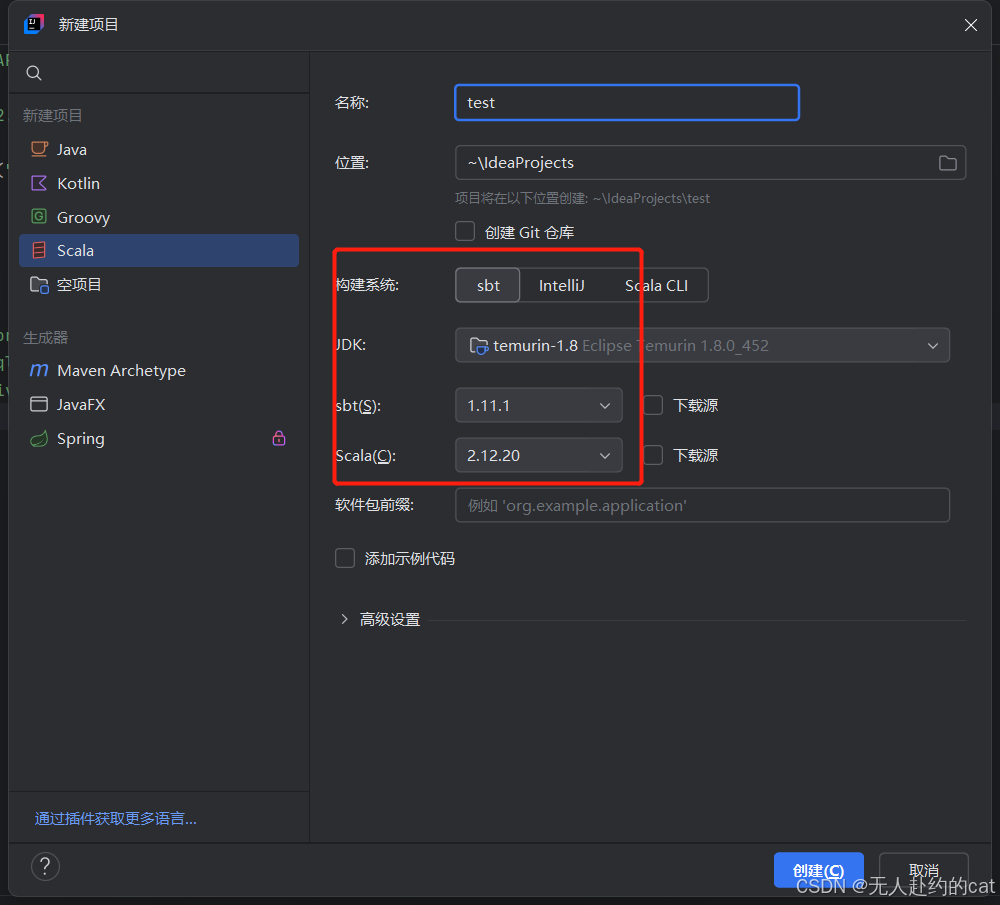
🚀 创建步骤:
-
打开 IntelliJ IDEA →
File > New > Project -
左侧选择
Scala→ 右侧选sbt -
配置:
- 项目名:
test - Scala SDK:选择
2.12.20 - sbt 版本:
1.11.1
- 项目名:
-
创建完成
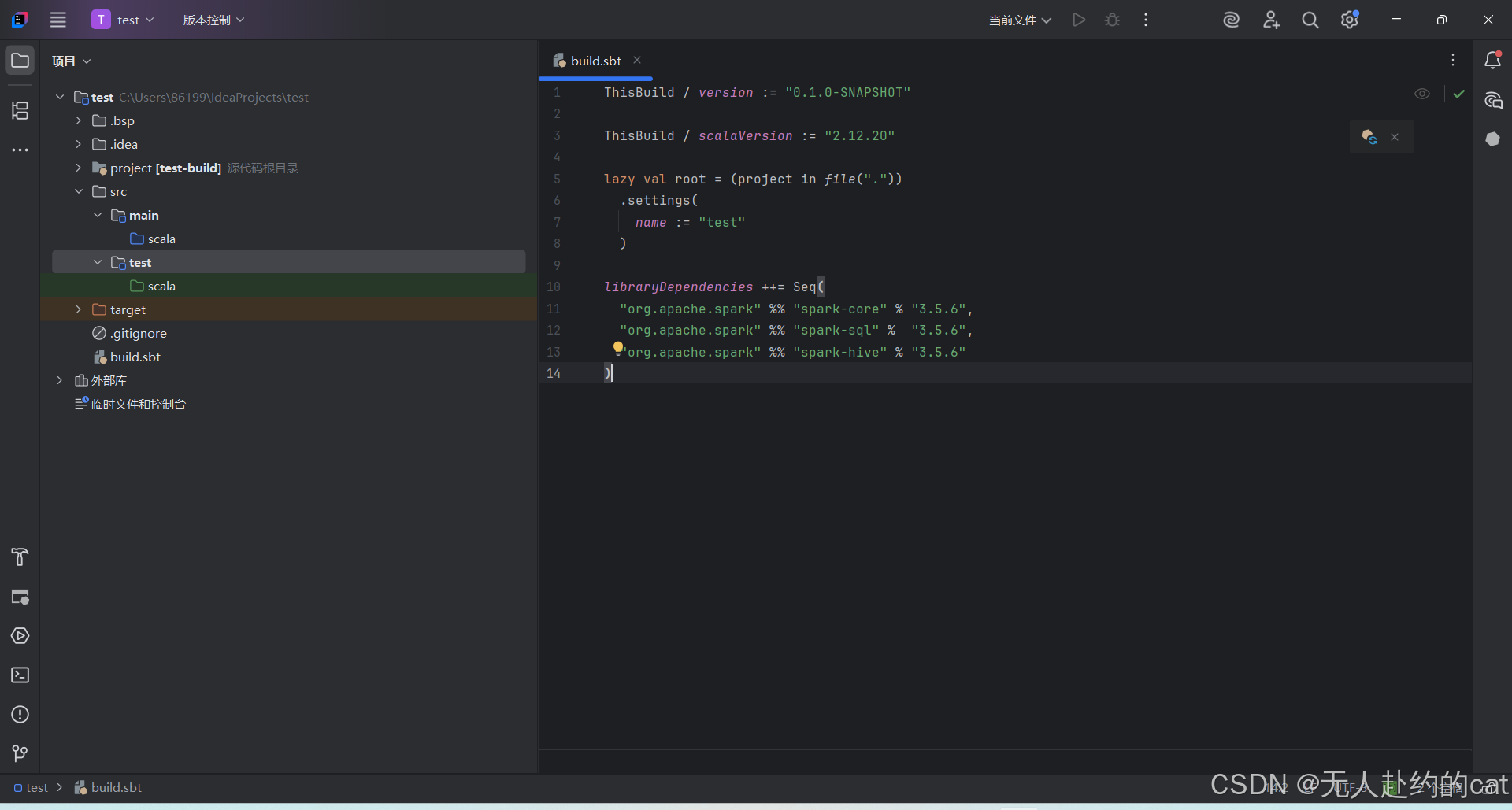
✅ 3. 编辑 build.sbt
scala
ThisBuild / version := "0.1.0-SNAPSHOT"
ThisBuild / scalaVersion := "2.12.20"
lazy val root = (project in file("."))
.settings(
name := "test"
)
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "3.5.6",
"org.apache.spark" %% "spark-sql" % "3.5.6",
"org.apache.spark" %% "spark-hive" % "3.5.6"
)
📄 三、运行你的代码文件
在scala文件夹下新建Explore.scala文件
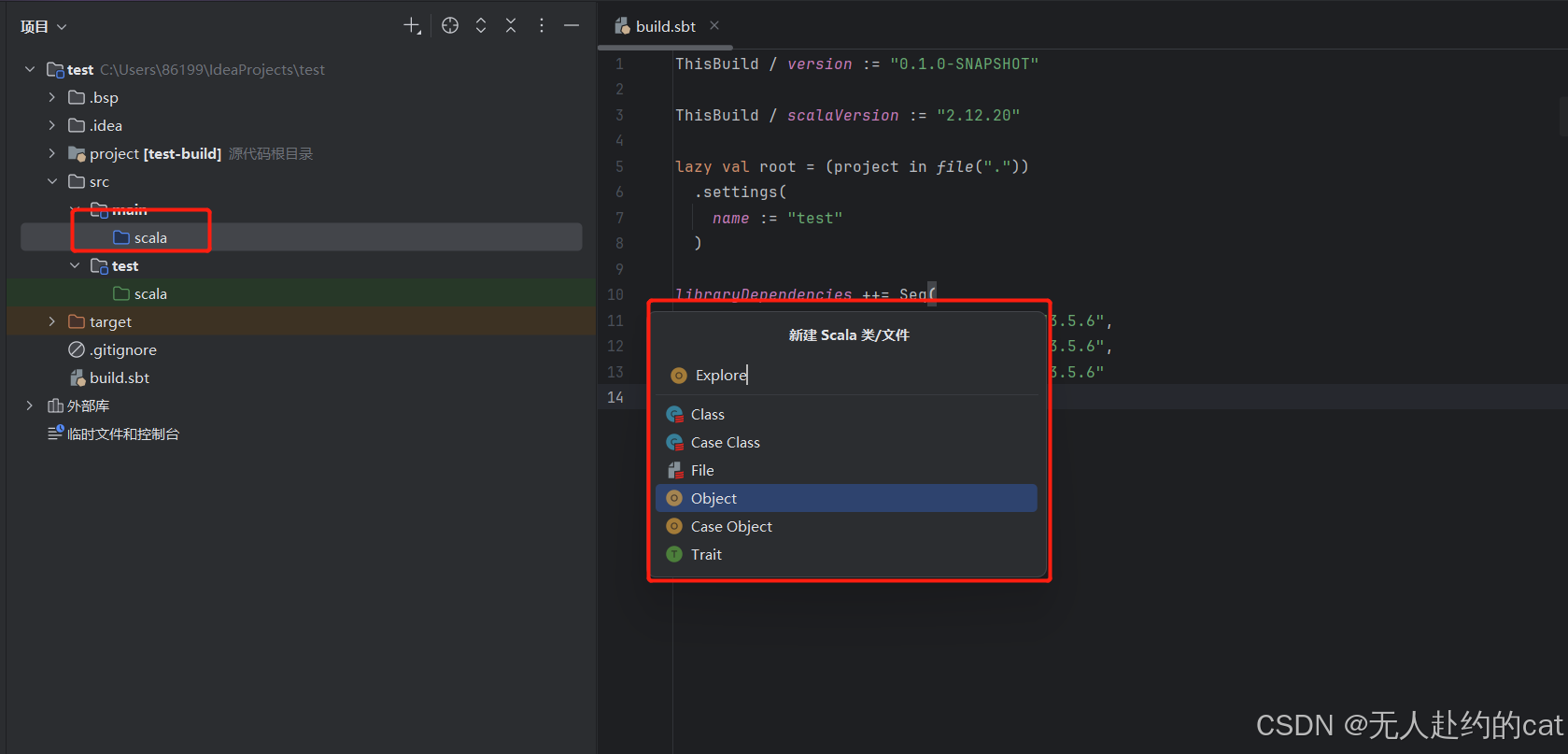
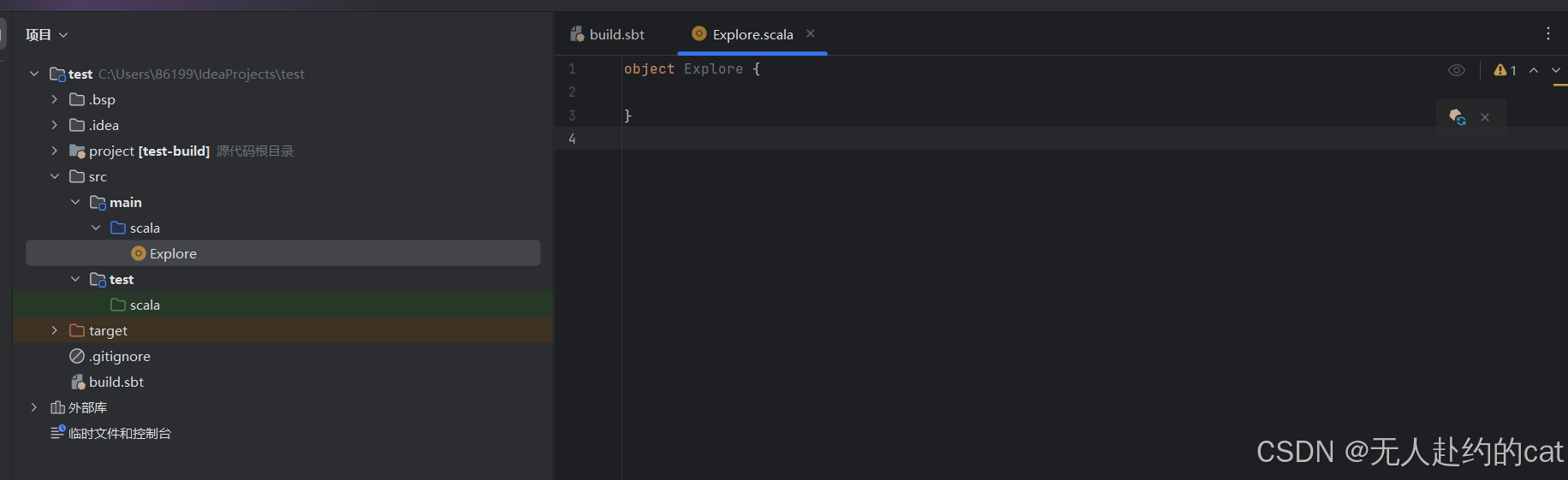
将你的代码文件复制 Explore.scala 中:
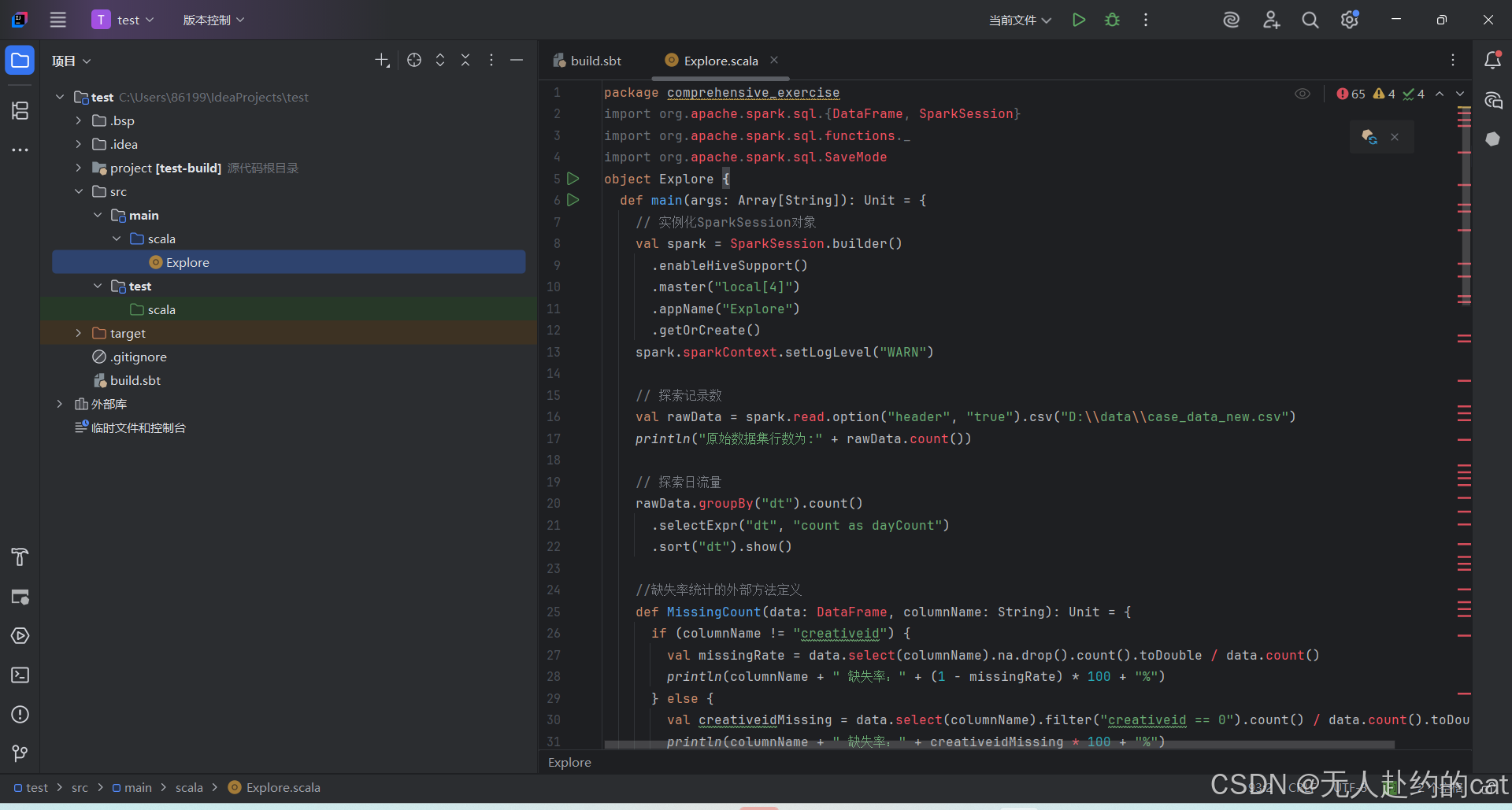
sbt下载配置依赖:
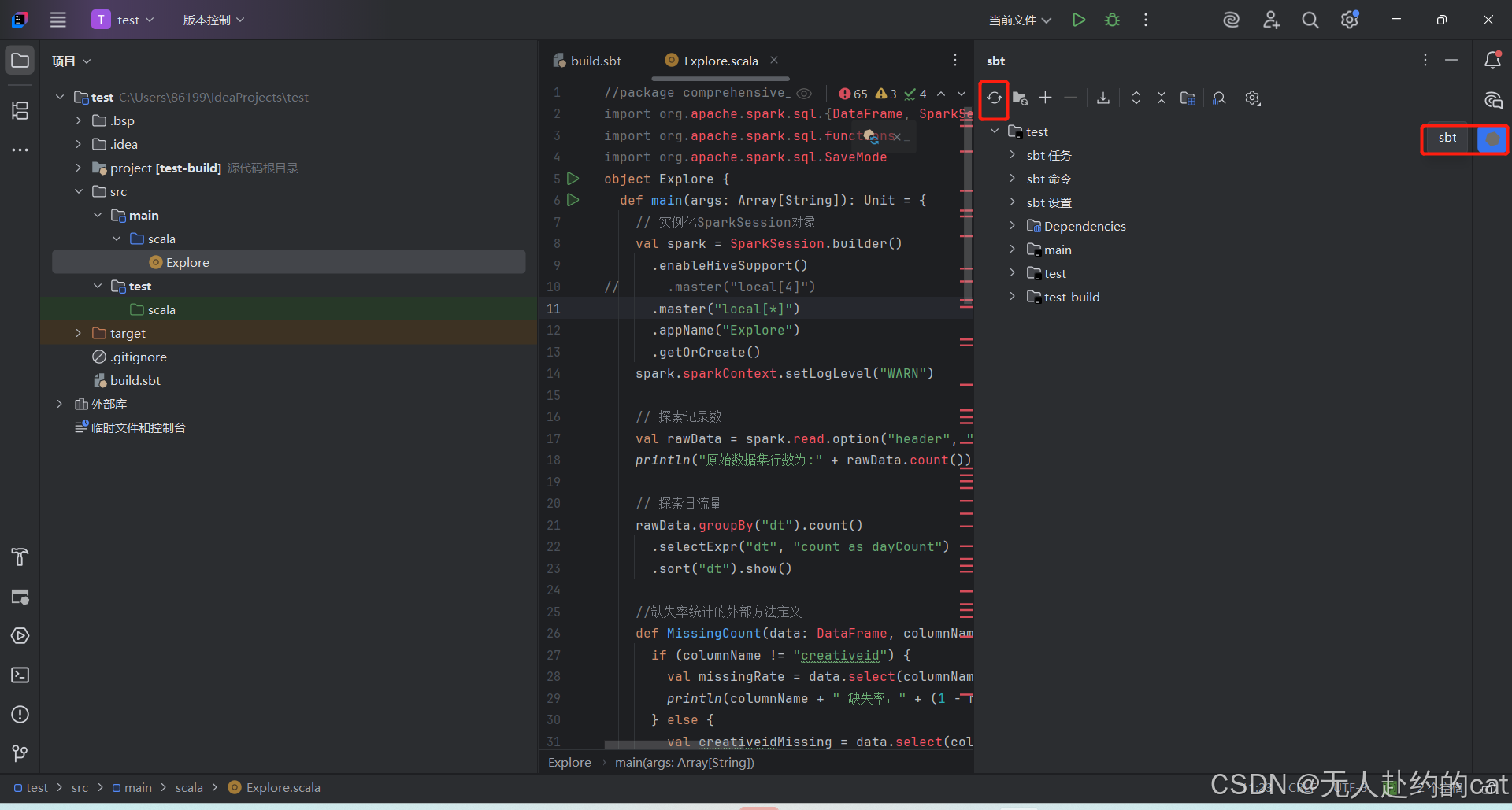
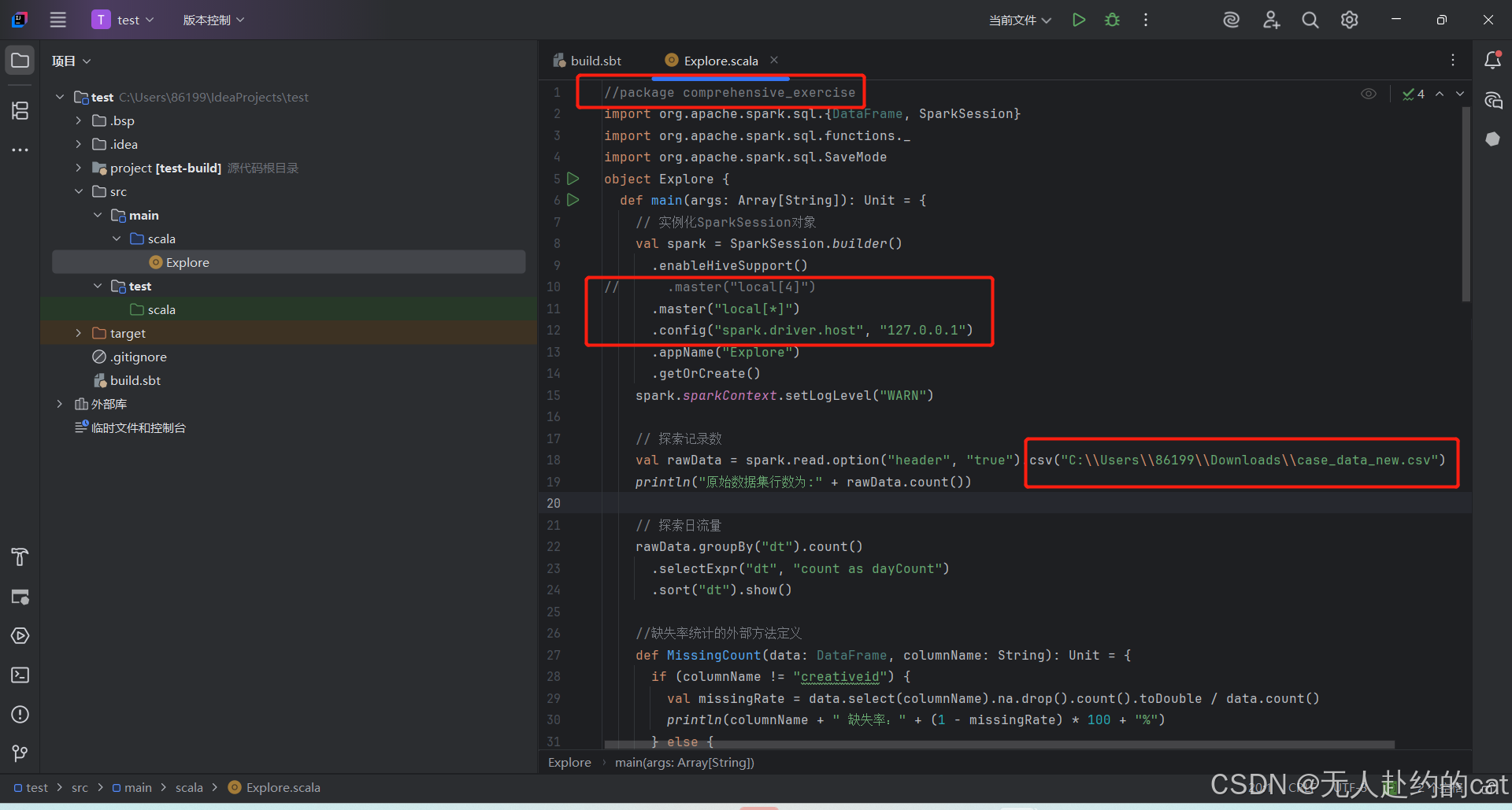
代码文件修改以下地方:
其中第三处文件位置填你自己csv文件存放的地址。
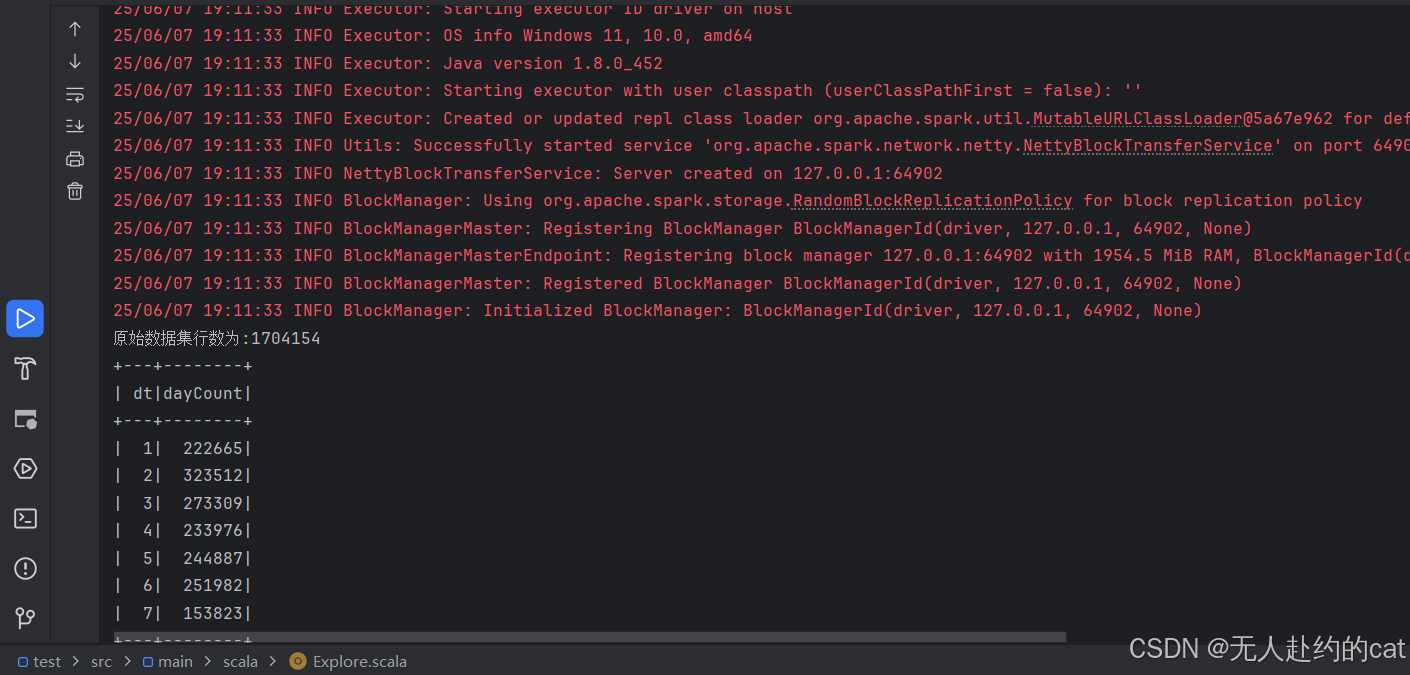
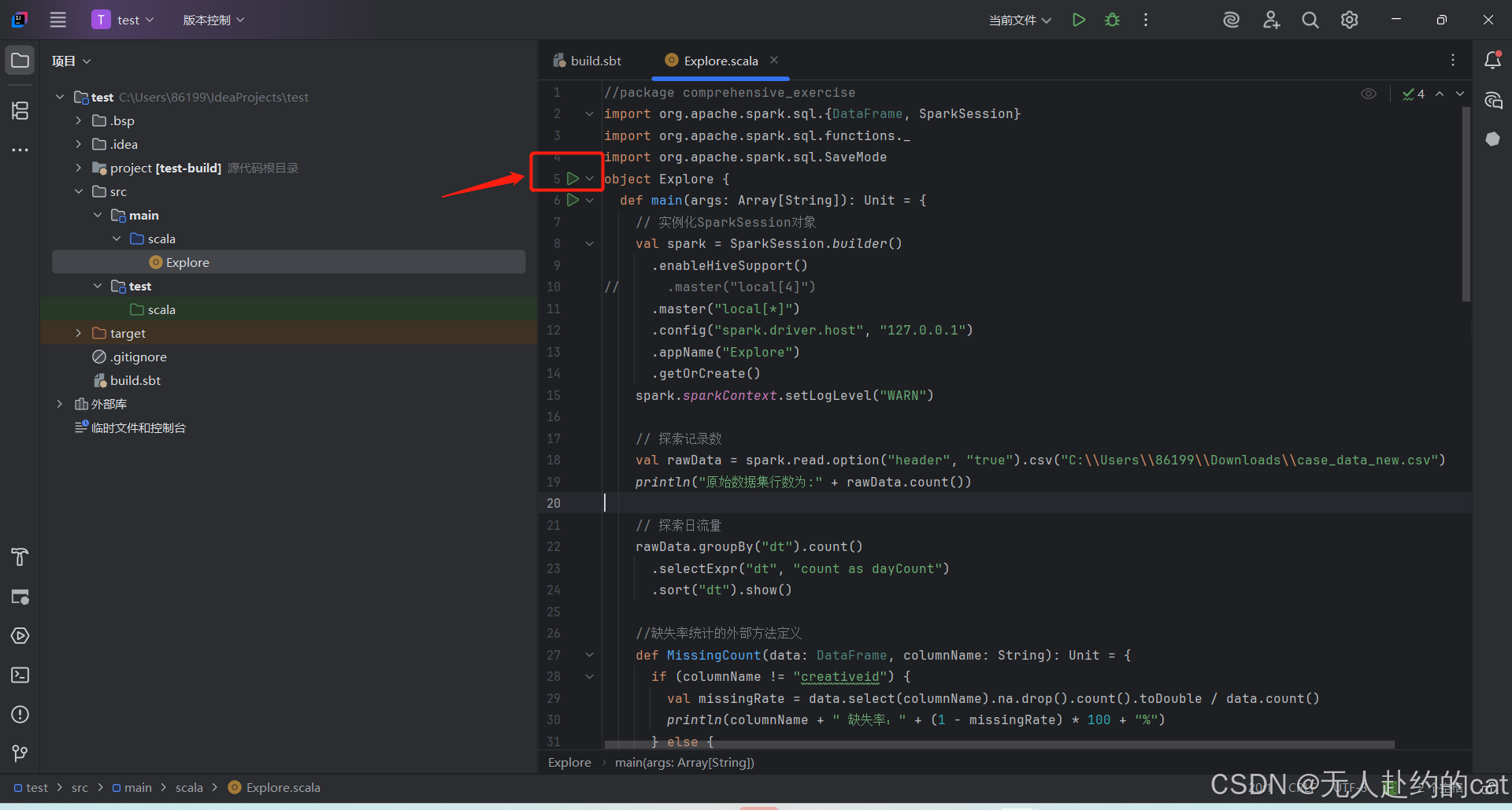
点击绿色三角运行即可:
出现如下结果即代码运行正常。