文章目录
- 一.基本使用
-
- 1.登录数据库
- 2.数据库操作
- 3.数据表操作
- 4.模式操作命令
- 4.1创建模式!在这里插入图片描述(https://i-blog.csdnimg.cn/direct/46238b019e694a82ad156f7de3c1a36f.png)
- 4.2默认模式
-
- 4.3删除模式
- 4.4查看所有模式
- 4.5在指定模式中创建表
- 4.6切换当前模式
- 4.7查看当前所在的schema
- [4.8查看搜索路径(search path)](#4.8查看搜索路径(search path))
- 4.9postgresql的模式隔离性
- 5.数据操作
- 6备份与恢复
- 7.远程连接
){kind=link}
){kind=link}
一.基本使用
1.登录数据库
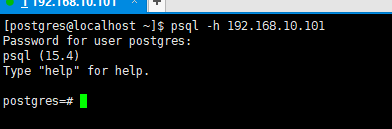
pgsql登陆时,必须使用postgres用户,登录后的命令提示符为"postgres=#"
postgres表示当前的数据库
2.数据库操作
2.1列出库
常用三种方法
方法一 :
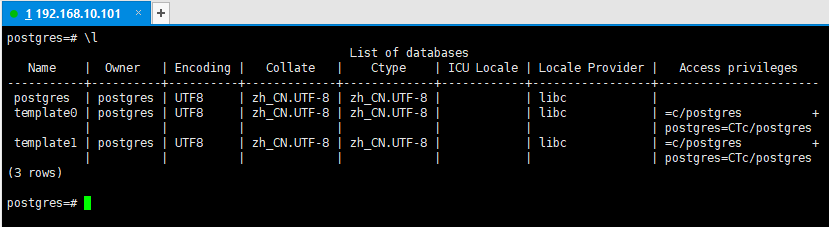
在postgresql交互式终端psql,"\"开头命令称为元命令(show语句)用于快速管理数据库
常用的元命令:
\l 查看所有数据库
\c 数据库名 或 \connect 数据库名
\dn 查看所有模式(schema)
\db****列出所有表空间
\? 显示pgsql命令说明(元命令查询帮助)
\q 退出数据库
\dt 列出数据库下所有的表
\d 查看表结构
\du 列出数据库用户
方法二:
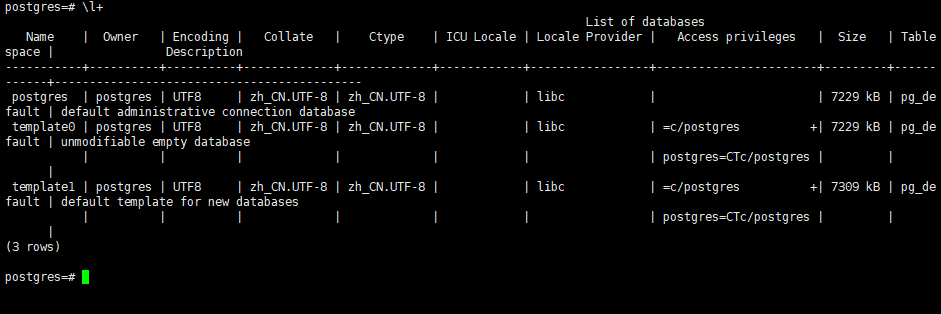 l+的输出比\1多了Size,Tablespace和Description列
l+的输出比\1多了Size,Tablespace和Description列
+:扩展输出,显示更多字段或详细信息
方法三:
使用sql语句
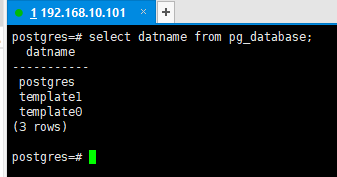
pg_database是系统表:它存储了PostgreSQL实例中所有数据库的元信息(如
数据库名称、所有者、编码等)。属于系统目录(SystemCatalog》:类似MySQL
的information_schema,但PostgreSQL的系统目录更底层且直接存储在
pg_catalog 模式中。
pg∠database是系统目录表,所以无论当前连接到哪个数据库,该表始终可见
系统表默认属于pg_catalog 模式,而pg_catalog始终位于搜索路径
(search_path)的首位。因此,查询时无需显式指定模式
(如pg_catalog.pg_database)。
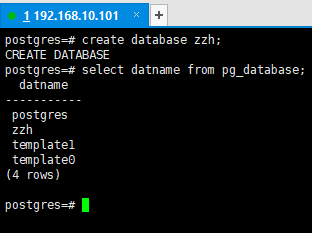
2.2创建数据库
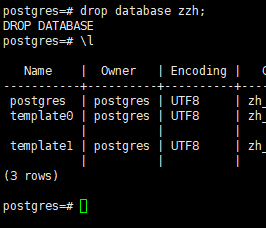
2.3删除数据库
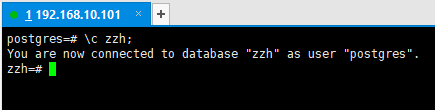
2.4切换数据库
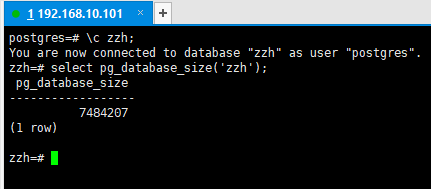
2.5查看库大小
3.数据表操作
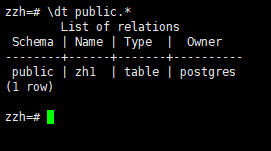
3.1列出表
列出表(显示search_path中模式里的表,默认public)

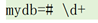
列出指定模式的表↑
查看当前数据库的所有表 包括系统表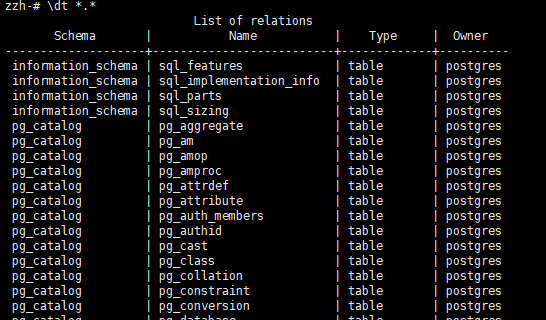
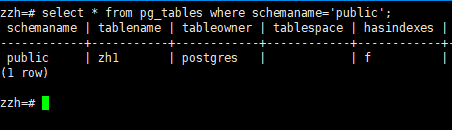
使用SLQL方式列出当前数据库中public模式下的所有表及其详细信息
pg_tables是视图:属于pg_catalog模式,但它是基于pg_class和
pg_namespace的逻辑视图,并非物理表。无需切换数据库,直接查询
pg_catalog.pg_tables即可获取当前数据库的表信息
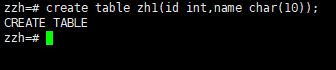
3.2创建表
PostgreSQL支持标准的 SQL类型int、smallint、real、double precision、
char(N)、varchar(N)、date、time、timestamp和interval,还支持其他的通
用功能的类型和丰富的几何类型。PostgreSQL中可以定制任意数量的用户定义
数据类型。因而类型名并不是语法关键字,除了SQL标准要求支持的特例外。
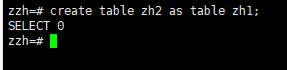
3.3复制表
要将已有的table_name表复制为新表new_table,包括表结构和数据,请
使用以下语句
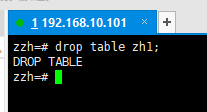
3.4删除表
3.5查看表结构
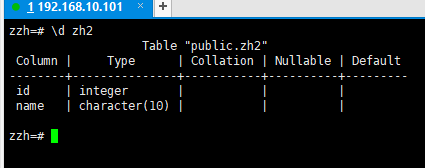
4.模式操作命令
在PostgreSQL中,模式(Schema)是一个逻辑容器,用于组织和管理数
据库对象(如表、视图、函数、索引等)。它类似于文件系统中的文件夹,帮助
你在同一个数据库中分类存储不同的对象,避免命名冲突,并实现权限隔离
4.1创建模式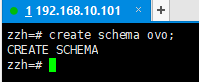
4.2默认模式
PostgreSQL每个数据库都有一个默认模式public。
如果创建对象(表、视图等)时不指定模式,默认会放在public模式中。
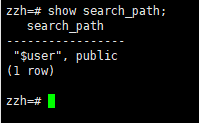
通过search_path参数可以设置模式的搜索优先级(类似PATH环境变量):
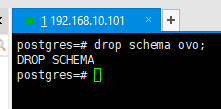
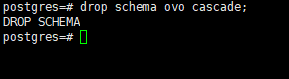
4.3删除模式
删除空模式
强制删除模式及所有对象
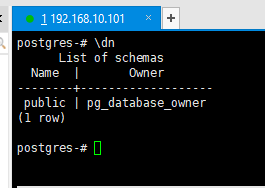
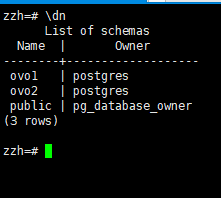
4.4查看所有模式
元命令列出当前库中所有模式
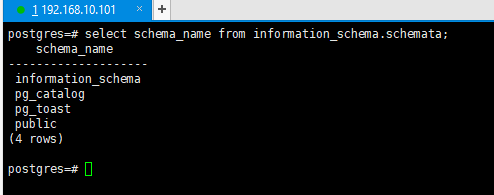
sql语句查询 当前库的所有模式
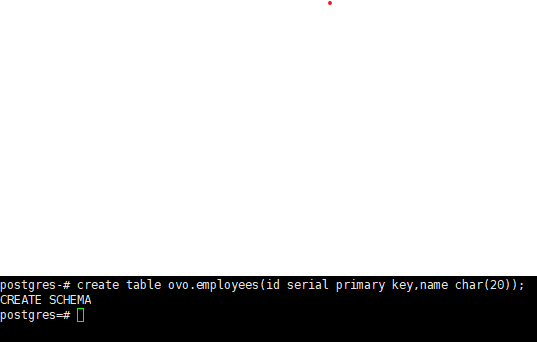
4.5在指定模式中创建表
未指定模式,创建的对象会按search_path顺序创建到第一个可用的模式中
在postgres库中的ovo模式下创建一个名为employees的表
4.6切换当前模式
切换模式也就是调整search_path搜索范围
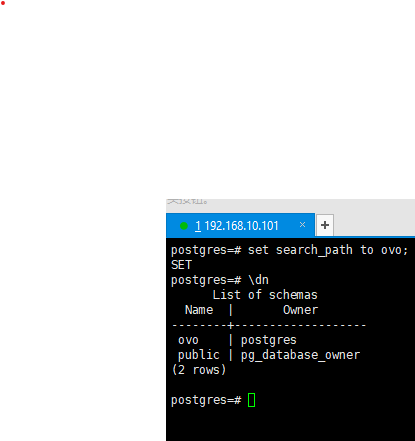
切换到多个schema(优先级顺序)
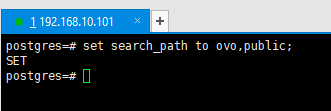
4.7查看当前所在的schema
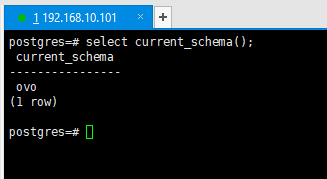
4.8查看搜索路径(search path)
4.9postgresql的模式隔离性
postgresql的模式是数据库的逻辑分组,不同模式可以存同名表。这就是跟mysql不同
跨模式查询需要根据模式指定的模式名字
通过search_path设置默认模式
无需切换数据连接
步骤1:创建数一个据库
创建数据库zzh
切换到zzh数据库
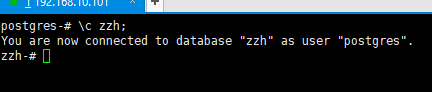
步骤2:在数据库中创建两个模式
创建一个ovo和ovo1模式
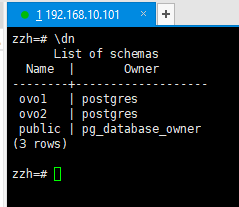
步骤3:在每个模式中创建同名表并插入数据
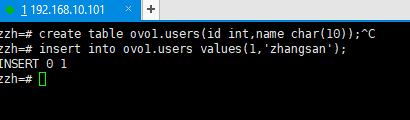
在ovo1创建users表
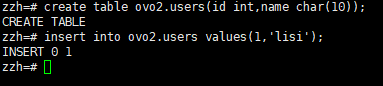
在ovo2中创建同名users表
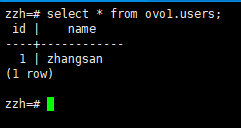
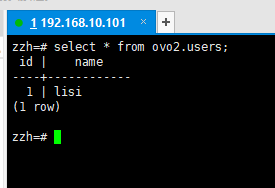
步骤4:跨模式查询
查询ovo1.users和ovo2.users(需显式指定模式名)
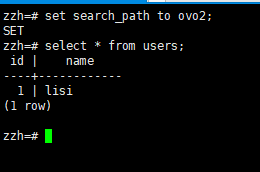
设置search_path切换默认模式(不需显式指定模式名)
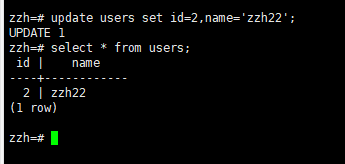
5.数据操作
5.1修改数据
5.2删除数据
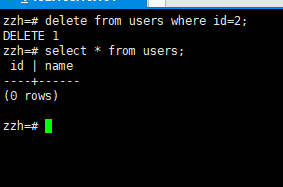
6备份与恢复
PostgreSQL数据库应当被定期地备份。虽然过程相当简单,但清晰地理解其
底层技术和假设是非常重要的。
有三种不同的基本方法来备份PostgreSQL数据:
SQL转储
>文件系统级备份
>连续归档
每一种都有其优缺点,我们主要以SQL转储为主。
6.1sql转储
SQL转储方法的思想是创建一个由SQL命令组成的文件,当把这个文件回馈
给服务器时,服务器将利用其中的SQL命令重建与转储时状态一样的数据
库。PostgreSQL为此提供了工具pgdump。这个工具的基本用法是:
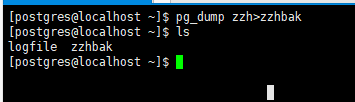
正如你所见,pg_dump把结果输出到标准输出。我们后面将看到这样做有什
么用处。尽管上述命令会创建一个文本文件,pg_dump可以用其他格式创建文
件以支持并行和细粒度的对象恢复控制。
pg_dump是一个普通的PostgreSQL客户端应用(尽管是个相当聪明的东西)。
这就意味着你可以在任何可以访问该数据库的远端主机上进行备份工作。但是请
记住pg_dump不会以任何特殊权限运行。具体说来,就是它必须要有你想备份
的表的读权限,因此为了备份整个数据库你几乎总是必须以一个数据库超级用户来运行它(如果你没有足够的特权来备份整个数据库,你仍然可以使用诸如
-nschema或-ttable选项来备份该数据库中你能够访问的部分)。
要声明pg_dump连接哪个数据库服务器,使用命令行选项-hhost
和 -pport。默认主机是本地主机或你的PGHOST环境变量指定的主机。类
似地,默认端口是环境变量PGPORT或(如果PGPORT不存在)内建的默认值。(服
务器通常有相同的默认值,所以还算方便。)
和任何其他PostgreSQL客户端应用一样,pg_dump默认使用与当前操作
系统用户名同名的数据库用户名进行连接。要使用其他名字,要么声明-U选项,
要么设置环境变量PGUSER。请注意pg_dump的连接也要通过客户认证机制。
pg_dump对于其他备份方法的一个重要优势是,pg_dump的输出可以很容
易地在新版本的PostgreSQL中载入,而文件级备份和连续归档都是极度的服务
器版本限定的。pg_dump也是唯一可以将一个数据库传送到一个不同机器架构上
的方法,例如从一个32位服务器到一个64位服务器,
由pg_dump创建的备份在内部是一致的,也就是说,转储表现了pg_dump
开始运行时刻的数据库快照,且在pg_dump运行过程中发生的更新将不会被转储。
pg_dump工作的时候并不阻塞其他的对数据库的操作。(但是会阻塞那些需要
排它锁的操作,比如大部分形式的ALTERTABLE)
6.2转储恢复
pg_dump生成的文本文件可以由psql程序读取。从转储中恢复的常用命令是:
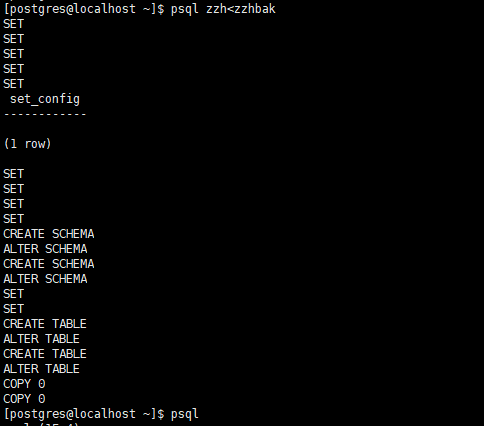
 其中dumpfile就是pg_dump命令的输出文件。这条命令不会创建数据库
其中dumpfile就是pg_dump命令的输出文件。这条命令不会创建数据库
dbname,你必须在执行psql前自己从template0创建(例如,用命令createdb
-Ttemplate0dbname)。psql支持类似pg_dump的选项用以指定要连接的数
据库服务器和要使用的用户名。参阅psql的手册获取更多信息。非文本文件转
储可以使用pg_restore工具来恢复。
在开始恢复之前,转储库中对象的拥有者以及在其上被授予了权限的用户必
须已经存在。如果它们不存在,那么恢复过程将无法将对象创建成具有原来的所
属关系以及权限(有时候这就是你所需要的,但通常不是)。
默认情况下,psql脚本在遇到一个SQL错误后会继续执行。你也许希望在遇
到一个SQL错误后让psql退出,那么可以设置ON_ERROR_STOP变量来运行psql,
这将使psql在遇到SQL错误后退出并返回状态3
不管怎样,你将只能得到一个部分恢复的数据库。作为另一种选择,你可以
指定让整个恢复作为一个单独的事务运行,这样恢复要么完全完成要么完全回滚。
这种模式可以通过向psql传递-1或--single-transaction命令行选项来指定。
在使用这种模式时,注意即使是很小的一个错误也会导致运行了数小时的恢复被
回滚。但是,这仍然比在一个部分恢复后手工清理复杂的数据库要更好。
pg_dump和psql读写管道的能力使得直接从一个服务器转储一个数据库到
另一个服务器成为可能
6.3使用pg_dumpall
pg_dump每次只转储一个数据库,而且它不会转储关于角色或表空间(因为
它们是集簇范围的)的信息。为了支持方便地转储一个数据库集簇的全部内容,
提供了pgdumpall程序。pg_dumpall备份一个给定集簇中的每一个数据库,并
且也保留了集簇范围的数据,如角色和表空间定义。该命令的基本用法是:
实际上,你可以指定恢复到任何已有数据库名,但是如果你正在将转储载
入到一个空集簇中则通常要用(postgres)。在恢复一个pg_dumpall转储时常
常需要具有数据库超级用户访问权限,因为它需要恢复角色和表空间信息。如果
你在使用表空间,请确保转储中的表空间路径适合于新的安装。
pg_dumpall工作时会发出命令重新创建角色、表空间和空数据库,接着
为每一个数据库pg_dump。这意味着每个数据库自身是一致的,但是不同数据库
的快照并不同步。
集簇范围的数据可以使用pg_dumpall的一─globals-only选项来单独转
储。如果在单个数据库上运行pg_dump命令,上述做法对于完全备份整个集簇是
必需的。
7.远程连接
7.1 修改postgresql监听地址
默认PostgreSQL监听的地址是127.0.0.1,别的机器无法远程连接上,所以
需要调整,修改postgresql.conf文件。
通过 dnf 安装的 pgsql 配置文件在
/var/lib/pgsql/data/postgresql.conf
过源码编译安装的pgsql配置文件在
/usr/local/pgsql/data/postgresql.conf
更改60行,取消注释并把localhost(本地主机)改成(所有主句地址) *

重启服务

7.2配置访问权限
默认是只能本地访问PostgreSQL的,我们需要在pg_hba.conf里面配置
找到IPv4localconnections这一行,在这一行下面添加

ost:这指定了连接类型。host表示该规则适用于通过TCP/IP进行的远程
连接。如果是本地连接,通常会使用local。
all:这定义了哪些数据库可以接受这个规则。all表示这个规则适用于所有
数据库。你也可以指定特定的数据库名,例如mydatabase。
all:这定义了哪些用户可以接受这个规则。all表示这个规则适用于所有用
户。你也可以指定特定的用户名,例如myuser。
X
0.0.0.0/0:这定义了哪些客户端IP地址或IP地址范围可以接受这个规
则。0.0.0.0/0是一个特殊的CIDR表示法,它表示任何IP地址(即没有IP地
址限制)。你也可以指定具体的IP地址,如192.168.1.100,或者IP地址范
围,如 192.168.1.0/24。
trust:这定义了认证方法。trust表示不需要密码或其他任何形式的认证,
客户端可以直接连接。这通常只在本地或受信任的网络环境中使用,因为它允许
任何人无需认证即可访问数据库。请注意,使用trust认证方法允许任何IP地
址连接到你的数据库,而不需要任何认证,这是非常不安全的。这通常只在开发
或测试环境中使用,并且应该始终确保数据库服务器不暴露在不受信任的网络中。
在生产环境中,你应该使用更安全的认证方法,如md5或password(对于较新
版本的PostgreSQL,建议使用scram-sha-256
如果不是设置的trust,而是选择了md5或password之类的,需要有密码才
行,配置PostgreSQL密码流程如下

7.4验证远程连接
使用其它主机远程连接本机数据库,设置的是trust,无密码,可直接登录
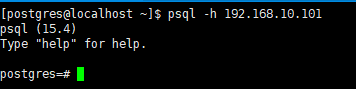
如果设置的是md5或password之类的需要有密码才行