- bugs归纳
|------------------------------------------------------------------------------------------------|-------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 工具 | 现象 | 对应bugs | 目前解决方案 | 详情 |
| hive3.1.2 登录 · 扁鹊健康科技 | 内存只升不降,最终进程挂断 | HIVE-22275 OperationManager.queryIdOperation does not properly clean up multiple queryIds - ASF JIRA HIVE-26530 HIVE-24179 HIVE-19860 | 定时挂断自起(临时) | operation.OperationManager的多个adding,只会remove最后一个 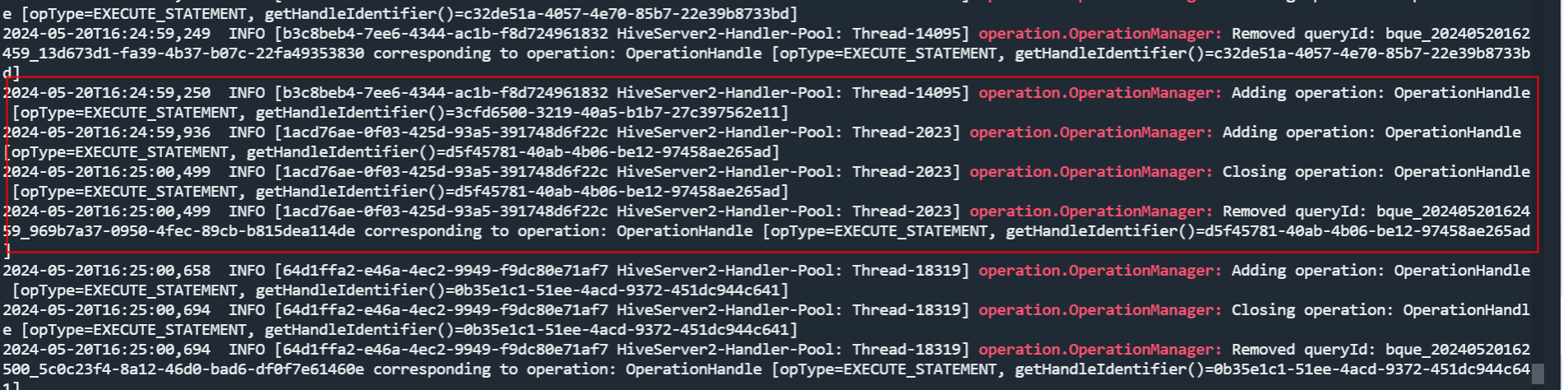 |
|
| hive3.1.2 登录 · 扁鹊健康科技 | 多表join丢数据(已解决) | HIVE-22098 Data loss occurs when multiple tables are join with different bucket_version - ASF JIRA HIVE-21304 | 手动增加临时表指定bucketVersion-》打补丁 | 三个表联接。第一个表中的table_a和第二个表中的table_b的临时结果数据连接结果记录为tmp_a_b,当它与第三个表连接时,hive-3.0.0后默认创建的表的 bucket_version=2,临时数据tmp_a_b初始化了 bucketVerison=-1,然后连接了 ReduceSinkOperator Verketison=-1。在 init 方法中,根据 bucketVersion 选择 join 列的哈希算法。如果 bucketVersion = 2 并且不是 acid 操作,则将获得新的哈希算法。否则,将获得哈希的旧算法。由于哈希算法的不一致,导致的数据分配分区不同。在Reducer阶段,具有相同键的数据无法配对,导致数据丢失。 |
| hive3.1.2 登录 · 扁鹊健康科技 | 每日调度随机出现以下报错,但可通过多次重试执行成功 | dolphinscheduler调度常见问题_org.apache.dolphinscheduler.plugin.task.api.taskex-CSDN博客 | 重试 | 1. TTransport:SocketTimeout:Read time out 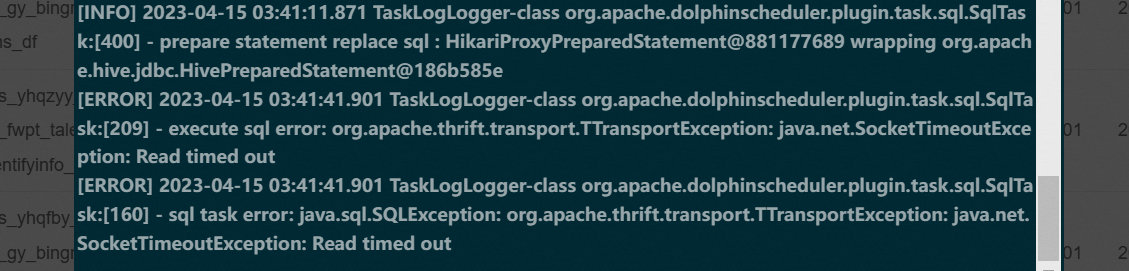 1. SQL task prepareStatementAndBind
1. SQL task prepareStatementAndBind 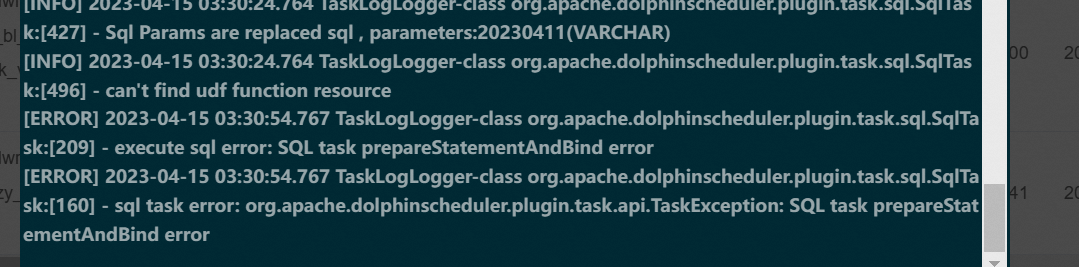 |
|
| dolphinscheduler2.0.6 | 传参偶发性失效 | https://github.com/apache/dolphinscheduler/issues/9745 | '{bizdate}'-\>'{yyyyMMdd-1}' (临时) | 由于多线程的影响,解析setValue语法的线程可能无法及时解析,导致varpool缺失。 当工作流同时启动多个工作线程时,会在另一个线程中解析setValue语法,有些工作会在解析setValue线程完成之前就已经完成了。 临时计划是等待getLogoutputService完成,然后进行下一步 |
| | 无法停止的工作流以及版本切换出现:切换工作流版本出错。 | https://github.com/apache/dolphinscheduler/issues/835 | 删掉僵尸元数据 | 在dolphinsscheduler对应的数据库中,查询t_ds_task_definition_log、t_ds_task_definition表 SELECT code ,version,COUNT(*) cnt from t_ds_task_definition_log group by code ,version order by cnt desc |