以下是基于 JDK 8 的 LinkedList 深度源码解析,涵盖其数据结构、核心方法实现、性能特点及使用场景。我们从 类结构、Node节点、插入/删除/访问操作、线程安全、性能对比 等角度进行详细分析
一、类结构与继承关系
1. 类定义
java
public class LinkedList<E> extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.SerializableAbstractSequentialList:提供按顺序访问元素的默认实现(如get(int index)、set(int index, E element))。List:支持按索引操作(如add(int index, E element)、get(int index))。Deque:双端队列接口,支持头尾插入/删除(如addFirst()、removeLast())。Cloneable和Serializable:支持克隆和序列化。
.
二、核心数据结构:Node节点
1. Node类定义
java
private static class Node<E> {
E item; // 当前节点存储的元素
Node<E> next; // 指向下一个节点
Node<E> prev; // 指向前一个节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}- 双向链表特性 :每个节点通过
prev和next指针连接,支持双向遍历。 - 内存分配 :节点分散存储,不依赖连续内存(与
ArrayList的数组不同)。
.
三、构造方法详解
1. 无参构造函数
java
public LinkedList() {}- 初始化时
first和last均为null,size为 0,表示链表为空。
2. 带初始集合的构造函数
java
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}- 调用无参构造函数后,通过
addAll()方法将集合元素逐个添加到链表尾部。
.
四、插入操作详解
1. 尾部插入:add(E e)
java
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}- 关键步骤 :
- 获取当前尾节点
l - 创建新节点
newNode,其prev指向l,next为null。 - 更新
last为newNode。 - 如果链表为空
(l == null),则first和last均指向newNode。 - 否则,将原尾节点的
next指向newNode。 - 更新
size和modCount(结构修改计数器,用于迭代器的 fail-fast 机制)。
- 获取当前尾节点
2. 头部插入:addFirst(E e)
java
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}- 关键步骤 :
- 获取当前头节点
f。 - 创建新节点
newNode,其next指向f,prev为null。 - 更新
first为newNode。 - 如果链表为空
(f == null),则first和last均指向newNode。 - 否则,将原头节点的
prev指向newNode。
- 获取当前头节点
3. 中间插入:add(int index, E element)
java
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}- 关键步骤 :
- 检查索引合法性(
0 ≤ index ≤ size)。 - 如果
index == size,调用linkLast()插入尾部。 - 否则,调用
node(index)找到目标节点,再调用linkBefore()插入到该节点前。
- 检查索引合法性(
linkBefore(E e, Node succ)
java
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}- 关键步骤 :
- 获取目标节点
succ的前驱节点pred。 - 创建新节点
newNode,其prev指向pred,next指向succ。 - 更新
succ.prev为newNode。 - 如果
pred == null(即插入到头部),更新first。 - 否则,将
pred.next指向newNode。
- 获取目标节点
.
五、删除操作详解
1. 删除指定元素:remove(Object o)
java
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}- 关键步骤 :
- 遍历链表查找匹配的节点。
- 找到后调用
unlink(x)删除节点。
unlink(Node x)
java
E unlink(Node<E> x) {
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}- 关键步骤 :
- 获取被删除节点
x的前后节点prev和next。 - 如果
prev == null,说明x是头节点,更新first为next。 - 否则,将
prev.next指向next,并断开x.prev。 - 如果
next == null,说明x是尾节点,更新last为prev。 - 否则,将
next.prev指向prev,并断开x.next。 - 将
x.item置为null,帮助GC回收。 - 更新
size和modCount。
- 获取被删除节点
2. 删除头节点:removeFirst()
java
private E unlinkFirst(Node<E> f) {
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null;
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}- 关键步骤 :
- 获取头节点
f的item和next。 - 断开
f的引用(f.item = null、f.next = null)。 - 更新
first为next。 - 如果
next == null,说明链表为空,更新last为null。 - 否则,将
next.prev置为null。
- 获取头节点
.
六、访问操作详解
1. 按索引访问:get(int index)
java
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}-
关键步骤:
- 根据索引位置选择从头节点或尾节点开始遍历。
- 如果
index < size/2,从头节点向后遍历;否则,从尾节点向前遍历。 - 返回对应节点的
item。
-
时间复杂度 :
O(n),因为需要遍历链表。
.
七、线程安全与 Fail-Fast 机制
1. 线程不安全
LinkedList 不是线程安全的 ,多线程环境下可能导致数据不一致或 ConcurrentModificationException。
2. Fail-Fast 机制
- 通过
modCount记录结构修改次数(如add、remove)。 - 迭代器遍历时会检查
modCount是否与创建迭代器时的值一致。如果不一致,抛出ConcurrentModificationException。
示例代码
java
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
int expectedModCount = modCount;
public boolean hasNext() {
checkForComodification();
return cursor != size;
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}.
八、性能对比与使用建议
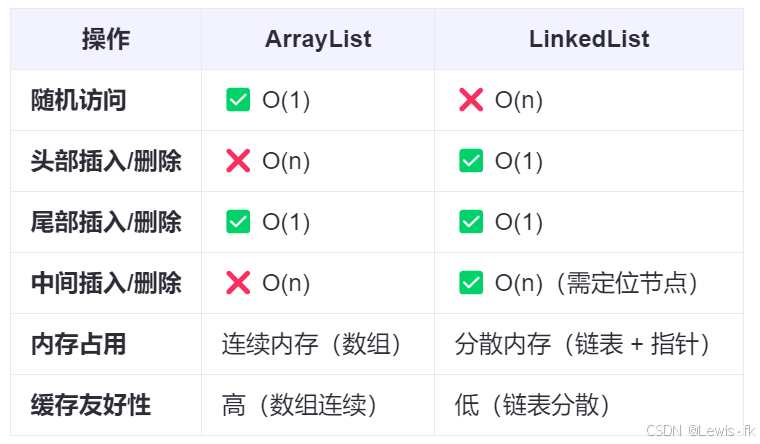
使用建议
- 频繁插入/删除 :优先使用
LinkedList(尤其是头部或尾部操作)。 - 频繁随机访问 :优先使用
ArrayList。 - 线程安全 :使用
Collections.synchronizedList(new LinkedList<>())或CopyOnWriteArrayList。 - 双端队列 :
LinkedList实现了Deque接口,可作为双端队列使用(如栈、队列)。
.
九、扩展学习建议
- 源码调试 :使用 IDE(如 IntelliJ IDEA)调试
LinkedList的add、remove、get方法,观察first、last、size的变化。 - 版本差异 :对比 JDK 8 和 JDK 21 的
LinkedList源码,观察是否引入新的优化(如Spliterator支持)。 - 进阶主题 :
LinkedList与Vector的区别(线程安全 vs 性能)。Deque接口的实现细节(如ArrayDeque与LinkedList的对比)。LinkedList在 JVM 内存模型中的表现(链表的离散性 vs 数组的连续性)。