使用apache amoro + trino+minio搭建iceberg数据湖架构
以下是基于 Apache Amoro + Trino + MinIO 搭建 Iceberg 数据湖架构的核心步骤和关键配置:
架构组件角色
- MinIO:提供兼容 S3 API 的云原生对象存储,作为 Iceberg 表的底层存储系统。官方文档:
- Apache Iceberg:表格式层,负责数据文件管理、ACID 事务支持及元数据版本控制。
- Apache Amoro :湖仓管理系统,提供表管理、自动优化(如小文件合并)及多引擎协调(Trino/Flink/Spark)。官方文档:https://amoro.apache.org/quick-start/
- Trino :分布式 SQL 查询引擎,用于高性能分析查询。官方文档:https://trino.io/docs/current/connector/iceberg.html
另外,此文章不包括ETL数据写入到apache iceberg,这一章需要应用 apache flink + DolphinScheduler(调度系统),请自行研究。
部署流程
以下是使用docker-compose搭建Apache Amoro、MinIO和Trino的集成环境方案,可用于日常开发环境。
确保已安装Docker 27.0.3 和Docker Compose。
把下面的yaml保存到docker-compose.yml的文件中:
version: "3"
services:
minio:
image: minio/minio
container_name: minio
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=password
- MINIO_DOMAIN=minio
networks:
amoro_network:
aliases:
- warehouse.minio
ports:
- 9001:9001
- 9000:9000
command: [ "server", "/data", "--console-address", ":9001" ]
amoro:
image: apache/amoro
container_name: amoro
ports:
- 8081:8081
- 1630:1630
- 1260:1260
environment:
- JVM_XMS=1024
networks:
amoro_network:
volumes:
- ./amoro:/tmp/warehouse
command: ["/entrypoint.sh", "ams"]
tty: true
stdin_open: true
trino:
image: trinodb/trino:419
container_name: trino
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
volumes:
- ./example.properties:/etc/trino/catalog/example.properties
networks:
amoro_network:
aliases:
- warehouse.trino
ports:
- 8080:8080
networks:
amoro_network:
driver: bridge接下来,在docker-compose.yml所在的目录下创建example.properties文件:
connector.name=iceberg
iceberg.catalog.type=rest
iceberg.rest-catalog.uri=http://<IP地址>:1630/api/iceberg/rest
iceberg.rest-catalog.warehouse=<amoro 创建的 iceberg catalog name>
fs.native-s3.enabled=true
s3.endpoint=http://<IP地址>:9000
s3.region=us-east-1
s3.aws-access-key=admin
s3.aws-secret-key=password最后一步骤:使用以下命令启动docker容器:
docker-compose up -d启动之后,trino容器可能会出现启动失败。不要着急,接下来将amoro配置完,重启容器即可。
配置
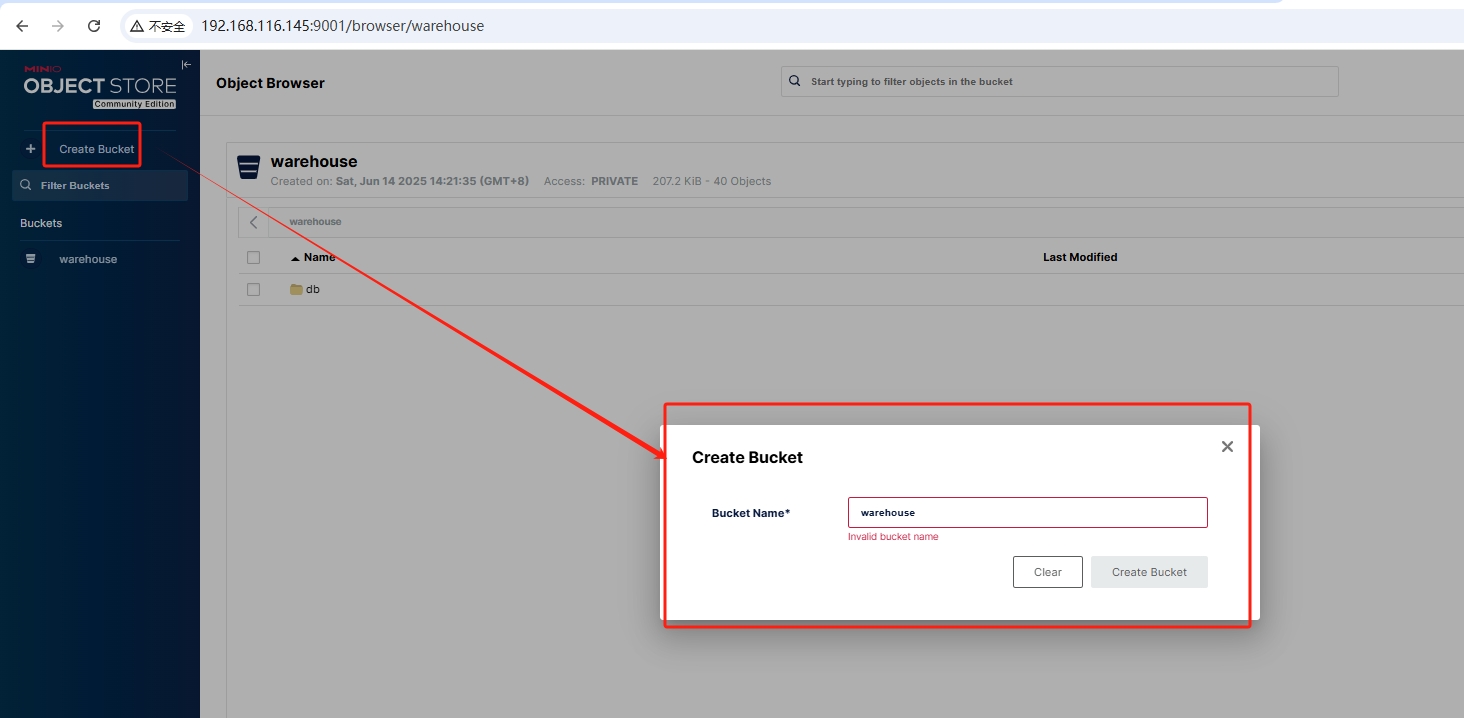
minio 创建 bucket
打开http://localhost:9000在浏览器中,输入admin/password登录minio界面。
amoro 配置
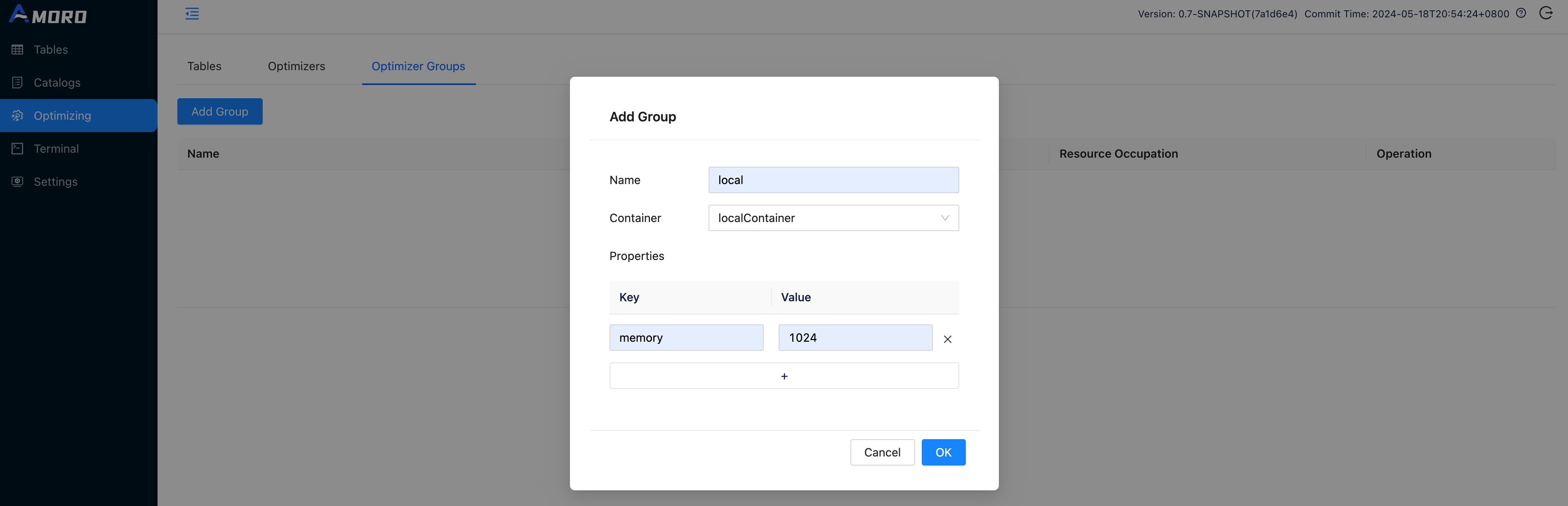
Create optimizer group
Open http://localhost:1630 in a browser, enter admin/admin to log in to the dashboard.
Click on Optimizing in the sidebar, choose Optimizer Groups and click Add Group button to create a new group befre creating catalog
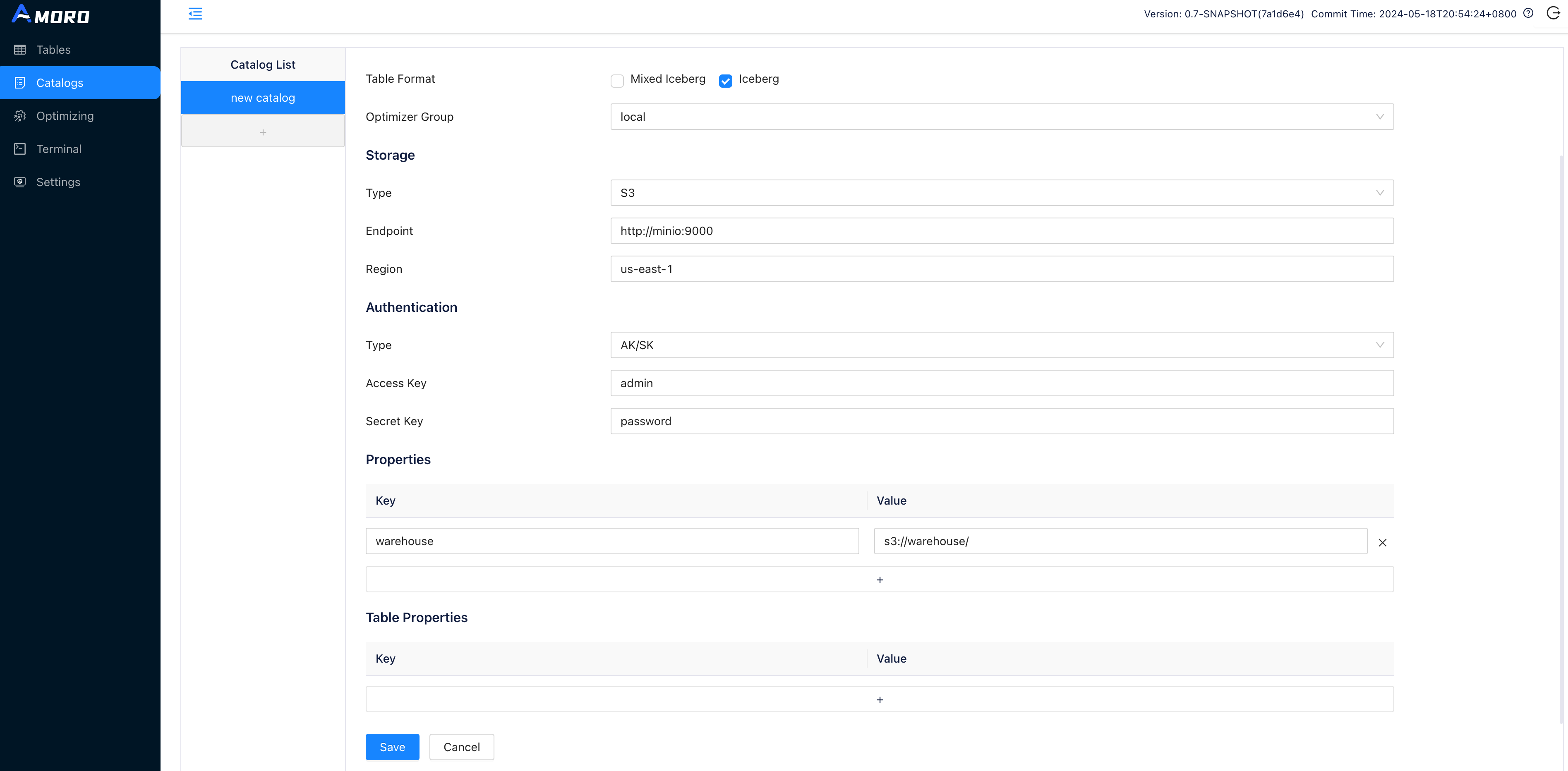
Create catalog
Click on Catalogs in the sidebar, click on the + button under Catalog List to create a test catalog, and name it to demo_catalog:
o use the Iceberg Format, select Type as Internal Catalog, and choose Iceberg as Table Format.
按照上面配置的,修改example.properties文件。然后执行以下命令:
docker stop tirno
docker rm trino
docker-compose up trinoDemo steps
Initialize tables
Click on amoro system Terminal in the sidebar, you can create the test tables here using SQL. Terminal supports executing Spark SQL statements for now.
CREATE DATABASE IF NOT EXISTS db;
CREATE TABLE IF NOT EXISTS db.tb_users (
id INT,
name string,
ts TIMESTAMP
) USING iceberg
PARTITIONED BY (days(ts));
INSERT OVERWRITE db.tb_users VALUES
(1, "eric", timestamp("2022-07-01 12:32:00")),
(2, "frank", timestamp("2022-07-02 09:11:00")),
(3, "lee", timestamp("2022-07-02 10:11:00"));
SELECT * FROM db.user;Click on the RUN button uppon the SQL editor, and wait for the SQL query to finish executing. You can then see the query results under the SQL editor.
Initialize tables
start up the docker containers with this command:
docker exec -it tirno trino
trino> show catalogs;
Catalog
---------
example
jmx
memory
system
tpcds
tpch
(6 rows)
trino> show schemas in example;
Schema
--------------------
db
information_schema
(2 rows)
trino> show tables in example.db;
Table
-------
tb_users
(1 row)
trino> select * from example.db.tb_users;
id | name | ts
----+-------+--------------------------------
1 | eric | 2022-07-01 12:32:00.000000 UTC
2 | frank | 2022-07-02 09:11:00.000000 UTC
3 | lee | 2022-07-02 10:11:00.000000 UTC
(3 rows)到此为止,我们的架构就搭建完成。
关键注意事项
- 首次启动需在Amoro中创建MinIO存储配置
- Trino查询前需在Amoro中创建表并同步元数据
- 生产环境建议配置持久化卷和网络隔离