1. Callback 功能介绍
Callback 是 LangChain 提供的回调机制,允许我们在 LLM 应用程序的各个阶段使用 hook (钩子)。钩子的含义也非常简单,我们把应用程序看成一个一个的处理逻辑,从开始到结束,钩子就是在事件传送到终点前截获并监控事件的传输。
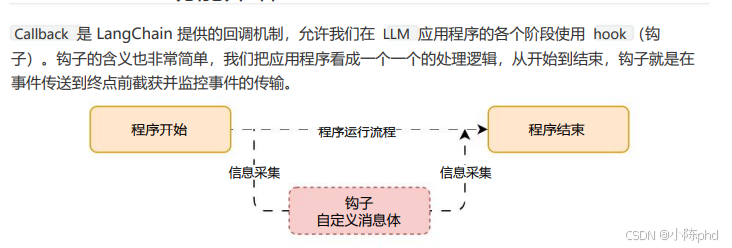
Callback 对于记录日志、监控、流式传输等任务非常有用,简单理解, Callback 就是记录整个流程的运行情况的一个组件,在每个关键的节点记录响应的信息以便跟踪整个应用的运行情况。
例如:
- 在 Agent 模块中调用了几次 tool,每次的返回值是什么?
- 在 LLM 模块的执行输出是什么样的,是否有报错?
- 在 OutputParser 模块的输出解析是什么样的,重试了几次?
Callback 收集到的信息可以直接输出到控制台,也可以输出到文件,更可以输入到第三方应用,相当于独立的日志管理系统,通过这些日志就可以分析应用的运行情况,统计异常率,运行的瓶颈模块以便优化。在 LangChain 中,callback 模块中具体实现包括两大功能,对应 CallbackHandler 和CallbackManager 。 - CallbackHandler:对每个应用场景比如 Agent 或 Chain 或 Tool 的纪录。
- CallbackManager:对所有 CallbackHandler 的封装和管理,包括了单个场景的 Handle,也包括运行时整条链路的 Handle。不过在 LangChain 的底层,这些任务的执行逻辑由回调处理器( CallbackHandler )定义。
CallbackHandler 里的各个钩子函数的触发时间如下:
以下是 LangChain Callback 事件机制 中常见的事件及其对应的触发时机和方法名称的完整表格,适用于实现自定义的CallbackHandler:
| 事件名称 | 事件触发时机 | 相关方法(Callback 方法名) |
|---|---|---|
| Chat Model Start | 当聊天模型(如 ChatOpenAI)开始执行时 | on_chat_model_start |
| LLM Start | 当大语言模型(如 OpenAI、Anthropic)开始执行时 | on_llm_start |
| LLM New Token | 当 LLM 生成新 token(流式输出)时 | on_llm_new_token |
| LLM End | 当 LLM 执行结束时 | on_llm_end |
| LLM Error | 当 LLM 执行出错时 | on_llm_error |
| Chain Start | 当整个链(Chain)开始运行时 | on_chain_start |
| Chain End | 当整个链运行结束时 | on_chain_end |
| Chain Error | 当链运行出错时 | on_chain_error |
| Tool Start | 当工具(Tool)开始执行时 | on_tool_start |
| Tool End | 当工具执行结束时 | on_tool_end |
| Tool Error | 当工具执行出错时 | on_tool_error |
| Agent Action | 当 Agent 执行某个动作(如调用工具)时 | on_agent_action |
| Agent Finish | 当 Agent 执行完毕(完成任务)时 | on_agent_finish |
| Retriever Start | 当 Retriever(检索器)开始工作时 | on_retriever_start |
| Retriever End | 当 Retriever 检索结束时 | on_retriever_end |
| Retriever Error | 当 Retriever 出错时 | on_retriever_error |
| Text | 任意文本输出事件(用于自定义链、Tool、Agent 的输出) | on_text |
| Retry | 当某个组件(如 LLM、Tool)触发重试机制时 | on_retry |
在 LangChain 中使用回调,使用 CallbackHandler 几种方式:
- 在运行 invoke 时传递对应的 config 信息配置 callbacks(推荐)。
- 在 Chain 上调用 with_config 函数,传递对应的 config 并配置 callbacks(推荐)。
- 在构建大语言模型时,传递 callbacks 参数(不推荐)。
在 LangChain 中提供了两个最基础的 CallbackHandler,分别是: StdOutCallbackHandler 和
FileCallbackHandler 。
使用示例如下:
python
import dotenv
from langchain_core.callbacks import StdOutCallbackHandler
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
# 1.编排prompt
prompt = ChatPromptTemplate.from_template("{query}")
# 2.创建大语言模型
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
# 3.构建链
chain = {"query": RunnablePassthrough()} | prompt | llm | StrOutputParser()
# 4.调用链并执行
content = chain.stream( "你好,你是?", config={"callbacks": [StdOutCallbackHandler()]}
)
for chunk in content: pass自定义回调
在 LangChain 中,想创建自定义回调处理器,只需继承 BaseCallbackHandler 并实现内部的部分接口即可,例如:
python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import time
from typing import Dict, Any, List, Optional
from uuid import UUID
import dotenv
from langchain_core.callbacks import StdOutCallbackHandler, BaseCallbackHandler
from langchain_core.messages import BaseMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.outputs import LLMResult
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
class LLMOpsCallbackHandler(BaseCallbackHandler):
"""自定义LLMOps回调处理器"""
start_at: float = 0
def on_chat_model_start(
self,
serialized: Dict[str, Any],
messages: List[List[BaseMessage]],
*,
run_id: UUID,
parent_run_id: Optional[UUID] = None,
tags: Optional[List[str]] = None,
metadata: Optional[Dict[str, Any]] = None,
**kwargs: Any,
) -> Any:
print("聊天模型开始执行了")
print("serialized:", serialized)
print("messages:", messages)
self.start_at = time.time()
def on_llm_end(
self,
response: LLMResult,
*,
run_id: UUID,
parent_run_id: Optional[UUID] = None,
**kwargs: Any,
) -> Any:
end_at: float = time.time()
print("完整输出:", response)
print("程序消耗:", end_at - self.start_at)
# 1.编排prompt
prompt = ChatPromptTemplate.from_template("{query}")
# 2.创建大语言模型
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
# 3.构建链
chain = {"query": RunnablePassthrough()} | prompt | llm | StrOutputParser()
# 4.调用链并执行
resp = chain.stream(
"你好,你是?",
config={"callbacks": [StdOutCallbackHandler(), LLMOpsCallbackHandler()]}
)
for chunk in resp:
pass