系列文章:
5、音视频之H.264/AVC解码器的原理和实现
H.264包含视频编码层(VCL)和网络提取层(NAL)。 VCL包括核心压缩引擎和块、宏块及片的语法级别的定义,它的设计目标是尽可能地独立于网络的情况下进行高效地编解码;而NAL则负责将VCL产生的比特字符串适配到各种各样的网络环境中,它覆盖了所有片级别以上的语法级别,同时支持以下功能:支持独立片解码,起始码唯一保证,支持SEI,支持流格式编码数据传送。
一、解码器原理:
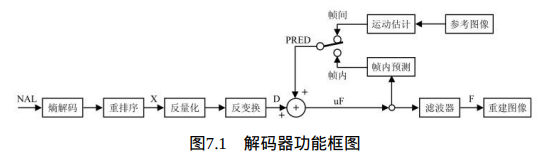
NAL解码器负责将符合H.264码流规范的压缩视频流解码, 并进行图像重建。根据如图7.1所示的解码器,我们可以看出基本的解码流程如下:解码器从NAL中接收压缩的比特流,经过对码流进行熵解码和重排序获得一系列量化系数X;这些系数经过反量化和反变换得到残差数据D;解码器使用从码流中解码得到的头信息创建一个预测块PRED,PRED与残差数据D求和得到图像块数据uF;最后每个uF通过去方块滤波得到重建图像的解码块F。
为更清晰的描述解码器的工作流程,我们用图7.2所示的流程图来描述 一帧图像的完整解码过程。
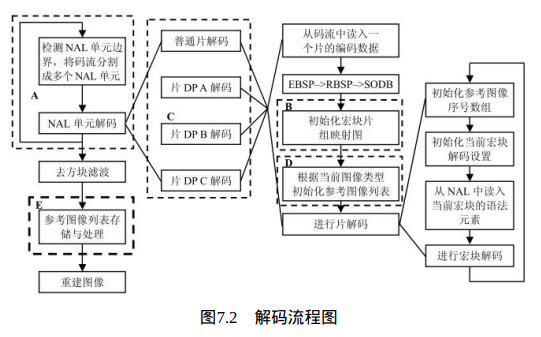
在图7.2中,A框中的NAL单元边界检测和单元解码在第二节中描述,
第三节中将详细介绍解码过程中所使用到的一个重要参数和参考图像序列号 (POC)的计算方法;
第四节将阐述B框中宏块片组映射图的产生过程;
第五节将阐述C框中的片数据分割的解码过程描述,
第六和第七节将详细介绍D框中的参考图像列表初始化和E框中参考图像存储和列表后处理等过程。
二、NAL单元:
早期的视频压缩标准总是集中于比特流的概念,高层语法元素被编码分割,以允许比特流发生误码时进行重同步。
而在H.264/AVC标准中, NAL(Network Abstract Layer)则是以NALU(NAL Unit)为单元来支持编码数据在基于包交换技术网络中传输的。它定义了符合传输层或存储介质要求的数据格式,同时给出头信息,从而提供了视频编码与外部世界的接口。网络层和传输层的RTP封装只针对基于NAL单元的本地NAL接口,且每个NAL单元都只包含整数个字节。
1、NAL单元结构:
一个NAL单元定义了可用于基于分组和基于比特流系统的基本格式, 区别这两种格式的方法在于每个比特流传输层都有一个起始代码。在NAL解码器接口,它假定按传输顺序传递NALU,同时,在NALU的头部设置标识接收正确的、丢失的或错误的标识位,如果在有效载荷中包含位错误, 则通过标识位来标志。
每一个NAL单元都包含两个部分:一个字节的NAL Header和一个原始字节序列载荷RBSP(Raw Byte Sequence Payload),如图7.3所示。
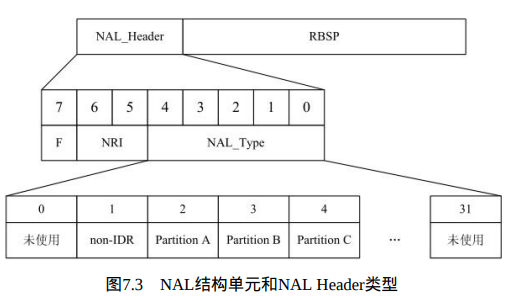
RBSP可以是一个编码片、A/B/C型数据分片、序列参数集、图像参数集等。NAL Header为一个字节,由定长的三部分组成:NAL类型(NAL_Type)、隐藏比特位(F)和NAL-REFERENCE-IDC(NRI)。
NAL_Type:
其中的NAL_Type有5位, 取值范围是0~31,标识本单元内的RBSP数据结构的类型。
RBSP区分:
根据RBSP的类型,NAL单元分为VCL-NAL单元和非VCL-NAL单元。前者的NAL_Type等于1~5,包含图像采样值的数据,具体来说,当NAL_Type=1表示非IDR的片,NAL_Type=1表示Partition A,NAL_Type=2和3分别表示Partition B和 Partition C。
NRI:
NRI用于在重构过程中标记一个NAL单元的重要性,值为0表示这个NAL单元没有用于预测,因此可被解码器抛弃而不会有错误扩散;值高于0表示此NAL单元要用于无漂移重构,且值越高,对此NAL单元丢失的影响越大。
隐藏比特位:
最后是隐藏比特位,在H.264编码中默认置为0,当网络识别到单元中存在比特错误时,可将其置为1。F位主要用于适应不同种类的网络环境(比如有线无线相结合的环境)。例如对于从无线到有线的网关,一边是无线的非IP协议环境,一边是有线网络的无比特错误的环境。假设一 个NAL单元到达无线那边时,校验和检测失败,网关可以选择从NAL流中去掉这个NALU单元,也可以把已知被破坏的NAL单元前传给接收端。在这种情况下,智能的解码器将尝试重构这个NAL单元(已知它可能包含比特错误)。而非智能的解码器将简单的抛弃这个NAL单元。
2、NAL单元解码过程:
在进行NAL单元解码之前,首先或者通过RTP解析(采用RTP封装), 或者通过起始码检测(采用比特流方式),从传输码流中获取NAL单元数据。
NAL解码流程:
NAL单元解码的总体流程是:
- 首先从NAL单元中提取出RBSP语法结构;
- 然后按照如图7.4所示的流程处理RBSP语法结构。
图7.4 NAL单元解码
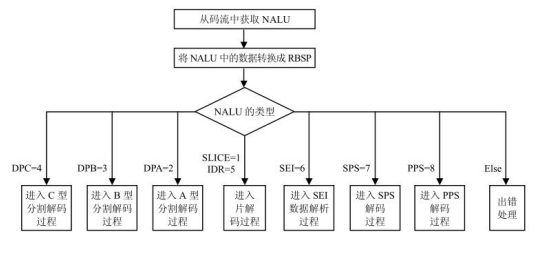
因此对于NAL单元的解码过程,其输入是NAL单元,输出结果是经过解码的当前图像 (CurrPic)的样点值。在H.264规范文档中规定:对于同一码流,所有的解码器必须产生数值上相同的结果,且必须符合规范定义的解码过程的标准。
在图7.4中,类型为7、8的NAL单元中分别包含了序列参数集 和图像参数集 。图像参数集和序列参数集在其他数据NAL单元的解码过程中作为参数使用,在这些数据NAL单元的片头中,通过语法元素 pic_parameter_set_id设置它们使用的图像参数集编号;而相应的每个图像参数集中,通过语法元素seq_parameter_set_id设置它所使用的序列参数集编号。
三、图像序列号的计算:
1、图像序列号(POC):
在H.264中,图像序列号(POC,Picture Order Count)主要用于标识图像的播放顺序,同时还用于帧间预测片的解码过程时,标记参考图像的初始图像序号,表明下列情况下帧或场之间的图像序号差别:时域直接预测模式的运动矢量推导过程时,B片的显式加权预测时,解码器一致性检测时。
对于每个编码帧、编码场和编码场对都要产生图像序列号信息。具体过程如下:
- (1)对于每个编码帧有两个图像序列号,分别称为顶场序列号 (TopFieldOrderCnt)和底场序列号(BottomFieldOrderCnt);
- (2)对于每个编码场有一个图像序列号,对于一个编码顶场,其称为 TopFieldOrderCnt,对于编码底场,其称为BottomFieldOrderCnt;
- (3)对于每个编码场对有两个图像序列号,TopFieldOrderCnt和 BottomFieldOrderCnt分别用于标记该场对的顶场和底场。
TopFieldOrderCnt 和BottomFieldOrderCnt分别指明了相应的顶场/底场相对于前一个IDR图像(或解码顺序中前一个包含 memory_management_control_operation=5的参考图像)的第一个输出场的相对位置。
POC类型:
由于H.264使用了B帧预测,使得图像的解码顺序并不一定等于播放顺序,但它们之间存在一定的映射关系。H.264中一共定义了三种POC的编码方法,句法元素pic_order_cnt_type就是用来通知解码器该用哪种方法来计算POC,下面我们称之为POC类型。
POC类型计算流程:
TopFieldOrderCnt和 BottomFieldOrderCnt根据当前序列参数集中的语法元素pic_order_cnt_type(POC类型)的值不同,按照如图7.5所示的计算流程获得。
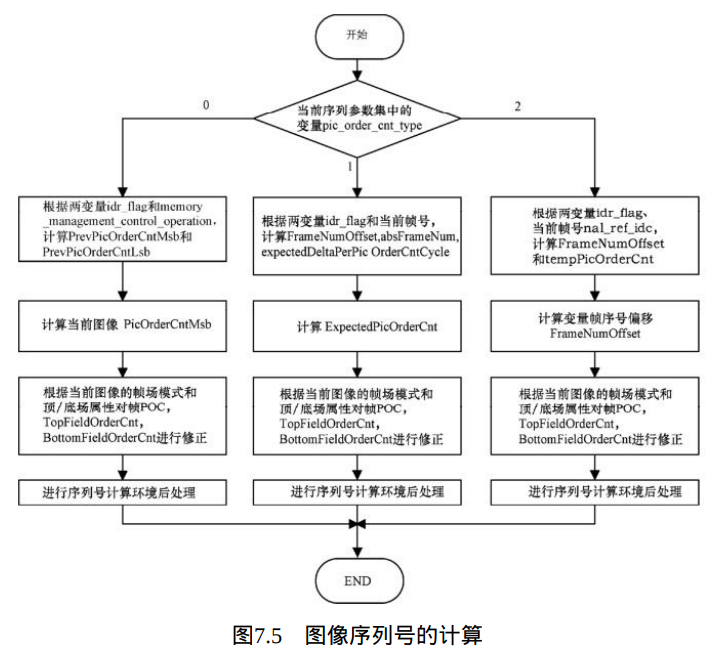
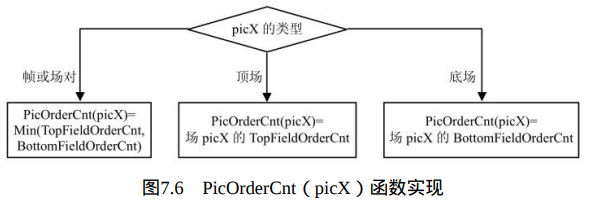
如当前图像的语法元素memory_management_control_operation等于5时,在当前图像解码完成后,进行图像序列号的重新初始化操作,即将顶场和底场的POC均减去PicOrderCnt(CurrPic)。CurrPic标志当前图像。函数 PicOrderCnt()的实现方法如图7.6所示。
对于图像序列号POC,H.264规定在H.264码流中不会出现下列情况:
- (1)一个IDR帧的Min(TopFieldOrderCnt, BottomFieldOrderCnt)不等于0;
- (2)一个IDR顶场的TopFieldOrderCnt不等于0;
- (3)一个IDR底场的BottomFieldOrderCnt不等于0。
因此,对于一个编码IDR帧的两个场,TopFieldOrderCnt和BottomFieldOrderCnt中至少有一个等于0。
同时,H.264规定码流中不允许存在导致TopFieldOrderCnt、 BottomFieldOrderCnt、PicOrderCntMsb或FrameNumOffset超出~
的范围的数据。
如我们使用DiffPicOrderCnt(picA, picB)表明两幅图像播放的时间间隔,即DiffPicOrderCnt(picA, picB)=PicOrderCnt(picA)- PicOrderCnt(picB),这样码流中的所有数据必须满足DiffPicOrderCnt(picA, picB)的取值范围为 ~
。理由如下:假设X是当前图像,Y和Z是同一序列中的另两个图像,Y和Z被认为是从X起始的,具有相同输出顺序方向,当DiffPicOrderCnt(X,Y)和DiffPicOrderCnt(X,Z)均为正或负时,其和不能超出
~
的范围。
根据当前图像性质的不同,其使用的图像序列号POC会有所区别,因此使用函数PicOrderCnt(picX)标记图像picX的图像序列号,很多应用中 PicOrderCnt(X)正比于图像X的采样时间与IDR采样时间的差值,其函数如图7.6中定义。
下面我们分别介绍POC类型分别为0、1和2的情况下,POC的计算过程。
2、POC类型为0的POC计算:
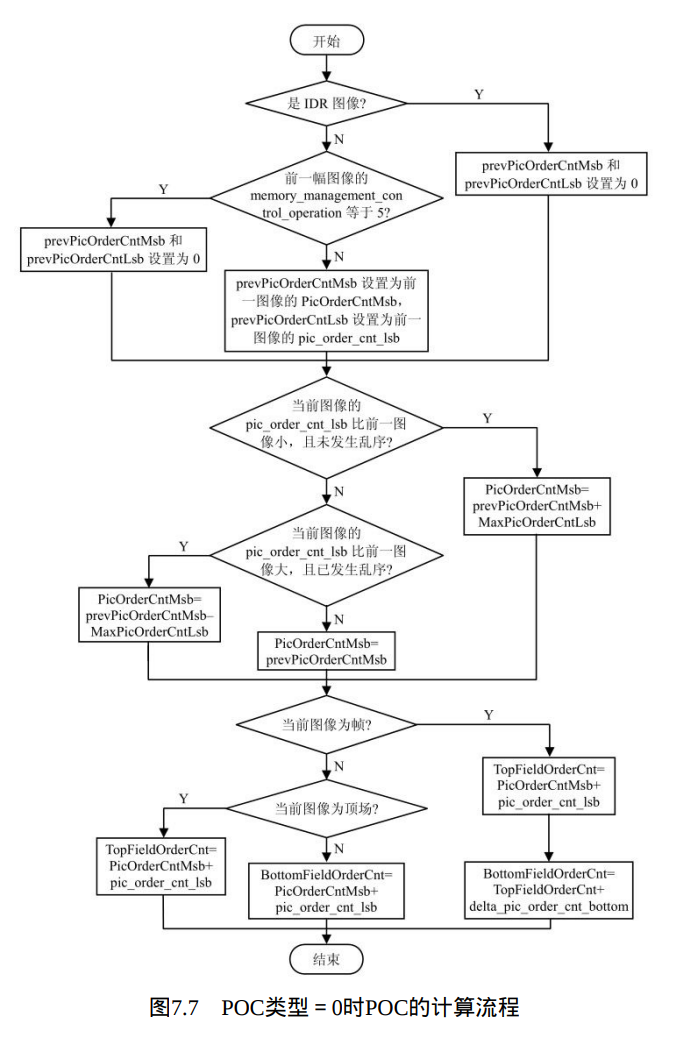
当pic_order_cnt_type等于0时,基于前一个参考图像(按照解码顺序)的PicOrderCntMsb可以用来计算当前图像的TopFieldOrderCnt和 BottomFieldOrderCnt,或者其中之一。首先计算变量 prevPicOrderCntMsb(前一个参考图像的PicOrderCntMsb),然后计算当前图像的PicOrderCntMsb,最后计算当前图像的TopFieldOrderCnt和(或) BottomFieldOrderCnt。具体的计算流程如图7.7所示。
3、POC类型为1的POC计算:
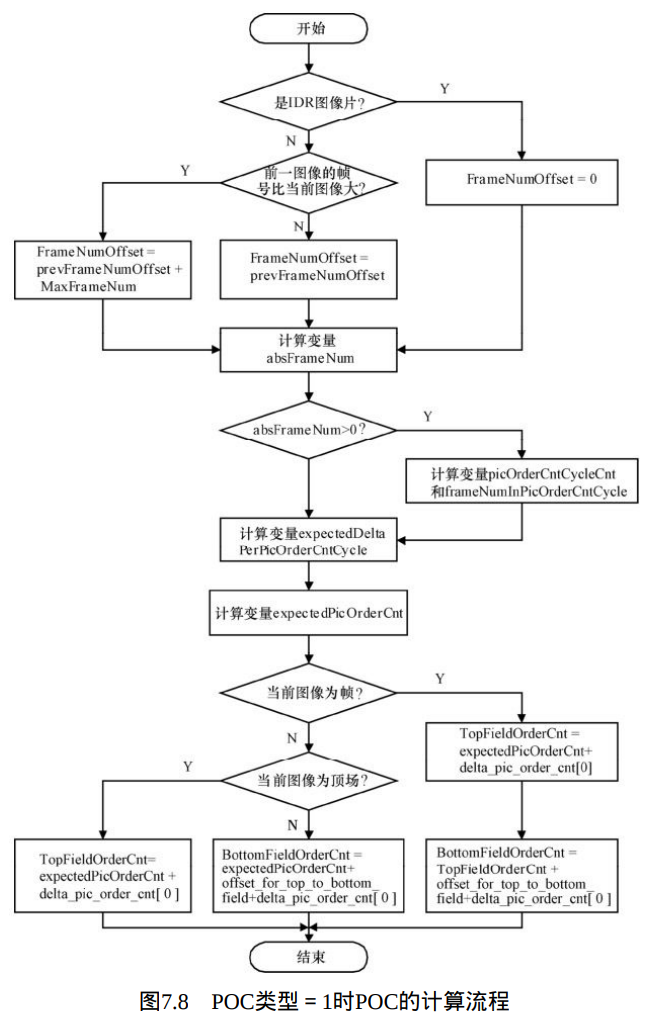
当pic_order_cnt_type等于1时,基于前一图像(按照解码顺序)的FrameNumOffset可以用来计算当前图像的TopFieldOrderCnt和 BottomFieldOrderCnt,或者其中之一,计算流程如图7.8所示。计算过程中涉及两个变量prevFrameNum和prevFrameNumOffset,其中prevFrameNum是前一图像的frame_num,而对于prevFrameNumOffset,如当前图像不是IDR,而前一图像的memory_management_control_operation等于5时, prevFrame NumOffset设为0;否则,prevFrameNumOffset设置为等于前一图像的FrameNumOffset。
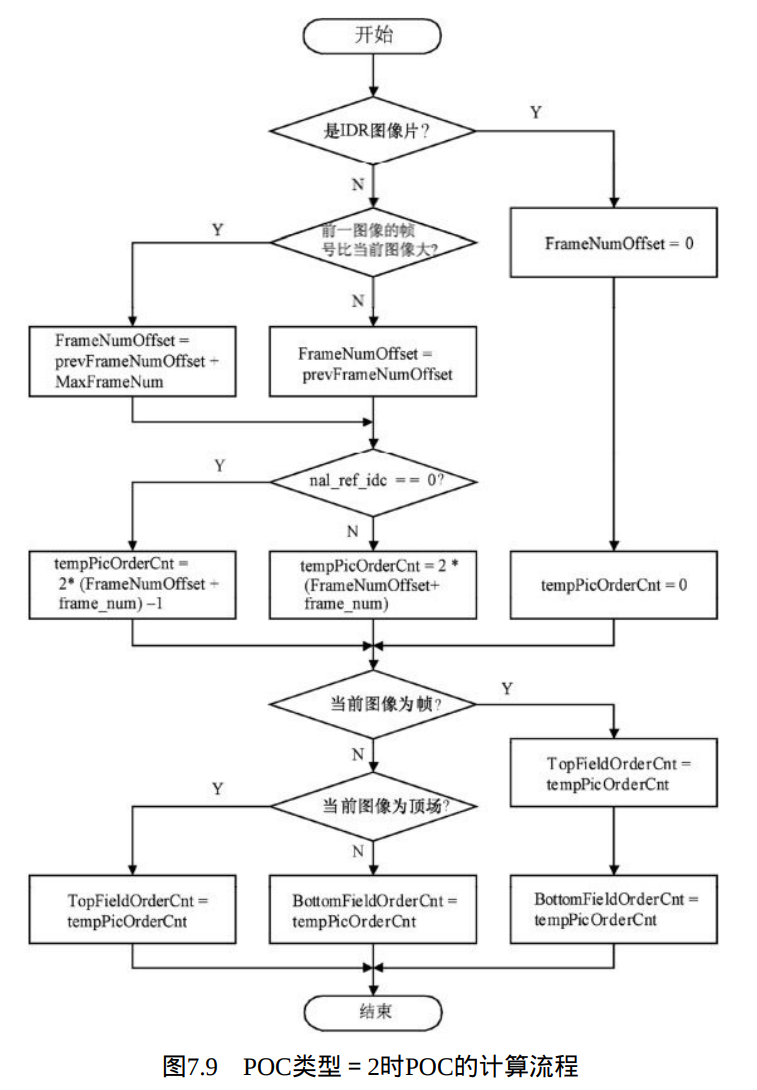
4、POC类型为2的POC计算:
当pic_order_cnt_type等于2时,TopFieldOrderCnt和BottomFieldOrderCnt 或者其中之一的计算流程如图7.9所示。POC类型2不能用于包含连续非参考图像的序列中,且解码结果导致输出的顺序与解码顺序相同。流程图中prevFrameNum表示按照解码顺序的前一图像的frame_num。如当前图像不是IDR图像,而前一图像的memory_management_control_operation等于5时,prevFrameNumOffset设为0;否则,prevFrameNumOffset设置为等于前一图像的FrameNumOffset。
四、宏块片组映射图的产生:
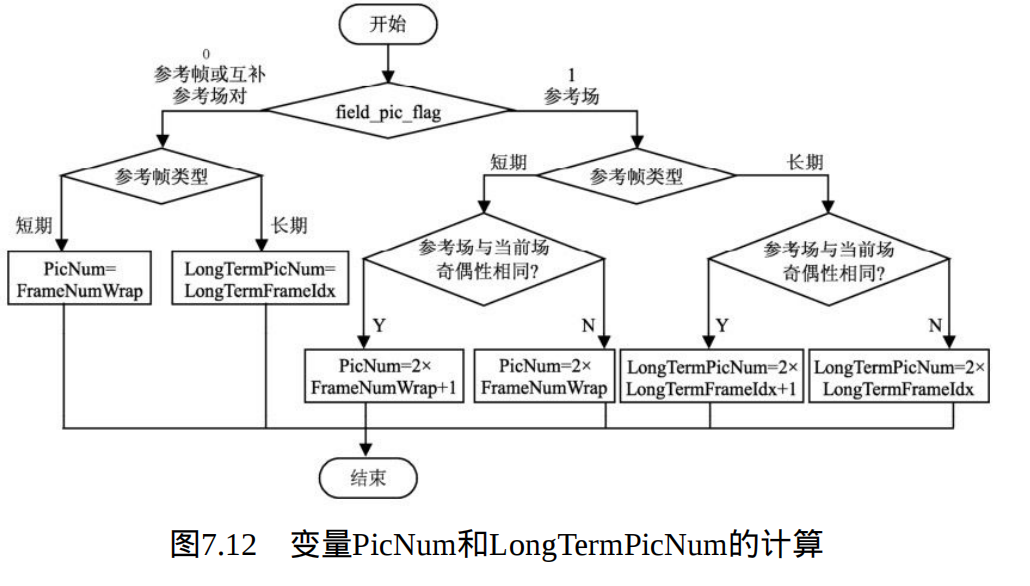
解码器在对每个片解码之前,首先需要基于当前有效图像参数集和需解码的片头,产生宏块片组映射图变量MbToSliceGroupMap,且此变量对于一个接入单元中的所有片均有效。当num_slice_groups_minus1等于1而且 slice_group_map_type等于3、4或5时,片组0和1的大小和形状的选择见表 7.1,由slice_group_change_direction_flag确定。
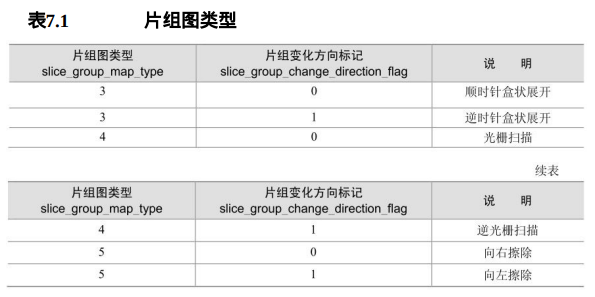
此时,按照定义的增长顺序的片组图单元MapUnitsInSliceGroup0被分配给片组0,剩余的片组图单元PicSizeInMapUnits--MapUnitsInSliceGroup0被分配给片组1。
当num_slice_groups_minus1等于1且slice_group_map_type等于4或5时, 标记左上片组大小的变量sizeOfUpperLeftGroup这样定义:当片组变化方向标记=1时,该变量等于PicSizeInMapUnits-MapUnitsInSliceGroup0,否则等于MapUnitsInSliceGroup0。
流程图7.10给出了变量mapUnitToSliceGroupMap的计算方法。
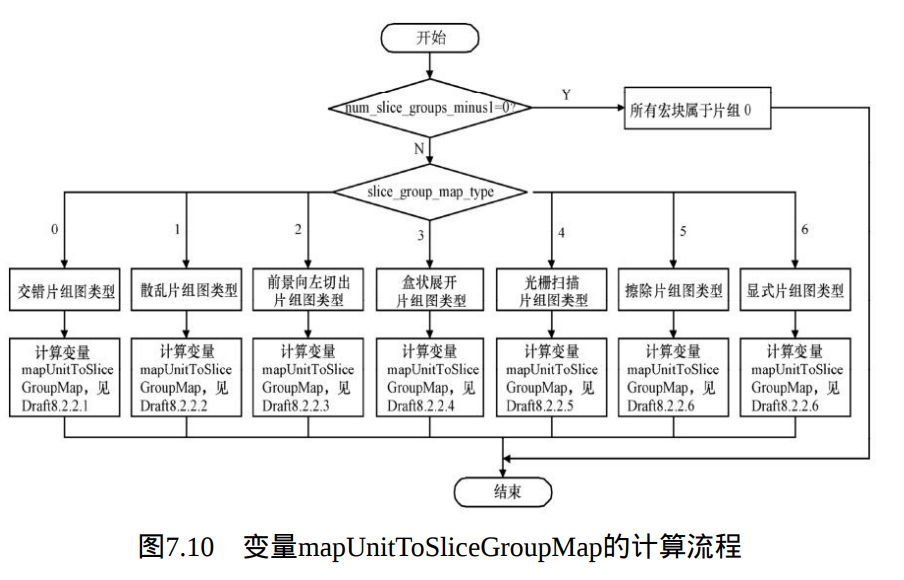
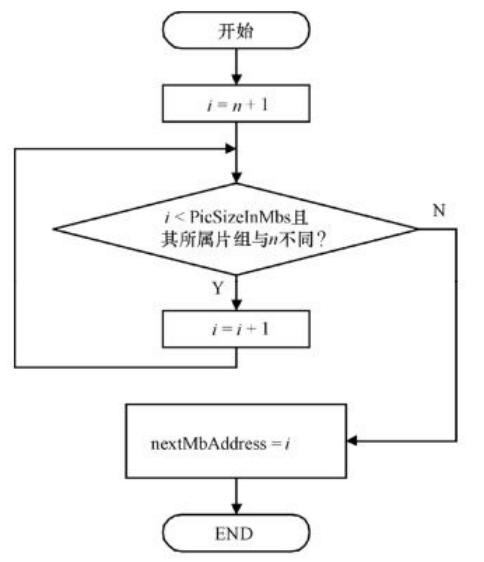
计算出mapUnitToSliceGroupMap后,会调用下面将要描述的片组图单元转换成宏块片组图的过程,将片组图单元mapUnitToSliceGroupMap转换成宏块片组映射图MbToSliceGroupMap。完成转换后,调用函数NextMbAddress(n)计算变量nextMbAddress,函数流程如图7.11所示。
图7.11 函数NextMbAddress(n)的流程
片组图单元mapUnitToSliceGroupMap转换成宏块片组映射图 MbToSliceGroupMap的过程规定如下:
如果frame_mbs_only_flag等于1或field_pic_flag等于1,宏块片组图设置为:
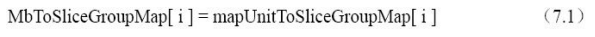
如果MbaffFrameFlag等于1,宏块片组图设置为:

否则(即frame_mbs_only_flag等于0且mb_adaptive_frame_field_flag等于 0且field_pic_flag等于0),宏块片组图设置为:
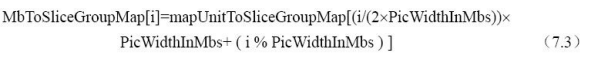
其中,i表示从0到PicSizeInMbs-1的每个值。
五、片数据分割的解码:
在H.264的扩展档次中,会引入数据分割的特性。当使用数据分割时, 解码器会根据输入的片数据分割RBSP来产生一个完整的编码片。片数据分割RBSP至少包括一个片的A型数据分割RBSP (NAL类型为2),或者还有一个属于同一片的B型数据分割RBSP(NAL类型为3)或一个属于同一片的 C型数据分割RBSP(NAL类型为4)。
当不使用片数据分割时,未数据分割的RBSP编码片包含一个片头,片头后是包含片中宏块数据的(NAL分类2、3、4)所有语法元素在内的一个片数据语法结构。
当使用片数据分割时,片中的宏块数据分割成1~3个分割块,封装到 各自单独的NAL单元中。
- 分割块A包括一个片数据分割A头部和所有的第2类语法元素。
- 分割块B包括一个片数据分割B头部和所有的第3类语法元素。
- 分割块C包括一个片数据分割C头部和所有的第4类语法元素。
其中,
- 第2类包含了所有其他的宏块解码相关的语法元素,这些信息通常称为头信息。
- 第3类语法元素与I和SI宏块类型的残差数据的解码有关。
- 第4类语法元素与P和B宏块类型的残差数据的解码有关。
片数据分割A的头部包含了片头的所有语法元素,还有一个slice_id用于关联相应的分割B和分割C。分割B和C的头只包含slice_id,用于建立与相应得分割A的联系。
当使用数据分割时,每类语法元素从单独的NAL单元中解析出来,如某类语法元素不存在,则相应的NAL单元不需出现。此时片数据分割的解析过程与没有分割RBSP类似,只需根据片数据分割的类型读出相应的语法元素。
六、参考图像列表的初始化
解码器在对每个P、SP或B片解码之前,需要进行参考图像列表的初始化,从而生成参考图像列表RefPicList0,当对B片解码时,还将生成另一个参考图像列表RefPicList1。
在参考图像列表中,解过码的参考图像根据码流的规定被标记成"用于短期参考"或"用于长期参考"。其中,短期参考图像使用frame_num 的值作为标识,而长期参考图像则被分配一个长期参考帧索引,根据码流中的语法元素设定。
下面将对如下几点进行描述:
- 对每个短期参考图像,变量FrameNum、FrameNumWrap和PicNum如何计算并赋值;
- 长期参考图像的变量LongTermPicNum如何计算并赋值。
参考图像通过参考索引来进行标志。一个参考索引是一个变量PicNum 和LongTermPicNum 的数组下标,此数组称为参考图像列表。
如果RefPicListXi使用LongTermPicNum(对于一个长期参考图像),将LongTermEntry( RefPicListXi) 设置为1;如果RefPicListXi使用PicNum(对于一个短期参考图像),则设为0。其中RefPicListX[i]标记参考图像列表X的第i个分量,其中X=0或1。
在每个片开始解码时,参考图像列表RefPicList0,对于B片的RefPicList1如下处理:
- 初始参考列表 RefPicList0 和 B 片的 RefPicList1 根据 6.2 节中的描述计算;
- 初始参考列表 RefPicList0 和 B 片的 RefPicList1 根据 6.3 节中的描述调整。
参考图像列表RefPicList0的下标分量有num_ref_idx_l0_active_minus1+1个,B片的RefPicList1下标分量有num_ref_idx_l1_active_minus1+1个。一个参考图像可在RefPicList0或RefPicList1中出现一次以上。
1、图像序号的计算:
变量FrameNum、FrameNumWrap、PicNum、LongTermFrameIdx和LongTermPicNum用于参考图像列表的初始化过程(详见6.2节)、调整过程(详见6.3节)和解码参考图像标记过程(详见7节)。
对于每个短期参考图像,变量FrameNum和FrameNumWrap的计算过程如下。
- 首先,FrameNum设置成相应短期参考图像的片头中解码所得的语法元素frame_num;
- 然后计算变量FrameNumWrap值:如FrameNum大于当前图像片头中的frame_num,则FrameNumWrap等于FrameNum减去MaxFrameNum;
- 否则FrameNumWrap等于FrameNum。
对于每个长期参考图像,变量LongTermFrameIdx按照7节中的方法计算。
对于每个短期参考图像,分配一个 PicNum 变量;对于每个长期参考图像,分配一个LongTermPicNum变量。这些变量的值由当前图像的field_pic_flag和 bottom_field_flag 的值决定,它们的设置见图 7.12 。
2、参考图像列表的初始化:
解码器在对P、SP或B片片头解码时进行参考图像列表的初始化,生成初始化的参考图像列表RefPicList0,和B片解码时所需的RefPicList1。RefPicList0和RefPicList1的各分量使用变量PicNum和LongTermPicNum初始化, 具体方法见下面所述。
当产生的RefPicList0或RefPicList1中的分量个数分别大于num_ref_idx_l0_active_minus1+1或num_ref_idx_l1_active_minus1+1时,多余的分量将从列表中丢弃;如果情况相反,分量个数分别小于num_ref_idx_l0_active_minus1+1或num_ref_idx_l1_active_minus1+1时,将剩下的初始参考图像列表中的分量设置为"非参考图像"。
帧中P和SP片的参考帧列表的初始化:
解码器在对一个编码帧中的P或SP片解码之前通过参考帧列表的初始化生成RefPicList0。
参考图像列表RefPicList0 被排序,从而使短期参考帧和短期互补参考场对的索引值位于长期参考帧和长期互补参考场对之前。同时,短期参考帧和短期互补参考场对根据PicNum 值进行降序排列,长期参考帧和长期互补参考场对根据LongTermPicNum 值进行升序排列。同时在 H.264 中对帧进行解码时,不论MbaffFrameFlag 取什么值,帧间预测不使用不成对的参考对。
例如,当3 个参考帧使用 PicNum = 300 、 302 、 303 标记为 " 用于短期参考" ,两个参考帧使用 LongTermPicNum = 0 和 3 时,标记为 " 用于长期参考 " :
RefPicList00 设置为 PicNum = 303
RefPicList01 设置为 PicNum = 302,
RefPicList02 设置为 PicNum = 300,
RefPicList03 设置为 LongTermPicNum = 0,
RefPicList04 设置为 LongTermPicNum = 3 。
且LongTermEntry(RefPicList0i) 设置为 0 ,当 i 等于 0 、 1 和 2 时;设置为1,当 i 等于 3 和 4 时。
场中P和SP片的参考帧列表的初始化:
解码器在对一个编码场中的P或SP片解码之前,同样需要先进行RefPicList0的初始化。不同的是对一个场解码时,参考图像列表RefPicList0中的每个场都有单独的列表索引;并且对一个场解码时,可用的参考图像数将是解码一个帧时的两倍。 在此过程中,首先需要计算两个有序的参考
帧列表 refFrameList0ShortTerm 和 refFrameList0LongTerm 。为方便参考帧列表排列,已解码的帧、互补参考场对、不成对参考场对和一个场标记为" 用于短期参考" 或 " 用于长期参考 " 的参考帧均被认为是参考帧。这两个列表的产生过程如下。
- 所有包含一个或多个场标记为"用于短期参考"的帧均包含在短期参考帧列表refFrameList0ShortTerm中。如当前场是互补参考场对的第二个场(按照解码顺序),且第一个场标记为"用于短期参考",则第一个场的FrameNumWrap也包含在refFrameList0ShortTerm中。refFrameList0ShortTerm按照FrameNumWrap值的降序进行排列。
- 所有包含一个或多个场标记为 " 用于长期参考 " 的帧包含在长期参考帧列表refFrameList0LongTerm 中。如当前场是互补参考场对的第二个场(按照解码顺序),且第一个场标记为" 用于长期参考 " ,则第一个场的LongTermFrameIdx也包含在 refFrameList0LongTerm 中。 refFrameList0LongTerm按照 LongTermFrameIdx 值的升序进行排列。
在这两个列表产生后,将根据在本节" 场模式的参考帧列表的初始化" 中定义的过程,使用 refFrame List0ShortTerm 和 refFrameList0LongTerm 作为输入,生成RefPicList0 。
帧模式的B片参考图像列表的初始化 :
与上面介绍的不同, 解码器在对一个编码帧的B片解码时,首先需要对参考帧列表RefPicList0和RefPicList1进行初始化。 对于 B 片, RefPicList0 和RefPicList1中短期参考图像的排列顺序取决于输出次序,即由 PicOrderCnt()给定。参考帧列表RefPicList0 和 RefPicList1 都是有序排列的,其中短期参考帧和短期互补参考场对均排在长期参考帧和长期互补参考场对之前。
参考帧列表 RefPicList0 详细的排列顺序如下:
-
短期参考帧和短期互补参考场对排列顺序如下:如果参考帧或互补参考场对frmi 被标记为 " 用于短期参考 " ,如果 frmi 中的PicOrderCnt(frmi)小于 PicOrderCnt(CurrPic) 时,将这些 frmi 按照PicOrderCnt(frmi)的降序方式放在 RefPicList0 的起始位置;然后,其余的frmi按 PicOrderCnt(frmi) 的升序方式排列到 RefPicList0 。
- 长期参考帧和长期互补参考场对的顺序按照 LongTermPicNum 值的升序排列。
参考帧列表RefPicList1详细的排列顺序如下:
-
短期参考帧和短期参考场对排列顺序如下:如果参考帧或互补参考场对frmi被标记为"用于长期参考",如果frmi中的PicOrderCnt(frmi)大于PicOrderCnt(CurrPic)时,将这些frmi按照PicOrderCnt(frmi)的升序方式放在RefPicList1的起始位置;然后,其余的frmi按PicOrderCnt(frmi)的降序方式排列到RefPicList1。
-
长期参考帧和长期参考场对的顺序按照 LongTermPicNum 值的升序排列。
-
当参考图像列表 RefPicList1 有多于一个入口且它与 RefPicList0 相同时,头两个入口RefPicList10 和 RefPicList11 将被交换。
场模式下B片的参考帧列表初始化:
同样解码器在对一个编码场的B片解码之前,首先需要初始化参考帧列表RefPicList0和RefPicList1。当对一个场解码时,存储的参考帧的每个场使用一个唯一的索引标记为一个单独的参考图像。 RefPicList0 和 RefPicList1 中短期参考图像的顺序取决于输出次序,即由PicOrderCnt() 给定。在此过程中,首先需要推导三个有序的参考帧列表refFrameList0 ShortTerm 、 refFrameList1ShortTerm和 refFrameListLongTerm 。在下面的描述中,用术语" 参考条目 " 表示已解码参考帧、互补参考场对和非成对互补参考场对。
refFrameList0ShortTerm列表构建方法如下: 如果参考帧或互补参考场对frmi 被标记为 " 用于短期参考 " ,当 frmi 中的 PicOrderCnt(frmi) 小于或等于PicOrderCnt(CurrPic) 时,将这些 frmi 按照 PicOrderCnt(frmi) 的降序方式放在refFrameList0ShortTerm 的起始位置;然后,其余的 frmi 按
PicOrderCnt(frmi) 的升序方式排列到 refFrameList0ShortTerm 。需注意的是,如当前场的nal_ref_idc 大于 0 且根据解码顺序当前编码场前面是属于同一参考场对的编码场fldPrev 时, fldPrev 必须用 PicOrderCnt(fldPrev) 包含在列表refFrameList0ShortTerm 中,且需符合前面所述的排序规则。
refFrameList1ShortTerm的构建构成如下:如果参考帧或互补参考场对frmi被标记为"用于短期参考",当frmi中的PicOrderCnt(frmi)大于PicOrderCnt(CurrPic)时,将这些frmi按照PicOrderCnt(frmi)的升序方式放在refFrameList0ShortTerm的起始位置;然后,其余的frmi按
PicOrderCnt(frmi) 的降序方式排列到 refFrameList0ShortTerm 。需注意的是,如当前场的nal_ref_idc 大于 0 且根据解码顺序当前编码场前面是属于同一参考场对的编码场fldPrev 时, fldPrev 必须用 PicOrderCnt(fldPrev) 包含在列表refFrameList1ShortTerm 中,且需符合前面所述的排序规则。
对于refFrameListLongTerm ,其列表次序按照 LongTermPicNum 值的升序排列。如当前图像的场对标记为" 用于长期参考 " ,它将被包含在列表refFrameListLongTerm中。一个仅一个场标记为 " 用于长期参考 " 的参考条目也包含在列表refFrameListLongTerm 中。
生成3 个列表后,根据本节 "5. 场模式的参考帧列表的初始化 " 中描述的过程,使用refFrameList0ShortTerm 和 refFrameListLongTerm 作为输入,生成RefPicList0;使用 refFrameList1ShortTerm 和 refFrameListLongTerm 作为输入,生成RefPicList1 。当参考图像列表 RefPicList1 有多于一个入口且它与RefPicList0相同时,头两个入口 RefPicList10 和 RefPicList11 将被交换。
场模式的参考帧列表的初始化 :
解码器在场模式下,对P片、SP片和B片解码时,首先需要根据上面描述的过程生成参考帧列表refFrameListXShortTerm(X为0或1)和refFrameListLongTerm;然后再以它们作为输入参数,生成参考图像列表RefPicListX(X为0或1)。
参考图像列表RefPicListX 被排序,以使得短期参考场的索引值总是比长期参考场的索引值低。RefPicListX 的推导过程如下。
- 短期参考场的顺序根据已排序的帧列表 refFrameListXShortTerm 选择奇偶交替的场得到。首先是与当前场奇偶性相同的场。如一个参考帧的某个场未解码或未被标记为" 用于短期参考 " ,丢失的场将被忽略,下一个从refFrameListXShortTerm 选择的相同奇偶性的有效的存储参考场被插入RefPicListX。如果 refFrameListXShortTerm 中没有更多的奇偶交替的短期参考场,下一个未被索引的奇偶有效的场按照它们在refFrameListXShortTerm的顺序插入RefPicListX 。
- 长期参考场的顺序根据已排序的帧列表 refFrameListLongTerm 选择奇偶交替的场得到。首先是与当前场奇偶性相同的场。如一个参考帧的某个场未解码或未被标记为" 用于长期参考 " ,丢失的场将被忽略,下一个从refFrameListLongTerm 选择的相同奇偶性的有效的存储参考场被插入
RefPicListX 。如果 refFrameListLongTerm 中没有更多的奇偶交替的长期参考场,下一个未被索引的奇偶有效的场按照它们在refFrameListLongTerm 的顺序插入RefPicListX 。
- 长期参考场的顺序根据已排序的帧列表 refFrameListLongTerm 选择奇偶交替的场得到。首先是与当前场奇偶性相同的场。如一个参考帧的某个场未解码或未被标记为" 用于长期参考 " ,丢失的场将被忽略,下一个从refFrameListLongTerm 选择的相同奇偶性的有效的存储参考场被插入
3、 参考帧列表的重排序 :
解码器在根据6.2 节 " 场中P和SP片的参考帧列表的初始化 " 中描述的过程产生参考图像列表RefPicList0 和 RefPicList1 后,需要根据片头码流中的相关语法元素,如ref_pic_list_reordering_flag_10 、 ref_pic_list_reordering_flag_11、 reordering_of_pic_nums_idc 、abs_diff_pic_num_minus1和 long_term_pic_num 等的规定,经过下面的重排序过程进行列表的重排序。重排序的流程如图7.13 所示
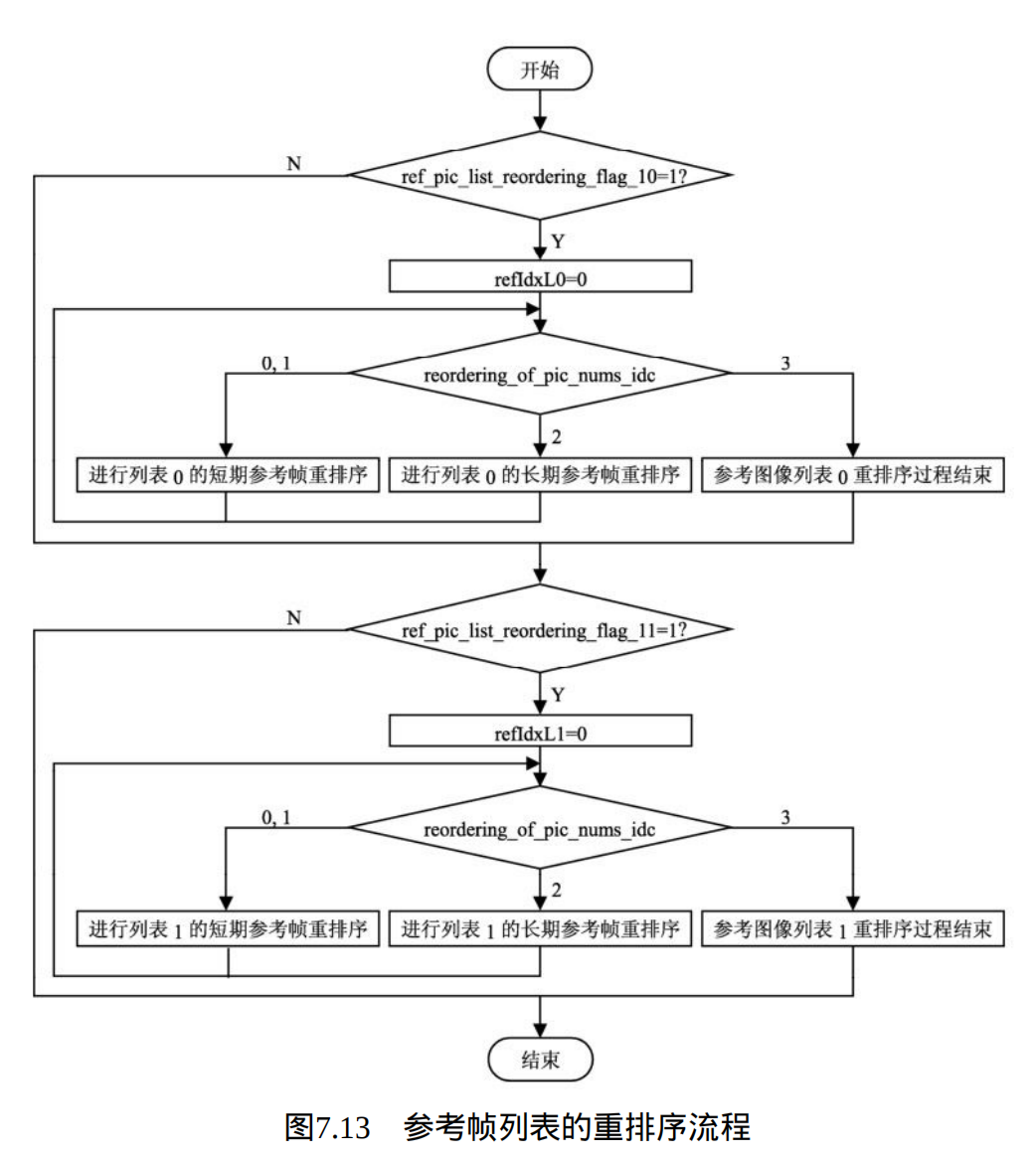
其中,refIdxL0 是参考图像列表 RefPicList0 的一个索引, refIdxL1 是参考图像列表RefPicList1 的一个索引,流程图中的短期参考帧重排序过程和长期参考帧重排序过程将在下面中详细描述。请注意,在短期参考帧的重排序和长期参考帧的重排序过程中,表RefPicListX 的长度比最终列表需要的长度大1 ;在排序过程执行完毕后,仅列表的元素 0 ~num_ref_idx_lX_active_minus1需要保留。
短期参考帧的重排序:
短期参考帧的重排序过程的输入参数是参考图像列表RefPicListX(X为0或1)和这个列表的一个索引refIdxLX;输出是调整之后的参考图像列表RefPicListX(X为0或1)和增加后的索引refIdxLX。过程的实现流程如图7.14所示。
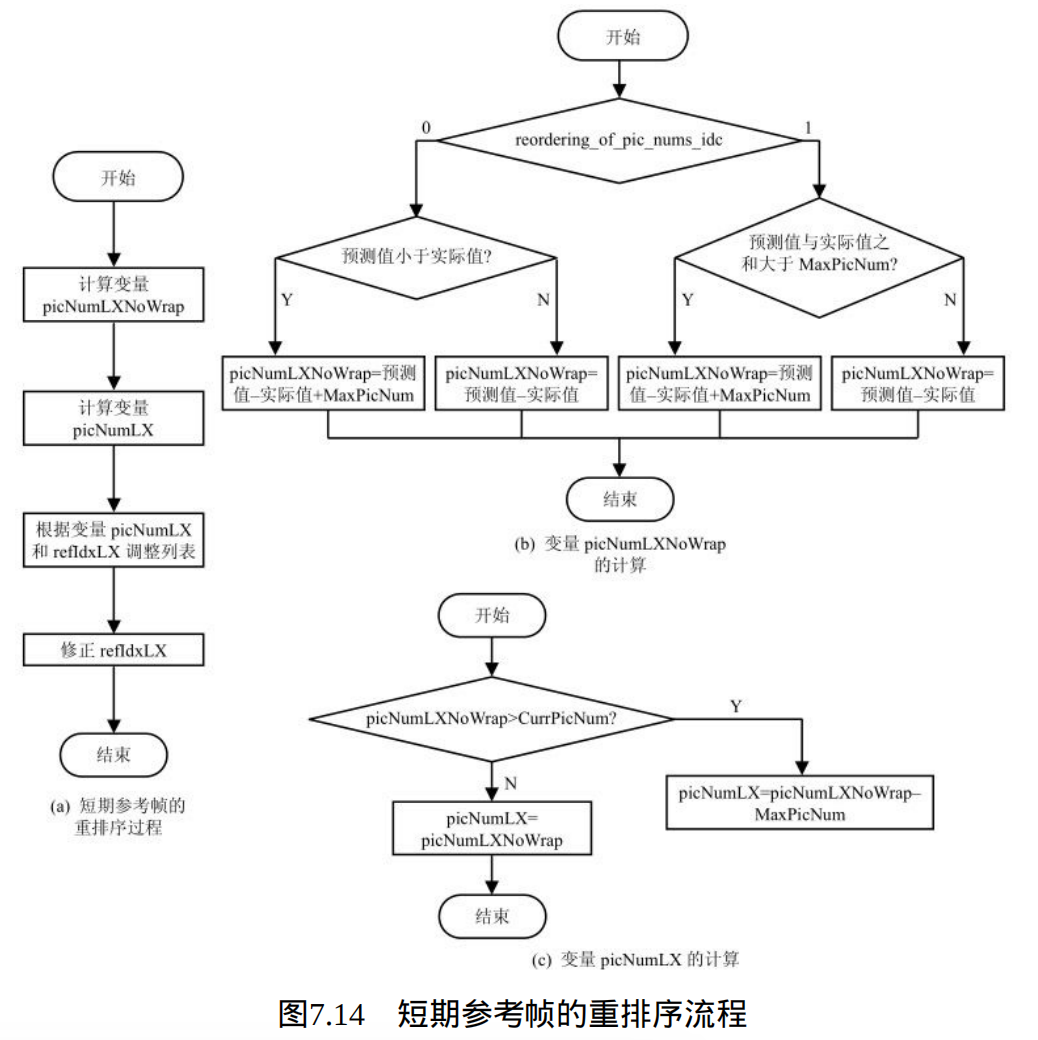
其中,预测值变量picNumLXPred,是变量picNumLXNoWrap的预测值。当一个片第一次调用本过程时(即在ref_pic_list_reordering()语法中第一次出现reordering_of_pic_nums_idc等于0或1),picNumL0Pred 和picNumL1Pred初始设置等于CurrPicNum。在每次picNumLXNoWrap的分配之后,picNumLXNoWrap 被赋给picNumLXPred。
图中的picNumLX 应指定一个标记为 " 用于短期参考 " 的参考图像,而不应指定一个标记为" 不存在 " 的短期参考图像。需要执行下面的过程将短期图像序号为picNumLX 的图像放入 refIdxLX 索引指定的位置,并将后面的其他图像向后移位,增加refIdxLX 的值。
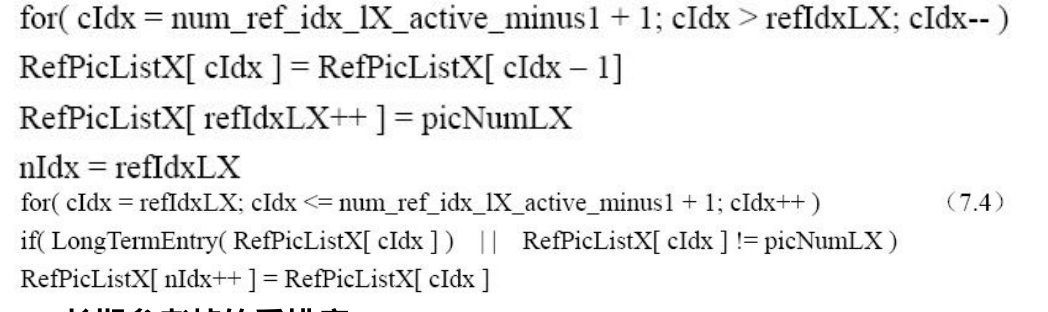
长期参考帧的重排序 :
长期参考帧的重排序过程的输入参数是参考图像列表RefPicListX(X为0或1)和这个列表的一个索引refIdxLX;输出是调整之后的参考图像列表RefPicListX(X为0或1)和增加后的索引refIdxLX。
重排序过程如下:首先根据图像的LongTermPicNum等于long_term_pic_num这一条件,确定一个将标记为"用于长期参考"的参考图像;然后需要执行下面的过程将长期图像序号为long_term_pic_num 的图像放入refIdxLX索引指定的位置,并将后面的其他图像向后移位;最后修正refIdxLX的值。

七、解码的参考图像的标记过程:
根据图7.2 中的解码整体流程可以看到, 解码器在完成一幅图像的解码后,需要对已解码图像进行存储处理,如果此图像用于其他图像的参考,同时还要进行已解码图像的标记操作。当nal_ref_idc 等于0时,不需要进行此操作。也就是说一个nal_ref_idc不等于0的已解码图像,如是一个参考图像,将被标记为"用于短期参考"或"用于长期参考" 。
标记为"用于短期参考"或"用于长期参考"的帧或互补参考场对可在帧解码时用于帧间预测的参考;标记为"用于短期参考"或"用于长期参考"的场可在场解码时用于帧间预测的参考;当一个帧或它的某个场标记为"不用于参考",或一个场标记为"不用于参考"时,它们将从参考列表中删除。一个图像在参考图像滑窗标记过程(采用先进先出机制)或参考图像自适应内存控制标记过程(采用客户自适应标记机制)中,进行"不用于参考"的标记操作,这两个过程将在7.1节和7.2节中描述。
解码器使用图像序号PicNum 标记一个短期参考图像,使用长期图像序号LongTermPicNum 标记一个长期参考图像,如果是一个场,将通过它的奇偶性来识别。关于PicNum LongTermPicNum 计算方法在 6.1 节中已描述。
已解码参考图像标记过程的操作流程参见图 7.15 。
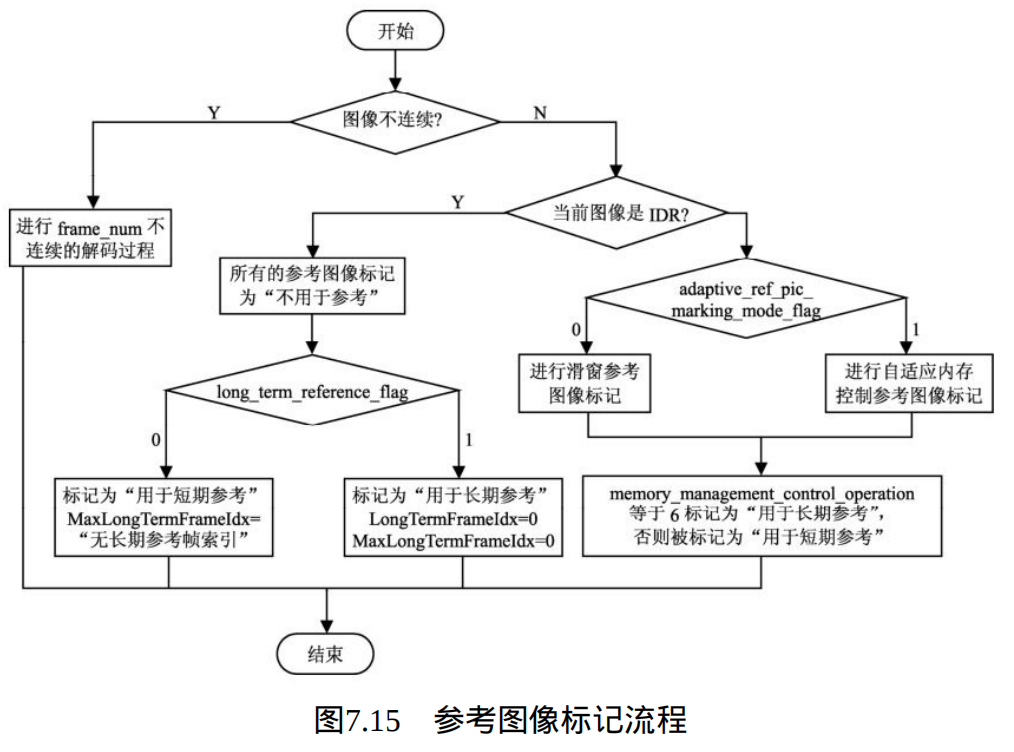
图中的"图像不连续"表示当前图像与前一幅图像之间出现跳跃,即frame_num不等于PrevRefFrameNum且不等于(PrevRefFrameNum+1)% MaxFrameNum。此外,在对当前图像标记完毕后,至少一个场标记为"用于参考"的帧数加上至少一个场标记为"用于参考"的场对数,加上标记为"用于参考"的非成对场数的和,不应大于num_ref_frames。下面详细介绍 frame_num不连续的解码过程、参考图像"滑窗"标记过程和参考图像自适应内存控制标记过程。
1、frame_num不连续的解码过程 :
本过程只在gaps_in_frame_num_value_allowed_flag等于1的相应比特流中调用。 如果比特流的gaps_in_frame_num_value_allowed_flag 等于 0 且frame_num不等于 PrevRefFrameNum 或 (PrevRefFrameNum + 1) %MaxFrameNum,解码过程应推断图像丢失已经发生。如本过程被调用,需要计算一系列" 不存在 " 图像所附属的 frame_num 值,所有的值根据"H.264语句语义" 中
描述的变量 UnusedShortTermFrameNum 获得,除了当前图像的 frame_num值。
解码过程需要对每个" 不存在 " 图像所附属的 frame_num 值进行标记,按照UnusedShortTermFrameNum 值的顺序,使用 7.2 节中描述的参考图像滑窗标记过程。添加的帧必须也标记为" 不存在 " 和 " 用于短期参考 " 。添加帧的采样值设置为任意值。这些标记为" 不存在 " 的添加帧不能用于帧间预测过程,不能在短期参考图像参考图像列表的重排序命令中使用,不能在分配
LongTermFrameIdx 给一个短期参考图像的过程中使用。当一个标记为 " 不存在" 的帧使用 " 滑窗 " 缓冲过程或 " 自适应内存控制 " 机制标记为 " 不用于参考" ,它不应再被标记为 " 不存在 " 。
如果任何一个" 不存在 " 图像所附属的 frame_num 值在帧间预测或参考索引分配中使用,解码过程应能推断图像丢失发生。如内存管理控制操作用到标记为" 不存在 " 的帧,解码过程不必推断图像丢失发生。
2、参考图像滑窗标记过程:
本过程当adaptive_ref_pic_marking_mode_flag等于0时调用。
如果当前编码场是一个互补参考场对中按照解码顺序的第二个场,且第一个场已被标记为" 用于短期参考 " ,当前图像也标记为 " 用于短期参考 " 。否则:
- 将 numShortTerm 赋值为至少一个场标记为 " 用于短期参考 " 的参考帧、互补参考场对和至少有一个场被标记为" 用于短期参考 " 的非成对参考场的总数,将numLongTerm 赋值为参考帧、参考场对和至少一个场标记为" 用于长期参考 " 的非成对参考场的总数;
- 当 numShortTerm + numLongTerm 等于 num_ref_frames 时,numShortTerm大于 0 且短期参考帧、互补参考场对和具有着最小 FrameNumWrap值的非成对参考场必须标记为 " 不用于参考 " ,如它是一个帧或互补参考场对,那么它的两个场都必须标记为" 不用于参考 " 。
3、参考图像的自适应内存控制标记过程:
本过程当adaptive_ref_pic_marking_mode_flag等于1时调用。在当前图像解码完毕后,根据memory_management_control_operation命令,按照它们在比特流出现的顺序执行,其中命令参数为从1到6。根据memory_management_control_operation的参数值,对于每个不同命令的具体 操作,在图7.16(a)中的1~6所示。其中,memory_management_control_operation等于0意味着退出标记操作。此外,操作过程中,解码器根据field_pic_flag的值确定操作的对象类型:如果 field_pic_flag等于0,则针对指定的帧或互补参考场对;否则(field_pic_flag等于1),则针对指定的某个场。具体操作过程参见流程图7.16。
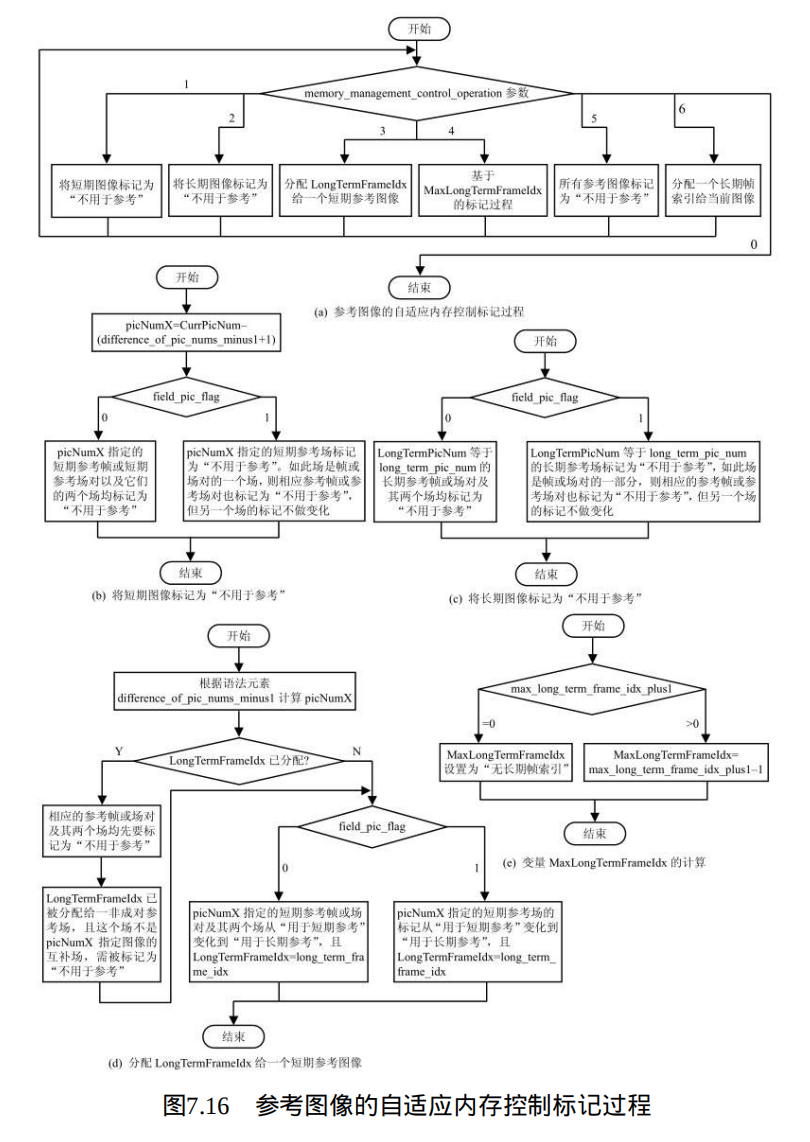
当memory_management_control_operation等于1、2时 ,分别是将短期参考图像、长期参考图像标记为" 不用于参考 " ,操作流程见图 7.16 ( b )~ (c )。变量 picNumX 和 Long TermPicNum 分别用于将一个短期参考图像、长期参考图像标记为" 未用于参考 " 。上述两种情况下,如果 field_pic_flag 等于0 ,则变量指定的参考帧或参考图像场对和它的两个场都被标记为 " 未用于参考" ;如果 field_pic_flag 等于 1 ,则指定的参考场被标记为 " 未用于参考" 。当这个参考图像是一个参考帧或一个互补参考场对的一部分时,这个参考帧或互补参考场对也将被标记为" 未用于参考 " ,但是其他场的标记不能改变。
当memory_management_control_operation等于3时,分配一个LongTermFrameIdx给短期参考图像,将将一个"用于短期参考"图像标记为"用于长期参考"。处理流程如图7.16(d)所示,首先根据句法元素difference_of_pic_nums_minus1的值计算变量picNumX,picNumX应指向标记为"用于短期参考"但不是"不存在"的一个帧或互补参考场对或非成对参考场。
当memory_management_control_operation等于4时 ,根据 MaxLongTermFrameIdx值进行标记的过程中,所有的 LongTermFrameIdx 大于max_long_term_frame_idx_plus1--1 且标记为 " 用于长期参考 " 的图像标记为" 不用于参考 " 。变量 MaxLongTermFrameIdx 的计算方法参见流程图 7.16( e )。请注意发送 max_long_term_frame_idx_plus1 的频度在当前建议 / 国际标准中没有定义,然而,编码器在接收到一个错误信息后必须发送一个memory_management_control_operation 命令 4 ,例如帧内刷新请求消息。
当memory_management_control_operation等于5时 ,在将所有参考图像标记为" 不用于参考 " 的过程中,必须首先将所有参考图像标记为 " 不用于参考" ,然后将 MaxLongTermFrameIdx 设置为 " 非长期帧索引 " 。
当memory_management_control_operation等于6时 ,分配一个长期帧索引给当前图像的过程中,如果LongTermFrameIdx 已经分配给一个长期参考帧或长期互补参考场对,相应的参考帧或互补参考场和它的两个场都要标记为" 不用于参考 " 。当这个 LongTermFrameIdx 已经被分配给一个非成对参考场且这个场不是当前图像的互补场时,这个场需被标记为" 不用于参考" 。然后将当前图像标记为 " 用于长期参考 " 且将 LongTermFrameIdx 赋值为long_term_frame_idx。当 field_pic_flag 等于 0 时,它的两个场也标记为 " 用于长期参考" 且 LongTermFrameIdx 赋值为 long_term_frame_idx ;当 field_pic_flag等于1且当前图像是一个参考场对的第二个场(按照解码顺序)时,相应的场对也标记为"用于长期参考",且LongTermFrameIdx赋值为long_term_frame_idx。
八、帧内预测:
- H.264采用了比以往编码标准更为精确和复杂的帧内预测方式,去除当前图像中的空间冗余度。由于当前被编码的宏块与相邻的宏块有很强的相似性,帧内预测用于计算编码宏块与其相邻宏块之间的空间相关性,以提高编码效率。在帧内预测中,当前编码的宏块上方及左方的宏块用于计算出当前宏块的预测值。当前宏块与其预测值的差值将进一步编码并予传输到解码器端。解码器利用该比特流中用于表示预测方式的相关比特与解码出的残差信号的比特,计算出当前宏块的预测值,恢复图像宏块的原始像素值。此外,H.264还提供了一种"PCM"的编码方式,采用"PCM"编码时, 解码器可直接恢复当前宏块的像素值而不必经过其他任何计算。
H.264提供了4种帧内预测方式:4×4亮度块的帧内预测(Intra_4×4)、16×16亮度块的帧内预测(Intra_16×16)、8×8色度块的帧内预测 (Intra_chroma)以及PCM的预测方式(I_PCM) 。
在4×4 亮度块的帧内预测( Intra_4×4 )过程中,一个宏块的亮度分量包括16 个 4×4 亮度样点块,采用变量 luma4×4BlkIdx = 0,...,15 索引,这 16 个 4×4亮度块的预测过程如下。
-
根据输入的 4×4 亮度块 luma4×4BlkIdx 和相邻亮度块构建的样点,计算得出Intra_4×4 亮度预测样点值 pred4×4 L x, y , x, y = 0,...,3 。
-
根据宏块的4×4亮度块的逆4×4亮度扫描过程,可以得到当前宏块中索引为luma4×4BlkIdx的4×4亮度块的左上角样点的位置(xO, yO),计算得到亮度宏块predL xO+x, yO+y=pred4×4L x, y,x, y=0,...,3。
-
根据反量化和反变换得到的残差数据,加上 pred L xO + x, yO + y,得出当前 4×4 亮度块的重建值。
1、4×4亮度块预测方式的推导 :
当前宏块采用4×4 亮度块的帧内预测方式( Intra_4×4 )时,每一个 4×4块可使用9 种预测方式的任意一种进行预测,根据输入的 4×4 亮度块的索引luma4×4BlkIdx和相邻宏块的变量 Intra4×4PredMode ,算出预测模式序号变量Intra4×4PredModeluma4×4BlkIdx ,表 7.2 给出了预测模式序号Intra4×4PredModeluma4×4BlkIdx的说明。
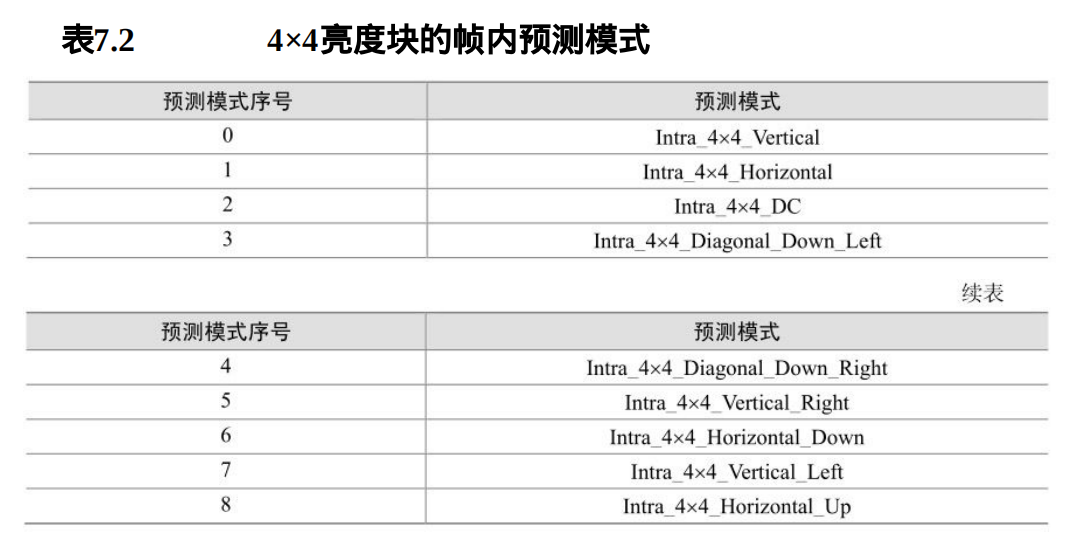
图7.17 给出了 Intra4×4PredModeluma4×4BlkIdx 的值为 0 、 1 、 2 、 3 、 4 、5、 6 、 7 和 8 时的预测方向。
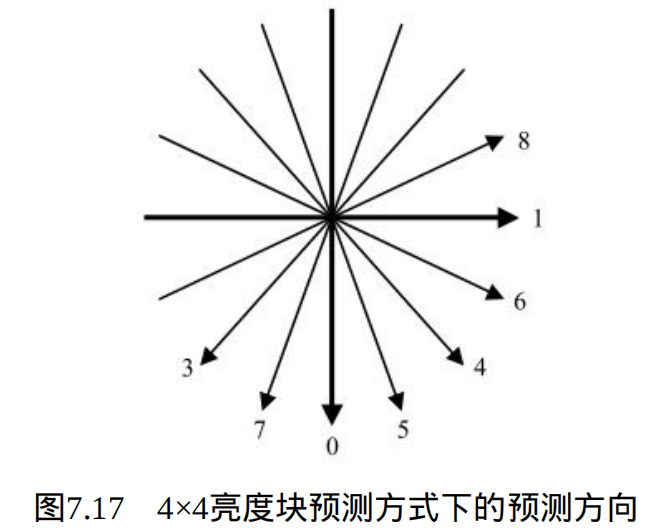
然而,全部传输每一个4×4 亮度块的预测方式仍将占用大量的比特数,因此可以考虑利用相邻块的预测方式之间的相关性。例如,已编码的4×4 亮度块A 及 B 位于当前块的上方及左方,如图 7.18 所示。若 A 和 B 均采用模式 2的帧内预测方式,对于当前块C 最有可能的预测方式也是模式 2 。
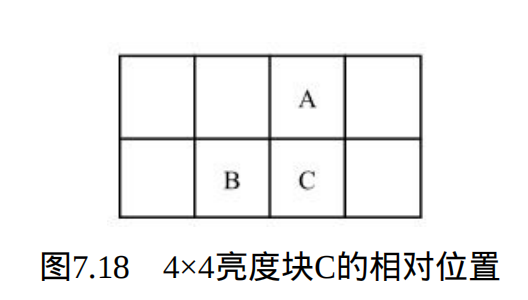
对于当前的4×4 亮度块 C ,若 C 的预测方式与 A 、 B 的预测方式的最小值 (predIntra4×4Pred 模式)相同,此时相应的句法元素 prev_intra4×4_pred_ 模式置为1 。否则( prev_intra4×4_pred_ 模式置为 0 ),另一个句法元素rem_intra4×4_pred_模式用于指出 C 块的预测方式与 predIntra4×4Pred 模式的差别。若rem_intra4×4_pred_ 模式的值小于 predIntra4×4Pred 模式,则当前块C的预测方式为 rem_intra4×4_pred_ 模式的值;否则当前块 C 的预测方式为rem_intra4×4_pred_模式 +1 的值。此外若图 7.16 中的 A 或 B 不存在,则其相应的预测方式为直流预测(模式2 )。
2、4×4亮度块的帧内预测编码方式:
当编码的宏块使用4×4亮度块帧内预测编码方式时,对于宏块中的每一 个4×4亮度块有9种可能的预测方式。预测的4×4块由相邻的像素值(A~ M)预测,如图7.19所示。在解码器端,根据 Intra4×4PredModeluma4×4BlkIdx的不同值,分别调用本节所规定的帧内预测方式。

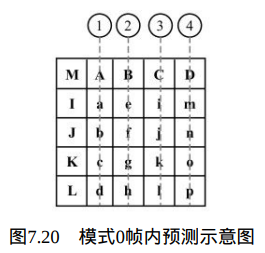
Intra_4×4_Vertical预测模式(模式0):
当Intra4×4PredModeluma4×4BlkIdx等于0时,也就是在 Intra_4×4_Vertical预测模式下,当前4×4块的像素值由相邻的像素A、B、C 和D预测得出,如图7.20所示。
像素预测值由下式决定:
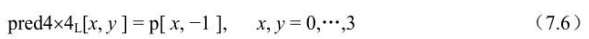
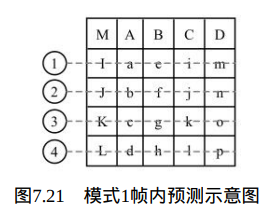
Intra_4×4_Horizontal预测模式(模式1):
当Intra4×4PredModeluma4×4BlkIdx等于1时,也就是 Intra_4×4_Horizontal预测模式,当前4×4块的像素值由相邻的像素I、J、K和 L预测得出,如图7.21所示。
像素预测值由下式决定:
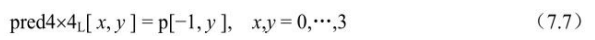
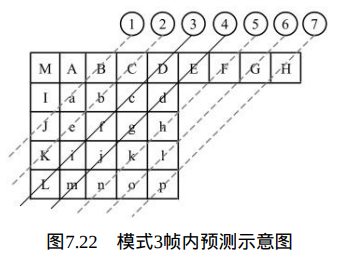
Intra_4×4_Diagonal_Down_Left预测模式(模式3):
当Intra4×4PredModeluma4×4BlkIdx等于3时,也就是 Intra_4×4_Diagonal_Down_Left预测模式,当前4×4块的像素值由相邻的像素 A、B、C、D、E、F、G和H预测得出,如图7.22所示。
像素预测值由下式决定:
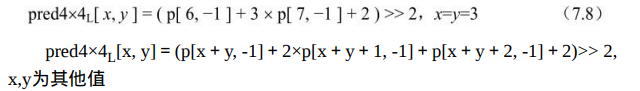
Intra_4×4_Diagonal_Down_Right预测模式(模式4):
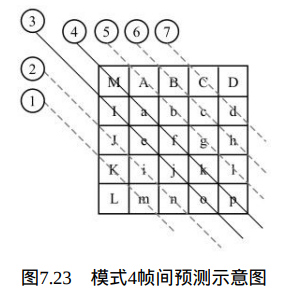
当Intra4×4PredModeluma4×4BlkIdx等于4时,也就是Intra_4×4_Diagonal_Down_Right预测模式,当前4×4块的像素值由相邻的像 素A、B、C、D、I、J、K、L和M预测得出,如图7.23所示。
像素预测值由下式决定:
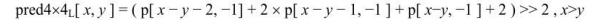
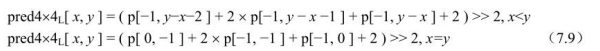
Intra_4×4_Vertical_Right预测模式(模式5):
当Intra4×4PredModeluma4×4BlkIdx等于5时,也就是在 Intra_4×4_Vertical_Right预测模式下,当前4×4块的像素值与相邻的像素A、 B、C、D、I、J、K、L和M预测得出,如图7.24所示。
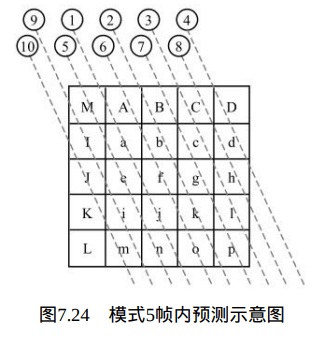
像素预测值由下式决定:
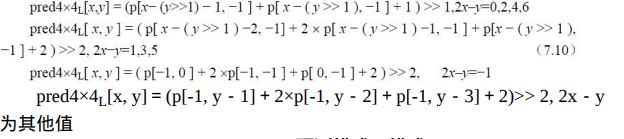
Intra_4×4_Horizontal_Down预测模式(模式6):
当Intra4×4PredModeluma4×4BlkIdx等于6时,也就是在 Intra_4×4_Horizontal_Down预测模式下,当前4×4块的像素值由相邻的像素 A、B、C、I、J、K和L预测得出,如图7.25所示。
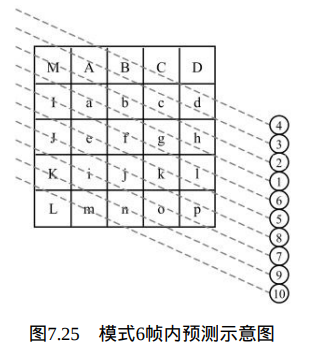
像素预测值由下式决定:
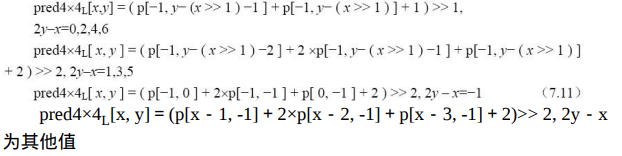
Intra_4x4_Vertical_Left预测模式(模式7):
当Intra4×4PredModeluma4×4BlkIdx等于7时,也就是在 Intra_4×4_Vertical_Left预测模式下,当前4×4块的像素值由相邻的像素A、 B、C、D、E、F和G预测得出,如图7.26所示。
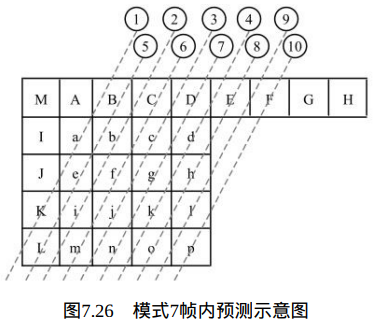
像素预测值由下式决定:
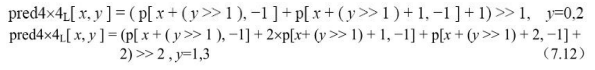
Intra_4×4_Horizontal_Up预测模式(模式8):
当Intra4×4PredModeluma4×4BlkIdx等于8时,也就是在Intra_4×4_Horizontal_Up预测模式下,当前4×4块的像素值由相邻的像素I、 J、K和L预测得出,如图7.27所示。
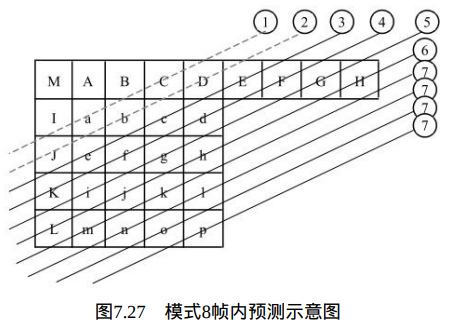
像素预测值由下式决定:
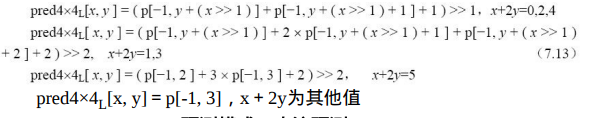
Intra_4×4_DC预测模式(直流预测):
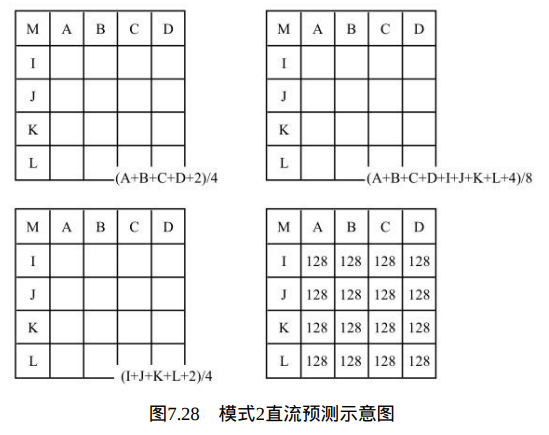
当Intra4×4PredModeluma4×4BlkIdx等于2时,也就是Intra_4×4_DC预 测模式,当相邻像素A、B、C、D、I、J、K及L均存在时,由其像素值的平均值预测当前4×4的亮度块;若只有像素I~L存在,则当前4×4块由I~L像 素值的平均值预测得到;若只有像素A~D存在,则当前4×4块由A~D像素值的平均值预测得到;否则,当前4×4块的预测值均为128,如图7.28所示。
3、16×16亮度块的帧内预测方式:
在这种预测方式下,整个16×16的亮度宏块同时被预测,且共有4中不同的预测方式,见表7.3。根据预测模式Intra16×16PredMode,调用本节中规定的任何一种Intra_16×16预测模式。

Intra_16x16_Vertical预测模式(模式0):
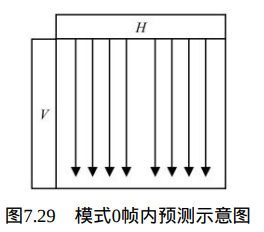
在Intra_16×16_Vertical预测模式下,当前宏块的所有像素由上方的像素H预测得到,如图7.29所示。
像素预测值由下式决定:
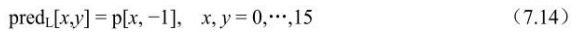
Intra_16x16_Horizontal预测模式(模式1):
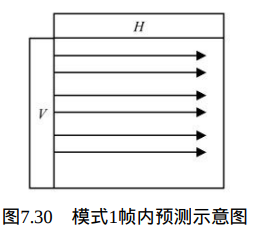
在Intra_16×16_Horizontal预测模式下,当前宏块的所有像素由左方的像素V预测得到,如图7.30所示。
像素预测值由下式决定:
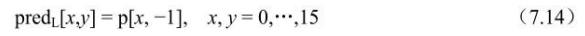
Intra_16x16_DC预测模式(模式2):
在Intra_16×16_DC预测模式下,当前宏块的所有像素由左方的像素V及 上方的像素H的平均值预测得到,如图7.31所示。
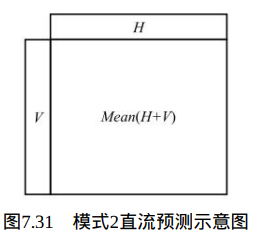
若相邻像素H与V均存在,当前宏块的所有像素值为(H+V)的平均值;若只有像素H存在,当前宏块的所有像素值为H的平均值;若只有像素V存在,当前宏块的所有像素值为像素V的平均值;否则(像素H与V均不存在),当前宏块的所有像素值为128。
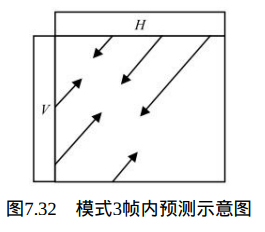
Intra_16x16_Plane预测模式(模式3):
在Intra_16×16_Plane预测模式下,其预测方式如图7.32所示。
像素预测值由下式决定:
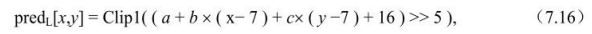
在上式中:
其中H、V由下式决定:
4、8×8色度块的帧内预测方式:
对于整个8×8的色度宏块,共有4种不同的预测方式,见表7.4。根据帧内色度预测模式intra_chroma_pred_mode,调用本节中定义的某一种帧间色度预测模式。
Intra_Chroma_Vertical l预测模式(模式0):
在Intra_Chroma_Vertical预测模式下,当前宏块的所有像素由上方的像素H预测得到,如图7.33所示。
 图7.33 模式0帧预测示意图
图7.33 模式0帧预测示意图
像素预测值由下式决定:
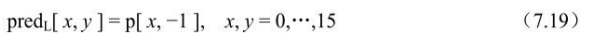
Intra_Chroma _Horizontal预测模式(模式1):
在Intra_Chroma _Horizontal预测模式下,当前宏块的所有像素由左方的像素V预测得到,如图7.34所示。
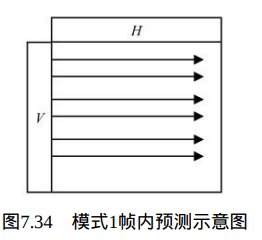
像素预测值由下式决定:
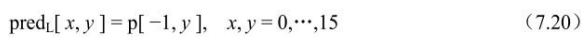
Intra_Chroma _DC预测模式(模式2):
在Intra_Chroma _DC预测模式下,当前宏块的所有像素由左方的像素V及上方的像素H的平均值预测得到,如图7.35所示。
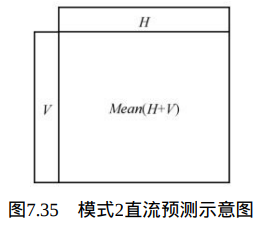
若相邻像素H与V均存在,当前宏块的所有像素值为(H+V)的平均值;若只有像素H存在,当前宏块的所有像素值为H的平均值;若只有像素V存在,当前宏块的所有像素值为像素V的平均值;否则(像素H与V均不 存在),当前宏块的所有像素值为128。
Intra_Chroma_Plane预测模式(模式3):
在Intra_Chroma_Plane预测模式下,其预测方式如图7.36所示。
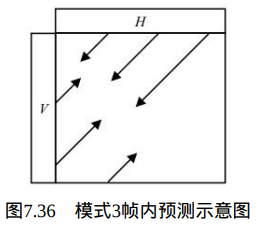
像素预测值由下式决定:
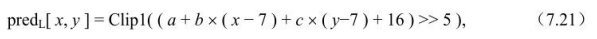
在上式中:
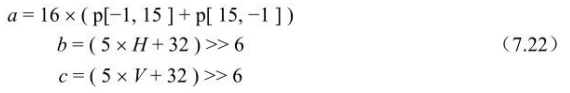
其中H、V由下式决定:
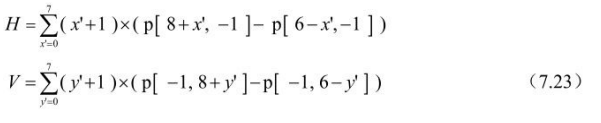
九、帧间预测解码处理:
H.264采用树状结构的运动补偿技术,提高了帧间预测性能。更高精度的预测产生更好的图像质量。H.264的亮度分量运动向量的精度提高到1/4像素,进一步提高了运动补偿算法的预测能力。此外,H.264引入了多参考帧选择模式,这将产生更好的视频质量和更高效率的视频编码。相对于1个参考帧,5个参考帧可以节约5%~10%的比特率,且有助于比特流的恢复。
宏块和子宏块的分割模式分别由句法元素mb_type和sub_mb_type规定。宏块的每个分割块各由一个索引值mbPartIdx标识。每个子宏块分割各由一个索引值subMbPartIdx标识。
解码中P宏块和B宏块需要进行帧间预测,其输出为相应宏块的帧间预测样点,包括一个16×16的亮度样点阵列predL和两个色度样点8×8阵列 predCr和predCb。其解码流程见图7.37。
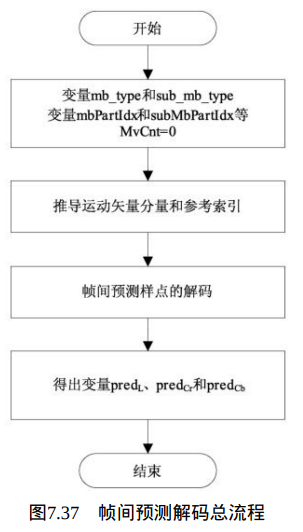
推导运动矢量分量和参考索引的过程详见9.1节。该过程的输入是宏块分割mbPartIdx和子宏块分割subMbPartIdx,输出的变量包括:
- ①亮度运动矢量mvL0和mvL1、色度运动矢量mvCL0、mvCL1;
- ②参考索引refIdxL0和refIdxL1;
- ③预测列表标志predFlagL0和predFlagL1和子宏块分割块的运动矢量个数subMvCnt。
帧间预测样点的解码过程见9.2节。该过程的输入包括:
- ①宏块分割 mbPartIdx、子宏块分割subMbPartIdx;
- ②分割块的高度和宽度partWidth、 partHeight、partWidthC和partHeightC;
- ③运动矢量mvL0、mvL1、mvCL0、 mvCL1;
- ④参考索引refIdxL0、refIdxL1;
- ⑤预测列表标志predFlagL0、 predFlagL1。输出的变量包括:一个partWidth×partHeight的亮度点阵列 predPartL和两个partWidthC×partHeightC色度点阵列predPartCr、predPartCb, 每个色度分量Cb和Cr对应一个。
宏块的预测可以通过将分割块或子宏块分割块的预测样点放置在宏块中的适当位置上来构造,宏块阵列形成如下:

其中,(xP, yP)为宏块分割的左上角像素与所处宏块左上角像素的相对位置。(xS, yS)为宏块子分割的左上角像素与所处宏块分割的左上角像素的相对位置。predC和predPartC中的C分别换成Cb或Cr。
1、 MV分量及参考索引获取:
本过程的输入为mbPartIdx和subMbPartIdx,输出为mvL0、mvL1、 mvCL0、mvCL1、refIdxL0、refIdxL1、predFlagL0、predFlagL1,如图7.38 所示。
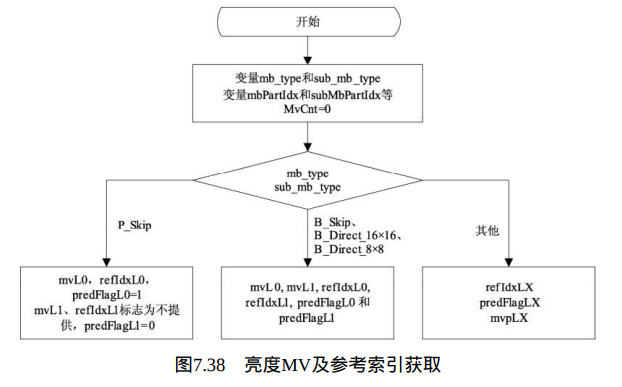
其具体处理过程见下文。色度MV获取以mvLX and refIdxLX为输入, mvCLX为输出。本文先讲通常情况下的亮度MV如何获取,再讨论特殊情况。最后讨论色度MV如何获得。
亮度运动矢量预测值的推导:
本处理的输入是宏块分割块索引mbPartIdx、子宏块分割块索引subMbPartIdx、当前分割块的参考索引refIdxLX(X为0或1)、变量currSubMbType,输出运动矢量mvLX的预测值mvpLX(X为0或1)。
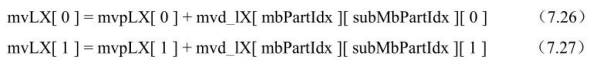
本处理的推导过程如图7.39所示,其中,N可以用A、B或C替代。
P片、SP片中跳跃宏块亮度运动矢量的推导:
本过程处理宏块类型mb_type等于P_Skip时的解码,输出为mvL0和 refIdxL0。在P_Skip模式下,参考索引refIdxL0等于0。
对于P_Skip类型的宏块,运动矢量mvL0推导过程如下。
第一步,根据"亮度运动矢量预测值的推导"中的相邻分割块运动矢量数据的推导过程,以mbPartIdx=0、subMbPartIdx=0、listsuffixFlag=0为输入,输出为mbAddrA、mbAddrB、mvL0A、mvL0B、refIdxL0A和 refIdxL0B。
第二步,如下列任一命题为真,运动矢量mvL0的两个分量都等于0:
- (1)mbAddrA不提供;
- (2)mbAddrB不提供;
- (3)refIdxL0A=0且mvL0A两个分量都等于0;
- (4)refIdxL0B=0且mvL0B两个分量都等于0。
否则,根据亮度运动矢量预测值的推导,以mbPartIdx=0、 subMbPartIdx=0、refIdxL0和currSubMbType为输入,mvL0为输出。
注:这里输出值直接赋给mvL0,因为预测值等于运动矢量的实际值。
B_skip,B_Direct_16×16,B_Direct_8×8的亮度运动矢量的推导:
该处理用于宏块类型为B_Skip或B_Direct_16×16,或者子宏块类型为 B_Direct_8×8时的解码。其输入为mbPartIdx和subMbPartIdx,输出为 refIdxL0、refIdxL1、mvL0、mvL1、predFlagL0和predFlagL1。
该处理还取决于句法元素direct_spatial_mv_pred_flag的值。 direct_spatial_mv_pred_flag=1时,该处理输出模式为空间直接预测模式; direct_spatial_mv_pred_flag=0时,该处理输出模式为时间直接预测模式。
色度运动矢量的推导:
该处理过程输入为亮度矢量mvLX和refIdxLX,输出为色度矢量 mvCLX。色度运动矢量根据相应亮度运动矢量MV推导而得。因为亮度MV精度为1/4像素,色度精度为其一半,故色度MV精度应为1/8像素精度。例如,亮度矢量指定8×16亮度像素时,相应色度矢量应针对4×8色度像素。
色度运动矢量的mvCLX的推导过程如下。
- (1)当前宏块为帧宏块时,色度运动矢量mvCLX的水平和垂直分量通过相应亮度mvLX分量除以2推出,该过程通过将1/4像素mvLX单元映射到1/8像素mvCLX单元实现。

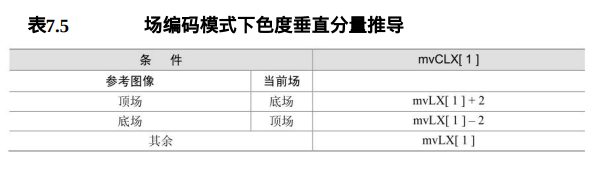
- (2)当前宏块为场宏块时,色度矢量的水平分量mvCLX0等于mvLX0。垂直分量mvCLX1则取决于当前场对或当前图像及其参考图像,见表7.5。.
2、帧间预测像素解码处理:
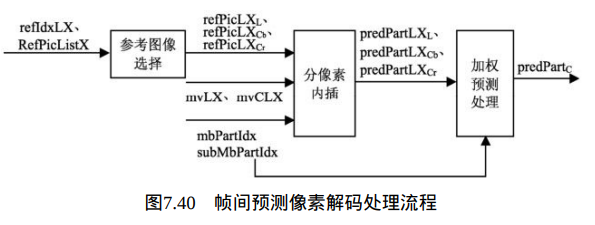
该处理过程输入为宏块分割mbPartIdx、子宏块分割subMbPartIdx、分割宽高变量partWidth和partHeight、亮度运动矢量mvL0和mvL1、色度运动矢量mvCL0和mvCL1、参考索引refIdxL0和refIdxL1、预测表使用标志 predFlagL0和predFlagL1。
其输出为帧间预测像素predPart,包括一个 (partWidth)×(partHeight)亮度预测像素和两个 (partWidthC)×(partHeightC)色度预测像素
和
。
这里设predPartL0L和predPartL1L为预测亮度像素值(partWidth)×(partHeight)矩阵, 、
、
、
为相应色度像素值 (partWidthC)×(partHeightC)矩阵。其流程如图7.40所示,变量中的X可以是0或1。
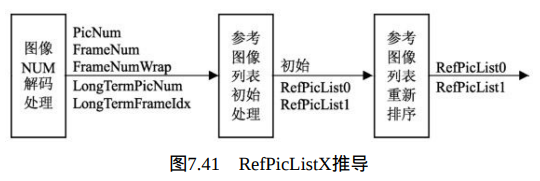
参考图像选择处理:
该处理过程输入为refIdxLX,输出为、
和
。参考图像列表RefPicListX是预先已解码参考帧、互补参考场对或非成对参考场的PicNum和LongTermPicNum的列表,但都标志为"参考图像用"。
PicNum和LongTermPicNum 规定如下:
- (1)若field_pic_flag=1,RefPicListX所有成员PicNum和LongTermPicNum为已解码参考场或已解码参考帧的场;
- (2)若field_pic_flag=0,PicNum和LongTermPicNum为已解码参考帧或已解码互补场对。
参考图像列表RefPicListX推导如图7.41所示。
分像素内插处理:
该处理过程输入为mbPartIdx 、subMbPartIdx、亮度像素单元的 partWidth和partHeight、mvLX、mvCLX、、
、
;
输出为一个预测亮度像素值矩阵(partWidth)×(partHeight)的、两个预测色度像素值矩阵(partWidth/2)x(partHeight/2)的
和
。
这里,设为当前分割左上亮度像素的整像素单元位置,这是相对于给出亮度像素二维矩阵左上的像素位置而言。设
为整像素单元亮度位置,
为1/4像素单元偏移。
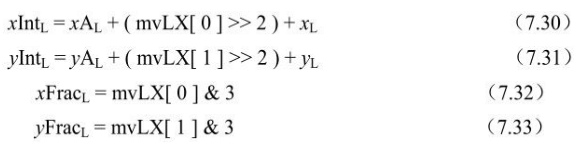
推导见本小节的"亮度像素内插处理"部分,以
、
、
为输入。
同样,设为整像素单元亮度位置,
为1/8像 素单元偏移。
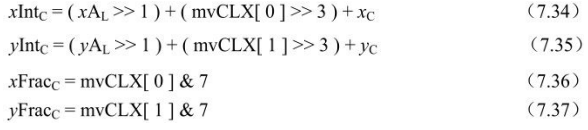
和
推导见本小节的"色度像素内 插处理",以
和
及
、
为输入。
亮度像素内插处理:
该处理过程输入为亮度整像素位置、亮度分像素位置偏移
、参考图像
的亮度像素矩阵。输出为预测亮度像素值
。
在图7.42中,标有大写字母阴影块位置为参考亮度像素值的二维矩阵的 整数位置。这些像素用来推导。
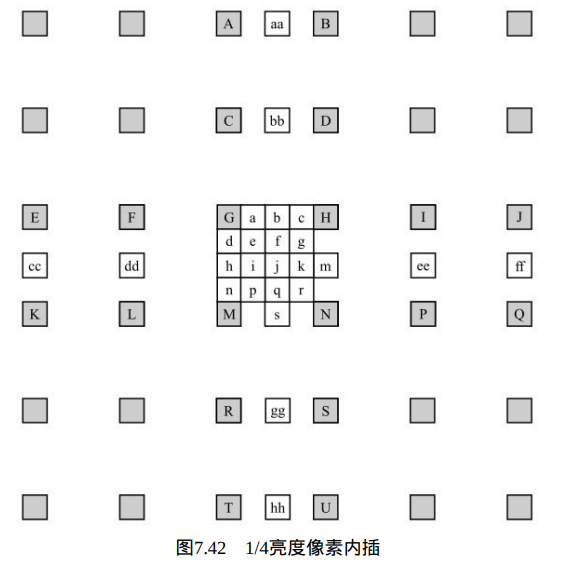
在参考亮度像素矩阵中,各像素位置
推导如下,Z 可为A、B、C、D、E、F、G、H、I、J、K、L、M、N、P、Q、R、S、T 或U。

表7.6给出了相应亮度像素位置。

在给出整像素位置到
的像素后,分像素位 置"a"到"s"的像素值便可计算出来。其中,半像素通过6抽头滤波器(1, -5, 20, 20, -5, 1)实现,1/4像素位置像素则通过整像素和半像素平均而得,具体如下。
- ①计算半像素位置像素b和h,先计算中间量b1和h1,再计算b和h。
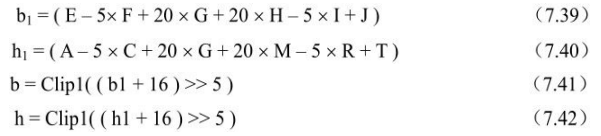
- ②计算半像素位置像素j,同样先计算中间量j1,j1通过对水平或垂直方向最近半像素滤波而得。
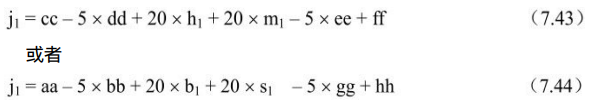
这里,中间量aa、bb、gg、s1、hh、cc、dd、ee、m1、ff类似与b1和h1 方式获得。最终,

- ③s和m类似于b 和h的获得方法:
- 1/4像素a、c、d、n、f、i、k、q由最近的整像素和半像素平均得出:

- 1/4像素e、g、p、r 由两个对角线上的半像素获得:

分像素单元中的亮度位置偏移指定了产生的整像素和分像素中为预测亮度像素值
的像素,如表7.7所示。

色度像素内插处理:
该处理过程输入为一色度整像素位置、一色度分像素位置
及参考图像
的色度像素。输出为
。
图7.43中,A、B、C、D表示色度像素二维矩阵的整像素位置像素。
 图7.43 色度分像素内插
图7.43 色度分像素内插
这些像素用来产生。如下,

预测色度像素值推导如下:
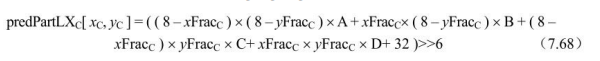
加权像素预测处理:
该处理过程输入为mbPartIdx、subMbPartIdx、predFlagL0和 predFlagL1、、
和
。输出为
、
和
。
P片和SP片中predFlagL0=1宏块或分割有如下处理过程:
- 若weighted_pred_flag=0,采用缺省加权处理;
- 若weighted_pred_flag=1,采用加权处理;
- B片中predFlagL0=1或predFlagL=1宏块或分割有如下处理过程:
若weighted_bipred_idc=0,采用缺省加权处理;
若weighted_bipred_idc=1, 采用加权处理;
若weighted_bipred_idc=2,则有,
predFlagL0=1且predFlagL1=1, 采用加权处理;
predFlagL0=1或predFlagL1=1,采用缺省加权处理。
(1)缺省加权像素预测处理:
根据预测方块类型,有以下约定。
- ①推导亮度
时,C设为L,x为0~partWidth-1,y为0~ partHeight--1。
- ②推导色度Cb的
- ③推导色度
缺省加权情况下的预测值如下:
- ①predFlagL0=1且predFlagL1=0时,
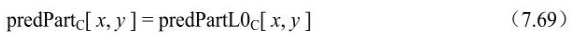
- ②predFlagL0=0且predFlagL1=1时,
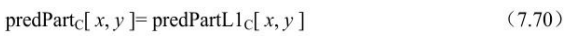
- ③predFlagL0=1且predFlagL1=1时,
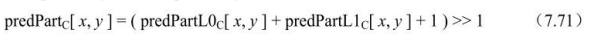
(2)加权像素预测处理:
根据预测方块类型,有以下约定。
- ①推导亮度
- ②推导色度
- ③推导色度
预测值计算方法如下:
- ①分割mbPartIdx\subMbPartIdx的predFlagL0=1且predFlagL1=0时,
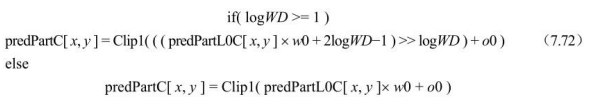
- ②分割mbPartIdx\subMbPartIdx 的predFlagL0=0且predFlagL1=1时,

(3)分割mbPartIdx\subMbPartIdx 的predFlagL0=1且predFlagL1=1 时,
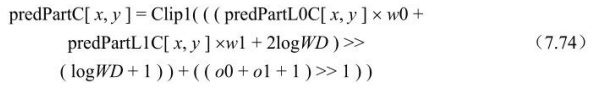
上述推导过程中变量的推导如下。
- ①若weighted_bipred_idc=2且slice_type=B时,

w0和w1推导如下:.
DiffPicOrderCnt(picA, picB)=0或一个或两个参考图像为长期参考图像或(DistScaleFactor >> 2)< -64或(DistScaleFactor >> 2)> 128时,
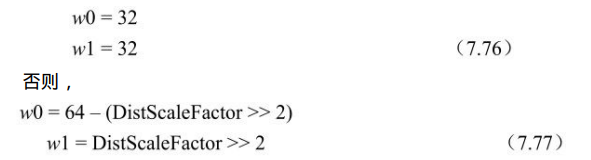
- ②若P片或SP片weighted_pred_flag=1或B片weighted_bipred_idc=1时, refIdxL0WP和refIdxL1WP推导如下:
MbaffFrameFlag=1且当前宏块为场宏块时,
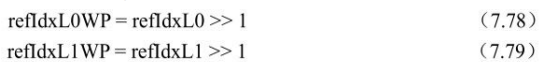
MbaffFrameFlag=0或当前宏块为帧宏块时,

logWD、w0、w1、o0、o1推导如下:
predPartCx, y中C为L时,

predPartCx, y中C为或
,
=0,
=1时,

注:在直接加权预测模式中,predFlagL0=1和predFlagL1=1时,必须 遵守以下约束,

而非直接模式中,则满足-64≤w0, w1≤128即可。
十、变换系数解码:
H.264中,变换系数解码包括逆整数DCT及反量化。这个过程的输出与整个解码器的实际输出的差别在于图像样点位置不一致以及存在方块效应。
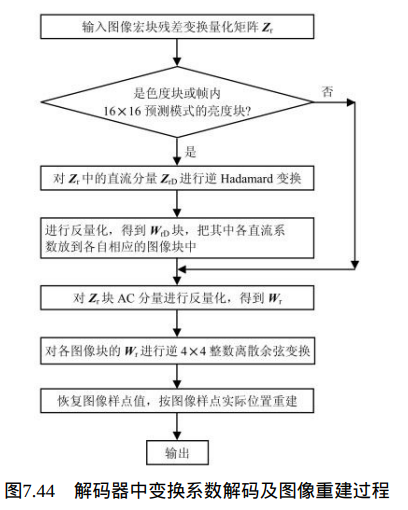
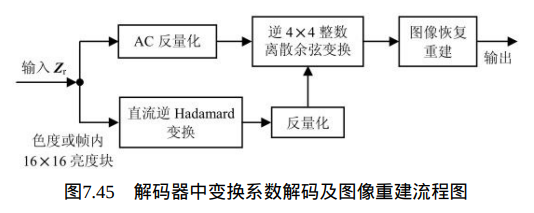
本节介绍H.264中的变换系数解码和去方块滤波前的图像重建过程。本节解码器工作过程如图7.44所示,图7.45为其流程图。如果输入块是色度块或帧内16×16预测模式的亮度块,则需要先对直流分量进行逆Hadamard变换,恢复整数DCT变换的直流分量。
1、变换系数逆扫描过程:
H.264多数场合是对4×4图像块进行处理的,在一个宏块中包含4×4个图像块。往往需要对4×4矩阵进行操作运算,而在网络传输等应用中数据是以一维形式进行传递的。在编码器中将二维编码信息以扫描方式变成一维数据输出,在解码器端则需要将这个一维数据转换成二维数组或矩阵进行运算。本小节所介绍的功能是将输入的一个长为16的图像变换系数的序列转换成各图像块在宏块中的对应坐标位置,以一个4×4二维数组表示。
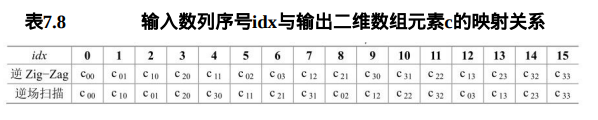
解码过程通过逆扫描过程将变换系数量化值序列映射到对应的坐标上 。有两种逆扫描模式,如图7.46所示。逆Zig-Zag扫描应用于帧宏块,而逆场扫描应用于场宏块。
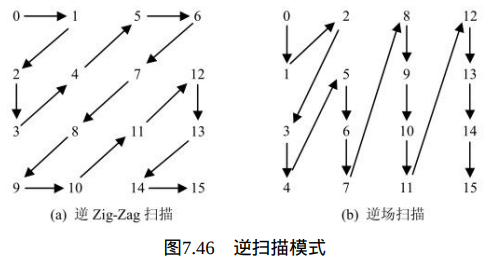
表7.8提供输入的16个元素数列的序号idx到输出的二维数组c的序号i和j的映射。
2、DCT变换系数中直流系数的逆变换量化:
如果当前处理的图像宏块是色度块或帧内16×16预测模式的亮度块,则需要先恢复各图像块的DCT变换的直流系数。
帧内16×16预测模式宏块的亮度直流变换系数的比例变换:
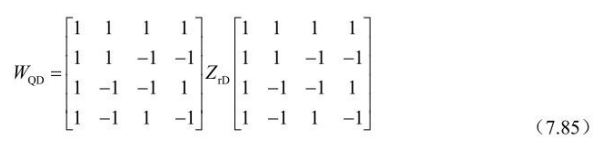
与一般设象的不同,这个过程是先进行逆Hadamard变换,而不是反量化。它的输入是帧内16×16预测模式宏块的亮度DC变换系数量化值,表示为4×4数组 ;输出是恢复的宏块中4×4个亮度块的DCT变换直流系数值, 表示成一个4×4数组
。
4×4亮度直流变换系数的逆Hadamard变换定义为:
类似于正向Hadamard变换和DCT变换,可以将矩阵乘法运算改造成两次一维变换。例如先对量化矩阵的每行进行一维变换,然后对经行变换所得数据块的每列再应用一维变换。而每次一维变换可以采用蝶形快速算法,节省计算时间,如图7.47所示。
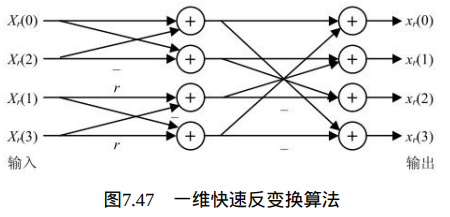
其中,r=1/2为逆整数DCT变换,r=1为逆Hadamard变换
反变换后,根据亮度的量化参数QP进行反量化及逆DCT中的比例变换:
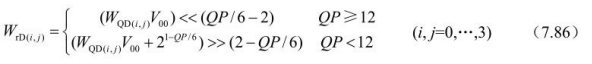
其中,V是融合在反量化过程中的逆DCT中的比例变换系数,它的定义类似于MF系数,V00是对应位置在(0,0)上的V值。不同位置的V值如表 7.9所示。
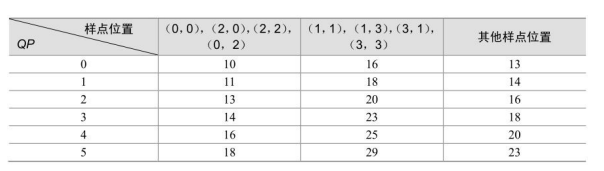 表7.9 H.264中V值题
表7.9 H.264中V值题
计算后要把相应得到的DCT直流系数放到对应图像亮度块的直流分量位置上。
色度直流变换系数的比例变换:
这个过程与帧内16×16预测模式宏块的亮度直流变换系数的比例变换类似,它的输入是宏块色度直流变换系数量化值,是一个2×2数组 。输出是4个反量化过的DCT中的直流系数值,表示成2×2数组
。
2×2色度直流变换系数的逆Hadamard变换定义为:

反变换后,根据色度的量化系数QPC进行反量化及逆DCT中的比例变换:
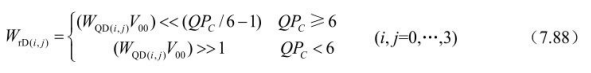
其中, 的值由亮度的量化系数QP及H.264中定义的句法元素chroma_qp_index_offset决定。
值由表7.10根据
值查找。
值由下式 计算:
 表7.10 QP值与qP的对应关系
表7.10 QP值与qP的对应关系
计算后要把相应得到的DCT直流系数放到对应图像色度块的直流分量 位置上。
3、残差变换系数的反量化:
同量化过程一样,反量化过程也融合了逆DCT变换中的乘法运算。首先,如果当前处理的图像块是色度块或帧内16×16预测模式的亮度块,则反量化输出矩阵 中的直流系数
直接为前节计算结果。对DCT交流分量或图像块不是前面情况的直流分量,计算如下:
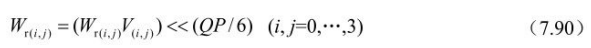
其中,QP为该块(亮度或色度)的量化参数,色度的量化参数的确定见上节。
4、残差变换系数的逆DCT变换:
按照整数DCT变换的原理,逆DCT变换的公式应该为:
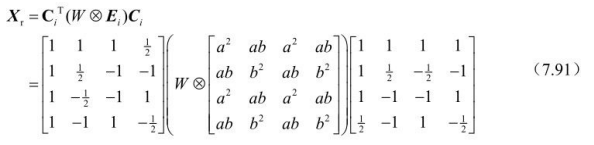
其中,"⊗ "已在前面的反量化中完成,其结果为
,所以这里只进行 以下运算:

同样,这里的矩阵运算也可以分成两次一维变换。
5、去方块滤波前的图像恢复与重建:
到上节为至,计算结果是图像与预测值之前的残差值矩阵,实际输出的各图像样点值(i和j为图像样点在图像块中的行和列)应该是在该点上得到的残差值与前面的预测值之和,这样才能得到图像各样点的恢复值。
图像的重建是将上面恢复的图像样点值赋值到实际的图像输出矩阵中。设当前宏块亮度样本的左上角位置为(xP,yP),当前图像块在宏块中的位置为(xO,yO),恢复样本矩阵为U。
如果U是亮度块,对4×4亮度块中的每个样本元素****,根据 MbaffFrameFlag的值进行以下操作。
- ①如果MbaffFrameFlag为1(当前宏块帧场自适应mb_adaptive_frame_field_flag为1,并且当前图像片为帧编码,即 field_pic_flag为0)并且当前宏块是场宏块,则重建图像中样点亮度值为:
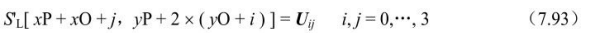
- ②否则(MbaffFrameFlag为0或者当前宏块是帧宏块),则重建图像中样点亮度值为:
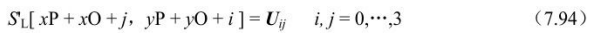
如果U是色度块,对4×4色度块中的每个样本元素****,根据 MbaffFrameFlag的值进行以下操作。
- ①如果MbaffFrameFlag为1并且当前宏块是场宏块,则重建中图像样点色度值为:
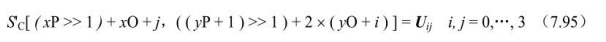
- ②否则(MbaffFrameFlag为0或者当前宏块是帧宏块),则重建中图像样点色度值为:
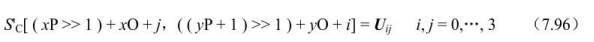
十一、SP片中的P宏块和SI片中的SI宏块的解码过程:
鉴于片是H.264标准的基本编解码单元,因此实质上是阐述对SP片中的P宏块和SI片中的SI宏块的解码。
SP帧分为主SP帧和辅SP帧,前者参考帧和当前编码帧属于同一码流, 而后者则不属于同一码流。片头语义变量sp_for_switch_flag用来区分主辅SP帧,0表示主SP帧,1表示辅SP帧。下面分别描述对这两种SP帧的解码过程。
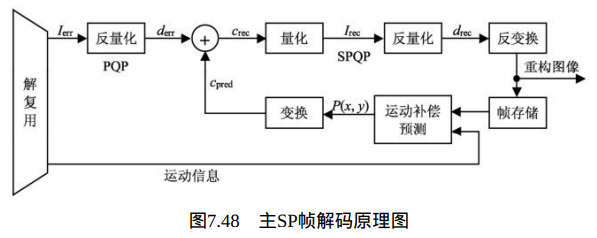
1、主SP片中P宏块的解码过程:
主SP片中P宏块的解码原理图如图7.48所示,具体又分为亮度变换系数和色度变换系数的解码过程。输入参数是当前宏块的帧间预测值和残差变换系数的预测值 ,输出参数为当前宏块的解码样点值。
亮度变换系数解码过程:
输入参数:当前宏块的帧间亮度预测值 、残差变换系数预测值LumaLevel和变换系数luma4×4BlkIdx。
输出参数:当前宏块的解码亮度样点值 。
亮度变换系数解码步骤如下。
- (1)luma4×4BlkIdx推导坐标(x,y);
- (2)求出宏块各点亮度的预测值:
- (3)求
- (4)
- (5)变换系数LumaLevelluma4×4BlkIdx 逆扫描过程映射为二维矩阵
- (6)求累加值:
- (7)
- (8)
色度的变换系数的解码过程:
输入参数是预测色度值ChromaDCLevel和预测残差变换系数值 ChromaACLevel,输出参数是当前宏块的解码色度值。
和上面类似,色度得变换系数分AC和DC两种,但两种的区别只是AC系数采用了DCT变换,而DC系数采用了Hadamard变换,其余步骤基本一 致,因此,下面只对AC系数的解码过程过行描述。
AC系数解码步骤如下。
- (1)chroma4×4BlkIdx推导坐标(x,y)。
- (2)求出宏块各点色度的预测值
- (3)求
- (4)对c p进行量化,量化参数为
- (5)求变量序列chromaListk:

- (6)变换系数chromaList chroma4×4BlkIdx 逆扫描求得二维矩阵
- (7)求重构值:
- (8)
- (9)对
- (10)
参考资料:
《新一代视频压缩编码标准 ---H.264/AVC》------毕厚杰 王健 编著